深度学习语音增强
深度学习语音降噪
我的书:

购买链接:
京东购买链接
淘宝购买链接
当当购买链接
在我的这本书里,详述了基于信号处理的语音降噪(NS)和回声消除(AEC)算法,并对基于监督深度学习降噪介绍了例子;这里对深度学习方法做个补充总结。
传统信号处理方法是经过全人类数百年经验积累而得到的,源于大千世界,因而模型的普适性较强,而监督深度学习依赖监督对象(训练集),由于训练集始终只能是大千世界的一个子集中的子集,所以其普适性和鲁棒性没有基于传统信号处理强,但是由于网络可以很复杂,因而在有些情况下其得到的模型可以比传统信号处理更精确(以计算量为代价),学术界比较好发文章,但是一旦到普适性的商用场景中深度学习方法往往并不是那么适用(场景的普适性+算力+存储资源),所以大部分一线工程师更倾向于信号处理+深度学习两者结合的方法,书中介绍Rnnoise的例子就是这类方法,这类方法对工程是的要求更高。
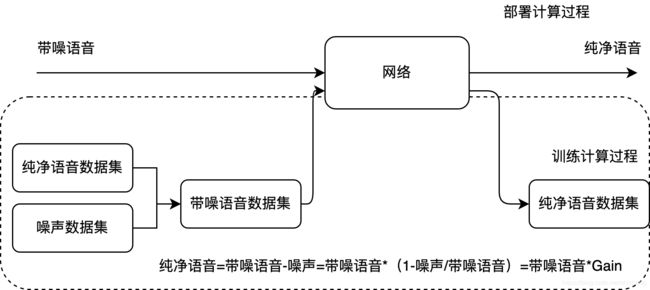
降噪的核心任务如图中地板公式所示,纯净语音=带噪语音-噪声=带噪语音*(1-噪声/带噪语音)=带噪语音*Gain,这样的话,只需要计算Gain值就可以得到纯净语音了,传统信号处理方法通过信号建模的方式获取Gain,监督深度学习方法是通过神经网络计算得到Gain,计算的正确性信号处理方法通过人类数百年的经验积累以及模型调优得到的,监督深度学习方法通过从大量的样本数据集中学习得到,
基于掩码的深度学习法
监督深度学习法在数据集一定时,影响Gain计算准确主要有三个因素,网络模型、声学特征和目标损耗函数;对于只有语音和非语音场景,这时Gain直接蜕化为0,1这两个值,这在信号处理领域,人类通过对耳朵的研究,早就发现人耳有所谓的掩码功能,掩码的意思就是主动将噪声过滤掉(对应于Gain=0),让语音顺利通过(对应于Gain=1),但是实际场景中,有可能语音和噪声是重叠的,所以Gain值应该是介于[0~1]之间更为合理。本篇介绍的深度学习基于T-F masking(时频掩码)思想,《实时语音处理实践指南》一书的波束形成技术就有基于信号处理理论的T-F masking实例。只不过这里使用深度学习方法,通过大量样本数据训练得到这些mask获取的模型。
特征提取
特征提取会影响到训练的目标对象,也就是常说的Label,人们可以很容易获取到纯净语音和噪声数据集,Rnnoise生成带噪语音的方法是书中第九章介绍的二阶IIR滤波器,数据生成之后,由于语音算是平稳性和对人的听觉系统研究发现频域作用不可忽略,所以深度学习法或多或少都会用到STFT变换(书中已介绍),掩码的类型有如下几种:
-
Ideal Binary Mask(IBM)
对于带噪语音,其mask的取值情况如下:

t和f分别表示时间和频率,如果SNR大于本地判决准则(LC,local criterion)则掩码取1,否则取0;
-
Target Binary Mask(TBM)
上述二分类问题有一个缺点,对于时频点(t,f),大于LC准则的点可能含有噪声的,如果mask取1,则这些点的噪声没有去掉,这时有如下准则:
![]()
其中![]() 和
和![]() 分别表示时频点的语音能量和噪声能量,加性噪声场景下,可调参数
分别表示时频点的语音能量和噪声能量,加性噪声场景下,可调参数 通常选0.5,当等于1时,这个准则和经典的维纳滤波法类似。
通常选0.5,当等于1时,这个准则和经典的维纳滤波法类似。
-
Spectral Magnitude Mask(SMM)
类似TBM,SMM通过纯净语音和带噪语音信号的幅度谱获取掩码值。有些文献将这种方法称为Ideal Amplitude Mask(IAM),基本一样的核心思想。
![]()
在频域对带噪语音乘以SMM掩码,然后在逆变换到时域去。
-
Phase-SensitiveMask(PSM)
有研究显示,相位也会影响人的听觉体验,PSM在SMM掩码的基础上加入了相位因素:
![]()
 表示了时频点
表示了时频点![]() 纯净语音相位和带噪语音相位的差异,加入相位信息之后,PSM方法可以获得更高的SNR,因而降噪效果比SMM更好。
纯净语音相位和带噪语音相位的差异,加入相位信息之后,PSM方法可以获得更高的SNR,因而降噪效果比SMM更好。
-
Complex Ideal Ratio Mask(cIRM)
cIRM是复数域理想的掩码,其可带噪语音理想重构纯净语音:
![]()
其中S和Y分别表示纯净语音和带噪语音的STFT结果,“*”表示复数乘,可以得到cIRM如下:
![]()
角标r和i分别表示实部分量和虚部分量。
总结来说,mask可以是频点能量(Rnnoise根据人的心理声学,使用的是Bark子带的能量),频点相位,或者直接复数域,对于直接复数域情况,如果做的是512实数点STFT,则输入特征是256个复数点(512个点),而Rnnoise使用的Bark子带18个子带(16KHz,加上其它的也不过是36个点),两者输入可以看出它们的特征差异比较大,而模型往往为了更具泛化能力,往往又比较大,这就导致受限于资源往往很难实时部署使用;相对而言输入特征和模型较小时,使用一传统信号处理方法进行弥补,如Rnnoise使用了pitch滤波(人的声带和声道决定了人类元音发音必然存在基频和谐振频率这一特点),那么就可以通过这一普适性特点进行处理。
模型
模型可以使用DNN,RNN,CNN都没问题,也可以级联使用以达到最优,相应的资料太多了,工具这块建议掌握Keras和Pytorch两种,在以后的工作和学习中应该够用了。Keras和Pytorch入门比较简单,且两者都在大量使用,花上个把星期应该就可以自己搭建模型了。
数据集
前面提到了数据集获取,网上开源比较多,想要强调的是如何构建更接近真实场景中的数据,前面提到的二阶IIR滤波器是一种方法,此外还有加混响等等,大多数开源ASR识别工程中通常都会带有这部分代码。
其它场景语音增强
前面主要基于深度学习的单通道降噪,此外还有基于深度学习的多通道降噪和回声消除算法;在多通道语音降噪传统方法是麦克风阵列算法,麦克风阵列算法实际上就是空域、频域和时域三维自适应滤波算法,在《实时语音处理实践指南》第七章介绍的T-F masking波束形成方法这里可以借鉴,输入特征选择空域、频域典型特征,然后输入网络中,还是计算最后的Mask值,当然也可以将多路STFT结果直接作为特征输入,但是这样计算量会非常大,意以至于大多数端上设备都无法使用,另外一类就是聚类思想,就是盲源分离,传统信号处理基于高阶统计量,《实时语音处理实践指南》一书已有叙述,深度学习和此类似,可以以高阶统计作为输入特征,训练掩码网络;
另外还有就是回声消除了,《实时语音处理实践指南》一书已叙述信号处理方法,深度学习方法和降噪类似,也是求近端信号的Mask,不过输入特征是Near+Far的组合了,当然难度还是比较大的,所以有些场景是先用《实时语音处理实践指南》一书已叙述信号处理方法进行降噪,这是会发现有残留,这是通过深度学习方法进一步降噪(RES,residual echo suppression)。
基于时域信号的深度学习法
这类方法认为T-F masking依赖STFT变换,这一通用的时域变换方法对于语音分离未必是最优的,其次这种方法很难获得最优纯净语音信号的相位信息,再次要STFT变换本身会引入分辨率和实时性这对矛盾体。所以这类方法摒弃了STFT,直接使用时域信号,用Encoder网络自主学习合适的网络结构,这取代了STFT,如TasNet就是这种思想,不过这种直接时域处理计算量往往一个问题。