Pandas,数据处理的好帮手!

最近做可视化视频,在处理数据的时候遇到了一些问题。
所以就来总结一下,也给大家一个参考。
1. pandas.pivot_table
数据透视表,数据动态排布并且分类汇总的表格格式。
我的理解就是可以进行「行列转换」。
比如下面这样的一个转换。
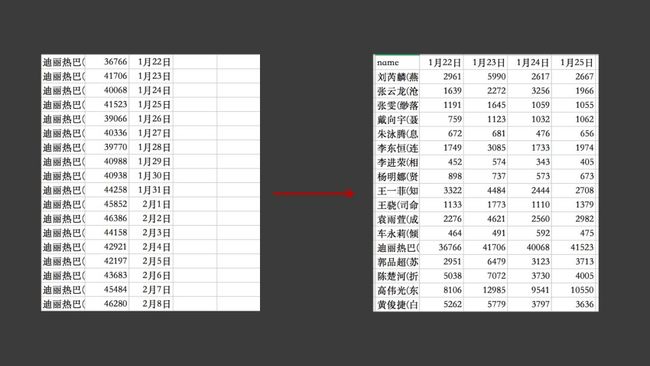
对名字列进行分类汇总,然后将日期那一列转换到行上,具体代码如下。
# 读取数据
df = pd.read_csv('test.csv', encoding='utf-8', header=0, names=['name', 'number', 'day'])
# 数据透视表
df_result = pd.pivot_table(df, values='number', index=['name'], columns=['day'], fill_value=0).reset_index()
# 输出表格
df_result.to_csv('result.csv')
2. pandas.Series.cumsum
获取累加数,可以选择「列累加」,也可以「行累加」。
下面来看一个全明星球员出场次数的统计。

首先添加num列,然后对name进行分类汇总,然后进行「行累加」。
最后便可得到球员历年的数据情况,避免出现数据缺失的情况,具体代码如下。
# 读取数据
df = pd.read_csv('test.csv', encoding='utf-8', header=None, names=['name', 'year'])
# 添加次数列
df['num'] = 1
# 进行行累加操作
df['cumsum'] = df.groupby('name')['num'].transform(pd.Series.cumsum)
df.to_csv('test.csv', encoding='utf-8')
「列累加」,对每年的数据进行累加。
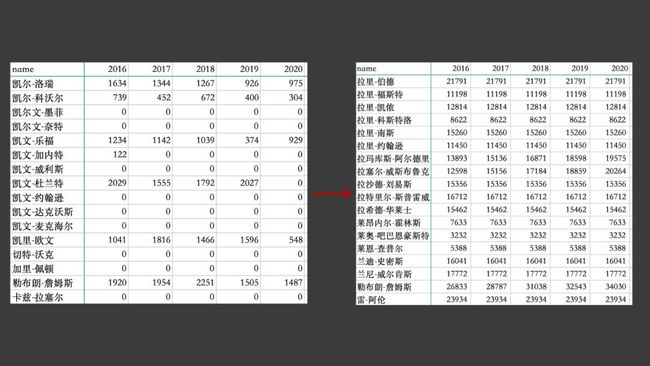
这样就可以得到汇总的数据,具体代码如下。
# 读取数据
df = pd.read_csv('test.csv', encoding='utf-8', header=0)
# 进行列累加
df = np.cumsum(df, axis=1)
print(df)
3. DataFrame.apply
上面的cumsum函数是逐列进行累加的,如果需要总累加,那么便可以使用apply函数。
代码如下,axis可转换轴。
# 进行「行累加」,并且把结果写在最后一行
df.loc['Row_sum'] = df.apply(lambda x: x.sum())
# 进行「列累加」,并且把结果写在最后一行
df['Col_sum'] = df.apply(lambda x: x.sum(), axis=1)
得到结果如下。
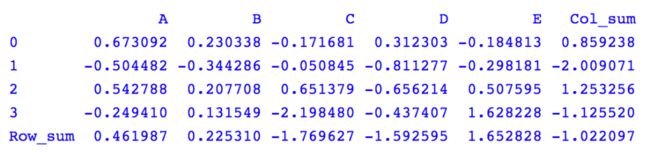
4. 计算分类汇总后的数据总和
# 按name分类汇总并计算总和
df.groupby(['name'])[['name', 'view', 'danmaku']].sum().reset_index())
5. pandas.to_datetime
利用to_datatime函数对字符串进行时间转换,然后以此来筛选数据。
比如要选取特定区间内的数据内容,可以通过如下的代码。
# 读取数据
df = pd.read_csv('test.csv', encoding='utf-8', header=None, names=['name', 'date', 'title', 'like', 'coin', 'sum'])
# 将字符串转换为时间格式
df['date'] = pd.to_datetime(df['date'])
# 时间条件筛选,选取20200114到20200224时间段的数据
df = df[(df['date'] >= pd.to_datetime('20200114')) & (df['date'] <= pd.to_datetime('20200224'))]
print(df)
最后附上小F发现的一个网站——Pandas中文网。

不仅有相关的技术文档。
还有整理好的资源,文章or视频。

网址:https://www.pypandas.cn
阅读原文,即可直接访问咯。
万水千山总是情,点个「在看」行不行。
推荐阅读



··· END ···

支持小F原创 ☟