记一次现网k8s中pod连接数据库异常的问题分析及解决实践(tcp_tw_recycle与tcp_tw_reuse内核参数修改)
背景:
在某项目部署测试过程中, k8s中的微服务出现连接集群之外的数据库服务超时,虽然是偶发性,但出现频率较高,已对安全产品按期交付构成较大风险,需要尽快解决。
问题分析:
为方便更加清晰的理解问题,首先介绍下服务整体部署架构。在3台VM虚机中部署k8s集群,在k8s集群内部署安全产品的容器服务,而数据库服务则是部署另外3台VM进行高可用,部署架构图1如下:
 图1 安全服务整体架构图标题
图1 安全服务整体架构图标题
控制台中的日志报错为以下截图2:
 图2 控制台日志报错图标题
图2 控制台日志报错图标题
起初我也认为这是一个简单的数据库连接超时问题,于是首先进行了常规的排查。
1.检查工程的k8s配置文件中db host的配置问题,没有问题;
2.检查网络状态,进入容器中对数据库ip地址进行telnet测试,也是可以正常返回的,没有问题;
3.检查数据库主机是否有对源包进行限制,运维同事反馈并未对安全产品访问做限制,没有问题;
4.检查HikariCP数据库连接池配置,经过日志排查,发现启动的时候连接是没有报错的,且前几次连接都没有问题,超时是出现在几次正常连接后;
5.检查是否存在慢查询和数据库连接数是否正常,一切正常。
定位问题:
经过多轮的检查,并尝试修改数据库连接配置,发现无论对数据库配置连接的参数如何修改,虽然数据库连接日志报错信息发生了变化,但是寻根究底,其本质原因依旧是超时的问题,如下图3。
 图3 控制台日志其他异常报错图题
图3 控制台日志其他异常报错图题
由于所有资源池都使用了相同的标准化k8s环境,导致排查问题时直接忽略了k8s本身,各种尝试未果后我们将目光重新投向了k8s集群本身。
确定是否是k8s集群的问题很简单,将k8s上部署的服务进行停止,不改变工程及配置,在虚机上采用java -jar的方式将服务启动,对出问题的接口进行高频调用测试,没有出现过一次数据库连接超时问题。
紧接着通过在数据库虚机上进行抓包,发现数据库丢包严重。同时发现pod注册在eureka上是pod的ip,而连接数据库和redis以及mq的时候,就是通过NAT转换成node节点的ip了,那么问题极有可能就是出现在k8s的工程连接到数据库虚机的网络方式有问题。
解决问题:
经过定位发现是TCP的连接出现了问题。在TCP连接中为了端口快速回收,会对连接进行时间戳的检查,如果发现后续请求中时间戳小于缓存的时间戳,即视为无效,相应数据包会被丢弃,这样就造成了大量的丢包。
查看数据库主机的内核参数,如下图4,发现net.ipv4.tcp_tw_recycle和net.ipv4.tcp_timestamps参数同时设置为1了,因此将net.ipv4.tcp_tw_recycle设置为0关闭。原来当开启了tcp_tw_recycle选项后,会拒绝非递增请求连接。当连接进入TIME_WAIT 状态后,会记录对应远端主机最后到达节点的时间戳。如果同样的主机有新的节点到达,且时间戳小于之前记录的时间戳,即视为无效,相应的数据包会被丢弃。关闭这个设置后成功解决问题,再也没有出现过超时问题。
在k8s环境中,node节点上的pod网络互联互通是采用网络插件结合etcd实现的。 默认情况下pod访问集群外部的网络走的是对应node节点的NAT规则。在这次连接中,由于在pod内连接数据库经过了一次NAT转换,客户端TCP请求到达数据库,修改目的地址(IP+端口号)后便转发给数据库服务器,而客户端时间戳数据没有变化。对于数据库来说,请求的源地址是node节点IP,所以在数据库看来,原先不同的客户端请求经过NAT的转发,会被认为是同一个连接,加上不同客户端的时间可能不一致,所以就会出现时间戳错乱的现象。这样就会导致后面的数据包被大量的丢弃,具体的表现就是客户端发送的SYN,服务端迟迟无法响应ACK。
原理分析:
问题最终通过修改了内核参数net.ipv4.tcp_tw_recycle解决了,但是问题出现的原因以及问题的解决方案值得我们研究。
其实在文章的一开始的日志截图中,实际上已经可以看出端倪,对于Linux,字段为TCP_TIMEWAIT_LEN硬编码为30秒,对于Windows为2分钟(可自行调整),而我们忽视了这个日志的报错,把它当成了一个普通的工程连接超时问题看待。想要明白问题出现的原因,首先需要明白TCP连接中TIME-WAIT状态,如下图5所示:
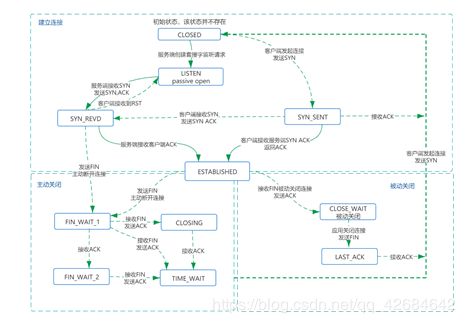 图5 TCP状态机图
图5 TCP状态机图
当TCP连接关闭之前,首先发起关闭的一方会进入TIME-WAIT状态,另一方可以快速回收连接。可以使用ss –tan来查看TCP连接的当前状态。
对于TIME-WAIT状态来说,有两个作用:
- 确保远端(服务端)能够正确的处于关闭状态,如图:
 图6 ACK包异常丢弃图
图6 ACK包异常丢弃图
当最后一个ACK丢失时,远程连接进入LAST-ACK状态,它可以确保远程已经关闭当前TCP连接。如果没有TIME-WAIT状态,当远程仍认为这个连接是有效的,则会继续与其通讯,导致这个连接会被重新打开。当远程收到一个SYN 时,会回复一个RST包,因为这SEQ不对,那么新的连接将无法建立成功,报错终止。如果远程因为最后一个ACK包丢失,导致停留在LAST-ACK状态,将影响新建立具有相同四元组的TCP连接。
2.防止上一次连接中的包,又重新收到,影响新的连接,如图7。
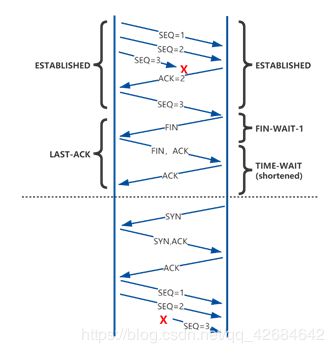 图7 正常连接中,出现了SEQ3异常重新收到图
图7 正常连接中,出现了SEQ3异常重新收到图
防止上一个TCP连接的延迟的数据包(发起关闭,但关闭没完成),被接收后,影响到新的TCP连接。(唯一连接确认方式为四元组:源IP地址、目的IP地址、源端口、目的端口),包的序列号也有一定作用,会减少问题发生的几率,但无法完全避免。尤其是较大接收windows size的快速(回收)连接。
那大量堆积的TCP TIME_WAIT状态在服务器上会造成什么影响呢?
- 占用连接资源
TIME_WAIT占用的1分钟时间内,相同四元组(源地址,源端口,目标地址,目标端口)的连接无法创建,通常一个ip可以开启的端口为net.ipv4.ip_local_port_range指定的32768-61000,如果TIME_WAIT状态过多,会导致无法创建新连接。
2.占用内存资源
保持大量的连接时,当多为每一连接多保留1分钟,就会多消耗一些服务器的内存。
最后,理解了TIME_WAIT状态的原理就可以很好的解决这个问题了,最合适的解决方案是增加更多的四元组数目,比如,服务器可用端口,或服务器IP,让服务器能容纳足够多的TIME-WAIT状态连接。
在常见的互联网架构中(NGINX反代跟NGINX,NGINX跟FPM,FPM跟redis、mysql、memcache等),减少TIME-WAIT状态的TCP连接,最有效的是使用长连接,不要用短连接,尤其是负载均衡跟web服务器之间。在服务端,不要启用net.ipv4.tcp_tw_recycle,除非你能确保你的服务器网络环境不是NAT。在服务端上启用net.ipv4.tw_reuse对于连接进来的TCP连接来说,是没有任何效果的。
拓展:
关于内核参数的详细介绍可以参考官方文档。这边简单说明下tcp_tw_recycle参数,在RFC1323中有这么一段描述:
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
其大致意思就是TCP有一种行为,可以缓存每个连接最新的时间戳,后续请求中如果时间戳小于缓存的时间戳,即视为无效,相应的数据包会被丢弃。
1.net.ipv4.tcp_tw_reuse
RFC 1323 实现了TCP拓展规范,以保证网络繁忙状态下的高可用。除此之外,另外,它定义了一个新的TCP选项–两个四字节的timestamp fields时间戳字段,第一个是TCP发送方的当前时钟时间戳,而第二个是从远程主机接收到的最新时间戳。启用net.ipv4.tcp_tw_reuse后,如果新的时间戳,比以前存储的时间戳更大,那么linux将会从TIME-WAIT状态的存活连接中,选取一个,重新分配给新的连接出去的TCP连接。
2.net.ipv4. tcp_tw_recycle
这种机制也依赖时间戳选项,这也会影响到所有进来和出去的连接。Linux将会放弃所有来自远程端的Timestamp时间戳小于上次记录的时间戳(也是远程端发来的)的任何数据包。除非TIME-WAIT状态已经过期。当远程端主机HOST处于NAT网络中时,时间戳在一分钟之内(MSL时间间隔)将禁止了NAT网络后面,除了这台主机以外的其他任何主机连接,因为他们都有各自CPU CLOCK,各自的时间戳。
在Linux中是否启用这个行为取决于tcp_timestamps和tcp_tw_recycle,因为tcp_timestamps缺省就是开启的,所以当tcp_tw_recycle被开启后,这种行为就被激活了。
简单来说就是,Linux会丢弃所有来自远端的timestamp时间戳小于上次记录的时间戳(由同一个远端发送的)的任何数据包。也就是说要使用该选项,则必须保证数据包的时间戳是单调递增的。同时从4.10内核开始,官方修改了时间戳的生成机制,所以导致 tcp_tw_recycle 和新时间戳机制工作在一起不那么友好,同时 tcp_tw_recycle 帮助也不那么的大。此处的时间戳并不是我们通常意义上面的绝对时间,而是一个相对时间。很多情况下,我们是没法保证时间戳单调递增的
tcp_tw_recycle 选项在4.10内核之前还只是不适用于NAT/LB的情况(其他情况下,也非常不推荐开启该选项),但4.10内核后彻底没有了用武之地,并且在4.12内核中被移除。
总结:
总体来说,这次数据库连接超时故障本身并没什么高深之处,不过拔出萝卜带出泥,在过程中牵扯的方方面面还是值得我们一起研究学习的,因此分享出这篇文章,也帮助遇到此类问题的小伙伴提供一个解决问题的思考方向。
(本文已在公众号发布,转载请注明出处。)
参考文档:
https://tools.ietf.org/html/rfc1323
https://www.jianshu.com/p/25e99b2d1956
https://blog.csdn.net/chengm8/article/details/51668992