MySQL慢查询优化(线上环境调优实践)
PS:本文已收录到1.3 K+ Star 数的开源项目《大厂面试指北》,如果想要领取《大厂面试指北》离线PDF版,请关注“大厂面试”公众号领取,或者去点击入群二维码扫码进群或者加我微信ruiwendelll,备注获取资料
项目地址:https://github.com/NotFound9/interviewGuide
入群二维码图片地址:http://notfound9.github.io/interviewGuide/static/49160c2basfdsf.jpeg)
项目截图:
扫码领取《大厂面试指北》PDF资料
文章说明
这篇文章主要是记录自己最近在真实工作中遇到的慢查询的案例,然后进行调优分析的过程,欢迎大家一起讨论调优经验。(以下出现的表名,列名都是化名,实际数据也进行过一点微调。)
本文已收录到1.1k Star数的开源项目《面试指北》中,如果想要了解更多MySQL相关的技术总结,可以看一看,如果对大家有帮助,希望大家帮忙给一个star,谢谢大家了!
《面试指北》项目地址:https://github.com/NotFound9/interviewGuide

为了方便技术交流,分享一些我觉得好的书和自己给大家,及便于大家领取《面试指北》的PDF版本,也建了一个技术交流群,欢迎大家扫码加入!

一.复杂的深分页问题优化
背景
有一个article表,用于存储文章的基本信息的,有文章id,作者id等一些属性,有一个content表,主要用于存储文章的内容,主键是article_id,需求需要将一些满足条件的作者发布的文章导入到另外一个库,所以我同事就在项目中先查询出了符合条件的作者id,然后开启了多个线程,每个线程每次取一个作者id,执行查询和导入工作。
查询出作者id是1111,名下的所有文章信息,文章内容相关的信息的SQL如下:
SELECT
a.*, c.*
FROM
article a
LEFT JOIN content c ON a.id = c.article_id
WHERE
a.author_id = 1111
AND a.create_time < '2020-04-29 00:00:00'
LIMIT 210000,100
因为查询的这个数据库是机械硬盘的,在offset查询到20万时,查询时间已经特别长了,运维同事那边直接收到报警,说这个库已经IO阻塞了,已经多次进行主从切换了,我们就去navicat里面试着执行了一下这个语句,也是一直在等待, 然后对数据库执行show proceesslist 命令查看了一下,发现每个查询都是处于Writing to net的状态,没办法只能先把导入的项目暂时下线,然后执行kill命令将当前的查询都杀死进程(因为只是客户端Stop的话,MySQL服务端会继续查询)。
然后我们开始分析这条命令执行慢的原因:
是否是联合索引的问题
当前是索引情况如下:
article表的主键是id,author_id是一个普通索引
content表的主键是article_id
所以认为当前是执行流程是先去article表的普通索引author_id里面找到1111的所有文章id,然后根据这些文章id去article表的聚集索引中找到所有的文章,然后拿每个文章id去content表中找文章内容等信息,然后判断create_time是否满足要求,进行过滤,最终找到offset为20000后的100条数据。
所以我们就将article的author_id索引改成了联合索引(author_id,create_time),这样联合索引(author_id,create_time)中的B+树就是先安装author_id排序,再按照create_time排序,这样一开始在联合(author_id,create_time)查询出来的文章id就是满足create_time < '2020-04-29 00:00:00’条件的,后面就不用进行过滤了,就不会就是符合就不用对create_time过滤。
流程确实是这个流程,但是去查询时,如果limit还是210000, 100时,还是查不出数据,几分钟都没有数据,一直到navica提示超时,使用Explain看的话,确实命中索引了,如果将offset调小,调成6000, 100,勉强可以查出数据,但是需要46s,所以瓶颈不在这里。
真实原因如下:
先看关于深分页的两个查询,id是主键,val是普通索引
直接查询法
select * from test where val=4 limit 300000,5;
先查主键再join
select * from test a
inner join
(select id from test where val=4 limit 300000,5) as b
on a.id=b.id;
这两个查询的结果都是查询出offset是30000后的5条数据,区别在于第一个查询需要先去普通索引val中查询出300005个id,然后去聚集索引下读取300005个数据页,然后抛弃前面的300000个结果,只返回最后5个结果,过程中会产生了大量的随机I/O。第二个查询一开始在普通索引val下就只会读取后5个id,然后去聚集索引下读取5个数据页。
同理我们业务中那条查询其实是更加复杂的情况,因为我们业务的那条SQL不仅会读取article表中的210100条结果,而且会每条结果去content表中查询文章相关内容,而这张表有几个TEXT类型的字段,我们使用show table status命令查看表相关的信息发现
| Name | Engine | Row_format | Rows | Avg_Row_length |
|---|---|---|---|---|
| article | InnoDB | Compact | 2682682 | 266 |
| content | InnoDB | Compact | 2824768 | 16847 |
发现两个表的数据量都是200多万的量级,article表的行平均长度是266,content表的平均长度是16847,简单来说是当 InnoDB 使用 Compact 或者 Redundant 格式存储极长的 VARCHAR 或者 BLOB 这类大对象时,我们并不会直接将所有的内容都存放在数据页节点中,而是将行数据中的前 768 个字节存储在数据页中,后面会通过偏移量指向溢出页。
(详细了解可以看看这篇文章深度好文带你读懂MySQL和InnoDB)
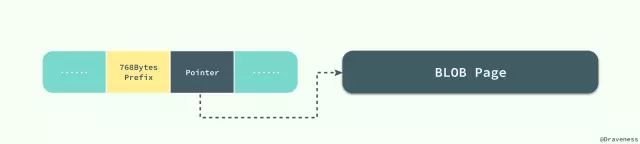
这样再从content表里面查询连续的100行数据时,读取每行数据时,还需要去读溢出页的数据,这样就需要大量随机IO,因为机械硬盘的硬件特性,随机IO会比顺序IO慢很多。所以我们后来又进行了测试,
只是从article表里面查询limit 200000,100的数据,发现即便存在深分页的问题,查询时间只是0.5s,因为article表的平均列长度是266,所有数据都存在数据页节点中,不存在页溢出,所以都是顺序IO,所以比较快。
//查询时间0.51s
SELECT a.* FROM article a
WHERE a.author_id = 1111
AND a.create_time < '2020-04-29 00:00:00'
LIMIT 200100, 100
相反的,我们直接先找出100个article_id去content表里面查询数据,发现比较慢,第一次查询时需要3s左右(也就是这些id的文章内容相关的信息都没有过,没有缓存的情况),第二次查询时因为这些溢出页数据已经加载到buffer pool,所以大概0.04s。
SELECT SQL_NO_CACHE c.*
FROM article_content c
WHERE c.article_id in(100个article_id)
解决方案
所以针对这个问题的解决方案主要有两种:
先查出主键id再inner join
非连续查询的情况下,也就是我们在查第100页的数据时,不一定查了第99页,也就是允许跳页查询的情况,那么就是使用先查主键再join这种方法对我们的业务SQL进行改写成下面这样,下查询出210000, 100时主键id,作为临时表temp_table,将article表与temp_table表进行inner join,查询出中文章相关的信息,并且去left Join content表查询文章内容相关的信息。 第一次查询大概1.11s,后面每次查询大概0.15s
SELECT
a.*, c.*
FROM article a
INNER JOIN(
SELECT id FROM article a
WHERE a.author_id = 1111
AND a.create_time < '2020-04-29 00:00:00'
LIMIT 210000 ,
100
) as temp_table ON a.id = temp_table.id
LEFT JOIN content c ON a.id = c.article_id
优化结果
优化前,offset达到20万的量级时,查询时间过长,一直到超时。
优化后,offset达到20万的量级时,查询时间为1.11s。
利用范围查询条件来限制取出的数据
这种方法的大致思路如下,假设要查询test_table中offset为10000的后100条数据,假设我们事先已知第10000条数据的id,值为min_id_value
select * from test_table where id > min_id_value order by id limit 0, 100,就是即利用条件id > min_id_value在扫描索引是跳过10000条记录,然后取100条数据即可,这种处理方式的offset值便成为0了,但此种方式有限制,必须知道offset对应id,然后作为min_id_value,增加id > min_id_value的条件来进行过滤,如果是用于分页查找的话,也就是必须知道上一页的最大的id,所以只能一页一页得查,不能跳页,但是因为我们的业务需求就是每次100条数据,进行分批导数据,所以我们这种场景是可以使用。针对这种方法,我们的业务SQL改写如下:
//先查出最大和最小的id
SELECT min(a.id) as min_id , max(a.id) as max_id
FROM article a
WHERE a.author_id = 1111
AND a.create_time < '2020-04-29 00:00:00'
//然后每次循环查找
while(min_id min_id LIMIT 100
//这100条数据导入完毕后,将100条数据数据中最大的id赋值给min_id,以便导入下100条数据
}
优化结果
优化前,offset达到20万的量级时,查询时间过长,一直到超时。
优化后,offset达到20万的量级时,由于知道第20万条数据的id,查询时间为0.34s。
二.联合索引问题优化
联合索引其实有两个作用:
1.充分利用where条件,缩小范围
例如我们需要查询以下语句:
SELECT * FROM test WHERE a = 1 AND b = 2
如果对字段a建立单列索引,对b建立单列索引,那么在查询时,只能选择走索引a,查询所有a=1的主键id,然后进行回表,在回表的过程中,在聚集索引中读取每一行数据,然后过滤出b = 2结果集,或者走索引b,也是这样的过程。
如果对a,b建立了联合索引(a,b),那么在查询时,直接在联合索引中先查到a=1的节点,然后根据b=2继续往下查,查出符合条件的结果集,进行回表。
2.避免回表(此时也叫覆盖索引)
这种情况就是假如我们只查询某几个常用字段,例如查询a和b如下:
SELECT a,b FROM test WHERE a = 1 AND b = 2
对字段a建立单列索引,对b建立单列索引就需要像上面所说的,查到符合条件的主键id集合后需要去聚集索引下回表查询,但是如果我们要查询的字段本身在联合索引中就都包含了,那么就不用回表了。
3.减少需要回表的数据的行数
这种情况就是假如我们需要查询a>1并且b=2的数据
SELECT * FROM test WHERE a > 1 AND b = 2
如果建立的是单列索引a,那么在查询时会在单列索引a中把a>1的主键id全部查找出来然后进行回表。
如果建立的是联合索引(a,b),基于最左前缀匹配原则,因为a的查询条件是一个范围查找(=或者in之外的查询条件都是范围查找),这样虽然在联合索引中查询时只能命中索引a的部分,b的部分命中不了,只能根据a>1进行查询,但是由于联合索引中每个叶子节点包含b的信息,在查询出所有a>1的主键id时,也会对b=2进行筛选,这样需要回表的主键id就只有a>1并且b=2这部分了,所以回表的数据量会变小。
我们业务中碰到的就是第3种情况,我们的业务SQL本来更加复杂,还会join其他表,但是由于优化的瓶颈在于建立联合索引,所以进行了一些简化,下面是简化后的SQL:
SELECT
a.id as article_id ,
a.title as title ,
a.author_id as author_id
from
article a
where
a.create_time between '2020-03-29 03:00:00.003'
and '2020-04-29 03:00:00.003'
and a.status = 1
我们的需求其实就是从article表中查询出最近一个月,status为1的文章,我们本来就是针对create_time建了单列索引,结果在慢查询日志中发现了这条语句,查询时间需要0.91s左右,所以开始尝试着进行优化。
为了便于测试,我们在表中分别对create_time建立了单列索引create_time,对(create_time,status)建立联合索引idx_createTime_status。
强制使用idx_createTime进行查询
SELECT
a.id as article_id ,
a.title as title ,
a.author_id as author_id
from
article a FORCE INDEX(idx_createTime)
where
a.create_time between '2020-03-22 03:00:00.003'
and '2020-04-22 03:00:00.003'
and a.status = 1
强制使用idx_createTime_status进行查询(即使不强制也是会选择这个索引)
SELECT
a.id as article_id ,
a.title as title ,
a.author_id as author_id
from
article a FORCE INDEX(idx_createTime_status)
where
a.create_time between '2020-03-22 03:00:00.003'
and '2020-04-22 03:00:00.003'
and a.status = 1
优化结果:
优化前使用idx_createTime单列索引,查询时间为0.91s
优化前使用idx_createTime_status联合索引,查询时间为0.21s
EXPLAIN的结果如下:
| id | type | key | key_len | rows | filtered | Extra |
|---|---|---|---|---|---|---|
| 1 | range | idx_createTime | 4 | 311608 | 25.00 | Using index condition; Using where |
| 2 | range | idx_createTime_status | 6 | 310812 | 100.00 | Using index condition |
原理分析
先介绍一下EXPLAIN中Extra列的各种取值的含义
Using filesort
当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain不会显示的告诉客户端用哪种排序。
Using index
仅使用索引树中的信息从表中检索列信息,而不需要进行附加搜索来读取实际行(使用二级覆盖索引即可获取数据)。 当查询仅使用作为单个索引的一部分的列时,可以使用此策略。
Using temporary
要解决查询,MySQL需要创建一个临时表来保存结果。 如果查询包含不同列的GROUP BY和ORDER BY子句,则通常会发生这种情况。官方解释:”为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。很明显就是通过where条件一次性检索出来的结果集太大了,内存放不下了,只能通过加临时表来辅助处理。
Using where
表示当where过滤条件中的字段无索引时,MySQL Sever层接收到存储引擎(例如innodb)的结果集后,根据where条件中的条件进行过滤。
Using index condition
Using index condition 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
我们的实际案例中,其实就是走单个索引idx_createTime时,只能从索引中查出 满足a.create_time between '2020-03-22 03:00:00.003' and '2020-04-22 03:00:00.003'条件的主键id,然后进行回表,因为idx_createTime索引中没有status的信息,只能回表后查出所有的主键id对应的行。然后innodb将结果集返回给MySQL Sever,MySQL Sever根据status字段进行过滤,筛选出status为1的字段,所以第一个查询的Explain结果中的Extra才会显示Using where。
filtered字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,这个是预估值,因为status取值是null,1,2,3,4,所以这里给的25%。
所以第二个查询与第一个查询的区别主要在于一开始去idx_createTime_status查到的结果集就是满足status是1的id,所以去聚集索引下进行回表查询时,扫描的行数会少很多(大概是2.7万行与15万行的区别),之后innodb返回给MySQL Server的数据就是满足条件status是1的结果集(2.7万行),不用再进行筛选了,所以第二个查询才会快这么多,时间是优化前的23%。(两种查询方式的EXPLAIN预估扫描行数都是30万行左右是因为idx_createTime_status只命中了createTime,因为createTime不是查单个值,查的是范围)
//查询结果行数是15万行左右
SELECT count(*) from article a
where a.post_time
between '2020-03-22 03:00:00.003' and '2020-04-22 03:00:00.003'
//查询结果行数是2万6行左右
SELECT count(*) from article a
where a.post_time
between '2020-03-22 03:00:00.003' and '2020-04-22 03:00:00.003'
and a.audit_status = 1
发散思考:如果将联合索引(createTime,status)改成(status,createTime)会怎么样?
where
a.create_time between '2020-03-22 03:00:00.003'
and '2020-04-22 03:00:00.003'
and a.status = 1
根据最左匹配的原则,因为我们的where查询条件是这样,如果是(createTime,status)那么索引就只能用到createTime,如果是(status,createTime),因为status是查询单个值,所以status,createTime都可以命中,在(status,createTime)索引中扫描行数会减少,但是由于(createTime,status)这个索引本身值包含createTime,status,id三个字段的信息,数据量比较小,而一个数据页是16k,可以存储1000个以上的索引数据节点,而且是查询到createTime后,进行的顺序IO,所以读取比较快,总得的查询时间两者基本是一致。下面是测试结果:
首先创建了(status,createTime)名叫idx_status_createTime,
SELECT
a.id as article_id ,
a.title as title ,
a.author_id as author_id
from
article a FORCE INDEX(idx_status_createTime)
where
a.create_time between '2020-03-22 03:00:00.003'
and '2020-04-22 03:00:00.003'
and a.status = 1
查询时间是0.21,跟第二种方式(createTime,status)索引的查询时间基本一致。
Explain结果对比:
| id | type | key | key_len | rows | filtered | Extra |
|---|---|---|---|---|---|---|
| 2 | range | idx_createTime_status | 6 | 310812 | 100.00 | Using index condition |
| 3 | range | idx_status_createTime | 6 | 52542 | 100.00 | Using index condition |
扫描行数确实会少一些,因为在idx_status_createTime的索引中,一开始根据status = 1排除掉了status取值为其他值的情况。