1. Elasticsearch简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。以后再给大家详细介绍solr。
它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
2. Elasticsearch深入了解
2.1 Elasticsearch的底层实现
-
2.1.1 lucene
Es是一个比较复杂的搜索服务器,本身也是使用Java语言编写的,在上面的简介中,说明了ES是一个基于lucene的搜索服务器,lucene是什么呢?Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。lucene也是使用Java语言编写的,Java天下第一!
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。至于lucene到底是怎么实现的,牛牛们可能要自己去百度或者谷歌一下啦。
-
2.1.2 Elasticsearch的基本概念
-
集群(Cluster):就是多台ES服务器在一起构成搜索服务器,现在很多应用基本上都有集群的概念,提高性能,让应用具有高可用性,一台服务器挂掉,可以很快有另一台ES服务器补上。
-
节点(Node):节点就是集群中的某一台ES服务器就称为一个节点。
-
索引库(Index Indices):就是ES服务器上的某一个索引,相当于Mysql数据库中的数据库的概念,一个节点可以有很多个索引库。
-
文档类型(Type):这个概念就相当于Mysql数据库中表的概念,一个索引库可以有很多个文档类型,但是这个概念现在慢慢淡化了,因为在ES中一个索引库直接存数据文档就挺好的,这个概念现在来说有点多余了,所以ES官方也在淡化这个概念,在ES8中,这个概念将会彻底的消失。
-
文档(Doc):文档就相当于Mysql是数据库中某个表的一条数据记录,现在ES已经到7.7版本了,我们也就忽略type这个概念,直接在索引库中存文档即可。另外需要说一下,我们一般把数据文档存到Es服务器的某个索引库的这个动作称之为索引。
最后还有两个比较重要的概念,但是可能不是那么直观的可以感受得到:
分片(Shards)和副本(Replicas)
索引可能会存储大量数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文档的单个索引占用了1TB的磁盘空间,可能不适合单个节点的磁盘,或者可能太慢而无法单独满足来自单个节点的搜索请求。
为了解决此问题,Elasticsearch提供了将索引细分为多个碎片的功能。创建索引时,只需定义所需的分片数量即可。每个分片本身就是一个功能齐全且独立的“索引”,可以托管在群集中的任何节点上。
分片很重要,主要有两个原因:
- 它允许您水平分割/缩放内容量
- 它允许您跨碎片(可能在多个节点上)分布和并行化操作,从而提高性能/吞吐量
分片如何分布以及其文档如何聚合回到搜索请求中的机制由Elasticsearch完全管理,并且对您作为用户是透明的。
在随时可能发生故障的网络/云环境中,非常有用,强烈建议您使用故障转移机制,以防碎片/节点因某种原因脱机或消失。为此,Elasticsearch允许您将索引分片的一个或多个副本制作为所谓的副本分片(简称副本)。
复制很重要,主要有两个原因:
- 如果分片/节点发生故障,它可提供高可用性。因此,重要的是要注意,副本碎片永远不会与从其复制原始/主要碎片的节点分配在同一节点上。
- 由于可以在所有副本上并行执行搜索,因此它可以扩展搜索量/吞吐量。
总而言之,每个索引可以分为多个碎片。索引也可以复制零(表示没有副本)或多次。复制后,每个索引将具有主碎片(从中进行复制的原始碎片)和副本碎片(主碎片的副本)。可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您可以随时动态更改副本数,但不能事后更改分片数。
默认情况下,Elasticsearch中的每个索引分配有5个主碎片和1个副本,这意味着如果集群中至少有两个节点,则索引将具有5个主碎片和另外5个副本碎片(1个完整副本),总共每个索引10个碎片。
-
-
2.1.3 Elasticsearch的索引原理
Es作为一个全文检索服务器,那么它在搜索方面肯定很在行啦!那它是怎么做到的呢?
Es官方有这么一句话:一切设计都是为了提高搜索的性能!
Es能够快速的搜索出我们需要的内容,靠的就是倒排索引的思想,或者说是一种设计!
在没有使用倒排索引的情况下,正常思路是根据搜索关键字去查找相应的内容,但是使用了倒排索引之后,ES会先将文档的所有内容拆分成多个词条,创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
例如,假设我们有两个文档,每个文档的
content域包含如下内容: Doc_1:The quick brown fox jumped over the lazy dog
Doc_2:Quick brown foxes leap over lazy dogs in summer
ES首先会将这两个文档拆分成多个单独的词,或者叫做词条,然后为所有的词条创建一个排序列表,并记录每个词条出现的文档的信息。就像下面这样:
Term Doc_1 Doc_2 ------------------------- Quick | | X /* The | X | Term就是词条,比如第一个Term就是Quick关键字,在Doc_1中不存 brown | X | X 在,在Doc_2中存在,其他的以此类推。 dog | X | */ dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------现在,如果我们想搜索 quick和brown这两个关键字,我们只需要查找包含每个词条的文档,就相当于我们查询的时候,是通过这个索引表找到文档,在通过文档去找文档内容中的搜索关键字,与传统的通过关键字去找内容是不同的。
倒排索引到底是个怎么实现的,怎么个思想,我在这里就不一一说明了,大家可以看下官方的详细介绍:倒排索引的原理
还有es官方的一系列的说明也都可以了解一下:什么是Elasticsearch?
2.2 Elasticsearch的安装
本演示项目ES版本为7.0.0版本,其他版本的ES的maven依赖与其他的jar包关系请自行查阅官方文档,保证不冲突。
-
Windows
Es服务器的安装很简单,Windows版本特别的简单,直接去官网下载,运行
bin/elasticsearch或者bin\elasticsearch.bat。 -
Linux(CentOS7)
首先我们去官网下载ES的tar.gz包,然后自建一个文件夹放好,然后解压tar.zg压缩包:
tar -xvf elasticsearch-7.0.0.tar.gz然后进入到bin目录下:
cd elasticsearch-7.0.0/bin然后运行elasticsearch:
./elasticsearch这个时候肯定会报错的,因为没有进行配置,所以我们先对es进行一些简单的配置,保证能单机运行,进入elasticsearch-7.7.0/config目录,对es的核心配置文件进行编辑:
vim elasticsearch.yml进入到了elasticsearch.yml文件的编辑页面:
首先我们配置集群名称,集群名称自己取一个喜欢的名字就好:

接下来配置节点名称,就是在这个集群中,这个es服务器的名称:

接下来配置一些必要的参数:

bootstrap.memory_lock: 是否锁住内存,避免交换(swapped)带来的性能损失,默认值是: false。bootstrap.system_call_filter: 是否支持过滤掉系统调用。elasticsearch 5.2以后引入的功能,在bootstrap的时候check是否支持seccomp。配置network为所有人都可以访问,因为我们一般是使用ssh连接工具在其他的电脑上操作Linux系统,所以我们需要配置一下:

到这里就配置完成了,但是当你重新去运行
.elasticsearch的可执行文件的时候,依然会报错。报错信息中可能包含以下几个错误:
-
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]原因:无法创建本地文件问题,用户最大可创建文件数太小。
解决方法:切换到root账户下,进入Linux系统文件夹,编辑limits.conf文件:
vim /etc/security/limits.conf在文件的末尾加上:
* soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 -
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]原因:最大虚拟内存太小,需要修改系统变量的最大值。
解决方法:切换到root账户下,进入Linux系统文件夹,编辑sysctl.conf文件:
vim /etc/sysctl.conf在文件的末尾加上:
vm.max_map_count=262144 -
max number of threads [1024] for user [es] likely too low, increase to at least [2048]原因:无法创建本地线程问题,用户最大可创建线程数太小。
解决方法:如果你是CentOS6及以下系统,编辑的文件是90-nproc.conf这个文件,如果你和我一样使用的是CentOS7的话,编辑的文件是20-nproc.conf文件,其实这两个文件是一样的,只是在不同CentOS系统中名称不一样而已。
CentOS7使用这个命令:
vim /etc/security/limits.d/20-nproc.confCentOS6使用这个命令:
vim /etc/security/limits.d/90-nproc.conf只需要在文件中加上以下配置:
* soft nproc 4096这个配置的意思是说赋予其他用户的可创建本地线程数为4096。在这个文件中本来就有一个配置,意思是说赋予root账户创建线程数不受限制。我们就把上面的配置加在本来存在的配置的下面一行就可以了。
如果是CentOS7的使用者,还需要配置另一个文件,否则这个最大线程数是不会生效的。CentOS 7 使用systemd替换了SysV,Systemd目的是要取代Unix时代以来一直在使用的init系统,兼容SysV和LSB的启动脚本,而且够在进程启动过程中更有效地引导加载服务。在/etc/systemd目录下有一个系统的默认管理配置,这里有登陆、日志、服务、系统等。所以CentOS7的使用者还需要配置下面这个文件:
vim /etc/systemd/system.conf对其中的选项进行配置,在文件的末尾加上:
DefaultLimitNOFILE=65536 DefaultLimitNPROC=4096
上面的所以错误解决完毕之后,我们再运行
.elasticsearch可执行文件,es才可以启动成功。 -
2.3 Elasticsearch的使用
首先给大家介绍一个谷歌浏览器插件,这个插件是用来可视化展示es的索引库数据的,这个插件叫做ElasticVue,个人感觉挺好用的,展示也比较方便,给大家截个图看看:

大家可以使用这个建立索引库,然后调用es官方的es专用的语法操作es服务器进行CRUD操作,但是此处我只介绍Java语言如何调用es服务器API,废话不多说,我们直接开始下一步。
-
2.3.1 引入依赖
搭建工程的过程我就不演示了,直接上pom.xml依赖文件。
pom.xml:org.springframework.boot spring-boot-starter-parent 2.2.2.RELEASE org.springframework.boot spring-boot-starter-web 2.2.2.RELEASE org.elasticsearch.client elasticsearch-rest-client 7.7.0 org.elasticsearch.client elasticsearch-rest-high-level-client 7.7.0 org.elasticsearch elasticsearch 7.7.0 org.mybatis.spring.boot mybatis-spring-boot-starter 2.1.0 mysql mysql-connector-java 8.0.18 org.projectlombok lombok 1.18.10 com.google.code.gson gson 2.8.5 org.springframework.boot spring-boot-test junit junit 4.12 test org.springframework spring-test 5.2.2.RELEASE test org.springframework.boot spring-boot-maven-plugin org.apache.maven.plugins maven-compiler-plugin -parameters -
2.3.2 Elasticsearch的配置类和Gson配置类和应用配置文件
application.yml:butterflytri: databaseurl-port: 127.0.0.1:3306 # 数据库端口 database-name: student_db # 数据库名 host: 192.168.129.100:9200 # es服务端 server: port: 8080 # 应用端口 servlet: context-path: /butterflytri # 应用映射 spring: application: name: mybatis # 应用名称 datasource: url: jdbc:mysql://${butterflytri.databaseurl-port}/${butterflytri.database-name}?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC driver-class-name: com.mysql.jdbc.Driver username: root password: root mybatis: type-aliases-package: com.butterflytri.entity # entity别名 mapper-locations: classpath:com/butterflytri/mapper/*Mapper.xml # mapper映射包扫描注意:yml文件中的192.168.129.100:9200是es对外的端口,使用的http协议进行操作,es服务器还有个9300端口,这个端口是es集群中各个节点进行交流的端口,使用的是tcp协议。所以我们连接的时候,端口要使用9200端口。
项目启动类没有什么特别的东西,就不展示了。
ElasticsearchConfig.java:package com.butterflytri.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.beans.factory.DisposableBean; import org.springframework.beans.factory.FactoryBean; import org.springframework.beans.factory.InitializingBean; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; /** * @author: WJF * @date: 2020/5/22 * @description: ElasticSearchConfig */ @Configuration public class ElasticSearchConfig implements FactoryBean, InitializingBean, DisposableBean { /** * {@link FactoryBean }:FactoryBean 是spring对外提供的对接接口,当向spring对象使用getBean("..")方法时, * spring会使用FactoryBean 的getObject 方法返回对象。所以当一个类实现的factoryBean 接口时, * 那么每次向spring要这个类时,spring就返回T对象。 * * {@link InitializingBean}:InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法, * 凡是继承该接口的类,在初始化bean的时候会执行该方法。在spring初始化bean的时候,如果该bean是 * 实现了InitializingBean接口,并且同时在配置文件中指定了init-method,系统则是 * 先调用afterPropertiesSet方法,然后在调用init-method中指定的方法。 * * {@link DisposableBean}:DisposableBean接口为bean提供了销毁方法destroy-method,会在程序关闭前销毁对象。 */ @Value("#{'${butterflytri.host}'.split(':')}") private String[] host; private RestHighLevelClient restHighLevelClient; private RestHighLevelClient restHighLevelClient() { restHighLevelClient = new RestHighLevelClient( RestClient.builder(new HttpHost(host[0],Integer.valueOf(host[1]),"http")) ); return restHighLevelClient; } @Override public void destroy() throws Exception { restHighLevelClient.close(); } @Override public RestHighLevelClient getObject() throws Exception { return restHighLevelClient; } @Override public Class getObjectType() { return RestHighLevelClient.class; } @Override public void afterPropertiesSet() throws Exception { restHighLevelClient(); } } ES的配置类,这个配置类实现了三个接口,三个接口的作用我也写上了注释,大家可以看下,需要注意的是
FactoryBean这个接口,一但实现了这个接口,每当你需要使用泛型表示的对象T的时候,Spring不会从容器中去拿这个对象,而是会调用这个FactoryBean.getObject()方法去拿对象。其他的就没有什么了。Gson.java:Gson是一个操作json数据的类,它的执行效率可能会慢一点,但是它在解析json数据的时候不会出Bug。
package com.butterflytri.config; import com.google.gson.Gson; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author: WJF * @date: 2020/5/22 * @description: GsonConfig */ @Configuration public class GsonConfig { /** * {@link Gson}:一个操作json的对象,有比较好的json操作体验,相对于Alibaba的FastJson来说速度慢一些,但是FastJson在解析 * 复杂的的json字符串时有可能会出现bug。 * @return Gson */ @Bean public Gson gson() { return new Gson(); } }Constants.java:这是我写的常量类,放一些ES使用的常量,直接写字符串也行,但是我建议这样做。
package com.butterflytri.constants; /** * @author: WJF * @date: 2020/5/22 * @description: Constants */ public class Constants { /** * es搜索关键字 */ public static final String KEYWORD = ".keyword"; /** * es的type类型:type字段将在 elasticsearch-version:8 中彻底删除,本来就觉得没得啥用。 */ public static final String DOC_TYPE = "_doc"; /** * 学生信息索引类型 */ public static final String INDEX_STUDENT = "student_info"; /** * 自定连接符 */ public static final String CONNECTOR = " --> "; }Student.java:package com.butterflytri.entity; import lombok.Getter; import lombok.Setter; import lombok.ToString; import java.io.Serializable; /** * @author: WJF * @date: 2020/5/16 * @description: Student */ @ToString @Getter @Setter public class Student implements Serializable { private Long id; private String studentName; private String studentNo; private String sex; private Integer age; private String clazz; }StudentMapper.java:package com.butterflytri.mapper; import com.butterflytri.entity.Student; import org.apache.ibatis.annotations.Mapper; import java.util.List; /** * @author: WJF * @date: 2020/5/16 * @description: StudentMapper */ @Mapper public interface StudentMapper { /** * 查询所有学生信息 * @return List*/ List findAll(); /** * 通过id查询学生信息 * @param id:学生id * @return Student */ Student findOne(Long id); /** * 通过学号查询学生信息 * @param studentNo:学生学号 * @return Student */ Student findByStudentNo(String studentNo); } mybatis的SQL映射文件我就不展示了,也很简单,大家看接口方法名就应该可以想象得到SQL语句是怎样的。
-
2.3.3 索引数据到ES服务器
IndexServiceImpl.java:package com.butterflytri.service.impl; import com.butterflytri.constants.Constants; import com.butterflytri.entity.Student; import com.butterflytri.service.IndexService; import com.google.gson.Gson; import org.elasticsearch.action.ActionListener; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.io.IOException; /** * @author: WJF * @date: 2020/5/22 * @description: IndexServiceImpl */ @Service public class IndexServiceImpl implements IndexService { @Resource private Gson gson; @Resource private RestHighLevelClient restHighLevelClient; @Override public String index(Student student) { StringBuilder builder = new StringBuilder(); IndexRequest indexRequest = this.initIndexRequest(student); try { // 同步索引到elasticsearch服务器,获取索引响应IndexResponse IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT); String statusName = indexResponse.status().name(); int statusCode = indexResponse.status().getStatus(); builder.append(statusName).append(Constants.CONNECTOR).append(statusCode); } catch (IOException e) { builder.append("Fail").append(Constants.CONNECTOR).append(e.getMessage()); } return builder.toString(); } @Override public String indexAsync(Student student) { StringBuilder builder = new StringBuilder(); IndexRequest indexRequest = this.initIndexRequest(student); // 异步索引到elasticsearch服务器,获取索引响应IndexResponse restHighLevelClient.indexAsync(indexRequest, RequestOptions.DEFAULT,actionListener(builder)); return builder.toString(); } /** * 初始化IndexRequest,并设置数据源。 * @param student * @return IndexRequest */ private IndexRequest initIndexRequest(Student student) { // 构建IndexRequest,设置索引名称,索引类型,索引id IndexRequest indexRequest = new IndexRequest(Constants.INDEX_STUDENT); // 可以不设置,默认就是'_doc' indexRequest.type(Constants.DOC_TYPE); // 设置索引id为studentId indexRequest.id(String.valueOf(student.getId())); // 设置数据源 String studentJson = gson.toJson(student); indexRequest.source(studentJson, XContentType.JSON); return indexRequest; } /** * 异步索引的回调监听器,根据不同的结果做出不同的处理 * @param builder * @return ActionListener*/ private ActionListener actionListener(StringBuilder builder) { return new ActionListener () { // 当索引数据到es服务器时,返回不同的状态 @Override public void onResponse(IndexResponse indexResponse) { String statusName = indexResponse.status().name(); int statusCode = indexResponse.status().getStatus(); builder.append(statusName).append(Constants.CONNECTOR).append(statusCode); } // 当索引数据时出现异常 @Override public void onFailure(Exception e) { builder.append("Fail").append(Constants.CONNECTOR).append(e.getMessage()); } }; } } 上面的内容很简单,就是将Student对象格式化为Json字符串,然后存到es服务器中,大家只要遵守一个规则就好,就是操作es服务器,不管是什么操作都是用RestHighLevelClient这个类去操作,上面的就是student对象索引的es服务器中,使用
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT),首先就是构建indexRequest对象,这个对象就是索引请求对象,具体干了什么看代码上的注释。这里还有个restHighLevelClient.indexAsync()这个方法,这个方法和上面的index方法一样的效果,只不过是异步调用。接下来我们测试一下这个代码,请看:
@Test public void indexTest() { Listlist = studentMapper.findAll(); for (Student student : list) { String message = indexService.index(student); System.out.println(message); } } 我们使用ElasticVue插件连接es服务器即可看到有一个索引库:

当我们点击到show按钮的时候,可以看到student_info索引库中有几条记录:
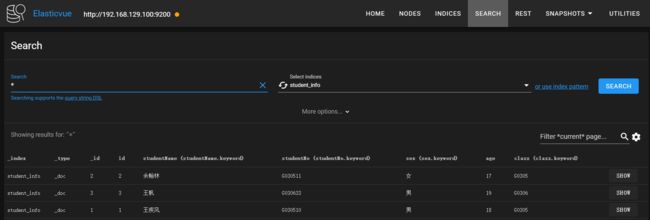
索引数据到数据库成功了。
-
2.3.4 获取Es服务器数据
获取数据,是es提供给我们的API,这个Api只能获取某个索引的某一条文档,示例如下:
GetServiceImpl.java:@Override public Student get(String id) { Student student = new Student(); GetRequest getRequest = new GetRequest(Constants.INDEX_STUDENT, id); try { GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); String source = getResponse.getSourceAsString(); student = gson.fromJson(source, Student.class); } catch (IOException e) { e.printStackTrace(); } return student; }接着我们在测试类中,调用这个方法然后打印一下结果:
GetServiceTest.java:@Test public void getTest() { Student student = getService.get("1"); System.out.println(student); }结果如下:

更新数据文档和删除数据文档我就不演示了,都是大同小异,大家可以拉下我的代码,好好研究一下,都有详细的注释,觉得可以的话,给我点下star也是极好的。下面演示一下searchApi,这个Api是我们经常需要使用的,特别重要。
-
2.3.5 搜索Es服务器数据
ES的搜索API包含很多,比如说组合搜索,区间搜索,高亮显示,分词搜索等等。我先给大家演示一下组合搜索,区间搜索其实也是组合搜索的一个子条件,其他的搜索其实也都是,代码如下:
SearchServiceImpl.java:@Override public ListsearchRange(Object from, Object to, String field, String index) { List list = new ArrayList<>(); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); // 需要搜索的区间字段field RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery(field); // 左区间 if (from != null) { rangeQueryBuilder.from(from, true); } // 右区间 if (to != null) { rangeQueryBuilder.to(to, true); } boolQueryBuilder.must(); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(boolQueryBuilder); SearchRequest searchRequest = new SearchRequest(index); searchRequest.source(searchSourceBuilder); try { SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); for (SearchHit hit : search.getHits()) { String source = hit.getSourceAsString(); Student student = gson.fromJson(source, Student.class); list.add(student); } } catch (IOException e) { e.printStackTrace(); } return list; } 上面的代码其实很简单,就是一个区间查询构建器,查询指定字段处于区间的所有数据,
rangeQueryBuilder.from(from, true)的第一个参数就是字段的下边界,第二个参数代表是否包含边界。SearchResponse就是搜索的响应对象,所有的数据都在SearchHit对象中。接下来给大家演示一些组合查询,这个方法搜索年龄在18到19岁并且班级为'G0305'的学生。记得ES默认是分页的,如果想不分页,一定要记得给搜索字段加上
.keyword(字符串加,数字不支持)。SearchServiceImpl.java:@Override public ListsearchBool() { List list = new ArrayList<>(); BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); boolQuery.must(QueryBuilders.rangeQuery("age").gte(18).lte(19)); boolQuery.must(QueryBuilders.termQuery("clazz" + Constants.KEYWORD,"G0305")); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(boolQuery); SearchRequest searchRequest = new SearchRequest(Constants.INDEX_STUDENT); searchRequest.source(searchSourceBuilder); try { SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); for (SearchHit hit : search.getHits()) { String source = hit.getSourceAsString(); Student student = gson.fromJson(source, Student.class); list.add(student); } } catch (IOException e) { e.printStackTrace(); } return list; } 上面的代码中的类
BoolQueryBuilder就是组合查询构建器,这个类可以用来构建组合的条件查询。boolQuery.must()方法就是用来拼接条件的一种方式,使用这个方法代表必须满足这个条件才会查询出来,上面的代码说明必须满足年龄为18(包含18)到19(包含19)岁,并且班级为'G0305'的学生才会查询出来。还有其他的一些常见的组合查询方法,如下:boolQuery.must():必须满足此条件,相当于=或者&。boolQuery.mustNot():必须不满足此条件,相当于!=。boolQuery.should():相当于||或者or。boolQuery.filter():过滤。
然后是聚合查询,很类似于MySQL中的聚合函数,这个示例我就不再解释了,代码注释很清楚:
@Override public void searchBoolAndAggregation() { BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); boolQuery.must(QueryBuilders.rangeQuery("age").gte(18).lte(19)); boolQuery.must(QueryBuilders.termQuery("clazz" + Constants.KEYWORD,"G0305")); // 聚合分组:按clazz字段分组,并将结果取名为clazz,es默认是分词的,为了精确配置,需要加上‘.keyword’关键词后缀。 TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("clazz").field("clazz" + Constants.KEYWORD); // 聚合求和:求符合查询条件的学生的年龄的和,并将结果取名为ageSum,因为不是字符串,所以默认是精确匹配,不支持分词。 aggregationBuilder.subAggregation(AggregationBuilders.sum("ageSum").field("age")); // 聚合求平均:求符合查询条件的学生的年龄的平均值,并将结果取名为ageAvg,因为不是字符串,所以默认是精确匹配,不支持分词。 aggregationBuilder.subAggregation(AggregationBuilders.avg("ageAvg").field("age")); // 聚合求数量:按学号查询符合查询条件的学生个数,并将结果取名为count,es默认是分词的,为了精确配置,需要加上‘.keyword’关键词后缀。 aggregationBuilder.subAggregation(AggregationBuilders.count("count").field("studentNo" + Constants.KEYWORD)); SearchSourceBuilder builder = new SearchSourceBuilder(); builder.query(boolQuery); builder.aggregation(aggregationBuilder); // 按年龄降序排序。 builder.sort("age", SortOrder.DESC); SearchRequest request = new SearchRequest("student_info"); request.source(builder); try { SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT); for (SearchHit hit : search.getHits()) { String source = hit.getSourceAsString(); Student student = gson.fromJson(source, Student.class); System.out.println(student); } // 使用Terms对象接收 Terms clazz = search.getAggregations().get("clazz"); for (Terms.Bucket bucket : clazz.getBuckets()) { System.out.println(bucket.getDocCount()); System.out.println("====================="); // 使用ParsedSum对象接收 ParsedSum ageCount = bucket.getAggregations().get("ageSum"); System.out.println(ageCount.getType()); System.out.println(ageCount.getValue()); System.out.println(ageCount.getValueAsString()); System.out.println(ageCount.getMetaData()); System.out.println(ageCount.getName()); System.out.println("====================="); // 使用ParsedAvg对象接收 ParsedAvg ageAvg = bucket.getAggregations().get("ageAvg"); System.out.println(ageAvg.getType()); System.out.println(ageAvg.getValue()); System.out.println(ageAvg.getValueAsString()); System.out.println(ageAvg.getMetaData()); System.out.println(ageAvg.getName()); System.out.println("====================="); // 使用ParsedValueCount对象接收 ParsedValueCount count = bucket.getAggregations().get("count"); System.out.println(count.getType()); System.out.println(count.getValue()); System.out.println(count.getValueAsString()); System.out.println(count.getMetaData()); System.out.println(count.getName()); } } catch (IOException e) { e.printStackTrace(); } }最后还有分词查询,分词查询就不加
.keyword关键字即可。@Override public ListsearchMatch(String matchStudentName) { List list = new ArrayList<>(); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); // 分词查询时不加'.keyword'关键字 boolQueryBuilder.must(QueryBuilders.matchQuery("studentName",matchStudentName)); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(boolQueryBuilder); SearchRequest searchRequest = new SearchRequest("student_info"); searchRequest.source(searchSourceBuilder); try { SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); for (SearchHit hit : search.getHits().getHits()) { String source = hit.getSourceAsString(); Student student = gson.fromJson(source, Student.class); list.add(student); } } catch (IOException e) { e.printStackTrace(); } return list; } 请记住,一般的进行分词都是字符串才进行分词搜索,数字等类型只能是精准匹配。
最后,ES功能很强大,作为搜索界的扛把子,ES的功能远远不止这些,它还可以高亮搜索,数据分析等等。我在这里演示的仅仅只是皮毛,甚至都不是皮毛,仅作为初学者的参考。如有大佬觉得我哪里写错了,或者有不同见解,欢迎留言。
3. 项目地址
本项目传送门:
- GitHub ---> spring-boot-elasticsearch
- Gitee ---> spring-boot-elasticsearch
此教程会一直更新下去,觉得博主写的可以的话,关注一下,也可以更方便下次来学习。
- 作者:Butterfly-Tri
- 出处:Butterfly-Tri个人博客
- 版权所有,欢迎保留原文链接进行转载