Python 全栈工程师必备面试题 300 道(2020 版)
2020元旦巨献,面试升级必备!献给正在学习Python的同学!
Python 全栈工程师必备面试题 300 道(2020 版)
-
Python 面试不仅需要掌握 Python 基础知识和高级语法,还会涉及网络编程、web 前端后端、数据库、网络爬虫、数据解析、数据分析和数据可视化等各方面的核心知识。针对网上资料参差不齐,并且自己上网寻找费时费力,效果还不好的问题,进行该 Chat 创作。
-
本人结合自己多年的开发经验,同时汲取网络中的精华,本着打造全网最全面最深入的面试题集,分类归纳总结了 Python 面试中的核心知识点,这篇文章不论是从深度还是广度上来讲,都已经囊括了非常多的知识点了,读者可以根据自己的需要强化升级自己某方面的知识点,文中所有案例在 Python3.6 环境下都已通过运行。
-
本文章是作者呕心沥血,耗时两个月潜心完成。通过阅读本文章,可以在最短的时间内获取 Python 技术栈最核心的知识点,同时更全面更深入的了解与 Python 相关的各项技术。
Python 全栈工程师必备面试题 300 道(2020 版)----欢迎订阅
加个人微信: AXiaShuBai 进Python小伙伴交流群

本 Chat 你将会获得以下知识:
- Python 基础知识
- 语言特征、编码规范、文件I/O操作、数据类型、常用内置函数
- Python高级语法
- 类、元类、装饰器、闭包、迭代器、生成器、模块、面向对象、设计模式、内存管理
- 系统编程
- 多进程、多线程、协程、并行、并发、锁
- 网络编程
- TCP、UDP、HTTP、SEO、WSGI
- 数据库
- MySQL、NoSQL、Redis、MongoDB
- 数据解析提取
- re正则表达式、XML、lxml、XPath、BeautifulSoup4
- 网络爬虫
- urllib、requests、Scrapy、反爬虫、分布式爬虫
- 数据分析及可视化
- Numpy、Pandas、Matplotlib
适合人群: 正在或者准备找工作的同学,想要武装强化的 Python 技术开发者
所有问题(含部分答案)
1. Python基础知识
语言特征及编码规范
1.1 Python的解释器有哪些?
1.2 列举至少5条Python3和Python2的区别?
1.3 Python新式类和经典类的区别是什么
1.4 Python 之禅是什么,python中如何获取python之禅?
1.5 python中的DocStrings(解释文档) 有什么作用?
- DocStrings 文档字符串是一个重要工具,用于解释文档程序,帮助你的程序文档更加简单易懂。主要是解释代码作用的。
- 我们可以在函数体的第一行使用一对三个单引号 ''' 或者一对三个双引号 """ 来定义文档字符串。
- 使用 \_\_doc\_\_(注意双下划线)调用函数中的文档字符串属性(注意,文中出现的反斜杠是转义符,去除一些符号的特殊格式)
'''
Author: Felix
WX: AXiaShuBai
Email: xiashubai@gmail.com
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/9 11:17
Desc:
'''
def print_max(x,y):
'''
打印两个整数中较大的值
:param x: 整数
:param y: 整数
:return: 返回较大值
'''
if x > y:
print(x)
else:
print(y)
print_max(3, 5)
print(print_max.__doc__)
1.6 Python3中的类型注解有什么好处?如何使用?
1.7 Python语言中的命名规范有哪些?
1. **基本原则**:Python 语言的标识符必须以字母、下划线\_开头,数字不能作为开头,后面可以跟任意数目的字母、数字和下划线\_。此处的字母并不局限于 26 个英文字母,可以包含中文字符、日文字符等。
2. **禁忌**:Python 还包含一系列关键字和内置函数,不建议使用它们作为变量名,防止发生冲突。
**常用命名规则:**
项目名:首字母大写、其余单词小写,多单词组合则用下划线分割
包名、模块名—:全用小写字母
类名:首字母大写、其他字母小写,多单词采用驼峰
方法:小写单词
函数:若函数的参数名与保留关键字冲突,则在参数后加一个下划线,比拼音好太多
全局变量——采用全大写,多单词用下划线分割
3. **注意**:
1. 不论是类成员变量还是全局变量,均不使用 m 或 g 前缀。
2. 私有类成员使用单一下划线前缀标识,多定义公开成员,少定义私有成员。
3. 变量名不应带有类型信息,因为Python是动态类型语言。如 iValue、names_list、dict_obj 等都是不好的命名。
4. 开头,结尾,一般为python的自有变量,不要以这种方式命名
5. 以__开头(2个下划线),是私有实例变量(外部不嫩直接访问),依照情况进行命名
1.8 Python中各种下划线的作用?
1.9 单引号、双引号、三引号的有什么区别?
文件I/O操作
1.10 Python中打开文件有哪些模式?
1.11 Python中read、readline和readlines的区别?
1.12 大文件只需读取部分内容,或者避免读取时候内存不足的解决方法?
1.13 什么是上下文?with上下文管理器原理?
- with常用于打开文件,使用with可以自动关闭,即使出现错误
- 什么是上下文(context)?
- context其实说白了,和文章的上下文是一个意思,在通俗一点,我觉得叫环境更好
- 上下文虽然叫上下文,但是程序里面一般都只有上文而已,只是叫的好听叫上下文。。
- 进程中断在操作系统中是有上有下的,不过不这个高深的问题就不要深究了
- 任何实现了 enter() 和 exit() 方法的对象都可称之为上下文管理器,
上下文管理器对象可以使用with关键字。显然,文件(file)对象也实现了上下文管理器。
- 那么文件对象是如何实现这两个方法的呢?我们可以模拟实现一个自己的文件类,
让该类实现 enter() 和 exit() 方法。
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/22 10:55
Desc:
'''
class File():
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
print("entering")
self.f = open(self.filename, self.mode)
return self.f
def __exit__(self, *args):
print("will exit")
self.f.close()
# __enter__() 方法返回资源对象,这里就是你将要打开的那个文件对象,
# __exit__() 方法处理一些清除工作。
with File('out.txt', 'w') as f:
print("writing")
f.write('hello, python')
# 你就无需显示地调用 close 方法了,由系统自动去调用,哪怕中间遇到异常 close 方法也会被调用。
1.14 什么是全缓冲、行缓冲和无缓冲?
1.15 什么是序列化和反序列化?json序列化时常用的四个函数是什么?
1.16 json中dumps转换数据时候如何保持中文编码?
数据类型
1.17 Python中的可变和不可变数据类型是什么?
1.18 is和==有什么区别?
1.19 Python中的单词大小写转换和字母统计?
1.20 字符串,列表,元组如何反转?反转函数reverse和reversed的区别?
1.21 Python中的字符串格式化的方法有哪些?f-string格式化知道吗?
1.22 含有多种符号的字符串分割方法?
1.23 嵌套列表转换为列表,字符串转换为列表的方法?
1.24 列表合并的常用方法?
1.25 列表如何去除重复的元素,还是保持之前的排序?
1.26 列表数据如何筛选,筛选出符合要求的数据?
1.27 字典中元素的如何排序?sorted排序函数的使用详解?
1.28 字典如何合并?字典解包是什么?
1.29 字典推导式使用方法?字典推导式如何格式化cookie值?
- 字典生成式和列表生成式一样,都是使用for循环,可以多层for循环嵌套
- 字典的键值交换:{v:k for k,v in d.items()}
- 字典生成式常用于cookie值转换为字典格式
# 字典键值交换
d = {'a': '1', 'b': '2', 'c': '3'}
print({v: k for k,v in d.items()})
# 字典推导式的常用于格式化cookie值:
# 字符串分割后得到字典
cookies = "anonymid=k06r6sdauyh36v; depovince=ZGQT; _r01_=1; JSESSIONID=abcOraT1E7z0JhHDATb0w; ick_login=8f53ebf1-b972-4572-8f77-810953dcfdfe; first_login_flag=1; [email protected];loginfrom=null; wp_fold=0"
# 使用字典推导式将上述字符串转化为一个字典, 先使用;分割得到一个列表,
# 列表中每一个元素再用=进行分割,列表第一个值为键,第二个值为值
cookies ={i.split("=")[0]: i.split("=")[1] for i in cookies.split(";")}
print(cookies)
# {'1': 'a', '2': 'b', '3': 'c'}
# {'anonymid': 'k06r6sdauyh36v', ' depovince': 'ZGQT', ' _r01_': '1', ' JSESSIONID': 'abcOraT1E7z0JhHDATb0w', ' ick_login': '8f53ebf1-b972-4572-8f77-810953dcfdfe', ' first_login_flag': '1', ' ln_uact': '[email protected]', 'loginfrom': 'null', ' wp_fold': '0'}
1.30 zip打包函数的使用?元组或者列表中元素生成字典?
1.31 字典的键可以是哪些类型的数据?
1.32 变量的作用域是怎么决定的?
常用内置函数
1.33 collections.Counter统计一篇文章中单词出现的次数?出现频率最高的5个单词?
1.34 map映射函数按规律生成列表或集合?
1.35 filter过滤函数如何使用?如何过滤奇数偶数平方根数?
1.36 sort和sorted排序函数的用法区别?
1.37 enumerate为元素添加下标索引?
1.38 lambda匿名函数如何使用?
1.39 type和help函数有什么作用?
1.40 assert语句有什么作用?
- 使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单。在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助。
- python assert断言语句是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常。
- assert expression,等价于:if not expression:raise AssertionError
- 参考代码
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/9 11:17
Desc:
'''
def deallist(l):
"""
此函数是用来返回列表中元素的和
"""
assert len(l) > 1, '此列表中没有元素'
return sum(l)
l1 = [1,2,3,4,5]
l2 = []
try:
a = deallist(l1)
except AssertionError as err:
print('出现错误,错误类型是:', err)
else:
print('和是:', a)
# 传入l1的结果
# 和是: 15
# 传入l2的结果
# 出现错误,错误类型是: 此列表中没有元素
2. Python高级语法
类和元类
2.1 类class和元类metaclass的有什么区别?
2.2 类实例化时候,__init__和__new__方法有什么作用?
2.3 实例方法、类方法和静态方法有什么不同?
- 实例方法、类方法和静态方法,三种方法在内存中都归属于类,区别在于传入的参数和调用方式不同
- 三种方法传入的参数分别是:self(实例化对象),cls(类本身),无参数
- 三种方法的调用方式:
- 实例方法:由对象调用;至少一个self参数;执行实例方法时,自动将调用该方法的实例化对象赋值给self;实例化方法中可以修改实例的属性
- 类方法:由类调用;至少一个cls参数;执行类方法时,自动将调用该方法的类赋值给cls;类方法中可以修改类的属性
- 静态方法:由类调用;无默认参数;内部使用;
- 静态方法特殊性:静态方法不需要传入实例或者类,它是用来被类内部普通方法或类方法使用的一种方法
- 参考代码:
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/12 11:33
Desc:
'''
class Foo(object):
def __init__(self, name):
self.name = name
def ord_func(self):
""" 定义实例方法,至少有一个self参数,self指向实例化的对象 """
print('实例方法')
# 类调用自己的静态方法
print("类调用自己的静态方法")
self.static_func()
@classmethod
def class_func(cls):
""" 定义类方法,至少有一个cls参数,cls指向类对象 """
print('类方法')
@staticmethod
def static_func():
""" 定义静态方法 ,无默认参数"""
print('静态方法')
# 创建一个实例
f = Foo("中国")
print("实例对象可以调用实例方法,类方法,静态方法:")
# 调用实例方法,类方法,静态方法
f.ord_func()
f.class_func()
f.static_func()
print("\n类只能调用类方法和静态方法:")
# 调用类方法
Foo.class_func()
# 调用静态方法
Foo.static_func()
# Foo.ord_func()
# 因为实例方法必须传入self参数,self参数是一个实例化对象
# 输出结果:
# 实例对象可以调用实例方法,类方法,静态方法:
# 实例方法
# 类调用自己的静态方法
# 静态方法
# 类方法
# 静态方法
# 类只能调用类方法和静态方法:
# 类方法
# 静态方法
2.4 类有哪些常用的魔法属性以及它们的作用是什么?
2.5 类中的property属性有什么作用?
2.6 描述一下抽象类和接口类的区别和联系?
2.7 类中的私有化属性如何访问?
2.8 类如何才能支持比较操作?
2.9 hasattr() getattr() setattr() delattr()分别有什么作用?
高级用法(装饰器、闭包、迭代器、生成器)
2.10 编写函数的四个原则是什么?
2.11 函数调用参数的传递方式是值传递还是引用传递?
2.12 Python中pass语句的作用是什么?
2.13 闭包函数的用途和注意事项?
2.14 *args和**kwargs的区别?
2.15 位置参数,关键字参数,包裹位置参数,包裹关键字参数执行顺序及使用注意?
2.16 如何进行参数拆包?
2.17 装饰器函数有什么作用?装饰器函数和普通函数有什么区别?
2.18 带固定参数和不定参数的装饰器有什么区别?
2.19 描述一下一个装饰器的函数和多个装饰器的函数的执行步骤?
2.20 知道通用装饰器和类装饰器吗?
2.21 浅拷贝和深拷贝的区别?
2.22 元组的拷贝要注意什么?
2.23 全局变量是否一定要使用global进行声明?
2.24 可迭代对象和迭代器对象有什么区别?
2.25 描述一下for循环执行的步骤?
2.26 迭代器就是生成器,生成器一定是迭代器,这句话对吗?
2.27 yield关键字有什么好处?
2.28 yield和return关键字的关系和区别?
2.29 简单描述一下yield生成器函数的执行步骤?
- 函数每次执行到yield暂停运行(生成器函数外部代码不受影响,正常运行)
- 下次调用时候,从yield之后开始运行
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/25 13:55
Desc:
'''
# 包含yield关键字,就变成了生成器函数
def foo():
print('Starting.....')
while True:
res = yield 4
print("res:", res)
# 下面调用函数并没有执行,可以先将后面的语句注释掉
# 下面调用foo时,并不是调用执行函数,而是创建了一个生成器对象
# 生成器对象访问通过next方法
# 逐行运行代码观察效果
g = foo()
print("第一次调用执行结果:")
print(next(g))
print("*" * 100)
print("第二次调用执行结果:")
print(next(g))
print("*" * 100)
print("第三次调用执行结果(已经开始了While循环,继续调用,输出结果都一样):")
print(next(g))
print("*" * 100)
- 执行结果
第一次调用执行结果:
Starting.....
4
****************************************************************************************************
第二次调用执行结果:
res: None
4
****************************************************************************************************
第三次调用执行结果(已经开始了While循环,继续调用,输出结果都一样):
res: None
4
****************************************************************************************************
2.30 生成器函数访问方式有哪几种?生成器函数中的send()有什么作用?
2.31 Python中递归的最大次数?
2.32 递归函数停止的条件是什么?
模块
2.33 如何查看模块所在的位置?
2.34 import导入模块时候,搜索文件的路径顺序?
2.35 多模块导入共享变量的问题?
2.36 Python常用内置模块有哪些?
2.37 Python中常见的异常有哪些?
2.38 如何捕获异常?万能异常捕获是什么?
2.39 Python异常相关的关键字主要有哪些?
2.40 异常的完整写法是什么?
2.41 包中的__init__.py文件有什么作用?
2.42 模块内部的__name__有什么作用?
面向对象
2.43 面向过程和面向对象编程的区别?各自的优缺点和应用场景?
2.44 面向对象设计的三大特征是什么?
2.45 面向对象中有哪些常用概念?
2.46 多继承函数有那几种书写方式?
2.47 多继承函数执行的顺序(MRO)?
2.48 面向对象的接口如何实现?
设计模式
2.49 什么是设计模式?
2.50 面向对象中设计模式的六大原则是什么?
2.51 列举几个常见的设计模式?
2.52 Mixin设计模式是什么?它的特点和优点?
2.53 什么是单例模式?单例模式作用的作用?
2.54 单例模式的应用场景有那些?
2.55 什么是工厂模式以及应用场景?
2.56 什么是策略模式以及应用场景?
内存管理
2.57 Python的内存管理机制是什么?
2.58 Python的内寸管理的优化方法?
2.59 Python中内存泄漏有哪几种?
2.60 Python中如何避免内存泄漏?
2.61 内存溢出的原因?如何解决内存溢出?
2.62 Python退出时是否释放所有内存分配?
3. 系统编程
3.1 并发与并行的区别和联系?
3.2 程序中的同步和异步与现实中一样吗?
3.3 进程,线程,协程的区别和联系?
3.4 多进程和多线程的区别?
3.5 协程和线程差异是什么?
3.6 多线程和多进程分别用于哪些场景?
3.7 全局解释器锁(GIL)是什么?如何解决GIL问题?
3.8 Python中有哪些锁(LOCK)?它们分别有什么作用?
3.9 Python中如何实现多线程和多进程?
3.10 守护线程和非守护线程是什么?
3.11 多线程的执行顺序是什么样的?
3.12 多线程非安全是什么意思?
3.13 互斥锁是什么?有什么好处和坏处?
3.14 什么是僵尸进程和孤儿进程?如何避免僵尸进程?
3.15 多线程和多进程如何实现通信?
3.16 Python3中multiprocessing.Queue()和queue.Queue()的区别?
3.17 如何使用多协程并发请求网页?
- 使用协程池gevent模块,遇到阻塞,自动切换协程
- 由于IO操作非常耗时,程序经常会处于等待状态,比如请求多个网页有时候需要等待,gevent可以自动切换协程
- 遇到阻塞自动切换协程,程序启动时执行monkey.patch_all()解决,多个协程,可以采用pool管理并发数,限制并发任务数
- 参考代码
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/22 15:25
Desc:
'''
from gevent import monkey; monkey.patch_all()
from urllib import request
from gevent.pool import Pool
def run_task(url):
print("Visit --> %s" % url)
try:
response = request.urlopen(url)
data = response.read()
print("%d bytes received from %s." %(len(data), url))
except Exception:
print("error")
return 'url:%s -->finish' % url
if __name__ == '__main__':
# 指定协程同时执行数量
pool = Pool(2)
urls = ['https://github.com/', 'https://blog.csdn.net/', 'https://www.hao123.com/']
# 协程池执行任务
results = pool.map(run_task, urls)
# 打出结果,打出上面返回的结果
# map最终返回的值是一个列表,就是每个任务执行完成之后的返回值
print(results)
# 查看运行结果可以发现,先访问了两个网址
# 第一个协程执行完毕后,开始第三个协程
# 最终的结果为每次任务执行完成后返回值,组成的一个列表
Visit --> https://github.com/
Visit --> https://blog.csdn.net/
133390 bytes received from https://github.com/.
Visit --> https://www.hao123.com/
322244 bytes received from https://blog.csdn.net/.
321144 bytes received from https://www.hao123.com/.
['url:https://github.com/ -->finish', 'url:https://blog.csdn.net/ -->finish', 'url:https://www.hao123.com/ -->finish']
3.18 简单描述一下asyncio模块实现异步的原理?
4. 网络编程
4.1 UDP和TCP有什么区别以及各自的优缺点?
4.2 IP地址是什么?有哪几类?
4.3 举例描述一下端口有什作用?
4.4. 不同电脑上的进程如何实现通信的?
4.5. 列举一下常用网络通信名词?
4.6 描述一下请求一个网页的步骤(浏览器访问服务器的步骤)?
4.7 Http与Https协议有什么区别?
4.8 TCP中的三次握手和四次挥手是什么?
4.9 TCP短连接和长连接的优缺点?各自的应用场景?
4.10 TCP第四次挥手为什么要等待2MSL?
4.11 HTTP常见的请求方法有哪些?
4.12 GET请求和POST请求有什么区别?
4.13 cookie和session的有什么区别?
4.14 七层模型和五层模型是什么?
4.15 HTTP协议常见状态码及其含义?
4.16 HTTP报文基本结构?列举常用的头部信息?
4.17 SEO是什么?
4.18 伪静态URL、静态URL和动态URL的区别?
4.19 浏览器镜头请求和动态请求过程的区别?
4.20 WSGI接口有什么好处?
4.21 简单描述浏览器通过WSGI接口请求动态资源的过程?
5. 数据库
MySQL
5.1 NoSQL和SQL数据库的比较?
5.2 了解MySQL的事物吗?事物的四大特性是什么?
5.3 关系型数据库的三范式是什么?
5.4 关系型数据库的核心元素是什么?
5.5 简单描述一下Python访问MySQL的步骤?
5.6 写一个Python连接操作MySQL数据库实例?
5.7 SQL语句主要有哪些?分别有什么作用?
5.8 MySQL有哪些常用的字段约束?
- 参考下表
| 约束 | 名称 | 作用 |
|---|---|---|
| primary key | 主键 | 一张表的代表性字段,一张表只能有一个主键,主键可以是一个字段,也可以是多个字段(联合主键,复合主键) |
| unique key | 唯一约束 | 此字段的值不允许重复 |
| not null | 非空约束 | 此字段不允许填写空值 |
| default | 默认值 | 不填写此值时会使用默认值,如果填写时以填写为准 |
| auto_increment | 自增长约束 | 主键编号自动增长 |
| comment | 注释 | 表、列都可以设置注释(comment) |
| foreign key | 外键约束 | 对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询此值是否存在 |
- 补充:unsigned 是MYSQL自定义的类型,非标准SQL。用途是起到约束数值的作用,可以增加数值范围(相当于把负数那部分加到正数上)。
5.9 什么是视图?视图有什么作用?
5.10 什么是索引?索引的优缺点是什么?
5.11 NULL是什么意思?它和空字符串一样吗?
5.12 主键、外键和索引的区别?
5.13 char和varchar的区别?
5.14 sql注入是什么?如何避免sql注入?
5.15 存储引擎MyISAM和InnoDB有什么区别?
5.16 MySQL中有哪些锁?
5.17 三种删除操作drop,truncate,delete的区别?
5.18 MySQL中的存储过程是什么?它有什么优点?
5.19 MySQL数据库的有哪些种类的索引?
5.20 MySQL的事务隔离级别?
5.21 MySQL中的锁如何进行优化?
5.22 解释MySQL外连接、内连接与自连接的区别?
5.23 如何进行SQL优化?
5.24 什么是MySQL主从?主从同步有什么好处?
5.25 MySQL主从与MongoDB副本集有什么区别?
5.26 MySQL账户权限怎么分类的?
5.27 如何使用Python面向对象操作MySQL数据库?
Redis
5.28 Redis是什么?常见的应用场景?
5.29 Redis常见数据类型有哪些?各自有什么应用场景?
5.30 非关系型数据库Redis和MongoDB数据库的结构有什么区别?
5.31 redis和mongodb数据库的键(key)和值(value)的区别?
5.32 Redis持久化机制是什么?有哪几种方式?
- Redis是一个支持持久化的内存数据库,通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化。当Redis重启后通过把硬盘文件重新加载到内存,就能达到恢复数据的目的。
- 实现过程:单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
- Reids支持两种不同的持久化操作。Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)
- 快照(snapshotting)持久化(RDB): Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中
save 900 1 # 在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 # 在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 # 在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
- AOF(append-only file)持久化: 与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启.开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。在Redis的配置文件中存在三种不同的 AOF 持久化方式:
appendonly yes
appendfsync always # 每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec # 每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no # 让操作系统决定何时进行同步
5.33 Redis的事务是什么?
5.34 为什么要使用Redis作为缓存?
5.35 redis 和 memcached 的区别?
5.36 redis如何设置过期时间和删除过期数据?
5.37 Redis有哪几种数据淘汰策略?
5.38 Redis为什么是单线程的?
5.39 单线程的redis为什么这么快?
5.40 缓存雪崩和缓存穿透是什么?如何预防解决?
5.41 布隆过滤器是什么?
5.42 简单描述一下什么是缓存预热、缓存更新和缓存降级?
5.43 如何解决 Redis 的并发竞争 Key 的问题?
5.44 写一个Python连接操作redis数据库实例?
5.45 什么是分布式锁?
5.46 python如何实现一个redis分布式锁?
5.47 如何保证缓存与数据库双写时的数据一致性?
5.48 集群是什么?Redis有哪些集群方案?
5.49 Redis 常见性能问题和解决方案?
5.50 了解Redis的同步机制么?
5.51 如果有大量的key需要设置同一时间过期,一般需要注意什么?
5.52 如何使用Redis实现异步队列?
5.53 列举一些常用的数据库可视化工具?
MongoDB
5.54 NoSQL数据库主要分为哪几种?分别是什么?
5.55 MongoDB的主要特点及适用于哪些场合?
5.56 MongoDB中的文档有哪些特性?
5.57 MongoDB中的key命名要注意什么?
5.58 MongoDB数据库使用时要注意的问题?
5.59 常用的查询条件操作符有哪些?
5.60 MongoDB常用的管理命令有哪些?
5.61 MongoDB为何使用GridFS来存储文件?
5.62 如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?
5.63 分析器在MongoDB中的作用是什么?
5.64 MongoDB中的名字空间(namespace)是什么?
5.65 更新操作会立刻fsync到磁盘吗?
5.66 什么是master或primary?什么是secondary或slave?
5.67 必须调用getLastError来确保写操作生效了么?
5.68 MongoDB副本集原理及同步过程?
- 副本集中数据同步过程:Primary节点写入数据,Secondary通过读取Primary的oplog得到复制信息,开始复制数据并且将复制信息写入到自己的oplog。
- 如果某个操作失败,则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从oplog的最后一个操作开始同步,同步完成后,将信息写入自己的oplog,由于复制操作是先复制数据,复制完成后再写入oplog,有可能相同的操作会同步两份,不过MongoDB在设计之初就考虑到这个问题,将oplog的同一个操作执行多次,与执行一次的效果是一样的。
- 执行具体步骤:
- 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步:
- 1:检查自己local库的oplog.rs集合找出最近的时间戳。
- 2:检查Primary节点local库oplog.rs集合,找出大于此时间戳的记录。
- 3:将找到的记录插入到自己的oplog.rs集合中,并执行这些操作。
- 副本集的同步和主从同步一样,都是异步同步的过程,不同的是副本集有个自动故障转移的功能。其原理是:slave端从primary端获取日志,然后在自己身上完全顺序的行日志所记录的各种操作(该日志是不记录查询操作的),这个日志就是local数据 库中的oplog.rs表,默认在64位机器上这个表是比较大的,占磁盘大小的5%,oplog.rs的大小可以在启动参数中设 定:–oplogSize 1000,单位是M。
- 注意:在副本集的环境中,要是所有的Secondary都宕机了,只剩下Primary。最后Primary会变成Secondary,不能提供服务。
5.69 MongoDB中的分片是什么意思?
5.70 "ObjectID"有哪些部分组成?
5.71 在MongoDb中什么是索引?
5.72 什么是聚合?
5.73 写一个Python连接操作MongoDB数据库实例?
6. 数据解析提取
正则表达式
6.1 match、search和findall有什么区别?
6.2 正则表达式的() [] {}分别代表什么意思?
6.3 正则表达式中的.* .+ .*? .+?有什么区别?
- * 匹配0个或多个的表达式,贪婪模式。
- + 匹配1个或多个的表达式,非贪婪。
- ? 匹配0个或1个由问好前面字符或者表达式,非贪婪方式
- .*:贪婪匹配,找到满足条件的最大匹配
- .+:贪婪匹配,找到满足条件的最大匹配
- .*?:非贪婪,找到满足条件的最小匹配
- .+?:非贪婪,找到满足条件的最小匹配
- 参考代码
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/11/21 14:52
Desc:
'''
import re
html = 'ChapterChapterEND'
res = re.match(r'<.*>', html)
print(res)
print(res.group())
print('*' * 50)
res = re.match(r'<.+>', html)
print(res)
print(res.group())
print('*' * 50)
# 非贪婪,?后面有一个>,会找到第一个满足表达式的匹配就结束匹配
res = re.match(r'<.+?>', html)
print(res)
print(res.group())
print('*' * 50)
# 非贪婪,?后面有一个>,会找到第一个满足表达式的匹配就结束匹配
res = re.match(r'<.*?>', html)
print(res)
print(res.group())
print('*' * 50)
ChapterChapter
**************************************************
ChapterChapter
**************************************************
**************************************************
**************************************************
6.4 .*?贪婪匹配的一种特殊情况?当*和?中间有一个字符会怎么样?
6.5 \s和\S是什么意思?re.S是什么意思?
6.6 写一个表达式匹配座机或者手机号码?
6.7 正则表达式检查Python中使用的变量名是否合法?
6.8 正则表达式检查邮箱地址是否符合要求?
6.9 如何使用分组匹配html中的标签元素?
6.10 如何使用re.sub去掉"028-00112233 # 这是一个电话号码"#和后面的注释内容?
6.11 re.sub替换如何支持函数调用?举例说明?
6.12 如何只匹配中文字符?
6.13 如何过滤评论中的表情?
6.14 Python中的反斜杠\如何使用正则表达式匹配?
6.15 如何提取出下列网址中的域名?
6.16 去掉’ab;cd%e\tfg,jklioha;hp,vrww\tyz’中的符号,拼接为一个字符串?
6.17 str.replace和re.sub替换有什么区别?
6.18 如何使用重命名分组修改日期格式?
6.19 (?:x) a(?=x) a(?!=x) (?<=x)a (?
- a和x都可以是一个分组或者一个字符
- (?:x) 非捕获组(Non-capturing group),表示不返回该组匹配的内容,当成一个普通分组,但是不占用分组编号。使用groups()取出分组的结果,非捕获分组不会再结果列表中
- a(?=x) 先行断言,意思是a后面是x,匹配a的内容的后面的内容要匹配x,\d+(?=%)表示匹配以%结尾的一个或多个数字,括号里的部分是不会返回的
- a(?!x) 先行否定断言,意思是a后面不能是x,匹配a的内容的后面的内容不匹配x即可,\d+(?!%)表示匹配不是以%结尾的一个或多个数字,括号里的部分是不会返回的
- (?<=x)a 后瞻断言,意思是a前面是x,匹配a的内容的前面的内容要匹配x
- (?
- 参考代码
- 非捕获匹配
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/13 14:06
Desc:
'''
import re
# 正常捕获匹配
s1 = 'http://google.com/index'
res = re.match('(http|ftp)://([^/\r\n]+)(/[^\r\n]*)?', s1)
print(res)
print(res.groups())
print('*' * 50)
# 非捕获匹配
s1 = 'http://google.com/index'
res = re.match('(?:http|ftp)://([^/\r\n]+)(/[^\r\n]*)?', s1)
print(res)
print(res.groups())
print('*' * 50)
# 正常捕获,一个正则表达式是正常匹配,第一个括号返回网络协议;
# 后一个正则表达式是非捕获匹配,返回结果中不包括网络协议。
('http', 'google.com', '/index')
**************************************************
('google.com', '/index')
**************************************************
- 先行断言
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/13 14:06
Desc:
'''
import re
s = '98%1KK58%2AA65%3'
# 先行断言和先行否定断言都是取出来的断言表达式的匹配结果
# 找出以%结尾的所有数字
res = re.findall('\d+(?=%)', s)
print(res)
print('*' * 50)
# 找出所有不是以%结尾的数字
res = re.findall('\d+(?!%)', s)
print(res)
print('*' * 50)
['98', '58', '65']
**************************************************
['9', '1', '5', '2', '6', '3']
**************************************************
- 后瞻断言
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/13 14:06
Desc:
'''
import re
s = '98%1KK58%2AA65%3'
# 找出数字前面是%的数字
res = re.findall('(?<=%)\d+', s)
print(res)
print('*' * 50)
# 找出数字前面不是%的数字
res = re.findall('(?, s)
print(res)
print('*' * 50)
['1', '2', '3']
**************************************************
['98', '58', '65']
**************************************************
XPath
6.20 XML是什么?XML有什么用途?
6.21 XML和HTML之间有什么不同?
6.22 描述一下XML lxml XPath之间有什么关系?
6.23 介绍一下XPath的节点?
6.24 XPath中有哪些类型的运算符?
6.25 XPath中的/ // ./ …/ .//别有什么区别?
6.26 XPath中如何同时选取多个路径?
6.27 XPath中的*和@*分别表示什么含义?
6.28 如何使用位置属性选取节点中的元素?
6.29 XPath中如何多条件查找?
6.30 scrapy和lxml中的XPath用法有什么不同?
- scrapy里面的xpath默认就是使用的Selector下的xpath方法,返回的是一个Selector列表
- lxml里面的xpath默认就是使用的SelectorList下的xpath方法,返回的是一个内容列表
- 参考代码
# -*- coding:utf-8 -*-
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/16 11:52
Desc:
'''
# Selector和SelectorList都是属于selector.py模块,只是两种对象的结果不一样
# scrapy里面的xpath默认就是使用的Selector下的xpath方法,返回的是一个Selector列表
# lxml里面的xpath默认就是使用的SelectorList下的xpath方法,返回的是一个内容列表
from lxml import etree
from scrapy.selector import Selector
body = 'helloworld'
# scrapy下使用的是Selector类(返回结果是selector对象)下,
selectors = Selector(text=body)
print(type(selectors.xpath('//body/text()')))
print(selectors.xpath('//body/text()')) # 结果是一个selector列表
print(selectors.xpath('//body/text()').extract()) # 内容的列表
print(selectors.xpath('//body/text()').extract()[0])
print(selectors.xpath('//body/text()').extract_first()) # 推荐写法
print(selectors.xpath('//body/text()')[0]) # 不推荐写法
print(selectors.xpath('//body/text()')[0].extract()) # 不推荐写法
print('*' * 50)
# lxml下使用的xpath是SelectorList类(返回结果是selector对象的内容对象)下,因此可以直接列表取出内容
html = etree.HTML(body, etree.HTMLParser())
print(type(html.xpath('//body/text()')))
print(html.xpath('//body/text()'))
print(html.xpath('//body/text()')[0])
print(html.xpath('//body/text()')[-1])
[, ]
['hello', 'world']
hello
hello
hello
**************************************************
['hello', 'world']
hello
world
6.31 用过哪些常用的XPath开发者工具?
BeautifulSoup4
6.32 BeautifulSoup4是什么?有什么特点?
6.33 三种解析工具:正则表达式 lxml BeautifulSoup4各自有什么优缺点?
6.34 etree.parse()、etree.HTML()和etree.tostring()有什么区别?
6.35 BeautifulSoup4支持的解析器以及它们的优缺点?
6.36 BeautifulSoup4中的四大对象是什么?
6.37 BeautifulSoup4中如何格式化HTML代码?
6.38 BeautifulSoup4中find和find_all方法的区别?
6.39 string strings 和 stripped_strings有什么区别?
6.40 BeautifulSoup4输出文档的编码格式是什么?
7. 网络爬虫
7.1 网络爬虫是什么?它有什么特征?
7.2 Python中常用的爬虫模块和框架有哪些?它们有什么优缺点?
7.3 搜索引擎中的ROBOTS协议是什么?
7.4 urlib和requests库请求网页有什么区别?
7.5 网页中的ASCII Unicode UTF-8 编码之间的关系?
7.6 urllib如何检测网页编码?
7.7 urllib中如何使用代理访问网页?
7.8 如果遇到不信任的ssl证书,如何继续访问?
7.9 如何提取和使用本地已有的cookie信息?
7.10 requests请求中出现乱码如何解决?
7.11 requests库中response.text 和response.content的区别?
- response.text
- 类型:str
- 解码类型: 根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:response.encoding=”gbk”
- response.content
- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:response.content.deocde(“utf-8”)
- 区别
- 使用response.text 时,requests 会基于 HTTP 响应的文本编码自动解码响应内容,大多数 Unicode 字符集都能被无缝地解码。
- 使用response.content 时,返回的是服务器响应数据的原始二进制字节流,可以用来保存图片等二进制文件。
requests默认自带的Accept-Encoding导致或者网站默认发送的就是压缩之后的网页
但是为什么content.read()没有问题,因为requests,自带解压压缩网页的功能
当收到一个响应时,requests会猜测响应的编码方式,用于在你调用response.text方法时对响应进行解码。requests首先在HTTP头部检测是否存在指定的编码方式,如果不存在,则会使用chardet.detect来尝试猜测编码方式(存在误差)
更推荐使用response.content.decode()
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/16 12:52
Desc:
'''
# -*- coding:utf-8 -*-
import requests
url = "https://www.baidu.com"式
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"}
response = requests.get(url=url, headers=headers)
print(response.status_code)
response.encoding = "utf-8"
print(type(response.text))
# - 解码类型: 没有指定,默认utf-8
# - 如何修改编码方式:response.content.decode(“utf-8”)
print(type(response.content))
print(type(response.content.decode()))
200
7.12 实际开发中用过哪些框架?
7.13 Scrapy和PySpider框架主要有哪些区别?
7.14 Scrapy的主要部件及各自有什么功能?
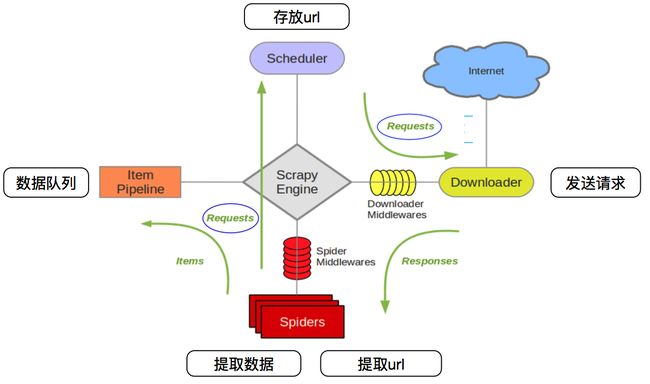
- Scrapy主要有5大部件和2个中间件
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
7.15 描述一下Scrapy爬取一个网站的工作流程?
7.16 Scrapy中的中间件有什么作用?
7.17 Scrapy项目中命名时候要注意什么?
7.18 Scrapy项目中的常用命令有哪些?
7.19 scrapy.Request()中的meta参数有什么作用?
7.20 Python中的协程阻塞问题如何解决?
7.21 Scrapy中常用的数据解析提取工具有哪些?
7.22 描述一下Scrapy中数据提取的机制?
7.23 Scrapy是如何实现去重的?指纹去重是什么?
7.24 Item Pipeline有哪些应用?
7.25 Scrapy中常用的调试技术有哪些?
7.26 Scrapy中有哪些常见异常以及含义?
7.27 Spider、CrawlSpider、XMLFeedSpider和RedisSpider有什么区别?
7.28 scrapy-redis是什么?相比scrapy有什么优缺点?
7.29 使用scrapy-redis分布式爬虫,需要修改哪些常用的配置?
7.30 常见的反爬虫措施有哪些?如何应对?
7.31 BloomFitler是什么?它的原理是什么? - BloomFilter是一种空间效率很高的随机数据结构,它利用位数组很简洁的表示一个集合,并能判断一个元素是否属于这个集合。
- BloomFilter使用多个哈希函数来降低错误率。基本原理:通过k个hash函数将这个元素映射到位数组的k个点,将他们设置为1。检索时,我们查看这k个点是否都为1就能够判断元素是否在BloomFilter中(会有一定的误差率);如果k个点有一个点不为1,那么这个元素肯定不在BloomFilter里面。
- python中使用BloomFilter
# -*- coding: utf-8 -*-
from pybloom import BloomFilter
# 创建一个一个容量为1000,漏失率为0.001的布隆过滤器
f = BloomFilter(capacity=1000, error_rate=0.001)
for x in range(10):
f.add(x)
print(f)
# 判断数字是否在容器(数据库)中
print(11 in f)
print(2 in f)
False
True
7.32 为什么会用到代理?代码展现如何使用代理?
7.33 爬取的淘宝某个人的历史消费信息(登陆需要账号、密码、验证码),你会如何操作?
7.34 网站中的验证码是如何解决的?
7.35 动态页面如何有效的抓取?
7.36 如何使用MondoDB和Flask实现一个IP代理池?
8. 数据分析及可视化
8.1 Python数据分析通常使用的环境、工具和库都有哪些?库功能是什么?
8.2 常用的数据可视化工具有哪些?各自有什么优点?
8.3 数据分析的一般流程是什么?
8.4 数据分析中常见的统计学概念有哪些?
8.5 归一化方法有什么作用?
8.6 常见数据分析方法论?
8.7 如何理解欠拟合和过拟合?
8.8 为什么说朴素贝叶斯是“朴素”的?
8.9 Matplotlib绘图中如何显示中文?
8.10 Matplotlib中如何在一张图上面画多张图?
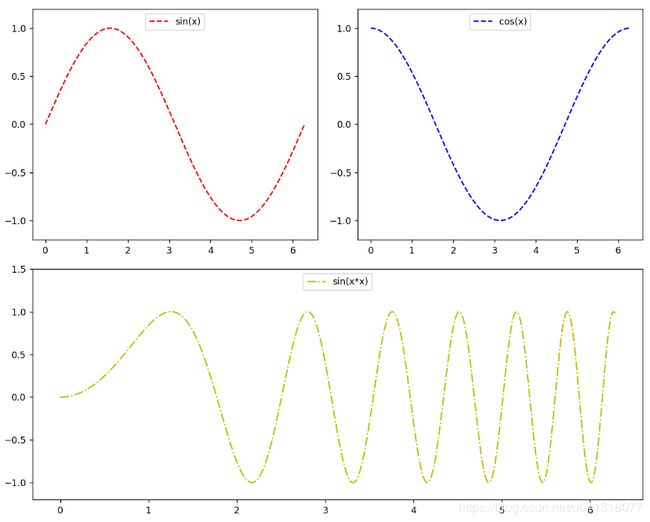
- 参考代码
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/12 15:50
Desc:
'''
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
#创建自变量数组
x= np.linspace(0,2*np.pi,500)
#创建函数值数组
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.sin(x*x)
#创建图形
plt.figure(figsize=(10, 8), dpi=128)
'''
多图形绘制需要设置图形所在位置:
subplot(numRows, numCols, plotNum)
前两个参数自动将图形分隔为几行几列,
第三个参数为从左上角开始,从左到右,从上到下图形所在的位置
如果有一行只有一列,那么其它行不同列也当做一个整体,就是一列
比如下面:subplot(2,2,1),分成2行2列的第1个元素
subplot(2,2,2),分成2行2列的第2个元素
subplot(2,1,2),分成2行1列的第2个元素,第一行所有列当做一个整体
'''
# 设置绘制图形的位置
#第一行第一列图形
ax1 = plt.subplot(2,2,1)
#第一行第二列图形
ax2 = plt.subplot(2,2,2)
#第二行的一个图形
ax3 = plt.subplot(2,1,2)
# 绘制ax1,先传入图形位置
plt.sca(ax1)
# 绘制红色曲线
plt.plot(x, y1, label='sin(x)', color='red', linestyle='--')
# 限制y坐标轴范围
plt.ylim(-1.2,1.2)
# 显示图例
plt.legend(loc='upper center')
# 绘制ax2
plt.sca(ax2)
# 绘制蓝色曲线,线条颜色和风格可以使用以下缩写方式
plt.plot(x, y2, 'b--', label='cos(x)')
plt.ylim(-1.2,1.2)
# 显示图例
plt.legend(loc='upper center')
# 绘制ax3
plt.sca(ax3)
plt.plot(x, y3, 'y-.', label='sin(x*x)')
plt.ylim(-1.2,1.5)
# 显示图例
plt.legend(loc='upper center')
plt.show()
8.11 使用直方图展示多部电影3天的票房情况?
8.12 如何绘制嵌套图?
- 参考代码
'''
Author: Felix
WX: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2019/12/16 10:59
Desc:
'''
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
# 显示中文和显示负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义一个画布
fig = plt.figure(figsize=(8, 6))
# 定义一个函数
def f(x):
return 1/(1 + x**2) + 0.1/(1 + ((3 - x)/0.1)**2)
# 定义一个绘图方法
def plot_and_format_axes(ax, x, f, fontsize):
ax.plot(x, f(x), lw=3, color='blue')
ax.xaxis.set_major_locator(mpl.ticker.MaxNLocator(5)) # X轴显示5个刻度
ax.yaxis.set_major_locator(mpl.ticker.MaxNLocator(4)) # Y轴显示5个刻度
ax.set_xlabel(r"$x$", fontsize=fontsize)
ax.set_ylabel(r"$f(x)$", fontsize=fontsize)
# 主图,添加主图在画布的位置(占画布的比例),离左侧10%,底部15%,宽80%,高80%,背景色
ax_max = fig.add_axes([0.1, 0.15, 0.8, 0.8], facecolor="#f5f5f5")
x = np.linspace(-4, 14, 1000)
plot_and_format_axes(ax_max, x, f, 18)
# 局部图,添加局部图绘图的位置
# 局部图X轴取值范围
x0, x1 = 2.5, 3.5
ax_min = fig.add_axes([0.5, 0.5, 0.38, 0.4], facecolor=None)
x = np.linspace(x0, x1, 1000)
plot_and_format_axes(ax_min, x, f, 14)
# 展示图形
plt.show()

8.13 描述一下numpy array对比python list的优势?
8.14 如何处理缺失数据?
8.15 数据清洗要遵循什么原则?