第36式 CALCULATE的元祖--最细粒度的筛选方式(高级)
请参阅《DAX圣经》第5章相关部分。
这部分本来是(8)的后半部分,因为提示字数超过指定数,不得已将其分成了两部分。
在第35式中,唯一的问题是:CALCULATE()需要一个返回单个值的表达式,这一次,我们希望返回整个表。因为,我们需要列表作为筛选函数的参数。幸运的是,有CALCULATE函数的一个伙伴可以,它不是返回一个值,而是返回一个表。这就是CALCULATETABLE,接下来将介绍。
1、使用CALCULATETABLE
CALCULATETABLE的工作方式与CALCULATE相同。唯一的区别是结果的类型:CALCULATE计算返回标量值,而CALCULATETABLE计算表表达式并返回表。下一个公式完全符合我们的需要:它删除了品牌和颜色列上的两个筛选器,而其他列上的筛选器仍保持筛选功能。
[CalcTable Version] :=
CALCULATE(SUM( Sales[SalesAmount] ),
FILTER(
CALCULATETABLE(Product,ALL( Product[Brand] ),ALL ( Product[Color] )),AND(Product[Brand] ="TailspinToys",Product[Color] ="Black")))
使用CALCULATETABLE计算出上图中的正确的值,这个等价的结果是很重要的,因为知道了正确的技术:需要将布尔筛选器转换成等效的列表筛选,这将极大地帮助你获得更复杂的条件。例如,如果想表示OR条件而不是AND条件,那么,需要采用这种技术。
例如,如果要计算所有brands 和colors--品牌和颜色的总和,条件是:该品牌可以是Tailspin Toys,或者Color-颜色为黑色的(OR条件),则需要使用CALCULATETABLE来定义它,如下代码所示:
[CalcTable Version OR] :=
CALCULATE(SUM( Sales[SalesAmount] ),
FILTER(
CALCULATETABLE(Product,
ALL(Product[Brand] ),ALL (Product[Color] )),
OR(Product[Brand] ="Tailspin Toys",Product[Color] ="Black"))
实际上:使用CALCULATETABLE方式可以方便地从Tailspin Toys和Color--品牌和颜色列中去除筛选器,而保持所有其他筛选器不受影响。
一方面,简单的使用CALCULATE就可以很容易地解决多列表的条件,因为用CALCULATE能将所有的AND筛选器参数放入其中。
另一方面,实际的使用中,不同列之间的组合条件要复杂得多,不能只依赖于AND和CALCULATE,这需要手工编写复杂的DAX代码。值得注意的是,作为替代公式,还可以使用下面的代码,它使用了ALL()函数直接引用两个列:
[ALL Version OR] :=
CALCULATE(SUM( Sales[SalesAmount] ),
FILTER(ALL ( Product[Brand], Product[Color] ),
OR(Product[Brand] ="Tailspin Toys",Product[Color] ="Black" ) ))
这种形式更优雅,即使在开始时,它不是很直观。你需要慢慢地习惯它。
2、CALCULATE的筛选转换
我们之前曾说到:CALCULATE会执行另一项非常重要的任务:CALCULATE将任何现有的行筛选转换为等效的列表筛选。
为了进一步再次说明这种行为,我们创建一个包含CALCULATE表达式的计算列。因为计算列总是存在行筛选,因此这将触发筛选转换。例如,让我们再次回忆一下相关的知识点:假如在Product表中定义一个计算列,其中包含以下DAX表达式:
Product[SumOfUnitPrice] =SUM( Product[Unit Price] )
这个公式你已经再熟悉不过:它计算了所有产品的、所有价格的值。表达式是在隐式行筛选中进行计算的,没有显式列表筛选,因此它返回表中所有产品的总价,而不是对其进行定义的产品列表的每行值的价格,即返回单位价格的总金额。
现在,我们知道,这需要增加函数 CALCULATE来显示化列表处理:
Product[SumOfUnitPriceCalc] = CALCULATE(SUM( Product[Unit Price] ) )
我们也许还在惊讶:这是怎么啦?CALCULATE可以使用一个表达式参数计算?原因是:使用CALCULATE,行筛选已转换为筛选器筛选,从而更改了结果(可以理解为:内部引擎以列表形态一次性计算出结果,关于内部引擎的问题,容后再说)。
当第一次观察到这种行为时,你很难理解CALCULATE为什么会执行了列表筛选转换。在经过这么多的说明后,你将开始使用此功能,之后也会慢慢喜欢它,因为使用它将能够编写强大的公式。
此外,需要提醒的是,筛选的语境转换还有另一个非常重要的副作用。你可能还记得,列表筛选和行筛选在关系方面的行为方式不同:行筛选不会通过关系自动传递,而列表筛选则会在关系之间传递。因此,当发生筛选转换时,列表筛选将自动传递到相关的关系列表,让我们仍然在产品表中,创建两个新的计算列:
Product[SalesAmount] = SUM( Sales[SalesAmount] ) Product[SalesAmountCalc] = CALCULATE(SUM( Sales[SalesAmount] ) )
这两个计算的结果显然是不同的。由CALCULATE定义的筛选转换会影响所有关系列表的筛选。[SalesAmount] 列将包含所有销售的总计(只有一个值),而[Sales AmountCalc]则包含当前所有产品行的销售。这时,“CALCULATE() ” 和行筛选在“Product”--产品列上的相关筛选转换的存在,将筛选器传递到“销售”表(传递的是由CALCULATE()转换后的列表筛选,SUM( Sales[SalesAmount] )的每一次结果都将被转换为引擎能识别的列表形态),因而显示每个产品的销售情况。
请注意,在执行CALCULATE()时,所有当前活动的行筛选都会发生筛选转换(每一个行行为都将被转换),而且这种行为不能避免(下面将介绍避免的方法)。实际上,在不同的表上可能存在一个或多个行筛选。例如,如果在Product表中创建的计算列中使用AVERAGEX迭代Product--客户,那么,对于两个行筛选:Product和Customer都会发生筛选转换,并且Sales表将同时接收这两个筛选器。请考虑以下表达式:
Product[SalesWithSUMX] =
AVERAGEX(Customer,CALCULATE(SUM( Sales[SalesAmount] ) ) )
该公式计算客户购买该产品的平均金额(不是指平均价格,而是总支出的平均值)。在一个列表筛选中执行SUM计算:只显示当前客户的销售(由AVERAGEX迭代)和当前产品的销售(通过CALCULATE()引用的值列表的列表计算迭代)。当然,公式不能省略CALCUALTE:
Product[SalesWithSUMX] =AVERAGEX(Customer,SUM( Sales[SalesAmount] ) )
这里有一种简单的方法来记住这个规则:在该CALCULATE()中没有行筛选(或者说只有隐式的行筛选),只有列表筛选(转换后的显式列表)存在。因为DAX公式必须同时具有值列表(行)筛选与列表筛选。
或者干脆理解为:CALCULATE(),比如CALCULATE(SUM( Sales[SalesAmount] ) ) 是引用一个列表(无论是值列表还是列表,统统视为列表!)计算,而不是定义一个值列表,也就是说,CALCULATE()是不需要你操心其行行为的,因为有CALCULATE存在,就有隐式的行行为!)。
更实际的,你无须理解那么多,作为一种“投机取巧”:在你考虑或纠结是使用CALCULATE(SUM( Sales[SalesAmount] ) ) 以及该形态的[度量](作为列表被引用),还是使用定义的SUM( Sales[SalesAmount] )时,总使用前者就好!现在,下面的这两个公式哪一个是对的?是不是很容易就知道了?要是以前,你会很纠结或者迷茫。虽然我们可以直接给予你答案,但这其中的说明过程很重要。
Product[SalesWithSUMX] =AVERAGEX(Customer,SUM( Sales[SalesAmount] ) )
Product[SalesWithSUMX] =AVERAGEX(Customer,
CALCULATE(SUM( Sales[SalesAmount] ) ) )
注意:为了以示区别:
1、我们通常所指的行筛选是指我们定义的值列表筛选(显式行筛选),列表筛选为引用的列表(显式列表筛选),而那些不需要我们操心(定义或引用)引擎能自动完成的行为(无论行行为还是列表行为)都称为隐式的行行为或列表行为(隐式行筛选和隐式列表筛选);
2、我们将非隐式筛选器称为显式筛选器,或者直接称为:常规筛选器。这样做的唯一目的是在需要时能区分显式筛选和隐式筛选,以掌握它们的不同之处。虽然通常情况下,是不需要考虑隐式的行为的(那是内部引擎的事情)。
但在解释某些更复杂的DAX行为,以及运用这些行为书写DAX解决一些复杂的业务逻辑时却相当有用。比如接下来的以ALLSELECTED函数开始的终极列表筛选问题,如果不理解或不接受隐式和显式的概念,将很艰难。
在最新的SQLBI关于ALLSELECTED的博文介绍中,意大利的大师主动就这个问题道歉:为在《DAX圣经》中关于ALLSELECTED函数讲解中的某些不适当(错误)定义。并首次提出隐式行筛选的问题。(当时化了整整几十页的说明文字也没有说清楚,应为没有引入隐式的概念。)

大致的意思是:如果您已阅读第一版“DAX权威指南”,请将本文内容作为对该书的错误评论的修正。 事实上,我们在这里的表述将比在写那本书时更精确和清晰。 我们为此道歉。

3、度量里的筛选转换
关于隐式筛选的问题,很多人对我提出该说法有不同的想法,或者说我曲解了意大利人的隐式定义。我很理解。如果你坚持看完我的系列啰嗦,最后我们将以相当多的案例篇幅来说明这个问题,现在还不是争论的时候。这也说明筛选转换在DAX里的重要性。
我们说,理解筛选转换非常重要,因为这是DAX的另一个隐式的方面。到目前为止,我们一直在CALCULATE中使用函数引用列或定义值列表来编写表达式。但是,你还可以编写包含度量值调用的表达式。如果从计算列中调用度量值,会发生什么情况?
后者为更普遍的情况。例如,可以定义一个SumOfSalesAmount度量:
[SumOfSalesAmount] :=SUM( Sales[SalesAmount] )
然后,可以使用这个更简单的代码定义SalesWithSUMX计算列:
Product[SalesWithSUMX] =SUMX(Customer, CALCULATE([SumOfSalesAmount]))
CALCULATE的存在意味着执行了筛选转换。问题是,每当从另一个表达式中调用度量值时,DAX将自动调用CALCULATE封装内部的度量。也就是说:任何一个度量被引用时,都可以看作是一个省略了CALCULATE()的显式列表。换句话说:任何一个度量都可以作为显式化的列表被引用。因此,前面的表达式具有与以下表达式相同的行为:
Product[SalesWithSUMX]=SUMX(Customer, [SumOfSalesAmount])
这一次,在公式中看不到CALCULATE,但是由于DAX添加CALCULATE自动计算,所以会发生筛选转换。这就是为什么总是编写DAX时需要区分列和度量的代码是非常重要的原因。写DAX使用的事实上的标准是:
避免将表名放在度量之前,并且总是在列前面加上表名。
事实上,在以前的公式里,例如[SumOfSalesAMounp]之前没有表名,这表明它是一个度量,因此,知道发生了筛选转变。
自动筛选转换使编写使用迭代来执行复杂计算的公式变得非常容易。话虽如此,我们需要一段时间才能熟悉阅读和使用它。例如,如果只想计算购买量超过总平均值的客户的销售额之和,可以编写如下度量:
[SalesMoreThanAverage] :=
VAR AverageSales = AVERAGEX( Customer,[SumOfSalesAmount] )
RETURN
SUMX(Customer,
IF([SumOfSalesAmount] > AverageSales,[SumOfSalesAmount]))
在这个代码中,我们使用[SumOfSalesAmount]作度量为不同行筛选中。在VAR定义的变量中,使用它来计算客户销售的平均值,而在使用SUMX的迭代中,我们使用它来检查当前客户的销售额与先前存储在变量中的平均值作比较。
基于VAR的语法更易于读取和维护(也可能更快)。但是,重要的是要理解针对不同行为来使用不同的语法,不管使用的DAX版本如何,如果不理解并掌握自动筛选转换,就没有完全了解CALCULATE。那么,可能会花费大量的时间来查看公式。这与使用VAR无关。
在引用度量值时,筛选转换总会自动发生,而且无法避免。这意味着在调用度量值时需要避免筛选转换时,唯一方法是扩展其代码。例如,假设以不同的方式编写了前面的代码。而不是使用VAR变量,定义一个名为[AverageSales]的度量,它表示客户的平均销售额,如下所示:
[AverageSales] : = AVERAGEX( Customer,[SumOfSalesAmount] )[SalesMoreThanAverage]:= SUMX(Customer,
IF( [SumOfSalesAmount] > [AverageSales],[SumOfSalesAmount]))
在突出显示的行中,使用[AverageSales]计算客户的平均销售额。问题是--这一次--在(SUMX)迭代中调用了一个度量,这会发生筛选转换。因此,[AverageSales]的结果将不是针对所有客户的平均销售,而是正在迭代的客户的平均销售额。因此,测试失败,度量返回空白。
最简单的理解:度量一旦被引用,总是以一个显式列表状态在, [SumOfSalesAmount] > [AverageSales]相当于“列表=列表”,这是不允许的,或者说都是全集的列表与列表间的比较,毫无意义。这里表现为:IF的真正条件并没有执行或不起作用。
如果要避免这种筛选转换,则需要扩展度量的代码(即函数定义的值列表),也就是前面所说的“列表=值列表”的方式。如以下示例所示:
[SalesMoreThanAverage] :=
SUMX(Customer,
IF([SumOfSalesAmount]>AVERAGEX( Customer,
[SumOfSalesAmount]),[SumOfSalesAmount]))
将单独的度量引用替换为扩展代码方式(即函数定义的计算式)后,[SalesMoreThanAverage]将返回正确的结果。
我们发现,如果按照DAX的原理来理解这些公式会比较难于理解,我们的目的是运用,因而借用“引用列表”与“定义值列表”的概念则相当容易,你只需要知道何时使用它们以及在什么情况下使用它们。
此外,值得注意的是,公式在Customer表上有两个嵌套的行筛选和三个度量调用。其中两个通过SUMX计算当前迭代客户的销售额,另一个(在AVERAGEX内部)通过AVERAGEX计算当前迭代客户的销售。整个IF函数是一个布尔值列表,用以作为SUMX遍历Customer表的计算条件。

上面图示中的两个行行为,是“X”类聚合函数的对第一参数--表的所谓“遍历表”功能,Customer表分别被两个函数引用(被遍历了两次).
我们将在接下来的内容中广泛使用这些特性,届时我们将开始编写复杂的DAX代码来解决特定的场景。在接下来的一式中,可能会更利于理解。
第37式 CALCULATE的筛选转换(加强)
1、筛选转换后的当前列值是多少?
筛选转换将行筛选转换为等效的列表筛选。这一说法需要作出一些澄清:
一方面,行筛选始终只包含一行,而CALCULATE在筛选转换后创建的列表筛选则可能包含多个行:
另一方面,由CALCULATE创建的筛选器可能会影响一个或多个列,这取决于列表结构(关系)。
1)如果表中有一个在模型里被定义的主键,那么,CALCULATE将创建一个列表筛选,并只筛选该主键。事实上,这样的列表筛选包含一个行,它由主键唯一标识。值得记住的是:可以通过使用现有表的元数据或创建列表之间的关系来定义主键。
在这两种情况下,筛选转换都将筛选单个的列,而且由于该列是表的标识主键列,因此将筛选主键唯一行对应的单个行。
2)如果表没有主键,则筛选转换将在表的所有列上创建一个筛选器。它可能导致包含一行或多行的筛选器,这取决于列表的内容。
实际上,如果所有的行都不同,那么,筛选器筛选将唯一地标识一行。但是,如果表中有相同的行,那么,所有行都将包含在该列表筛选中。在前面已提示的以下示例中,[Wrong Sales]和[Correct Sales]会导致返回不同的值:
[Sales Amount] := SUMX( Sales,Sales[Quantity] * Sales[Unit Price] )
[Wrong Sales]: = SUMX( Sales,[Sales Amount] )
[Correct Sales]: = SUMX( Sales,Sales[Quantity] * Sales[Unit Price] )
事实上,[Wrong Sales]会迭代Sales--销售表,对于每一行,它计算所有相同行的[SalesAmount] --[销售金额](即每个唯一值的行的计算),而[Correct Sales]则计算每一行(不考虑是否重复)的金额。因此,如果销售中有多个相同(重复的行)的行,则[Wrong Sales]会导致得出更高的值。
在处理维度表时,这通常不是问题,因为维度表总是存在唯一值的主键。在这种情况下,与当前行相同的每个唯一行是该行本身。那么,关于事实表或其他用于计算的表呢?……。一般情况下,对于那些没有主键的表(通常是事实表或用于计算的表),都需要考虑可能有重复的行(事实上也总是如此),否则可能会得到意想不到的结果。
2、理解筛选转换的计算顺序
根据你已学习到的经验,了解了在Product--产品表中创建的这两个计算列之间的区别:
Product[SumOfUnitPrice] = CALCULATE(SUM( Product[Unit Price]))Product[SumOfAllUnitPrice] = CALCULATE(SUM( Product[Unit Price] ),
ALL ( Product ) )
它们都是计算列,都使用CALCULATE函数功能。因此,两种情况都会发生筛选转换。第一个[SumOfUnitPrice]应该只包含当前行的[Unit Price]-单位价格的值。
但是,[SumOfAllUnitPrice]的值是什么?直观地,因为有一个 ALL(Product),期望它应该包含所有[Unit Price]-单位价格列的总和,这也正是它所计算的。然而,如果遵守到目前为止我们已知的所有规则,就会发现这里总有些不对劲。
因为ALL(Product)的结果返回整个Product表,这有效地从筛选器筛选中删除了任何筛选器。但同时,由于筛选转换,应该筛选Product表,并只使一行可见。如果将这两个条件AND在一起,筛选转换就会有更多的限制,因此,它应该会起作用。那么,为什么结果总是所有单价的总和,而不是当前行的单价?
这是因为,筛选转换创建的列表筛选与CALCULATE()的条件创建的筛选筛选之间具有优先顺序。CALCULATE会先执行筛选转换,然后应用筛选器。因此:
CALCULATE的任何条件都可以覆盖筛选转换创建的筛选器。
这种行为描述它要比使用它更难。上面的两个公式精确地计算了我们在直觉上所期望的结果。然而,重要的是要理解为什么会发生这种情况,更最要的是,被CALCULATE()覆盖的筛选器来自筛选转换(换句话说,筛选器参数稍后才被应用)。
上述公式中,由于ALL ( Product ) 的结果是一个全集的列表,因而筛选并不会起作用(结果与第一个类似公式相同)。但是,如果是ALL ( Product [某列]) ,结果将是一个唯一值的结果表(值列表),筛选将会起到作用。这是我们第二次提高这个区别。
3、定义变量与定义筛选
在变量系列中,我们展示了变量的概念,这个概念是通过使用如下表达式创建的:
VAR Denominator = SUMX( Sales,Sales[Line Amount] - Sales[Line Cost])
VAR Numerator = SUM (Sales[Line Amount])
RETURN
DIVIDE(Numerator , Denominator )
VAR变量可以使代码更方便、更容易阅读,并避免重复相同的子表达式,而且,由于它们对应于处理计算筛选的方式,它们还有另一个非常重要的用途。
实际上:VAR变量是在 DAX定义的当前筛选中被计算,而不是在创建它们的公当前式中计算。即必须 RETURN “取出来”使用。
这个特性对于创建复杂的公式非常有用。在这些公式中,可以引用基于“以前”存在的计算筛选的值。让我们用一个例子来说明。想象一下,我们想要使用一个透视表来显示类别,以及每个类别中的销量高的产品数量。定义该类产品的条件:如果它的销售额超过了这个类别总销售额的10%,那就算是高销量了。
这很容易用变量来计算。此外,使用变量处理会使阅读变得更简单,正如在以下代码中所看到的那样:
[HighSalesProducts] :=
VAR TenPercentOfSales =[SalesAmount] * 0.1
RETURN
COUNTROWS ( FILTER ( Product,[SalesAmount]>=TenPercentOfSales)
这个公式有趣的部分是DAX在筛选器迭代之外计算变量[TenPercentOfSales]。如果[TenPercentOfSales]的计算在筛选器迭代中,它将计算当前迭代产品由于筛选转换而计算销售额的10%,这将使整个度量无法计算其值。
相反,DAX先计算迭代外部的值,然后在内部使用它,从而可以引用当前筛选器筛选之外的表达式的值。这相当于事先定义了一个值列表,然后再引用它作为参数计算(这里是做为布尔值筛选的“列表”="值列表"中的值列表,即通常所说的“当前行”)如果要编写没有变量的相同方式的度量,则应该编写如下表达式:
[HighSalesProductsCalculate] :=
COUNTROWS ( FILTER(Product,
[SalesAmount] >= CALCULATE( [SalesAmount],
ALL(Product),'ProductCategory') *0.1))
最后这一段代码很难阅读,基本上,需要在迭代中重建之前的CALCULATE筛选,这并不是一项容易的任务,即使对于经验丰富的DAX程序员来说也是如此。实际上,这将只在后面的最后关于列表筛选的定义时,了解到前面表达式的细节,我们将最后一次揭示筛选器筛选的所有细节。
如果在阅读前面的示例时,你发现可以使用变量来计算一些内容,比如替代EARLIER(当前行)的筛选计算,那么,我们可以很高兴地称呼你为DAX精英,因为你非常了解DAX的计算+筛选。如果还没有达到这一步,也不要担心。
不可能一开始第一次阅读就能掌握,仍然有很多内容专门讨论这些复杂的主题,这将帮助我们获得掌握计算+筛选所需的技能。
第37式 CALCULATE 列表关系的循环依赖
在设计数据模型时,应该注意一个较为复杂的主题,即公式中的循环依赖关系。虽然我们尽量避免讨论较为复杂的DAX问题,但简单的了解模型中的列表关系间的循环依赖是什么,以及如何在模型中避免循环依赖,很有必要。事实上,实际运用中经常会遇到这些问题。
在讨论循环依赖关系之前,值得讨论的是简单的线性依赖关系。让我们先观察一个具有以下计算列的示例:
Product[Profit] = Product[Unit Price] - Product[Unit Cost]
该计算列依赖于同一Product表的两列:[Unit Price]列与[Unit Cost]列。在这种情况下,我们说:[Profit]利润列取决于[Unit Price]和[Unit Cost]--单价列以及单位成本列。然后,可以创建一个新列,类似于具有以下公式的[profitPct]:
Product[ProfitPct] = Product[Profit] / Product[Unit Price]
显然,同样[ProfitPct]--利润,又依赖于[Profit]和[Unit Price]--利润和价格两列。因此,当DAX计算出Product表中的计算列时,它会识别出,并只在[Profit]之后计算[ProfitPct]。否则,它将无法计算ProfitPct公式的有效值。这是列表产生的顺序,也就是你引用的列表必须事先存在。
循环依赖通常不需要过于去担心它。在DAX内部使用它,可用来检测计算结果的正确顺序。
在具有多个计算列的普通数据模型中,计算的依赖关系变成了一个复杂的形状,但同样,引擎的处理却任然很优雅。
循环依赖关系是在列表出现循环时发生的情况。例如,出现循环依赖的一个明显情况是,如果试图将Profit利润的定义修改为此公式:
Product[Profit] : = Product[ProfitPct] * Product[Unit Price]
因为[Profit]依赖于[ProfitPct]产生,而在这个新的公式中,[Profit]又取决于[ProfitPct],从顺序上来说,该公式引用[ProfitPct]后又回到[ProfitPct],形成一个[ProfitPct]列表闭环。从列表筛选的本质上看,引用某个列表然后其结果又重新回到该列表(相当于列表没有任何变化,开始与结果都是全集的列表状态,这将没有实际意义)。
当然,引用某个列表全集作为某个函数的参数,或参与其他方式的计算都是可以的。但单独引用某个列表,然后兜一圈回来,结果又回到该列表,这就有点玩弄DAX引擎了。所以,DAX很聪明的拒绝执行公式,并显示错误“检测到循环依赖”。
到目前为止,我们已经从公式的角度了解了循环依赖项是什么:也就是说,通过查看表达式,无须关注表内容,你已能检测出依赖性的存在。
然而,还存在更加微妙和复杂的依赖类型,例如,通过使用CALCULATE()或任何表达式内部的筛选器引发的循环依赖。
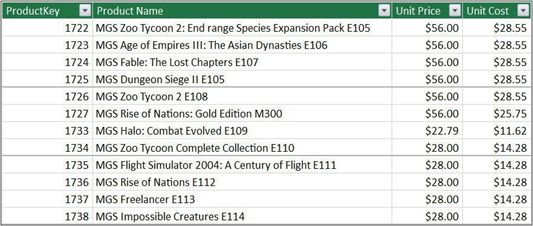
让我们用一个示例演示这个场景,从Product表的一个列表子集(值列表)开始,如图5-18所示。请注意,对于这个例子,我们只加载了Product表,从模型中删除了所有其他列表,以便使场景更加明显。
我们有兴趣理解使用CALCULATE函数的新计算列的依赖项列表,如下所示:
Product[SumOfUnitPrice] = CALCULATE(SUM(Product[Unit Price] ) )
乍一看,该列似乎仅依赖于[Unit Price]列,因为这是公式中引用的唯一列。然而,我们使用CALCULATE将当前行筛选转换为了筛选器筛选。因为我们没有定义与表的任何关系,也没有为它设置主键。所以,当CALCULATE进行筛选转换时,它会筛选表的所有列。
如果我们扩展CALCULATE调用的含义,公式实际上是Product表中的ProductKey、ProductName、UnitCost以及UnitPrice所有这些列中具有相同值的所有行的[value of Unit Price]--单位价格值之和。
如果以这种方式读取公式,那么,现在可以清楚地看到:代码依赖于Products表的所有列,因为新引入的列表筛选将筛选表中的所有列。可以在下图中看到结果表。
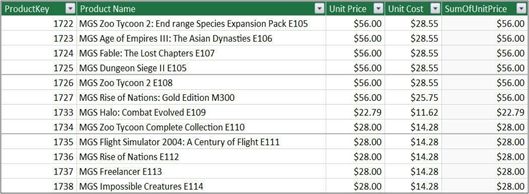
你可以看到[SumOfUnitPrice]的Product表的计算列。可以尝试在同一个表中使用完全相同的公式定义一个新的计算列。考虑使用以下公式定义NewSumOfUnitPrice,该公式与前一个公式完全相同。
Product[NewSumOfUnitPrice] = CALCULATE(SUM(Product[Unit Price] ) )
令人惊讶的是,此时DAX会引发一个错误:检测到了循环依赖关系。这很奇怪,因为我们这时候使用的实际是相同的代码,公式检测到了以前没有检测到的循环依赖关系。这里确实发生了一些变化,这是表中列的数量。如果能够将NewSumOfUnitPrice添加到表中,我们就会达到这样的情况:
这两个公式具有以下含义:[SUMOfUnitPrice]求Product表中与ProductKey、ProductName、Unit Cost以及UnitPrice和NewSumOfUnitPrice中具有相同值的、所有行的、UnitPrice--单位价格值。
[NewSumOfUnitPrice]对Product表中与ProductKey、ProductName、Unit Cost和UnitPrice以及SumOfUnitPrice的所有行的Unit Price--单位价格值。
计算列与表中的任何其他列一样,成为CALCULATE引入的筛选器筛选的一部分。因此,所有计算列都是依赖项--列表的一部分。
如果阅读了前面的定义,很明显,这两个公式之间存在一个循环依赖关系:即NewSumOfUnitPrice与SumOfUnitPrice的互为引用。这就是DAX拒绝创建NewSumOfUnitPrice的原因。理解这个错误并不容易。然而,找到一个解决方案却很简单,即使不是很直观。问题是:
一方面,如果表没有主键,那么任何包含CALCULATE的计算列(或调用任何度量,都会添加自动CALCULATE()显式列表筛选),即从表的所有列(包括计算列)创建依赖项。
另一方面,如果表有一个行标识符(按数据库术语来说,是主键),则情况就不同了:当表中有一个列充当行标识符时,所有包含CALCULATE函数的列都将依赖于该行标识符所在列,从而将它们的依赖项列表缩减为该单个列(主键列)。
在ProductKey列中,ProductKey列可以唯一地标识到表的每一行,因为它是主键。为了将Productkey标记为行标识符,有两个选项:
1)使用ProductKey作为目标列,从任何表创建关系。执行此操作的前提是:确保[ProductKey]列是产品的唯一值;
2) 可以手动设置[ProductKey]列的行标识符的列表 “表行为”属性。
行标识符并不总是单指某一列(某一个字段属性)得到行,有可能为多个甚至需要整个表的列表属性来标示为行标识符。这是我们前面提到的数据模型表的行的概念(数据模型表中横向一列或多列所在的行)。这是DAX列表关系灵活的地方。
这其中任何一个操作都能告诉DAX引擎:该表有一个行标识符。在这种情况下,现在,你可以定义[NewSumOfUnitPrice]列来避免循环依赖关系,因为:使用CALCULATE的计算列仅依赖于新的键--行标识符。
无论哪一种筛选,都需要关系的标识符。其实就是列表先必须具有关系,这是前提。我们把前面那句话再次补充一遍:
任何添加到数据模型中的计算列都成为由CALCULATE引入的筛选器的一部分,而且结果是所有计算列都成为依赖列表的一部分。阅读上述定义,两个公式之间很明确地存在着循环依赖,这恰恰就是DAX拒绝创建NewSumOfListPrice列的原因。
要理解该错误并不容易,但是,找到解决方案却相当简单。问题在于任何包含CALCULATE的计算列(或对任何度量的调用,这些调用都添加了一个自动的CALCULATE),即创建了对表格中所有列的依赖。如果表中有一个行标识符(用数据库术语来说是主键),情况将会有所不同。如果表中有某个作为行标识符的列,那么,包含CALCULATE()的所有列可仅依赖该行标识符,从而降低对某个列的列表依赖。
第38式 CALCULTE 规则 (列表行为方式)
重述CALCULATE工作的方式是很有用的。可以使用这组规则来测试DAX的计算知识:如果能够阅读和理解所有这些规则,那么,就可能会成为真正的DAX大师了。
1、CALCULATE和 CALCULATETABLE是DAX中唯一能直接操作筛选器筛选(行、列筛选)的函数;
有人说,FILTER才是列表筛选,这是两个概念,严格的说:FILTER只是CALCULATE的列表参数,或者是组合列表(提供CALCULATE筛选参数的依据、逻辑条件,其实际是为CALCULATE提供FILTER的两大功能:值列表状态与列表行为);
2、CALCULATE()只有一个必需的参数,即需要计算的表达式。其他参数(也称为筛选参数),它们是(一组)筛选器,它将用于构建新的筛选器筛选:如果只是需要调用CALCULATE来执行筛选转换,则可以省略它们。
3、CALCULATE中的筛选器(值列表)参数定义可以有三种形状:
1)布尔条件,也叫布尔值列表。如Product[Color] = “White”;
2)某一列表的值列表。形式为单列表,如:
ALL(Product[Color]);
VALUES(Product[Color]) 等。
或具有更复杂的表函数--如FILTER 表达式,例如: FILTER(ALL(Product[Color],Product[Color] = “White” )。这里可以看出来,FILTER()的结果是一个值列表。
3)某个表(多个列表)的值列表,如ALL(Product)或更复杂的FILTER条件,如 FILTER(ALL(Product),Product[Color]= “White”。由于FILTER引用的是ALL(Product)(Product表的全部列表),其结果也将是Product表的全部这些列表的列表子集。
使用 1)或 2)的形态写的条件只能在一列上运行。使用 3)形态编写的条件可以在任意数量的列上工作。
CALCULATE中的所有筛选器参数都是独立(单线程)计算的,然后将这些筛选及逻辑条件集聚在一起。最后用于确定新创建的筛选器筛选。
CALCULATE的筛选器参数(从第二个参数开始)都是在原始的列表筛选中计算的,它们可以缩小、扩展或替换计算列表的范围。
其实,更好、更易于理解的表述:所谓缩小、扩展或替换等说话,统一为“当前列表”或产生了新的列表集。
例如,当使用直接布尔表达式作为参数时,CALCULATE将替换原始筛选器筛选,而当传递一个在表上使用筛选器的表达式时,CALCULATE会考虑原始筛选筛选。CALCULATE的第一个参数(要计算的表达式)是在新创建的筛选器筛选后的结果中计算的。
而且,我们再次提示:在CALCULATE的筛选转换以及筛选参数之间存在优先顺序。即 CALCULATE在执行筛选转换之后应用筛选器。因此,筛选器可以覆盖转换已创建的筛选。
第39式 CALCULATE 的列表筛选(高级)
在前面,我们介绍了列表筛选,知道如何引用列表与定义值列表创建DAX的筛选计算。到目前为止,你已经学会了如何使用它们来定义一些简单的计算公式。
然而,前面所有关于“当前列表筛选”的定义都是不完整的,或者更确切地说,只是当前列表筛选最初的大概意思。
为了能继续进行更复杂的计算,并充分了解DAX计算表达式是如何计算的,我们需要进化到下一个级别,并深入了解计算列表筛选的工作方式以及它们是如何交互的。
在本部分中,将揭示DAX计算筛选的所有复杂性,并展示多个错误案例的表达式的示例,这些在实际运用中可能会出现的错误示例,只是因为你还不完全了解它们的工作方式的缘故。一门语言的学习,并不是一件容易的事。
这一部分非常复杂。尽管如此,如果你想更充分了解DAX并学习更多的知识。那么,学习这些详细的看起来较复杂的内容是必须的。如有必要,你需要多读一遍或多遍该部分的内容。
我们将在后面的内容中介绍列表筛选的一些复杂场景。如果你想了解它到底对于你有多难,你可以试着读完下一部分,很可能你需要回到这里继续阅读。
为便于使用实例说明,我们将开始涉及部分重要的DAX函数的功能学习及运用。其实还是那句话:我们不希望把稍难一些的DAX知识放在靠前的部分来讲。因为到目前为止,列表筛选的话题基本上已接近尾声。
这部分难于理解的复杂部分也是水到渠成,在接近40式时,列表筛选的话题基本结束,接下来是DAX计算的话题,也就是使用函数引用列表以及定义值列表创建DAX计算。这也将作为与随后的综合运用部分的衔接。
这一式也将放于下一部分的系列中开始。