Node.js --- 使用koa2编写入门级数据爬虫
在阅读本文前请先确保已安装好node.js(点击此处下载node.js)配置好环境变量相关(点击此处跳转安装配置教程),本文编辑器为vscode(点击此处下载vscode)IDE可根据个人喜好使用,那么下载好运行环境和编辑的IDE之后,就开始了。
node.js + koa2爬虫需要中间件列表
- cheerio: 爬虫数据抓取的中间件
- superagent-charset: 解决爬虫数据中文乱码问题
- koa-router: koa路由,用于根据路由访问对应代码块,逻辑编写等作用(把他理解为像日常API接口就好)
- koa2: 搭建服务器环境等等(详情可点击这里)
了解cheerio
英文:https://github.com/cheeriojs/cheerio
中文:https://cnodejs.org/topic/5203a71844e76d216a727d2e
了解 superagent-charset: https://www.npmjs.com/package/superagent-charset
打开vscode,首先建立一个文件夹在这里我就命名为doujiang,然后再文件夹内建立一个文件,dou.js之后就可以开始了
![]()
在doujiang目录下在vscode中打开终端,快捷键为ctrl + ~(tab上面的那个按键)

进入目录后输入命令进行所需中间件下载
那么了解了所需要下面的东西是什么之后,就进行下载操作吧,如果安装好了淘宝镜像也可以使用cnpm
//一行命令就可以下载全部啦
npm i --save cheerio superagent-charset koa-router koa2
等待所需中间件下载完毕后,就开始编写代码,首先使用require进行引入
const Koa = require('koa'),
Router = require('koa-router'),
cheerio = require('cheerio'),
superagent = require('superagent-charset'),
app = new Koa(),
router = new Router();
然后编写路由和搭建服务器环境
router.get('/', function(ctx, next) {
ctx.body = "路由搭建好啦";
});
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3000, () => {
console.log('[服务已开启,访问地址为:] http://127.0.0.1:3000/');
});
环境搭建好后使用 node dou.js: http://127.0.0.1:3000/ 就可以访问了
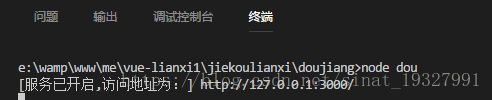
看见浏览器这样就恭喜你了,成功了搭建了环境
那么接下来,就开始编写爬虫需要代码了,首先要确定需要爬的网站,这里我们去爬百度新闻,然后爬这个地方的列表文字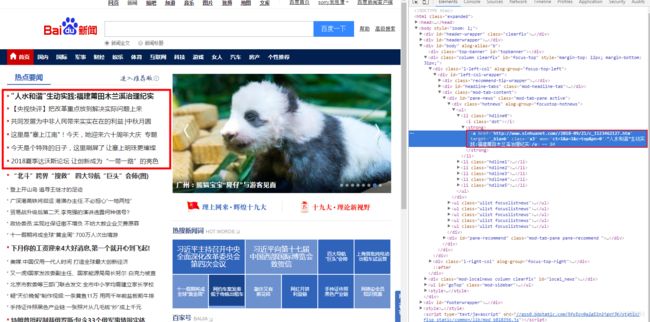
const Koa = require('koa'),
Router = require('koa-router'),
cheerio = require('cheerio'),
superagent = require('superagent-charset'),
app = new Koa(),
router = new Router();
let arr;
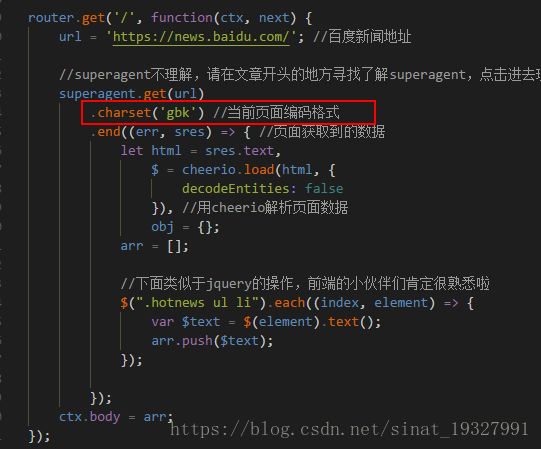
router.get('/', function(ctx, next) {
url = 'https://news.baidu.com/'; //百度新闻地址
//superagent不理解,请在文章开头的地方寻找了解superagent,点击进去理解
superagent.get(url)
.charset('utf-8') //当前页面编码格式
.end((err, sres) => { //页面获取到的数据
let html = sres.text,
$ = cheerio.load(html, {
decodeEntities: false
}), //用cheerio解析页面数据
obj = {};
arr = [];
//下面类似于jquery的操作,前端的小伙伴们肯定很熟悉啦
$(".hotnews ul li").each((index, element) => {
var $text = $(element).text();
arr.push($text);
});
});
ctx.body = arr;
});
app
.use(router.routes())
.use(router.allowedMethods());
app.listen(3000, () => {
console.log('[服务已开启,访问地址为:] http://127.0.0.1:3000/');
});
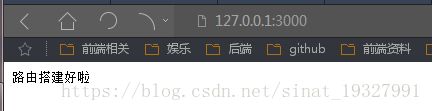
再次在命令行窗口输入命令:node dou.js 就可以愉快的在浏览器看见这个画面了

恭喜你,你的第一个node爬虫完成啦~
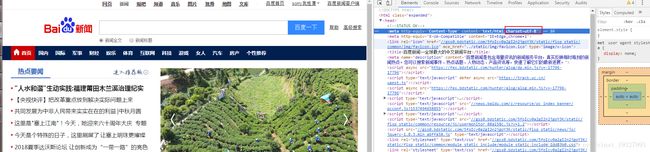
注意的是,如果小伙伴去抓取其他页面出现乱码
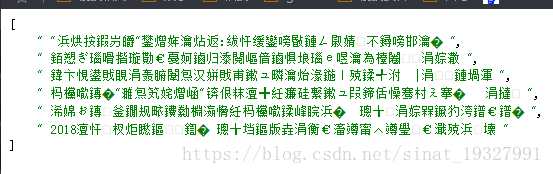
可能就是代码的编码格式和要抓取页面的编码格式不一样导致的,要注意一下
以上就是本文的全部内容,希望帮到你