python爬虫抓取千千音乐网站的歌曲
python是写爬虫最好的、也是最方便的语言,没有之一。在这里我给大家分享我爬取千千音乐网站歌曲的全过程。
整个过程分可为四大步:一、了解爬虫的本质;
二、利用谷歌浏览器分析http请求;
三、写代码前的准备工作;
四、 通过python实现请求;
一、爬虫的本质
既然要写爬虫,我们就得先了解什么是爬虫或者说爬虫的本质是什么。百度百科中给的解释有点生涩难懂,我个人的理解是:爬虫就是 模拟浏览器,访问互联网资源,根据我们自己制定的规则,批量地下载我们所需要的数据的程序。说白了它的本质就是模拟浏览器行为。比如说我们要访问一个网站,首先要输入网址对吧,然后点击各种按钮,登陆的时候要提交我们用户的数据等等,这些全部都是浏览器的行为。所以我们要想写爬虫,就肯定要知道浏览器的工作流程。
二、利用谷歌浏览器分析http请求
打开谷歌的浏览器,输入百度的网址就会展现百度首页这样一个网站,

其实它的背后是浏览器向百度网址https://www.baidu.com/ 发送http请求 ,然后浏览器会从服务器下载数据(如图片或者文字等),并将数据展示给用户。即我们在浏览器上所看到的所有信息都是浏览器从服务器下载得来。也就是说,如果我们想下载数据,我们只需要模仿浏览器向服务器发送http请求。
三、准备工作
对爬虫本质和下载数据http请求有了基础的了解后,接下来为写代码做准备工作。
1. 下载软件
编写python代码有多种软件可供选择,到底要安装哪一个看个人喜好。
① 安装python
具体的安装方法可参考文章,在这里我就不一一赘述了。
https://blog.csdn.net/nerissa_lou/article/details/78300839
②安装pycharm
pycharm是一个比较专业的软件,但是安装和使用较麻烦,具体可参考:
https://blog.csdn.net/yctjin/article/details/70307933?locationNum=11&fps=1
③安装anaconda
我个人偏好用anaconda,它的安装和使用都比较简单,重点是anaconda基本包含了 python要用到的所有库,在使用时不用另外安装可以直接使用。而且在调试代码的时候也 非常方便。
https://blog.csdn.net/u012318074/article/details/77075209
2.安装第三方库
如果安装了anaconda的则不用另外安装第三方库,如果是安装了其他的,则需要另外安装第三 方库。这里需要安装requests模块。
requests安装方法: https://jingyan.baidu.com/article/86f4a73ea7766e37d7526979.html
四、通过python实现http请求
准备工作做好后,可以开始写代码了。三步走:第一步 获取歌曲id
第二步 获取歌曲信息
第三步 下载歌曲
第一步 获取歌曲id
我抓取的是许嵩的歌,那么首先应找到搜索歌曲的http请求。
用谷歌浏览器(推荐用谷歌浏览器,但是也可用Firefox或者IE)打开千千音乐网站并搜索“许嵩”,右击鼠标点击“检查”,打开开发者工具,选择network然后重新加载页面,在Headers中找到url,如图所示
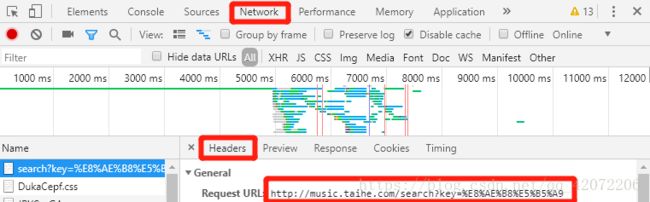
复制url,关键字key后面部分不要,那个其实就是“许嵩”
search_api = 'http://music.taihe.com/search'在Headers中查看请求方式,用该方法发送http请求
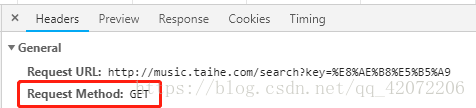
response = requests.get(search_api,params=keyword)点击Element元素查找歌曲id并复制
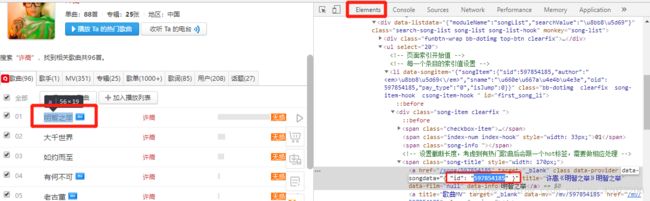
右击鼠标点击“查看网页源代码”,在源代码中找到一段有规律且有格式的歌曲id匹配文本,通过正则表达式获取歌曲id

html = response.text #取出html源代码
ids = re.findall(r'{"sid":(\d+),"',html)第二步 获取歌曲信息
随意选中歌曲播放弹出新的页面,同理使用开发者工具,在所有的请求列表中找到songlink,查看Headers中的url、请求方式和From Data信息
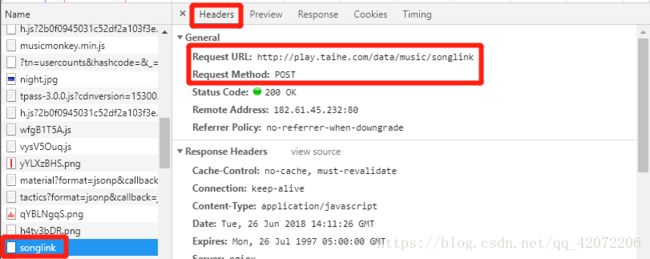
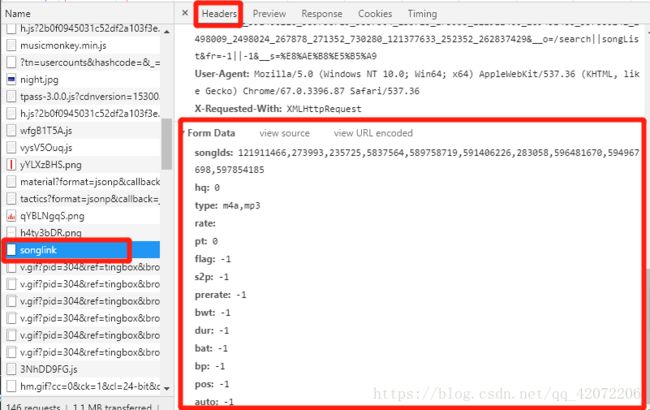
复制url
mp3_info_api = 'http://play.taihe.com/data/music/songlink'然后把数据包装成一个字典
data = {
'songIds': ','.join(ids), #拼接参数,如:'121377633,252352,121911466,269431488,235725,589758719,596481670,597854185,595262'
'hq': 0, 'type': 'm4a,mp3', 'rate': '', 'pt': 0,
'flag': -1, 's2p': -1, 'prerate': -1, 'bwt': -1,
'dur': -1, 'bat': -1, 'bp': -1, 'pos': -1, 'auto': -1,
}第三步 下载歌曲
在preview中查看数据的结构,根据数据结构获取歌曲信息
找到想要的内容,这里我要的是歌曲的歌名、歌词、下载地址以及格式
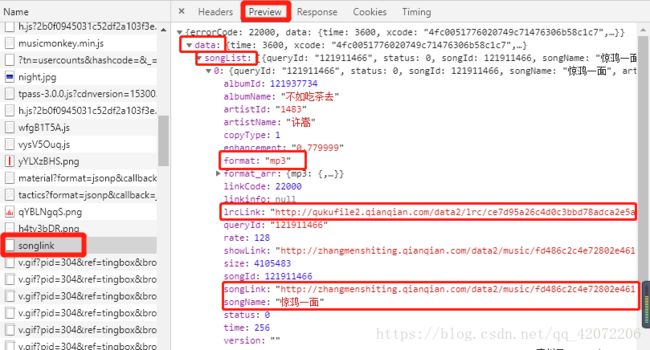
song_info = info['data']['songList'] #根据数据的结构,获取歌曲信息
for song in song_info: #for循环获取歌曲
#根据网页中的数据结构获取信息
song_name = song['songName'] #歌名
song_link = song['songLink'] #mp3地址
for_mat = song['format'] #格式
lrc_link = song['lrcLink'] #歌词地址
#下载歌曲
if song_link: #有可能没有地址
song_response = requests.get(song_link)
with open('%s.%s' % (song_name,for_mat),'wb') as f: #写文件
f.write(song_response.content) #歌曲是二进制信息,所以用content方法
#下载歌词
if lrc_link:
lrc_response = requests.get(lrc_link)
with open('%s.lrc' % song_name,'w') as f:
f.write(lrc_response.text)下面是完整代码
import requests
import re
#第一步 获取歌曲id
search_api = 'http://music.taihe.com/search'
keyword = {'key':'许嵩'} #搜索关键字,传递参数,通过字典构造
response = requests.get(search_api,params=keyword) #发送get请求
response.encoding = 'utf-8' #不用utf-8形式输出会有乱码
html = response.text #取出html源代码
#找一段有规律有格式的歌曲id匹配文本,通过正则表达式获取歌曲id
ids = re.findall(r'{"sid":(\d+),"',html)
#第二步 获取歌曲信息
mp3_info_api = 'http://play.taihe.com/data/music/songlink'
#把数据包装成一个字典
data = {
'songIds': ','.join(ids), #拼接参数,如:'121377633,252352,121911466,269431488,235725,589758719,596481670,597854185,595262'
'hq': 0, 'type': 'm4a,mp3', 'rate': '', 'pt': 0,
'flag': -1, 's2p': -1, 'prerate': -1, 'bwt': -1,
'dur': -1, 'bat': -1, 'bp': -1, 'pos': -1, 'auto': -1,
}
res = requests.post(mp3_info_api,data=data)
info = res.json() #因为返回的数据是json格式,所以直接调用json()方法,转成字典
#第三步 下载歌曲
song_info = info['data']['songList'] #根据数据的结构,获取歌曲信息
for song in song_info: #for循环获取歌曲
#根据网页中的数据结构获取信息
song_name = song['songName']#歌名
song_link = song['songLink']#mp3地址
for_mat = song['format']#格式
lrc_link = song['lrcLink']#歌词地址
#下载歌曲
if song_link: #有可能没有地址
song_response = requests.get(song_link)
with open('%s.%s' % (song_name,for_mat),'wb') as f: #写文件
f.write(song_response.content) #歌曲是二进制信息,所以用content方法
#下载歌词
if lrc_link:
lrc_response = requests.get(lrc_link)
with open('%s.lrc' % song_name,'w') as f:
f.write(lrc_response.text)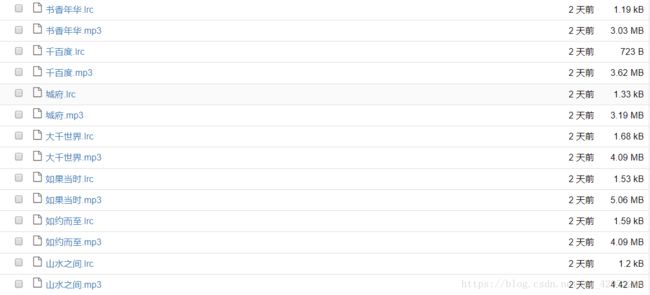
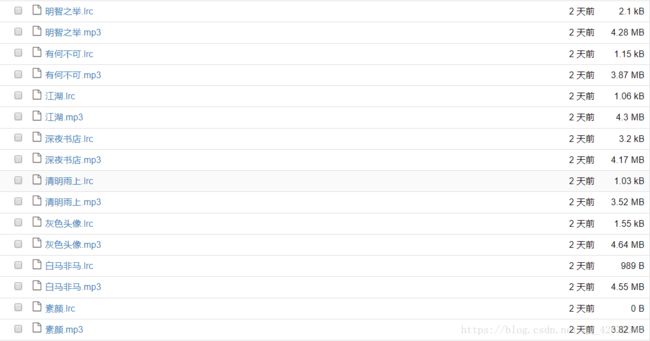
抓取完成。
点击mp3文件即可播放歌曲,lrc文件可查看歌词。