2019深度学习人体姿态估计指南
本文素材来源于nanonets技术博客网站,经本人编辑首发于CSDN,仅供技术分享所用,不作商用。
原文地址:https://blog.nanonets.com/human-pose-estimation-2d-guide/
人体姿势估计是过去几十年来一直受到计算机视觉社区关注的重要问题。这是了解图像和视频中人物的关键步骤。在这篇文章中,我写了人体姿势估计(2D)的基础知识,并回顾了有关该主题的文献。这篇文章还将作为人体姿势估计的教程,可以帮助您学习基础知识。
什么是人体姿势估计?
人体姿势估计被定义为图像或视频中人体关节(也称为关键点 - 肘部,手腕等)的定位问题。它还被定义为在所有关节姿势的空间中搜索特定姿势。
2D姿势估计 - 从RGB图像估计每个关节的2D姿势(x,y)坐标。
3D姿势估计 - 从RGB图像估计3D姿势(x,y,z)坐标。
人体姿势估计有一些非常酷的应用程序,并且大量用于动作识别,动画,游戏等。例如,一个非常流行的深度学习应用程序HomeCourt使用姿势估计来分析篮球运动员的动作。
人类行为识别的姿势条件时空关注
为什么这么难?
强大的关节,小而几乎不可见的关节,遮挡,衣服和灯光变化使这成为一个难题。

我将在这篇文章中介绍2D人体姿势估计。
二维人体姿态估计的不同方法
经典方法
- 关于姿势估计的经典方法是使用图形结构框架。这里的基本思想是通过以可变形配置(非刚性)排列的“部件”集合来表示对象。“part”是在图像中匹配的外观模板。弹簧显示零件之间的空间连接。 当通过像素位置和方向对部件进行参数化时,所得到的结构可以模拟与姿势估计非常相关的关节。(结构化预测任务)
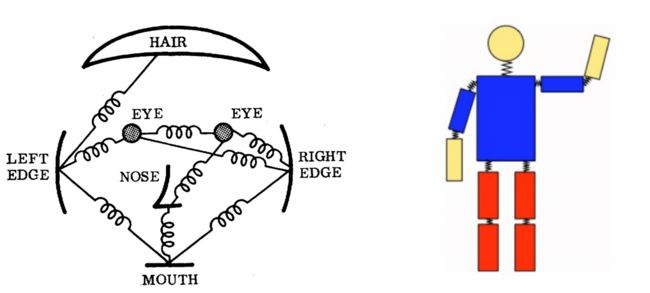
- 然而,上述方法具有不依赖于图像数据的姿势模型的限制。因此,研究的重点是丰富模型的代表性能力。
- 可变形零件模型 - Yang和Ramanan使用表达复杂关节关系的零件混合模型。可变形零件模型是以可变形配置排列的模板集合,每个模型都具有全局模板+零件模板。这些模板在图像中匹配以识别/检测对象。基于部件的模型可以很好地模拟关节。然而,这是以有限表现力为代价实现的,并未考虑全局背景。
基于深度学习的方法
经典流水线有其局限性,CNN已经大大改变了姿态估计。随着Toshev等人引入“ DeepPose ”,人类姿势估计的研究开始从经典方法转向深度学习。大多数最近的姿势估计系统都普遍采用ConvNets作为它们的主要构建块,大大取代了手工制作的特征和图形模型; 这一战略在标准基准方面取得了重大进展。
在下一节中,我将按时间顺序总结一些论文,这些论文代表人类姿势估计的演变,从Google的DeepPose开始(这不是一个详尽的列表,但是我认为最佳进展/最多的论文列表每次会议都很重要)。
论文涵盖
1. DeepPose
2. 使用卷积网络进行高效的对象本地化
3. 卷积姿势机器
4. 具有迭代误差反馈的人体姿态估计
5. 用于人体姿势估计的堆叠沙漏网络
6. 人体姿势估计和跟踪的简单基线
7. 用于人体姿势估计的深度高分辨率表示学习
DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR’14) [arXiv]
DeepPose是第一篇将深度学习应用于人体姿态估计的主要论文。它实现了SOTA性能并击败了现有模型。在该方法中,姿势估计被公式化为针对身体关节的基于CNN的回归问题。他们还使用一系列这样的回归量来改进姿势估计并获得更好的估计。这种方法的一个重要作用是以整体方式构建姿势的原因,即即使某些关节被隐藏,如果姿势是全面推理的,也可以估计它们。该论文认为,CNN自然会提供这种推理并展示出强有力的结果。
模型
该模型由一个AlexNet后端(7层)和一个额外的最终层组成,输出2k个联合坐标 :对于i∈{1,2…k},有 (xi,yi)∗2(其中ki是关节的数量)。
在模型训练时,使用了L2损失函数。
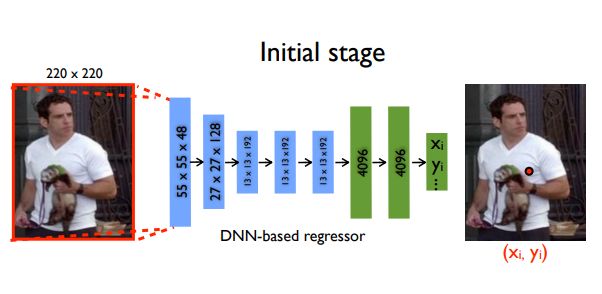
该模型实现的一个有趣的想法是使用级联回归量来改进预测。初始粗糙的姿势被细化后,实现了更好的估计。图像在预测的关节周围被裁剪并被馈送到下一阶段,这样随后的姿势回归器看到更高分辨率的图像,从而学习更精细尺度的特征,这最终导致更高的精度。
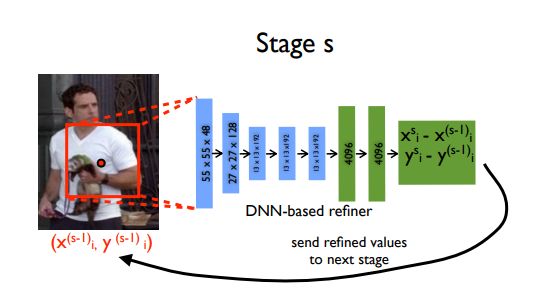
结果
在这里,PCP被使用于 LSP (Leeds sports dataset) 和FLIC (Frames Labeled In Cinema)。关于一些流行的评估指标的定义,如PCP和PCK,查看附录说明。
评论
- 本文将深度学习(CNN)应用于人体姿态估计,并在这方面开展了相当多的研究。
- 对于XY位置的回归是比较困难的并且增加了学习的复杂性,这削弱了泛化并因此在某些区域中表现不佳。
- 最近的SOTA方法将问题转化为估计大小为W0×H0,{H1,H2,...,Hk}的K个热力图,每个热图Hk表示第k个关键点的置信度,(总共K个关键点)。下一篇论文是介绍这一想法的基础。
Efficient Object Localization Using Convolutional Networks (CVPR’15) [arXiv]
该方法通过在一张图像上以多个分辨率库并行运行来生成热力图,以同时捕获各种尺度的特征。因此最后的结果,它输出的是离散的热力图而不是连续回归的热力图。每张热力图预测了在每个像素处存在关节的概率。这个输出模型非常成功,后续的很多论文都沿用了这种做法,预测热力图而不是直接回归。
模型
多分辨率CNN架构(coarse heatmap model)被用于实现滑动窗口检测器以产生粗略的热力图输出。
本文的主要动机是恢复由于初始模型中的汇集而导致的空间精度损失。他们通过使用额外的“姿势细化”ConvNet来实现这一点,ConvNet改进了粗略热力图的定位结果。但是,与标准级联模型不同,它们重用现有的卷积特征。这不仅减少了级联中可训练参数的数量,而且还充当粗略热图模型的正则化器,因为粗略和精细模型是联合训练的。
本质上,该模型包括用于粗略定位的基于热图的零件模型,用于在指定的(x ,y )处采样和裁剪卷积特征的模块(X,ÿ) 每个关节的位置,以及用于微调的附加卷积模型。
该方法的一个关键特征是联合使用ConvNet和图形模型。图形模型学习关节之间的典型空间关系。
训练
通过最小化我们预测的热图到目标热图的均方误差(MSE)距离来训练模型(目标是以地面实况为中心的恒定方差(σ≈1.5像素)的2D高斯(x ,y )(X,ÿ) 联合地点)
结果
评论
- 热力图比直接联合回归更好
- 联合使用CNN和图形模型
- 但是,这些方法缺乏结构建模。由于身体部位比例,左右对称性,互穿约束,关节限制(例如肘部不向后弯曲)和物理连接(例如,手腕与肘部严格相关)等,2D人体姿势的空间高度结构化。对此结构进行建模应该可以更容易地确定可见关键点,并可以估计被遮挡的关键点。接下来的几篇论文以他们自己的新颖方式解决了这个问题。
Convolutional Pose Machines (CVPR’16) [arXiv] [code]
摘要
- 这是一篇有趣的论文,使用了一种叫做Pose machine的东西。姿势机由图像特征计算模块和预测模块组成。卷积式姿态机可以完全区分,它们的多级架构可以端到端地进行训练。它们为学习丰富的隐式空间模型提供了一个顺序预测框架,并且非常适合人类姿势。
- 本文的主要动机之一是学习长距离空间关系,他们表明这可以通过使用更大的感受野来实现。
模型

g1()和g2()预测热图(论文中的信念图belief maps )。以上是高级视图。阶段1是图像特征计算模块,阶段2是预测模块。以下是详细的架构。注意感受野的大小是如何增加的?
CPM包含> 2个阶段,阶段数是超参数(通常= 3)。阶段1是固定的,阶段> 2只是阶段2的重复。阶段2将热图和图像证据作为输入。输入的热图为下一阶段增加了空间背景。(已在论文中详细讨论过)。
在较高的层面上,CPM通过后续阶段细化热图。
本文在每个阶段后使用中间监督,以避免梯度消失的问题,这是深层多阶段网络的常见问题
结果
- MPII:PCKh-0.5得分达到87.95%,比最接近的竞争者高出6.11%,值得注意的是,在脚踝(最具挑战性的部分),我们的[email protected]得分是78.28%,这是比最接近的竞争对手高出10.76%。
- LSP:模型达到84.32%的现状(添加MPII训练数据时为90.5%)。
评论
- 介绍了一种新的CPM框架,该框架显示了MPII,FLIC和LSP数据集的SOTA性能。
Human Pose Estimation with Iterative Error Feedback (CVPR’16) [arXiv] [code]
摘要
这是一篇pretty dense的论文,我试图简单地总结一下,尽量不遗漏太多。整体工作非常简单:预测当前估计的错误并迭代纠正。引用作者的一句话,他们不是一次性直接预测输出,而是使用自校正模型,通过反馈误差预测逐步改变初始解决方案,这个过程称为迭代误差反馈(IEF)。
让我们直接跳到模型管道。
- 输入包括图像I和先前输出 y(t−1)。请记住,这是一个迭代过程,相同的输出在步骤中得到改进。
- 输入,x(t)=I⊕g[y(t−1)]其中I表示图像,y(t−1)是先前一步的输出结果。
- f[x(t)]输出校正ε(t),然后与当前的输出 y(t)相加,以产生y(t + 1),这类注意到y(t + 1)已将修正值考虑在内。
- g[y(t +1)]将y(t + 1)的每个关键点转化进热力图通道,以便它们可以堆叠到图像I 上,然后再形成输入,作为下一个teration的输入。该过程重复T次,直到我们得到精确的y(t + 1),使得加上修正值ε(t),也能非常接实际的情况。
-
在数学表达式上,
- ϵ(t)=f[x(t)]
- y(t+1)=y(t)+ϵ(t)
- x(t+1)=I⊕g[y(t+1)]
-
f ()和g ()是可学习的和f()是CNN.
-
需要注意的一点是,作为ConvNet f ()需要I⊕g[y(t)]作为输入,它具有在联合输入 - 输出空间上学习特征的能力,这非常酷。
-
参数Θ (g)ΘG和Θ (f)通过优化以下等式来进行学习:

示例
如您所见,姿势在校正步骤中得到了改进。
结果
评论
这篇不错的论文,介绍了一个很新奇,并且运作良好的方法。
Stacked Hourglass Networks for Human Pose Estimation (ECCV’16) [arXiv] [code]
这是一篇具有里程碑意义的论文,它引入了一种新颖而直观的架构,并击败了所有之前的方法 。它被称为堆叠沙漏网络,因为网络包括池化的步骤,以及上采样层层看起来像沙漏,并且层叠在一起。沙漏的设计是由于需要捕获各种规模的信息。虽然局部的证据对于识别面部手等特征至关重要,但最终的姿势估计需要全局背景。在不同尺度的图像识别中,人的方向、肢体的排列以及相邻关节的关系都是比较好的线索(较小的分辨率捕获更高阶的特征和全局背景)。
网络通过中间监督执行自下而上,自上而下的处理
- 自下而上处理(从高分辨率到低分辨率)
- 自上而下处理(从低分辨率到高分辨率)
网络使用跳过连接来保留每个分辨率的空间信息,并将其传递给上采样,进一步沿着沙漏。
每个盒子都是一个残留模块,如下图所示;
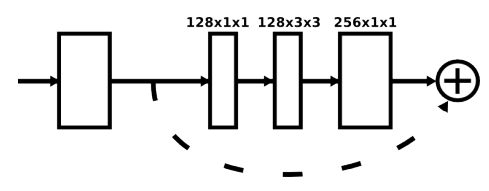
中级监督
中级监督应用于每个沙漏阶段的预测,即监督堆栈中每个沙漏的预测,而不仅仅是最终的沙漏预测。
结果
它为什么这么好用?
沙漏可以捕获不同尺度的信息。通过这种方式,全局和局部的信息被完全捕获并被网络用于学习预测。
Simple Baselines for Human Pose Estimation and Tracking (ECCV’18) [paper] [code]
以前的方法工作得很好但很复杂。这项工作遵循这样一个问题 - 一个简单的方法有多好?这个工作在COCO上实现了73.7%的mAP最新技术水平。
网络结构非常简单,最后由ResNet +几个反卷积层组成。(可能是估算热力图的最简单方法)
虽然沙漏网络使用上采样来增加特征图分辨率并将卷积参数放入其他块中,但此方法以非常简单的方式将它们组合为反卷积层。令人惊讶的是,这样一个简单的架构比具有跳过连接的架构表现更好,保留了每个分辨率的信息。
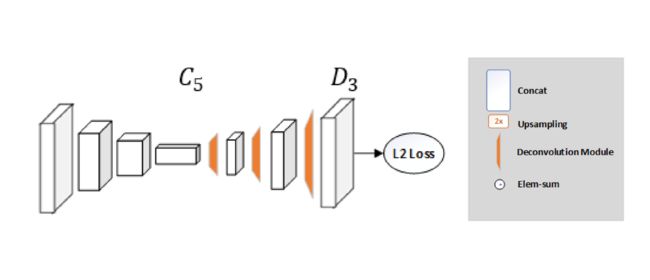
均方误差(MSE)用作预测热力图和目标热力图之间的损失。对于关节点k,目标热力图H(k)是通过在第k个关节的实际位置上应用2D Gaussian (std dev = 1)来生成的。
结果
Deep High-Resolution Representation Learning for Human Pose Estimation [HRNet] (CVPR’19) [arXiv] [code]
HRNet(高分辨率网络)模型在COCO数据集中的关键点检测,多人姿态估计和姿态估计任务,均优于现有的所有方法,并且是最新的。HRNet遵循一个非常简单的想法。以前的大多数论文都来自高→低→高分辨率表示。HRNet 在整个过程中始终保持高分辨率的表示,这非常有效。
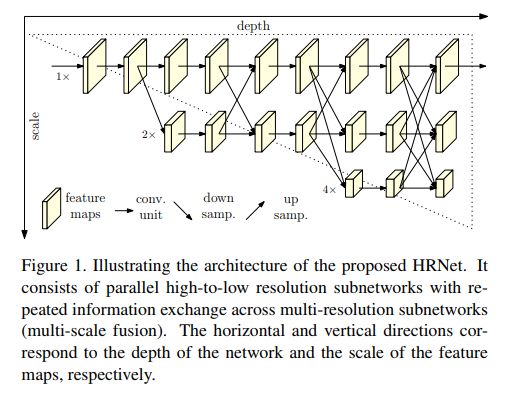
该架构从作为第一阶段的高分辨率子网开始,逐步逐个添加高到低分辨率的子网,以形成更多的阶段并并行连接多分辨率子网。
通过在整个过程中反复跨越并行多分辨率子网络交换信息来进行重复的多尺度融合。
此外,与Stacked Hourglass不同的是,这种架构不使用中间热力图进行监控。
使用MSE损失对热力图进行回归,类似于简单的基线。(在文章链接中添加)
结果
以下是其他一些我认为有趣的论文:
- Flowing ConvNets for Human Pose Estimation in Videos (ICCV’15) [arXiv]
- Learning Feature Pyramids for Human Pose Estimation (ICCV’17) [arXiv] [code]
- Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (CVPR’17) [arXiv] [code]: Very popular real-time multi-person pose estimator (Better known as OpenPose)
- Multi-Context Attention for Human Pose Estimation (CVPR’17) [arXiv][code]
- Cascaded Pyramid Network for Multi-Person Pose Estimation (CVPR’18) [arXiv] [code]
附录
通用评估指标
需要评估指标来衡量人体姿势估计模型的性能。
正确部位的百分比 - PCP:如果两个预测的关节位置与真实肢体关节位置之间的距离小于肢体长度的一半(通常表示为[email protected]),则认为肢体被检测到(正确的部位)。
- 它测量肢体的检出率。结果是,由于较短的肢体具有较小的阈值,因此它会对较短的肢体进行惩罚。
- PCP越高,模型越好。
正确关键点的百分比 - PCK:如果预测关节与真实关节之间的距离在特定阈值内,则检测到的关节被认为是正确的。阈值可以是:
- [email protected]是阈值=头骨链接的50%时
- [email protected] ==预测和真实关节之间的距离<0.2 *躯干直径
- 有时将150 mm作为阈值。
- 缓解较短的肢体问题,因为较短的肢体具有较小的躯干和头骨连接。
- PCK用于2D和3D(PCK3D)。再次,越高越好。
检测到的关节的百分比 - PDJ:如果预测关节和真实关节之间的距离在躯干直径的某一部分内,则检测到的关节被认为是正确的。[email protected] =预测和真实关节之间的距离<0.2 *躯干直径。
基于对象关键点相似度(OKS)的mAP:
- 常用于COCO关键点的挑战。
