直方图,一种特殊类型的列的统计信息,它能提供表中列的更详细的数据分布信息,直方图将值存放于桶(buckets)中。基于不同值的数目和数据的分布,数据库选择要创建的直方图类型,直方图的类型有如下几种:
- 频率直方图和顶频直方图:Frequency histograms and to frequency histograms;
- 高度平衡直方图(遗留):Height-Balanced hitograms;
- 混合柱状图:Hybrid histograms;
1 直方图介绍
1.1 使用直方图的目的
默认情况下,优化器假定列的不同值之间时均匀分布的。对于包含数据倾斜列(列中数据的分布不均匀的列),直方图使优化器能够为涉及这些列的过滤或连接谓词生成更准确的基数的估计值,从而生成更精确的执行计划。
1.2 何时数据库创建直方图
使用DBMS_STATS搜集表的统计信息,查询引用表中的列时,数据库会根据之前的查询负载来自动的创建直方图。基本过程如下:
- 使用DBMS_STATS搜集表的统计信息,且指定METHOD_OPT参数默认为SIZE AUTO;
- 用户查询对应的表;
- 数据库记录前面查询时使用的谓词,并更新数据字典表SYS.COL_USAGE$;
- 再次运行DBMS_STATS时,DBMS_STATS会查询SYS.COL_USAGE$视图并根据前面的查询负载决定哪些列需要直方图。
示例:
1)创建测试表
SQL> create table sh.sales_new as select * from sh.sales;
Table created.2)查看统计信息
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW';
COLUMN_NAME NOTES HISTOGRAM
------------------------------ ------------------------------ ---------------
AMOUNT_SOLD STATS_ON_LOAD NONE
QUANTITY_SOLD STATS_ON_LOAD NONE
PROMO_ID STATS_ON_LOAD NONE
CHANNEL_ID STATS_ON_LOAD NONE
TIME_ID STATS_ON_LOAD NONE
CUST_ID STATS_ON_LOAD NONE
PROD_ID STATS_ON_LOAD NONE
7 rows selected.3)执行查询
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW';
COLUMN_NAME NOTES HISTOGRAM
------------------------------ ------------------------------ ---------------
AMOUNT_SOLD STATS_ON_LOAD NONE
QUANTITY_SOLD STATS_ON_LOAD NONE
PROMO_ID STATS_ON_LOAD NONE
CHANNEL_ID STATS_ON_LOAD NONE
TIME_ID STATS_ON_LOAD NONE
CUST_ID STATS_ON_LOAD NONE
PROD_ID STATS_ON_LOAD NONE
7 rows selected.4)搜集统计信息
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','SALES_NEW',OPTIONS=>'GATHER AUTO');
PL/SQL procedure successfully completed.5)查看统计信息
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='SALES_NEW';
COLUMN_NAME NOTES HISTOGRAM
------------------------------ ------------------------------ ---------------
AMOUNT_SOLD STATS_ON_LOAD NONE
QUANTITY_SOLD STATS_ON_LOAD NONE
PROMO_ID STATS_ON_LOAD NONE
CHANNEL_ID STATS_ON_LOAD NONE
TIME_ID STATS_ON_LOAD NONE
CUST_ID STATS_ON_LOAD NONE
PROD_ID HISTOGRAM_ONLY FREQUENCY
7 rows selected.6)查看列的使用
SQL> select * from sys.col_usage$ where obj#=93264;
OBJ# INTCOL# EQUALITY_PREDS EQUIJOIN_PREDS NONEQUIJOIN_PREDS RANGE_PREDS LIKE_PREDS NULL_PREDS TIMESTAMP
---------- ---------- -------------- -------------- ----------------- ----------- ---------- ---------- ---------
93264 1 1 0 0 0 0 0 25-APR-201.3 如何选择直方图类型
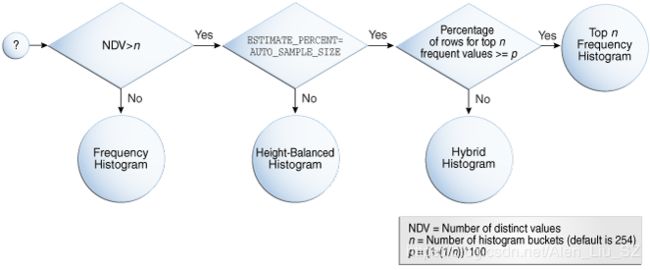
前面讲过,直方图有多种类型,那么创建直方图时,数据库如何选择直方图的类型呢?这里有几个参考变量:
- NDV:表示列的不同值的数量;
- n:表示直方图桶(buckets)的数量,默认时254;
- p:表示内部百分比阈值,等于(1-(1/n))*100;
- DBMS_STATS中estimate_percent参数是否设置为auto_sample_size(默认值)。
下图展示的是直方图创建时的决策树:
2 直方图基数算法
对于直方图,基数的算法取决于端点数和值等因素,以及列值是否受欢迎。
2.1 端点编号和值(Endpoint Numbers and Values)
端点编号是唯一标识桶的编号,在频率和混合直方图中,端点编号是当前桶和之前桶中包含的所有值的累计频率,例如:端点编号是100的桶表示当前桶和以前所有桶的值的总频率是100,在高度平衡的直方图中,优化器按顺序给桶编号,从0或1开始。在所有情况下,端点编号就是桶号。
端点值是桶中值范围内的最大值,例如,如果一个桶只包含52794和52795,那么端点值是52795。
2.2 受欢迎和不受欢迎值(Popular and Nopopular Values)
直方图中某个值的受欢迎程度会影响基数估值算法,具体如下:
- 受欢迎值:受欢迎值出现在多个桶的端点值,优化器通过检查某个值是否是桶的端点值来确定该值是否受欢迎,如果是,那么对于频率直方图,优化器将从当前桶的端点数减去前一个桶的端点数,混合直方图存储了每个端点的信息,如果这个值大于1,那么该值是受欢迎的。对于受欢迎的值,优化器通过下面的公式计算基数估计:cardinality of popular value = (num of rows in table) * (num of endpoints spanned by this value / total num of endpoints);
- 不受欢迎值:所有不是受欢迎的值都是不受欢迎的值,对于不受欢迎的值,,优化器通过下面的公式计算基数估计:cardinality of nonpopular value = (num of rows in table) * density。
2.3 桶压缩(Bucket Compression)
在某些情况下,为了减少桶的总数,优化器将多个桶压缩到一个桶中,例如,下面的频率直方图表示第一个桶数是1,最后一个桶数是23:
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792
6 52793
8 52794
9 52795
10 52796
12 52797
14 52798
23 52799可以看到,有几个桶“丢失”了,最初,桶2到桶6每个都包含一个值为52793的实例,优化器将所有这些桶压缩到具有最高端点数(桶6)的桶中,该桶现在包含5个实例的值52793,这个值是受欢迎的,因为当前桶和前一个桶的端点数之差为5,因此,在压缩之前,52793是5个桶的端点。下图展示了哪些桶是压缩的,哪些值是受欢迎的:
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792 -> nonpopular
6 52793 -> buckets 2-6 compressed into 6; popular
8 52794 -> buckets 7-8 compressed into 8; popular
9 52795 -> nonpopular 10 52796 -> nonpopular
12 52797 -> buckets 11-12 compressed into 12; popular
14 52798 -> buckets 13-14 compressed into 14; popular
23 52799 -> buckets 15-23 compressed into 23; popular3 频率直方图
在频率直方图中,每个不同的列值对应一个直方图桶,由于每个值都有自己的专用桶,所以有些桶会有很多值,而有些则很少。
3.1 频率直方图满足的条件
当满足下面的条件时,数据库创建频率直方图:
- NDV少于或等于桶数(默认为254);
- DBMS_STATS对应的过程的参数设置为AUTO_SAMPLE_SIZE或指定一个具体的值;
3.2 生成频率直方图
本实验在sh.countries_new的列country_subregion_id产生频率直方图。
1)生成测试数据
SQL> create table sh.countries_new as select * from sh.countries;
Table created.
SQL> select country_subregion_id,count(1) from sh.countries_new group by country_subregion_id order by 1;
COUNTRY_SUBREGION_ID COUNT(1)
-------------------- ----------
52792 1
52793 5
52794 2
52795 1
52796 1
52797 2
52798 2
52799 9
8 rows selected.2)搜集统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SH',
tabname => 'COUNTRIES_NEW',
method_opt => 'for columns country_subregion_id');
end;
/
PL/SQL procedure successfully completed.3)查看列统计信息
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='COUNTRIES_NEW';
COLUMN_NAME NOTES HISTOGRAM
------------------------------ ------------------------------ ---------------
COUNTRY_NAME_HIST STATS_ON_LOAD NONE
COUNTRY_TOTAL_ID STATS_ON_LOAD NONE
COUNTRY_TOTAL STATS_ON_LOAD NONE
COUNTRY_REGION_ID STATS_ON_LOAD NONE
COUNTRY_REGION STATS_ON_LOAD NONE
COUNTRY_SUBREGION_ID FREQUENCY
COUNTRY_SUBREGION STATS_ON_LOAD NONE
COUNTRY_NAME STATS_ON_LOAD NONE
COUNTRY_ISO_CODE STATS_ON_LOAD NONE
COUNTRY_ID STATS_ON_LOAD NONE
10 rows selected.可看到COUNTRY_SUBREGION_ID已搜集了直方图信息。
4)查看直方图信息
select t.endpoint_number, t.endpoint_value
from dba_histograms t
where t.owner = 'SH'
and t.table_name = 'COUNTRIES_NEW'
and t.column_name = 'COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792
6 52793
8 52794
9 52795
10 52796
12 52797
14 52798
23 52799
8 rows selected.5)优化器评估52799的基数
SQL> select count(1) from sh.countries_new;
COUNT(1)
----------
23
SQL> select count(1) from sh.countries_new where country_subregion_id=52799;
COUNT(1)
----------
9cardinality of popular value = (num of rows in table) * (num of endpoints spanned by this value / total num of endpoints)
即:C=23*(9/23)=9
和查询的结果相同
4 最高频率直方图
最高频率直方图是频率直方图的一种变种,它忽略了统计上不重要的不受欢迎的值。
4.1 最高频率直方图满足的条件
如果一小部分值占了大部分行,那么在这一小部分值上创建一个频率直方图是很有用的,即使NDV大于请求的直方图的桶的数量。为受欢迎的值创建一个更高质量的直方图,优化器将忽略不受欢迎的值并创建一个直方图。
当满足下面的条件时,数据库创建最高频率直方图:
- NDV大于直方图桶的数量(默认为254);
- 前n个频率值占用的行数百分比等于或大于阈值p,p等于(1-(1/n))*100;
- BMS_STATS对应的过程的参数设置为AUTO_SAMPLE_SIZE;
4.2 生成最高频率直方图
本实验在sh.countries_new的列country_subregion_id产生频率直方图。
1)生成测试数据
SQL> select country_subregion_id,count(1) from sh.countries_new group by country_subregion_id order by 1;
COUNTRY_SUBREGION_ID COUNT(1)
-------------------- ----------
52792 1
52793 5
52794 2
52795 1
52796 1
52797 2
52798 2
52799 9
8 rows selected.2)搜集统计信息
begin
dbms_stats.gather_table_stats(ownname => 'SH',
tabname => 'COUNTRIES_NEW',
method_opt => 'for columns country_subregion_id size 7 ');
end;
/
PL/SQL procedure successfully completed.
3)查看列统计信息
SQL> select column_name,notes,histogram from dba_tab_col_statistics where owner='SH' and table_name='COUNTRIES_NEW';
COLUMN_NAME NOTES HISTOGRAM
------------------------------ ------------------------------ ---------------
COUNTRY_NAME_HIST STATS_ON_LOAD NONE
COUNTRY_TOTAL_ID STATS_ON_LOAD NONE
COUNTRY_TOTAL STATS_ON_LOAD NONE
COUNTRY_REGION_ID STATS_ON_LOAD NONE
COUNTRY_REGION STATS_ON_LOAD NONE
COUNTRY_SUBREGION_ID TOP-FREQUENCY
COUNTRY_SUBREGION STATS_ON_LOAD NONE
COUNTRY_NAME STATS_ON_LOAD NONE
COUNTRY_ISO_CODE STATS_ON_LOAD NONE
COUNTRY_ID STATS_ON_LOAD NONE
10 rows selected.可看到COUNTRY_SUBREGION_ID已搜集了最高频率直方图( TOP-FREQUENCY)信息。
4)查看直方图信息
select t.endpoint_number, t.endpoint_value
from dba_histograms t
where t.owner = 'SH'
and t.table_name = 'COUNTRIES_NEW'
and t.column_name = 'COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
1 52792
6 52793
8 52794
9 52796
11 52797
13 52798
22 52799
7 rows selected.5 高度平衡直方图(遗留)
在高度平衡直方图中,将列值划分为桶,以便每个桶包含大约相同的数据行。
待续。。。