WebRTC 中的基本音频处理操作
在 RTC,即实时音视频通信中,要解决的音频相关的问题,主要包括如下这些:
- 音频数据的采集及播放。
- 音频数据的处理。主要是对采集录制的音频数据的处理,即所谓的 3A 处理,AEC (Acoustic Echo Cancellation) 回声消除,ANS (Automatic Noise Suppression) 降噪,和 AGC (Automatic Gain Control) 自动增益控制。
- 音效。如变声,混响,均衡等。
- 音频数据的编码和解码。包括音频数据的编码和解码,如 AAC,OPUS,和针对弱网的处理,如 NetEQ。
- 网络传输。一般用 RTP/RTCP 传输编码后的音频数据。
- 整个音频处理流水线的搭建。
WebRTC 的音频处理流水线大体如下图:
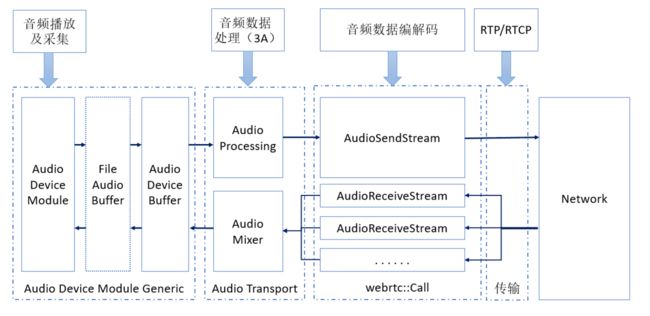
除了音效之外,WebRTC 的音频处理流水线包含其它所有的部分,音频数据的采集及播放,音频数据的处理,音频数据的编码和解码,网络传输都有。
在 WebRTC 中,通过 AudioDeviceModule 完成音频数据的采集和播放。不同的操作系统平台有着不同的与音频设备通信的方式,因而不同的平台上使用各自平台特有的解决方案实现平台特有的 AudioDeviceModule。一些平台上甚至有很多套音频解决方案,如 Linux 有 pulse 和 ALSA,Android 有 framework 提供的 Java 接口、OpenSLES 和 AAudio,Windows 也有多种方案等。
WebRTC 的音频流水线只支持处理 10 ms 的数据,有些操作系统平台提供了支持采集和播放 10 ms 音频数据的接口,如 Linux,有些平台则没有,如 Android、iOS 等。AudioDeviceModule 播放和采集的数据,总会通过 AudioDeviceBuffer 拿进来或者送出去 10 ms 的音频数据。对于不支持采集和播放 10 ms 音频数据的平台,在平台的 AudioDeviceModule 和 AudioDeviceBuffer 还会插入一个 FineAudioBuffer,用于将平台的音频数据格式转换为 10 ms 的 WebRTC 能处理的音频帧。
WebRTC 的 AudioDeviceModule 连接称为 AudioTransport 的模块。对于音频数据的采集发送,AudioTransport 完成音频处理,主要即是 3A 处理。对于音频播放,这里有一个混音器,用于将接收到的多路音频做混音。回声消除主要是将录制的声音中播放的声音的部分消除掉,因而,在从 AudioTransport 中拿音频数据播放时,也会将这一部分音频数据送进 APM 中。
AudioTransport 接 AudioSendStream 和 AudioReceiveStream,在 AudioSendStream 和 AudioReceiveStream 中完成音频的编码发送和接收解码,及网络传输。
WebRTC 的音频基本操作
在 WebRTC 的音频流水线,无论远端发送了多少路音频流,也无论远端发送的各条音频流的采样率和通道数具体是什么,都需要经过重采样,通道数转换和混音,最终转换为系统设备可接受的采样率和通道数的单路音频数据。具体来说,各条音频流需要先重采样和通道数变换转换为某个统一的采样率和通道数,然后做混音;混音之后,再经过重采样以及通道数变换,转变为最终设备可接受的音频数据。(WebRTC 中音频流水线各个节点统一用 16 位整型值表示采样点。)如下面这样:
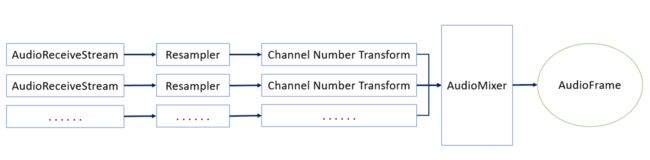
WebRTC 提供了一些音频操作的工具类和函数用来完成上述操作。
混音如何混?
WebRTC 提供了 AudioMixer 接口来抽象混音器,这个接口定义 (位于 webrtc/src/api/audio/audio_mixer.h) 如下:
namespace webrtc {
// WORK IN PROGRESS
// This class is under development and is not yet intended for for use outside
// of WebRtc/Libjingle.
class AudioMixer : public rtc::RefCountInterface {
public:
// A callback class that all mixer participants must inherit from/implement.
class Source {
public:
enum class AudioFrameInfo {
kNormal, // The samples in audio_frame are valid and should be used.
kMuted, // The samples in audio_frame should not be used, but
// should be implicitly interpreted as zero. Other
// fields in audio_frame may be read and should
// contain meaningful values.
kError, // The audio_frame will not be used.
};
// Overwrites |audio_frame|. The data_ field is overwritten with
// 10 ms of new audio (either 1 or 2 interleaved channels) at
// |sample_rate_hz|. All fields in |audio_frame| must be updated.
virtual AudioFrameInfo GetAudioFrameWithInfo(int sample_rate_hz,
AudioFrame* audio_frame) = 0;
// A way for a mixer implementation to distinguish participants.
virtual int Ssrc() const = 0;
// A way for this source to say that GetAudioFrameWithInfo called
// with this sample rate or higher will not cause quality loss.
virtual int PreferredSampleRate() const = 0;
virtual ~Source() {}
};
// Returns true if adding was successful. A source is never added
// twice. Addition and removal can happen on different threads.
virtual bool AddSource(Source* audio_source) = 0;
// Removal is never attempted if a source has not been successfully
// added to the mixer.
virtual void RemoveSource(Source* audio_source) = 0;
// Performs mixing by asking registered audio sources for audio. The
// mixed result is placed in the provided AudioFrame. This method
// will only be called from a single thread. The channels argument
// specifies the number of channels of the mix result. The mixer
// should mix at a rate that doesn't cause quality loss of the
// sources' audio. The mixing rate is one of the rates listed in
// AudioProcessing::NativeRate. All fields in
// |audio_frame_for_mixing| must be updated.
virtual void Mix(size_t number_of_channels,
AudioFrame* audio_frame_for_mixing) = 0;
protected:
// Since the mixer is reference counted, the destructor may be
// called from any thread.
~AudioMixer() override {}
};
} // namespace webrtc
WebRTC 的 AudioMixer 将 0 个、1 个或多个 Mixer Source 混音为特定通道数的单路音频帧。输出的音频帧的采样率,由 AudioMixer 的具体实现根据一定的规则确定。
Mixer Source 为 AudioMixer 提供特定采样率的单声道或立体声的音频帧数据,它有责任将它可以拿到的音频帧数据重采样为 AudioMixer 期待的采样率的音频数据。它还可以提供它倾向的输出采样率的信息,以帮助 AudioMixer 计算合适的输出采样率。Mixer Source 通过 Ssrc() 提供一个这一路的 Mixer Source 标识。
WebRTC 提供了一个 AudioMixer 的实现 AudioMixerImpl 类,位于 webrtc/src/modules/audio_mixer/。这个类的定义 (位于 webrtc/src/modules/audio_mixer/audio_mixer_impl.h) 如下:
namespace webrtc {
typedef std::vector AudioFrameList;
class AudioMixerImpl : public AudioMixer {
public:
struct SourceStatus {
SourceStatus(Source* audio_source, bool is_mixed, float gain)
: audio_source(audio_source), is_mixed(is_mixed), gain(gain) {}
Source* audio_source = nullptr;
bool is_mixed = false;
float gain = 0.0f;
// A frame that will be passed to audio_source->GetAudioFrameWithInfo.
AudioFrame audio_frame;
};
using SourceStatusList = std::vector>;
// AudioProcessing only accepts 10 ms frames.
static const int kFrameDurationInMs = 10;
static const int kMaximumAmountOfMixedAudioSources = 3;
static rtc::scoped_refptr Create();
static rtc::scoped_refptr Create(
std::unique_ptr output_rate_calculator,
bool use_limiter);
~AudioMixerImpl() override;
// AudioMixer functions
bool AddSource(Source* audio_source) override;
void RemoveSource(Source* audio_source) override;
void Mix(size_t number_of_channels,
AudioFrame* audio_frame_for_mixing) override
RTC_LOCKS_EXCLUDED(crit_);
// Returns true if the source was mixed last round. Returns
// false and logs an error if the source was never added to the
// mixer.
bool GetAudioSourceMixabilityStatusForTest(Source* audio_source) const;
protected:
AudioMixerImpl(std::unique_ptr output_rate_calculator,
bool use_limiter);
private:
// Set mixing frequency through OutputFrequencyCalculator.
void CalculateOutputFrequency();
// Get mixing frequency.
int OutputFrequency() const;
// Compute what audio sources to mix from audio_source_list_. Ramp
// in and out. Update mixed status. Mixes up to
// kMaximumAmountOfMixedAudioSources audio sources.
AudioFrameList GetAudioFromSources() RTC_EXCLUSIVE_LOCKS_REQUIRED(crit_);
// The critical section lock guards audio source insertion and
// removal, which can be done from any thread. The race checker
// checks that mixing is done sequentially.
rtc::CriticalSection crit_;
rtc::RaceChecker race_checker_;
std::unique_ptr output_rate_calculator_;
// The current sample frequency and sample size when mixing.
int output_frequency_ RTC_GUARDED_BY(race_checker_);
size_t sample_size_ RTC_GUARDED_BY(race_checker_);
// List of all audio sources. Note all lists are disjunct
SourceStatusList audio_source_list_ RTC_GUARDED_BY(crit_); // May be mixed.
// Component that handles actual adding of audio frames.
FrameCombiner frame_combiner_ RTC_GUARDED_BY(race_checker_);
RTC_DISALLOW_COPY_AND_ASSIGN(AudioMixerImpl);
};
} // namespace webrtc
AudioMixerImpl 类的实现 (位于 webrtc/src/modules/audio_mixer/audio_mixer_impl.cc) 如下:
namespace webrtc {
namespace {
struct SourceFrame {
SourceFrame(AudioMixerImpl::SourceStatus* source_status,
AudioFrame* audio_frame,
bool muted)
: source_status(source_status), audio_frame(audio_frame), muted(muted) {
RTC_DCHECK(source_status);
RTC_DCHECK(audio_frame);
if (!muted) {
energy = AudioMixerCalculateEnergy(*audio_frame);
}
}
SourceFrame(AudioMixerImpl::SourceStatus* source_status,
AudioFrame* audio_frame,
bool muted,
uint32_t energy)
: source_status(source_status),
audio_frame(audio_frame),
muted(muted),
energy(energy) {
RTC_DCHECK(source_status);
RTC_DCHECK(audio_frame);
}
AudioMixerImpl::SourceStatus* source_status = nullptr;
AudioFrame* audio_frame = nullptr;
bool muted = true;
uint32_t energy = 0;
};
// ShouldMixBefore(a, b) is used to select mixer sources.
bool ShouldMixBefore(const SourceFrame& a, const SourceFrame& b) {
if (a.muted != b.muted) {
return b.muted;
}
const auto a_activity = a.audio_frame->vad_activity_;
const auto b_activity = b.audio_frame->vad_activity_;
if (a_activity != b_activity) {
return a_activity == AudioFrame::kVadActive;
}
return a.energy > b.energy;
}
void RampAndUpdateGain(
const std::vector& mixed_sources_and_frames) {
for (const auto& source_frame : mixed_sources_and_frames) {
float target_gain = source_frame.source_status->is_mixed ? 1.0f : 0.0f;
Ramp(source_frame.source_status->gain, target_gain,
source_frame.audio_frame);
source_frame.source_status->gain = target_gain;
}
}
AudioMixerImpl::SourceStatusList::const_iterator FindSourceInList(
AudioMixerImpl::Source const* audio_source,
AudioMixerImpl::SourceStatusList const* audio_source_list) {
return std::find_if(
audio_source_list->begin(), audio_source_list->end(),
[audio_source](const std::unique_ptr& p) {
return p->audio_source == audio_source;
});
}
} // namespace
AudioMixerImpl::AudioMixerImpl(
std::unique_ptr output_rate_calculator,
bool use_limiter)
: output_rate_calculator_(std::move(output_rate_calculator)),
output_frequency_(0),
sample_size_(0),
audio_source_list_(),
frame_combiner_(use_limiter) {}
AudioMixerImpl::~AudioMixerImpl() {}
rtc::scoped_refptr AudioMixerImpl::Create() {
return Create(std::unique_ptr(
new DefaultOutputRateCalculator()),
true);
}
rtc::scoped_refptr AudioMixerImpl::Create(
std::unique_ptr output_rate_calculator,
bool use_limiter) {
return rtc::scoped_refptr(
new rtc::RefCountedObject(
std::move(output_rate_calculator), use_limiter));
}
void AudioMixerImpl::Mix(size_t number_of_channels,
AudioFrame* audio_frame_for_mixing) {
RTC_DCHECK(number_of_channels >= 1);
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
CalculateOutputFrequency();
{
rtc::CritScope lock(&crit_);
const size_t number_of_streams = audio_source_list_.size();
frame_combiner_.Combine(GetAudioFromSources(), number_of_channels,
OutputFrequency(), number_of_streams,
audio_frame_for_mixing);
}
return;
}
void AudioMixerImpl::CalculateOutputFrequency() {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
rtc::CritScope lock(&crit_);
std::vector preferred_rates;
std::transform(audio_source_list_.begin(), audio_source_list_.end(),
std::back_inserter(preferred_rates),
[&](std::unique_ptr& a) {
return a->audio_source->PreferredSampleRate();
});
output_frequency_ =
output_rate_calculator_->CalculateOutputRate(preferred_rates);
sample_size_ = (output_frequency_ * kFrameDurationInMs) / 1000;
}
int AudioMixerImpl::OutputFrequency() const {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
return output_frequency_;
}
bool AudioMixerImpl::AddSource(Source* audio_source) {
RTC_DCHECK(audio_source);
rtc::CritScope lock(&crit_);
RTC_DCHECK(FindSourceInList(audio_source, &audio_source_list_) ==
audio_source_list_.end())
<< "Source already added to mixer";
audio_source_list_.emplace_back(new SourceStatus(audio_source, false, 0));
return true;
}
void AudioMixerImpl::RemoveSource(Source* audio_source) {
RTC_DCHECK(audio_source);
rtc::CritScope lock(&crit_);
const auto iter = FindSourceInList(audio_source, &audio_source_list_);
RTC_DCHECK(iter != audio_source_list_.end()) << "Source not present in mixer";
audio_source_list_.erase(iter);
}
AudioFrameList AudioMixerImpl::GetAudioFromSources() {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
AudioFrameList result;
std::vector audio_source_mixing_data_list;
std::vector ramp_list;
// Get audio from the audio sources and put it in the SourceFrame vector.
for (auto& source_and_status : audio_source_list_) {
const auto audio_frame_info =
source_and_status->audio_source->GetAudioFrameWithInfo(
OutputFrequency(), &source_and_status->audio_frame);
if (audio_frame_info == Source::AudioFrameInfo::kError) {
RTC_LOG_F(LS_WARNING) << "failed to GetAudioFrameWithInfo() from source";
continue;
}
audio_source_mixing_data_list.emplace_back(
source_and_status.get(), &source_and_status->audio_frame,
audio_frame_info == Source::AudioFrameInfo::kMuted);
}
// Sort frames by sorting function.
std::sort(audio_source_mixing_data_list.begin(),
audio_source_mixing_data_list.end(), ShouldMixBefore);
int max_audio_frame_counter = kMaximumAmountOfMixedAudioSources;
// Go through list in order and put unmuted frames in result list.
for (const auto& p : audio_source_mixing_data_list) {
// Filter muted.
if (p.muted) {
p.source_status->is_mixed = false;
continue;
}
// Add frame to result vector for mixing.
bool is_mixed = false;
if (max_audio_frame_counter > 0) {
--max_audio_frame_counter;
result.push_back(p.audio_frame);
ramp_list.emplace_back(p.source_status, p.audio_frame, false, -1);
is_mixed = true;
}
p.source_status->is_mixed = is_mixed;
}
RampAndUpdateGain(ramp_list);
return result;
}
bool AudioMixerImpl::GetAudioSourceMixabilityStatusForTest(
AudioMixerImpl::Source* audio_source) const {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
rtc::CritScope lock(&crit_);
const auto iter = FindSourceInList(audio_source, &audio_source_list_);
if (iter != audio_source_list_.end()) {
return (*iter)->is_mixed;
}
RTC_LOG(LS_ERROR) << "Audio source unknown";
return false;
}
} // namespace webrtc
不难看出,AudioMixerImpl 的 AddSource(Source* audio_source) 和 RemoveSource(Source* audio_source) 都只是普通的容器操作,但它强制不能添加已经添加的 Mixer Source,也不能移除不存在的 Mixer Source。整个类的中心无疑是 Mix(size_t number_of_channels, AudioFrame* audio_frame_for_mixing) 了。
void AudioMixerImpl::Mix(size_t number_of_channels,
AudioFrame* audio_frame_for_mixing) {
RTC_DCHECK(number_of_channels >= 1);
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
CalculateOutputFrequency();
{
rtc::CritScope lock(&crit_);
const size_t number_of_streams = audio_source_list_.size();
frame_combiner_.Combine(GetAudioFromSources(), number_of_channels,
OutputFrequency(), number_of_streams,
audio_frame_for_mixing);
}
return;
}
AudioMixerImpl::Mix() 混音过程大致如下:
- 计算输出音频帧的采样率。这也是这个接口不需要指定输出采样率的原因,
AudioMixer的实现内部会自己算,通常是根据各个 Mixer Source 的 Preferred 采样率算。 - 从所有的 Mixer Source 中获得一个特定采样率的音频帧的列表。
AudioMixer并不是简单的从所有的 Mixer Source 中各获得一个音频帧并构造一个列表就完事,它还会对这些音频帧做一些简单变换和取舍。 - 通过
FrameCombiner对不同的音频帧做混音。
计算输出音频采样率
计算输出音频采样率的过程如下:
void AudioMixerImpl::CalculateOutputFrequency() {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
rtc::CritScope lock(&crit_);
std::vector preferred_rates;
std::transform(audio_source_list_.begin(), audio_source_list_.end(),
std::back_inserter(preferred_rates),
[&](std::unique_ptr& a) {
return a->audio_source->PreferredSampleRate();
});
output_frequency_ =
output_rate_calculator_->CalculateOutputRate(preferred_rates);
sample_size_ = (output_frequency_ * kFrameDurationInMs) / 1000;
}
AudioMixerImpl 首先获得各个 Mixer Source 的 Preferred 的采样率并构造一个列表,然后通过 OutputRateCalculator 接口 (位于 webrtc/modules/audio_mixer/output_rate_calculator.h) 计算输出采样率:
class OutputRateCalculator {
public:
virtual int CalculateOutputRate(
const std::vector& preferred_sample_rates) = 0;
virtual ~OutputRateCalculator() {}
};
WebRTC 提供了一个默认的 OutputRateCalculator 接口实现 DefaultOutputRateCalculator,类定义 (webrtc/src/modules/audio_mixer/default_output_rate_calculator.h) 如下:
namespace webrtc {
class DefaultOutputRateCalculator : public OutputRateCalculator {
public:
static const int kDefaultFrequency = 48000;
// Produces the least native rate greater or equal to the preferred
// sample rates. A native rate is one in
// AudioProcessing::NativeRate. If |preferred_sample_rates| is
// empty, returns |kDefaultFrequency|.
int CalculateOutputRate(
const std::vector& preferred_sample_rates) override;
~DefaultOutputRateCalculator() override {}
};
} // namespace webrtc
这个类的定义很简单。默认的 AudioMixer 输出采样率的计算方法如下:
namespace webrtc {
int DefaultOutputRateCalculator::CalculateOutputRate(
const std::vector& preferred_sample_rates) {
if (preferred_sample_rates.empty()) {
return DefaultOutputRateCalculator::kDefaultFrequency;
}
using NativeRate = AudioProcessing::NativeRate;
const int maximal_frequency = *std::max_element(
preferred_sample_rates.begin(), preferred_sample_rates.end());
RTC_DCHECK_LE(NativeRate::kSampleRate8kHz, maximal_frequency);
RTC_DCHECK_GE(NativeRate::kSampleRate48kHz, maximal_frequency);
static constexpr NativeRate native_rates[] = {
NativeRate::kSampleRate8kHz, NativeRate::kSampleRate16kHz,
NativeRate::kSampleRate32kHz, NativeRate::kSampleRate48kHz};
const auto* rounded_up_index = std::lower_bound(
std::begin(native_rates), std::end(native_rates), maximal_frequency);
RTC_DCHECK(rounded_up_index != std::end(native_rates));
return *rounded_up_index;
}
} // namespace webrtc
对于音频,WebRTC 内部支持一些标准的采样率,即 8K,16K,32K 和 48K。DefaultOutputRateCalculator 获得传入的采样率列表中最大的那个,并在标准采样率列表中找到最小的那个大于等于前面获得的最大采样率的采样率。也就是说,如果 AudioMixerImpl 的所有 Mixer Source 的 Preferred 采样率都大于 48K,计算会失败。
获得音频帧列表
AudioMixerImpl::GetAudioFromSources() 获得音频帧列表:
AudioFrameList AudioMixerImpl::GetAudioFromSources() {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
AudioFrameList result;
std::vector audio_source_mixing_data_list;
std::vector ramp_list;
// Get audio from the audio sources and put it in the SourceFrame vector.
for (auto& source_and_status : audio_source_list_) {
const auto audio_frame_info =
source_and_status->audio_source->GetAudioFrameWithInfo(
OutputFrequency(), &source_and_status->audio_frame);
if (audio_frame_info == Source::AudioFrameInfo::kError) {
RTC_LOG_F(LS_WARNING) << "failed to GetAudioFrameWithInfo() from source";
continue;
}
audio_source_mixing_data_list.emplace_back(
source_and_status.get(), &source_and_status->audio_frame,
audio_frame_info == Source::AudioFrameInfo::kMuted);
}
// Sort frames by sorting function.
std::sort(audio_source_mixing_data_list.begin(),
audio_source_mixing_data_list.end(), ShouldMixBefore);
int max_audio_frame_counter = kMaximumAmountOfMixedAudioSources;
// Go through list in order and put unmuted frames in result list.
for (const auto& p : audio_source_mixing_data_list) {
// Filter muted.
if (p.muted) {
p.source_status->is_mixed = false;
continue;
}
// Add frame to result vector for mixing.
bool is_mixed = false;
if (max_audio_frame_counter > 0) {
--max_audio_frame_counter;
result.push_back(p.audio_frame);
ramp_list.emplace_back(p.source_status, p.audio_frame, false, -1);
is_mixed = true;
}
p.source_status->is_mixed = is_mixed;
}
RampAndUpdateGain(ramp_list);
return result;
}
AudioMixerImpl::GetAudioFromSources()从各个 Mixer Source 中获得音频帧,并构造SourceFrame的列表。注意SourceFrame的构造函数会调用AudioMixerCalculateEnergy()(位于webrtc/src/modules/audio_mixer/audio_frame_manipulator.cc) 计算音频帧的 energy。具体的计算方法如下:
uint32_t AudioMixerCalculateEnergy(const AudioFrame& audio_frame) {
if (audio_frame.muted()) {
return 0;
}
uint32_t energy = 0;
const int16_t* frame_data = audio_frame.data();
for (size_t position = 0;
position < audio_frame.samples_per_channel_ * audio_frame.num_channels_;
position++) {
// TODO(aleloi): This can overflow. Convert to floats.
energy += frame_data[position] * frame_data[position];
}
return energy;
}
计算所有采样点数值的平方和。
- 然后对获得的音频帧排序,排序的逻辑如下:
bool ShouldMixBefore(const SourceFrame& a, const SourceFrame& b) {
if (a.muted != b.muted) {
return b.muted;
}
const auto a_activity = a.audio_frame->vad_activity_;
const auto b_activity = b.audio_frame->vad_activity_;
if (a_activity != b_activity) {
return a_activity == AudioFrame::kVadActive;
}
return a.energy > b.energy;
}
-
从排序之后的音频帧列表中选取最多 3 个信号最强的音频帧返回。
-
对选择的音频帧信号 Ramp 及更新增益:
void RampAndUpdateGain(
const std::vector& mixed_sources_and_frames) {
for (const auto& source_frame : mixed_sources_and_frames) {
float target_gain = source_frame.source_status->is_mixed ? 1.0f : 0.0f;
Ramp(source_frame.source_status->gain, target_gain,
source_frame.audio_frame);
source_frame.source_status->gain = target_gain;
}
}
Ramp() 的执行过程 (位于 webrtc/src/modules/audio_mixer/audio_frame_manipulator.cc) 如下:
void Ramp(float start_gain, float target_gain, AudioFrame* audio_frame) {
RTC_DCHECK(audio_frame);
RTC_DCHECK_GE(start_gain, 0.0f);
RTC_DCHECK_GE(target_gain, 0.0f);
if (start_gain == target_gain || audio_frame->muted()) {
return;
}
size_t samples = audio_frame->samples_per_channel_;
RTC_DCHECK_LT(0, samples);
float increment = (target_gain - start_gain) / samples;
float gain = start_gain;
int16_t* frame_data = audio_frame->mutable_data();
for (size_t i = 0; i < samples; ++i) {
// If the audio is interleaved of several channels, we want to
// apply the same gain change to the ith sample of every channel.
for (size_t ch = 0; ch < audio_frame->num_channels_; ++ch) {
frame_data[audio_frame->num_channels_ * i + ch] *= gain;
}
gain += increment;
}
}
之所以要执行这一步,是因为在混音不同音频帧的特定时刻,同一个音频流的音频帧可能会由于它的音频帧的信号相对强度,被纳入混音或被排除混音,这一步的操作可以使特定某一路音频听上去变化更平滑。
FrameCombiner
FrameCombiner 是混音的最终执行者:
void FrameCombiner::Combine(const std::vector& mix_list,
size_t number_of_channels,
int sample_rate,
size_t number_of_streams,
AudioFrame* audio_frame_for_mixing) {
RTC_DCHECK(audio_frame_for_mixing);
LogMixingStats(mix_list, sample_rate, number_of_streams);
SetAudioFrameFields(mix_list, number_of_channels, sample_rate,
number_of_streams, audio_frame_for_mixing);
const size_t samples_per_channel = static_cast(
(sample_rate * webrtc::AudioMixerImpl::kFrameDurationInMs) / 1000);
for (const auto* frame : mix_list) {
RTC_DCHECK_EQ(samples_per_channel, frame->samples_per_channel_);
RTC_DCHECK_EQ(sample_rate, frame->sample_rate_hz_);
}
// The 'num_channels_' field of frames in 'mix_list' could be
// different from 'number_of_channels'.
for (auto* frame : mix_list) {
RemixFrame(number_of_channels, frame);
}
if (number_of_streams <= 1) {
MixFewFramesWithNoLimiter(mix_list, audio_frame_for_mixing);
return;
}
std::array mixing_buffer =
MixToFloatFrame(mix_list, samples_per_channel, number_of_channels);
// Put float data in an AudioFrameView.
std::array channel_pointers{};
for (size_t i = 0; i < number_of_channels; ++i) {
channel_pointers[i] = &mixing_buffer[i][0];
}
AudioFrameView mixing_buffer_view(
&channel_pointers[0], number_of_channels, samples_per_channel);
if (use_limiter_) {
RunLimiter(mixing_buffer_view, &limiter_);
}
InterleaveToAudioFrame(mixing_buffer_view, audio_frame_for_mixing);
}
FrameCombiner把各个音频帧的数据的通道数都转换为目标通道数:
void RemixFrame(size_t target_number_of_channels, AudioFrame* frame) {
RTC_DCHECK_GE(target_number_of_channels, 1);
RTC_DCHECK_LE(target_number_of_channels, 2);
if (frame->num_channels_ == 1 && target_number_of_channels == 2) {
AudioFrameOperations::MonoToStereo(frame);
} else if (frame->num_channels_ == 2 && target_number_of_channels == 1) {
AudioFrameOperations::StereoToMono(frame);
}
}
- 执行混音
std::array MixToFloatFrame(
const std::vector& mix_list,
size_t samples_per_channel,
size_t number_of_channels) {
// Convert to FloatS16 and mix.
using OneChannelBuffer = std::array;
std::array mixing_buffer{};
for (size_t i = 0; i < mix_list.size(); ++i) {
const AudioFrame* const frame = mix_list[i];
for (size_t j = 0; j < number_of_channels; ++j) {
for (size_t k = 0; k < samples_per_channel; ++k) {
mixing_buffer[j][k] += frame->data()[number_of_channels * k + j];
}
}
}
return mixing_buffer;
}
可以看到,所谓混音,只是把不同音频流的音频帧的样本点数据相加。
- RunLimiter
这一步会通过 AGC,对音频信号做处理。
void RunLimiter(AudioFrameView mixing_buffer_view,
FixedGainController* limiter) {
const size_t sample_rate = mixing_buffer_view.samples_per_channel() * 1000 /
AudioMixerImpl::kFrameDurationInMs;
limiter->SetSampleRate(sample_rate);
limiter->Process(mixing_buffer_view);
}
- 数据格式转换
// Both interleaves and rounds.
void InterleaveToAudioFrame(AudioFrameView mixing_buffer_view,
AudioFrame* audio_frame_for_mixing) {
const size_t number_of_channels = mixing_buffer_view.num_channels();
const size_t samples_per_channel = mixing_buffer_view.samples_per_channel();
// Put data in the result frame.
for (size_t i = 0; i < number_of_channels; ++i) {
for (size_t j = 0; j < samples_per_channel; ++j) {
audio_frame_for_mixing->mutable_data()[number_of_channels * j + i] =
FloatS16ToS16(mixing_buffer_view.channel(i)[j]);
}
}
}
经过前面的处理,得到浮点型的音频采样数据。这一步将浮点型的数据转换为需要的 16 位整型数据。
至此混音结束。
结论:混音就是把各个音频流的采样点数据相加。
通道数转换如何完成?
WebRTC 提供了一些 Utility 函数用于完成音频帧单通道、立体声及四通道之间的相互转换,位于 webrtc/audio/utility/audio_frame_operations.cc。通过这些函数的实现,我们可以看到音频帧的通道数转换具体是什么含义。
单通道转立体声:
void AudioFrameOperations::MonoToStereo(const int16_t* src_audio,
size_t samples_per_channel,
int16_t* dst_audio) {
for (size_t i = 0; i < samples_per_channel; i++) {
dst_audio[2 * i] = src_audio[i];
dst_audio[2 * i + 1] = src_audio[i];
}
}
int AudioFrameOperations::MonoToStereo(AudioFrame* frame) {
if (frame->num_channels_ != 1) {
return -1;
}
if ((frame->samples_per_channel_ * 2) >= AudioFrame::kMaxDataSizeSamples) {
// Not enough memory to expand from mono to stereo.
return -1;
}
if (!frame->muted()) {
// TODO(yujo): this operation can be done in place.
int16_t data_copy[AudioFrame::kMaxDataSizeSamples];
memcpy(data_copy, frame->data(),
sizeof(int16_t) * frame->samples_per_channel_);
MonoToStereo(data_copy, frame->samples_per_channel_, frame->mutable_data());
}
frame->num_channels_ = 2;
return 0;
}
单通道转立体声,也就是把一个通道的数据复制一份,让两个声道播放相同的音频数据。
立体声转单声道:
void AudioFrameOperations::StereoToMono(const int16_t* src_audio,
size_t samples_per_channel,
int16_t* dst_audio) {
for (size_t i = 0; i < samples_per_channel; i++) {
dst_audio[i] =
(static_cast(src_audio[2 * i]) + src_audio[2 * i + 1]) >> 1;
}
}
int AudioFrameOperations::StereoToMono(AudioFrame* frame) {
if (frame->num_channels_ != 2) {
return -1;
}
RTC_DCHECK_LE(frame->samples_per_channel_ * 2,
AudioFrame::kMaxDataSizeSamples);
if (!frame->muted()) {
StereoToMono(frame->data(), frame->samples_per_channel_,
frame->mutable_data());
}
frame->num_channels_ = 1;
return 0;
}
立体声转单声道是把两个声道的数据相加除以 2,得到一个通道的音频数据。
四声道转立体声:
void AudioFrameOperations::QuadToStereo(const int16_t* src_audio,
size_t samples_per_channel,
int16_t* dst_audio) {
for (size_t i = 0; i < samples_per_channel; i++) {
dst_audio[i * 2] =
(static_cast(src_audio[4 * i]) + src_audio[4 * i + 1]) >> 1;
dst_audio[i * 2 + 1] =
(static_cast(src_audio[4 * i + 2]) + src_audio[4 * i + 3]) >>
1;
}
}
int AudioFrameOperations::QuadToStereo(AudioFrame* frame) {
if (frame->num_channels_ != 4) {
return -1;
}
RTC_DCHECK_LE(frame->samples_per_channel_ * 4,
AudioFrame::kMaxDataSizeSamples);
if (!frame->muted()) {
QuadToStereo(frame->data(), frame->samples_per_channel_,
frame->mutable_data());
}
frame->num_channels_ = 2;
return 0;
}
四声道转立体声,是把 1、2 两个声道的数据相加除以 2 作为一个声道的数据,把 3、4 两个声道的数据相加除以 2 作为另一个声道的数据。
四声道转单声道:
void AudioFrameOperations::QuadToMono(const int16_t* src_audio,
size_t samples_per_channel,
int16_t* dst_audio) {
for (size_t i = 0; i < samples_per_channel; i++) {
dst_audio[i] =
(static_cast(src_audio[4 * i]) + src_audio[4 * i + 1] +
src_audio[4 * i + 2] + src_audio[4 * i + 3]) >>
2;
}
}
int AudioFrameOperations::QuadToMono(AudioFrame* frame) {
if (frame->num_channels_ != 4) {
return -1;
}
RTC_DCHECK_LE(frame->samples_per_channel_ * 4,
AudioFrame::kMaxDataSizeSamples);
if (!frame->muted()) {
QuadToMono(frame->data(), frame->samples_per_channel_,
frame->mutable_data());
}
frame->num_channels_ = 1;
return 0;
}
四声道转单声道是把四个声道的数据相加除以四,得到一个声道的数据。
WebRTC 提供的其它音频数据操作具体可以参考 WebRTC 的头文件。
重采样
重采样可已将某个采样率的音频数据转换为另一个采样率的分辨率。WebRTC 中的重采样主要通过 PushResampler 、 PushSincResampler 和 SincResampler 等几个组件完成。如 webrtc/src/audio/audio_transport_impl.cc 中的 Resample():
// Resample audio in |frame| to given sample rate preserving the
// channel count and place the result in |destination|.
int Resample(const AudioFrame& frame, const int destination_sample_rate,
PushResampler* resampler, int16_t* destination) {
const int number_of_channels = static_cast(frame.num_channels_);
const int target_number_of_samples_per_channel =
destination_sample_rate / 100;
resampler->InitializeIfNeeded(frame.sample_rate_hz_, destination_sample_rate,
number_of_channels);
// TODO(yujo): make resampler take an AudioFrame, and add special case
// handling of muted frames.
return resampler->Resample(
frame.data(), frame.samples_per_channel_ * number_of_channels,
destination, number_of_channels * target_number_of_samples_per_channel);
}
PushResampler 是一个模板类,其接口比较简单,类的具体定义 (位于 webrtc/src/common_audio/resampler/include/push_resampler.h) 如下:
namespace webrtc {
class PushSincResampler;
// Wraps PushSincResampler to provide stereo support.
// TODO(ajm): add support for an arbitrary number of channels.
template
class PushResampler {
public:
PushResampler();
virtual ~PushResampler();
// Must be called whenever the parameters change. Free to be called at any
// time as it is a no-op if parameters have not changed since the last call.
int InitializeIfNeeded(int src_sample_rate_hz,
int dst_sample_rate_hz,
size_t num_channels);
// Returns the total number of samples provided in destination (e.g. 32 kHz,
// 2 channel audio gives 640 samples).
int Resample(const T* src, size_t src_length, T* dst, size_t dst_capacity);
private:
std::unique_ptr sinc_resampler_;
std::unique_ptr sinc_resampler_right_;
int src_sample_rate_hz_;
int dst_sample_rate_hz_;
size_t num_channels_;
std::unique_ptr src_left_;
std::unique_ptr src_right_;
std::unique_ptr dst_left_;
std::unique_ptr dst_right_;
};
} // namespace webrtc
这个类的实现 (位于 webrtc/src/common_audio/resampler/push_resampler.cc) 如下:
template
PushResampler::PushResampler()
: src_sample_rate_hz_(0), dst_sample_rate_hz_(0), num_channels_(0) {}
template
PushResampler::~PushResampler() {}
template
int PushResampler::InitializeIfNeeded(int src_sample_rate_hz,
int dst_sample_rate_hz,
size_t num_channels) {
CheckValidInitParams(src_sample_rate_hz, dst_sample_rate_hz, num_channels);
if (src_sample_rate_hz == src_sample_rate_hz_ &&
dst_sample_rate_hz == dst_sample_rate_hz_ &&
num_channels == num_channels_) {
// No-op if settings haven't changed.
return 0;
}
if (src_sample_rate_hz <= 0 || dst_sample_rate_hz <= 0 || num_channels <= 0 ||
num_channels > 2) {
return -1;
}
src_sample_rate_hz_ = src_sample_rate_hz;
dst_sample_rate_hz_ = dst_sample_rate_hz;
num_channels_ = num_channels;
const size_t src_size_10ms_mono =
static_cast(src_sample_rate_hz / 100);
const size_t dst_size_10ms_mono =
static_cast(dst_sample_rate_hz / 100);
sinc_resampler_.reset(
new PushSincResampler(src_size_10ms_mono, dst_size_10ms_mono));
if (num_channels_ == 2) {
src_left_.reset(new T[src_size_10ms_mono]);
src_right_.reset(new T[src_size_10ms_mono]);
dst_left_.reset(new T[dst_size_10ms_mono]);
dst_right_.reset(new T[dst_size_10ms_mono]);
sinc_resampler_right_.reset(
new PushSincResampler(src_size_10ms_mono, dst_size_10ms_mono));
}
return 0;
}
template
int PushResampler::Resample(const T* src,
size_t src_length,
T* dst,
size_t dst_capacity) {
CheckExpectedBufferSizes(src_length, dst_capacity, num_channels_,
src_sample_rate_hz_, dst_sample_rate_hz_);
if (src_sample_rate_hz_ == dst_sample_rate_hz_) {
// The old resampler provides this memcpy facility in the case of matching
// sample rates, so reproduce it here for the sinc resampler.
memcpy(dst, src, src_length * sizeof(T));
return static_cast(src_length);
}
if (num_channels_ == 2) {
const size_t src_length_mono = src_length / num_channels_;
const size_t dst_capacity_mono = dst_capacity / num_channels_;
T* deinterleaved[] = {src_left_.get(), src_right_.get()};
Deinterleave(src, src_length_mono, num_channels_, deinterleaved);
size_t dst_length_mono = sinc_resampler_->Resample(
src_left_.get(), src_length_mono, dst_left_.get(), dst_capacity_mono);
sinc_resampler_right_->Resample(src_right_.get(), src_length_mono,
dst_right_.get(), dst_capacity_mono);
deinterleaved[0] = dst_left_.get();
deinterleaved[1] = dst_right_.get();
Interleave(deinterleaved, dst_length_mono, num_channels_, dst);
return static_cast(dst_length_mono * num_channels_);
} else {
return static_cast(
sinc_resampler_->Resample(src, src_length, dst, dst_capacity));
}
}
// Explictly generate required instantiations.
template class PushResampler;
template class PushResampler;
PushResampler 函数根据源和目标采样率初始化了一些缓冲区和必要的 PushSincResampler。
PushResampler 函数中,通过 PushSincResampler 完成重采样。PushSincResampler 执行单个通道的音频数据的重采样。对于立体声的音频数据,PushResampler 函数会先将音频帧的数据,拆开成两个单通道的音频帧数据,然后分别做重采样,最后再合起来。
webrtc/src/common_audio/include/audio_util.h 中将立体声的音频数据拆开为两个单通道的数据,和将两个单通道的音频数据合并为立体声音频帧数据的具体实现如下:
// Deinterleave audio from |interleaved| to the channel buffers pointed to
// by |deinterleaved|. There must be sufficient space allocated in the
// |deinterleaved| buffers (|num_channel| buffers with |samples_per_channel|
// per buffer).
template
void Deinterleave(const T* interleaved,
size_t samples_per_channel,
size_t num_channels,
T* const* deinterleaved) {
for (size_t i = 0; i < num_channels; ++i) {
T* channel = deinterleaved[i];
size_t interleaved_idx = i;
for (size_t j = 0; j < samples_per_channel; ++j) {
channel[j] = interleaved[interleaved_idx];
interleaved_idx += num_channels;
}
}
}
// Interleave audio from the channel buffers pointed to by |deinterleaved| to
// |interleaved|. There must be sufficient space allocated in |interleaved|
// (|samples_per_channel| * |num_channels|).
template
void Interleave(const T* const* deinterleaved,
size_t samples_per_channel,
size_t num_channels,
T* interleaved) {
for (size_t i = 0; i < num_channels; ++i) {
const T* channel = deinterleaved[i];
size_t interleaved_idx = i;
for (size_t j = 0; j < samples_per_channel; ++j) {
interleaved[interleaved_idx] = channel[j];
interleaved_idx += num_channels;
}
}
}
音频数据的基本操作混音,声道转换,和重采样。