hive学习总结
hive 学习总结
- 1.组成
- 2.运行流程
- hive sql 转换为MapReduce过程
- 3.hive 操作数据
- 3.1 DML 数据操作
- 3.1.1 数据导入表
- 3.1.2 数据导出表
- 3.2 DDL数据操作
- 3.2.1 数据库操作
- 3.2.2 表的操作
- 3.2.3 列的操作
- 3.2.4 详解创建表
- 1 EXTERNAL(内部表与外部表)
- 2.PARTITIONED BY(分区表)
- 3.CLUSTERED BY(分桶表)
- 4.ROW FORMAT(行切割符)
- 3.2.5 查询
- 1. 执行的顺序
- 2. 查询语法
- 3. join
- 4. where
- 5. group by
- 6. 函数
- 7. having
- 8. distinct
- 9. order by
- 10 cluster by
- 11 over() 窗口函数
1.组成
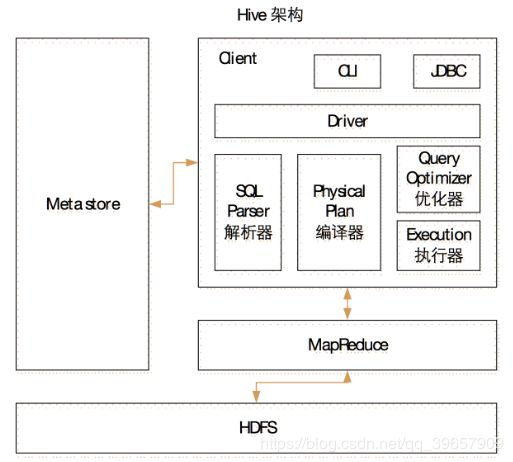
1.用户接口(Clint) : CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据(Metastore) : 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
3.驱动器(Driver):
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark
4.Hadoop : 使用 HDFS 进行存储,使用 MapReduce 进行计算
2.运行流程
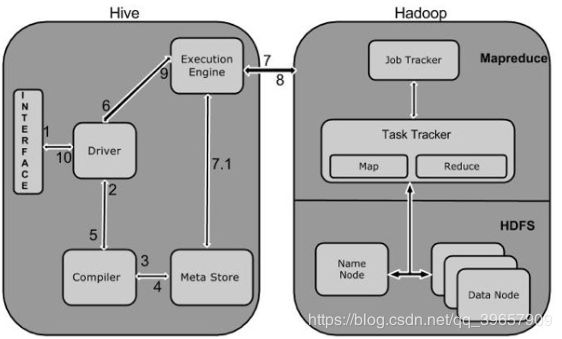
- Execute Query :Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
- Get Plan:在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求
- Get Metadata:编译器发送元数据请求到Metastore(任何数据库)。
- Send Metadata:Metastore发送元数据,以编译器的响应。
- Send Plan:编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
- Execute Plan:驱动程序发送的执行计划到执行引擎
- Execute Job:在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
Metadata Ops:与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 - Fetch Result:执行引擎接收来自数据节点的结果。
- Send Results:执行引擎发送这些结果值给驱动程序。
- Fetch Result:驱动程序将结果发送给Hive接口。
hive sql 转换为MapReduce过程
- antlr 定义sql语法规则,完成sql词法,语法解析,将sql转换为抽象语法树AST tree
- 遍历 AST tree,抽象出查询的基本单元 查询块queryBlock
- 遍历 queryBlock,翻译成执行操作树 operatorTree
- 逻辑层优化器进行OperatorTree优化,合并不需要的reduceSinkOperator(合并操作),减少shuffle(遍历清洗)数据量
- 遍历operatorTree ,翻译成MapReduce任务
- 物理层优化器进行MapReduce任务的转化,生成最终执行计划
HiveSql->AST tree(抽象语法树)->query block(查询块)->operation tree(执行操作树)->逻辑层优化执行操作树 减少重复的合并 减少不必要的shuffle(混洗)->new operation tree(新的执行逻辑树)->MapReduce task->进行物理层的优化->new MapReduce task
3.hive 操作数据
3.1 DML 数据操作
3.1.1 数据导入表
-
load语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]- load data : 表示加载数据
- local : 表示从本地文件系统导入数据. 如果不加local表示从 HDFS 文件系统导入数据
- filepath : 表示要加载的数据的路径.
- overwrite : 表示覆盖表中已有数据, 不加参数表示追加数据到表中.
- partition:上传到指定分区.
3.1.2 数据导出表
-
insert语句
-
插入数据
insert overwrite [local] table [表名] [查询语句] 加上local表示本地系统,不加表示HDFS -
导出数据
inset overwrite [local] directory '路径' [导出格式化说明] 查询语句 加上local表示本地系统,不加表示HDFS
-
-
由于Hive的表在HDFS上表现的就是文件
-
所以如果存储的文件格式恰好使我们想要的那么我们可以直接用hdfs命令把它拷贝下来
hadoop fs -get /user/hive/warehouse/student_3 /opt/module/datas/export/student_3.txt; -
也可以用Export 导出表的内容到 HDFS 上
export table default.student to '/user/hive/warehouse/export/student';
-
3.2 DDL数据操作
3.2.1 数据库操作
-
创建数据库
create database [if not exists] [数据库名] -
删除数据库
drop database [if not exists] [数据库名] -
使用数据库
use [数据库名] -
查看数据库信息
desc database [数据库名] desc database extended [数据库名] //查看数据库详细信息
3.2.2 表的操作
-
创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [like table_name]- EXTERNAL:加上该关键字可以让用户创建一个外部表。
- IF NOT EXISTS:当创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。(如果不存在才创建这个表)
- COMMENT:为表和列添加注释。
- PARTITIONED BY:创建分区表
- CLUSTERED BY:创建分桶表
-
SORTED BY: 在桶中以哪个列进行排序. 几乎不用 -
INTO num_buckets BUCKETS:分几个桶
-
- ROW FORMAT:行内的切割符
- STORED AS:指定存储文件类型 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件) 如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- LOCATION :指定表在HDFS上的存储位置。
- LIKE:允许用户复制现有的表结构,但是不复制数据。
-
删除表
drop table [if not exists] [表名] -
修改表
alter table [旧表名] rename to [新表名]
3.2.3 列的操作
-
更新列
alter table [表名] change column [旧列名] [新列名] [列的类型] -
增加列
alter table [表名] add columns([列名] [列的类型]) -
替换列
alter table [表名] replace columns([列名1] [列1的类型], [列名2] [列2的类型], [列名3] [列3的类型])
3.2.4 详解创建表
1 EXTERNAL(内部表与外部表)
-
区别
区别 创建表过程 删除表过程 内部表 会将数据移动到数据仓库指向的路径 元数据和实际数据一起删除 外部表 仅记录数据所在的路径,不会对数据的位置坐任何改变 只删除元数据,不删除实际数据,相对比较安全。 注:Hive 默认情况创的表都是内部表。内部表使用简单, 但是不方便的地方是不能与其他应用程序共享数据
-
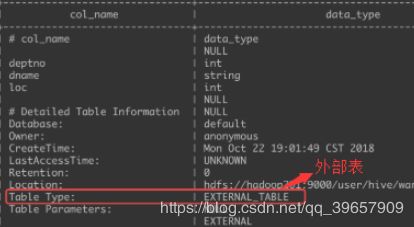
如何查看创建好的表是内部表还是外部表
desc formatted dept;
-
如何对内部表和外部表进行转换
-
把外部表变为内部表
alter table [表名] set tblproperties('EXTERNAL'='FALSE'); -
把内部表变为外部表
alter table [表名] set tblproperties('EXTERNAL'='TRUE');
-
注:在团队开发中,在hdfs上存放重要数据时不要使用内部表,都是使用外部表关联数据。
2.PARTITIONED BY(分区表)
-
创建分区表
-
创建时指定
-
已创建添加
-
增加多个分区
alter table [表名] add partition([表的分区名]='分区指定') partition([表的分区名]='分区指定');
-
-
-
查看表中有哪些分区
show partitions [表名]; -
向分区中导入数据
- 上传数据后修复
//手动创建分区目录, 后面直接通过 hdoop fs ... 的方式把数据上传到分区目录, 则需要修复一下即可. msck repair table dept_partition2;场景:hive分区已经创建好,hdfs上也有分区目录,但是数据没有
- 上传数据后添加分区
//手动创建分区目录, 后面直接通过 hdoop fs ... 的方式把数据上传到分区目录, 则根据手动创建的目录, 再执行添加分区的命令就可以了. alter table dept_partition2 add partition(month='201709', day='11');场景:hive没有创建分区,hdfs上没有分区目录;hive没有创建分区,hdfs上有分区目录
- 上传数据后load数据到分区
//手动创建分区目录, 则再执行 load命令也可以. load data local inpath '/opt/module/datas/dept.txt' into table dept_partition2 partition(month='201709',day='10');场景:hive有创建分区,hdfs上没有分区目录
-
查询分区表中的数据
select * from [表名] where [表的分区名]="分区指定"; -
删除分区
alter table [表名] drop partition ([表的分区名]='分区指定'), partition ([表的分区名]='201706'); -
存在分区表的意义
因为Hive 在查询数据的时候,一般会扫描整个表的数据,在数据量很大而且查询准确的条件下,会消耗很多不必要的时间。而分区会对某列相同的数据或者某一个数据范围的数据进行分类,这样在查询的时候,就可以只是针对分区查询,从而不必全表扫描。
注:可以理解分区表就是将整个表进行了拆分,使一个大表根据分区分成了多个小表
3.CLUSTERED BY(分桶表)
-
对于每一个表或者分区,可以进一步细分成桶,桶是对数据进行更细粒度的划分。 默认时对某一列进行 hash,使用hashcode对桶的个数求模取余,确定哪一条记录进入哪一个桶。
-
每个分区在 HDFS 上表现为一个文件夹, 每个桶在 HDFS 上表现一个文件.
-
主要用在抽样查询的时候,用户需要的使用的是一个具有代表性的查询结果而不是全部结果时。
-
有两种抽样的方法:分桶抽样和数据块抽样(百分比)
4.ROW FORMAT(行切割符)
- 语法
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
- 举个例子
create table person(
name string,
friends array<string>,
children map<string, int>,
address struct<street : string, city : string>
)
row format delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
- row format delimited fields terminated by ‘,’ : 每行中列与列的分隔符是,
- collection items terminated by '’ : array 和 sturct的分隔符是
- map keys terminated by ‘:’ , map 键值对的分隔符是
- lines terminated by ‘\n’, 行分隔符是 \n
3.2.5 查询
1. 执行的顺序

2. 查询语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
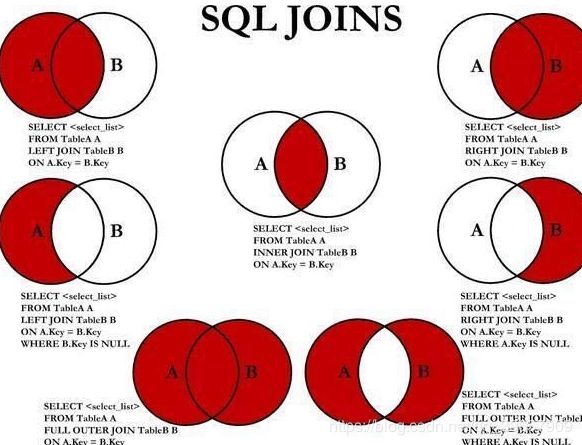
3. join
-
内连接:
select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno; -
左外连接:
select e.empno, e.ename, d.deptno, d.dname from emp e left join dept d on e.deptno=d.deptno; -
右外连接:
select e.empno, e.ename, d.deptno, d.dname from emp e right join dept d on e.deptno=d.deptno; -
支持满外连接
返回两张表中所有的记录, 如另外一张表没有匹配的, 则用 NULL 替换. -
支持多表连接
e.ename, d.deptno, l. loc_name FROM emp e JOIN dept d ON d.deptno = e.deptno JOIN location l ON d.loc = l.loc;注:大多数情况下,Hive 会对每对 JOIN 连接对象启动一个 MapReduce 任务,并且Hive总是按照从左到右的顺序执行的!!!且Hive只支持等值连接,不支持普通的SQL的非等值连接
4. where
支持like,类Mysql,但是也支持rlike 子句,他是 Hive 中对 like 的一个扩展,其可以通过 Java 的正则表达式这个更强大的工具
5. group by
分组:类似 每 这个字
主要是当需求中需要用到分组函数时用到!且查询的内容必须包含在group by字段后,或者是分组函数
6. 函数
官方参考网址: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
7. having
-
为什么出现?
因为where语句后不能使用分组函数,而为了完善这个所以推出了having,用于分组函数过滤 -
举栗子
select job,avg(sal) from emp having avg(sal)>1500 group by job; SELECT openid , count(*) FROM smj_order GROUP BY openid HAVING count(*)>1 ORDER BY count(*) desc;
8. distinct
去除重复数据
-
单一字段去重
select distinct a_name from a1说明:对单一一个字段使用distinct去除重复值时,会过滤掉多余重复相同的值,只返回唯一的值。
-
多字段去重
select distinct a_id,a_name from a1说明:对多个字段同时使用distinct去除重复值时,distinct字段必须放在第一个字段前面,不能放在其他字段的后面。既distinct必须放在select 后面,第一个字段的前面。同时,使用distinct多个字段去除重复数据时,必须满足各行中各列所对应的值都相同才能去除重复值,如果有其中一列的值不相同,那就表示这些数据不是重复的数据,不会过滤掉。
9. order by
根据指定的字段排序
- 多列的时候
order by A,B 这个时候都是默认按升序排列
order by A desc,B 这个时候 A 降序,B 升序排列
order by A ,B desc 这个时候 A 升序,B 降序排列
注:desc 或者 asc 只对它紧跟着的第一个列名有效,其他不受影响,仍然是默认的升序。
10 cluster by
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
distribute by 一般与sort by 一起使用:进行分区排序
cluster by :等价于distribute by与sort by作用在字段相同且升序排序的时候
举个栗子:
以下两种写法等价
select * from emp cluster by deptno;
select * from emp distribute by deptno sort by deptno;
11 over() 窗口函数
-
什么时候我们需要用到开窗函数
- 当我们用到聚合函数并且希望查询结果的每条记录都能包含聚合函数的值时
- 当我们用到分析函数(sum /avg …)且需要指定函数的分析范围大小时
-
开窗函数的执行顺序仅在order by 的前面
-
over()函数中可以写
放在开窗函数内部: CURRENT ROW:当前行 n PRECEDING:往前n行数据 n FOLLOWING:往后n行数据 UNBOUNDED:起点, UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点 -
over()函数前可以写
LAG(col,n):往前第n行数据; LEAD(col,n):往后第n行数据; NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。 first_value(col), last_value(col), 指定列的第一个或者最后一列的值; 产生序号(名次)的的函数 RANK() 排序相同时会重复,序号会出现不连续的情况; DENSE_RANK() 排序相同时会重复,序号连续; ROW_NUMBER() 排序相同时不会重复,序号连续 percent_rank() (分组内的rank值 - 1)/(分组内的总行数 - 1) cume_dist() : 分组内的当前行数/分组内的总行数
版权声明:本博客为记录本人自学感悟,转载需注明出处!
https://me.csdn.net/qq_39657909