JVM垃圾收集器
新生代垃圾收集器
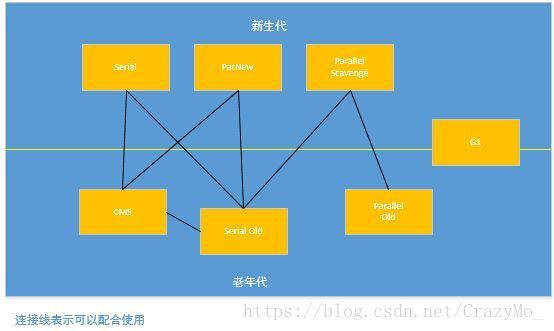
Serial
此垃圾收集器年代久远,用于新生代的垃圾收集,采用复制算法。是单线程的垃圾收集器也就是不管你的服务器有多少CPU,反正它就用其中的一个CPU启动一个线程去处理垃圾回收,并且停止所有工作线程等待它回收完成。所以它在收集时会STW(stop the world)。能与其搭配的老年代收集器是CMS与Serial Old。

Serial与Serial Old搭配
单线程的好处就在于它简单,没有上下文线程切换的开销。多用于桌面应用中,也就是适用于client模式。因为桌面应用一般占用的内存不大,内存不大代表需要处理的垃圾不多,所以即使单线程也能处理很快,所以感受不到STW。是client模式下默认的新生代垃圾收集器。
ParNew
此垃圾收集器可以说是Serial的多线程版本,它和Serial的差别就在于复制的时候是多线程的。
ParNew与Serial Old搭配
它主要是能利用多CPU,提升复制的速度,减少STW的时间。但是在单CPU情况下不要使用它,因为线程切换有开销,性能不一定会比Serial好,当然如果CPU数很多的话那性能肯定是比Serial好的。所以在Server模式下可以用它来作为新生代垃圾处理器。能与其搭配的老年代收集器是CMS与Serial Old。
Parallel Scavenge
Scavenge是捡破烂的意思...恩并行捡破烂说的是好像没错,用的也是复制算法。那不是已经在ParNew了吗,怎么还来个并行的。它和ParNew主要有两个不同点
1、Parallel Scavenge的关注点在于可控制的吞吐量,吞吐量=运行用户代码的时间/(运行用户代码的时间+GC时间)。就是说它的重点不在于想缩短每次GC的时间,而在于控制虚拟机运行一段时间中,所花费在GC上的总时间。比如程序运行了100分钟,其间垃圾收集了1分钟,那吞吐量就是99%。
2、Parallel Scavenge能自适应调节新生代中配置的参数,例如Eden和survivor比例等。其实就是因为它能自适应,所以才能可控制吞吐量,它根据实际情况动态调整这些参数来达到要求的吞吐量。
此收集器也提供了“-XX:MaxGCPauseMillis”控制垃圾收集最大停顿时间(允许值大于0),“-XX:GCTimeRatio”吞吐量(1-99)。
看到“-XX:MaxGCPauseMillis”,别以为我们想设置多少就多少,收集器只能尽可能的保证而已。而且说白了能如果想提高新生代GC的速度,那就是减少新生代的内存空间,内存空间少垃圾肯定少处理起来肯定快。但是空间少是不是更快的容易满啊,所以所需的GC次数肯定会增多,那吞吐量也会下降。
比如说一个程序现在跑在服务器上,假设每次新生代GC时间是100毫秒,每10秒钟一次新生代GC,那一分钟花费在GC上的时间就是600毫秒。那我想每次花在GC时间更少比如60毫秒,那就减少新生代内存空间,但是这样每5秒钟一次GC,那一分钟花费在GC上的时间就是720毫秒。
对应使用的场景就是如果你的服务是计算类的,默默在后台计算,和用户交互很少,所以你肯定想的是吞吐量大,也就是总的GC时间短,能充分的用了CPU来计算,这个时候就适合用Parallel Scavenge。
那如果你的程序是交互类的,你的要求肯定就是STW的时间越短越好,能快速响应客户的请求。Parallel Scavenge也行,但是它不能和CMS联合使用呀!因为Parallel Scavenge没有使用原本HotSpot中和其它GC通用的那个GC框架,而是新框架。所以默认和CMS搭配的就是ParNew。

Parallel Scavenge与Parallel Old搭配
老年代垃圾收集器
Serial Old
它是Serial 收集器的老年代版本,是单线程收集,采用的是标记-整理算法。主要用于client模式和CMS的后备收集器。除了G1,上面说的几个新生代收集器都可以与它搭配使用。图请参考上面Serial。
Paraller Old
它是Parallel Scavenge的老年代版本,是多线程收集,采用的是标记-整理算法。它只能和Parallel Scavenge搭配。它的出现打破了Parallel Scavenge尴尬的地位,因为之前Parallel Scavenge只能和Serial Old配合,人家新生代都多线程跑了,奈何老年代只有单线程,拖累它了。图请参考上面Parallel Scavenge。
CMS
CMS(Concurrent Mark Sweep),从名字可以看出它采用的是标记-清除算法。它致力于减少STW的时间,让垃圾收集时同时用户线程也能并行着。在目前的Server主流垃圾收集器。
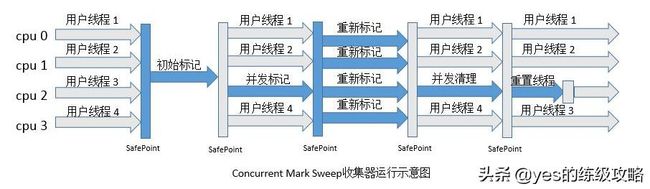
CMS
它的垃圾收集步骤分为以下4步:
1、初始标记(会STW)
2、并发标记
3、重新标记(会STW)
4、并发清理
初始标记就是仅标记GC Roots直接关联的对象,不继续深入标记,致力于减少STW时间。并发标记就是深入标记遍历后面所有关联对象。重新标记就是修正因并发标记阶段而发生变动了的对象标记会STW。然后就是并发清理垃圾。
所以CMS把所需消耗时间最长的深入标记阶段和清理阶段与用户线程并行。大大减少了STW所需的时间。
但是它有以下3个缺点:
1、并发阶段会与工作线程争抢CPU资源
2、空间碎片问题,因为采取的是标记-清除算法所以会产生空间碎片。为什么解决这个问题CMS提供了"-XX:+UseCMSCompactAtFullCollection"(默认开启),用于当CMS顶不住需要进行FullGC时整理空间碎片,但是整理的过程是用户线程是得停止工作的,所以停顿的时间会变长。
3、浮动垃圾问题。因为在并发清理的时候允许用户线程继续执行,而执行就可能产生新的垃圾进入老年代,所以需要预留一部分空间给这些浮动垃圾,而当这些浮动垃圾过多在CMS运行期间爆了,那CMS就会出现“Concurrent Mode Failure”,这是时候就得后备的Serial Old上来重新进行老年代的垃圾收集,所以停顿的时间就更长了。
G1
此垃圾收集器不需要和别人配合,自己处理新生代和老年代。在jdk9中G1变为Server模式默认的垃圾收集器。它的发明就是为了替代CMS。
G1(Garbage-First)从整体来看是基于标记-整理的算法,从局部来看是基于复制算法。它和CMS一样可以和用户进程并行。相对于CMS 它的优点是首先它能建立可预测的停顿时间模型,能在一个规定的时间段内指定垃圾收集的时间不超过限制的毫秒数,并且它将Java堆分为多个大小相等的独立区域,也就是Region。虽然它还保留着分代的概念,但是新生代和老年代不是物理隔离了。它的清理区间不再是整个新生代或者老年代,而是以区域为划分,不会产生空间碎片。
G1会维护一个优先列表,根据跟踪各个region回收所能产生的空间大小和时间来标定优先级,优先回收优先级最大的Region。这就等于每次的回收目标更加精确化,提高回收的效率
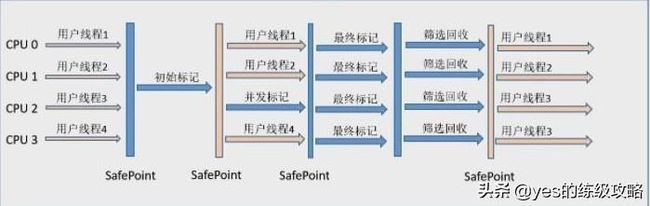
G1的收集步骤可分为:
1、初始标记
2、并发标记
3、最终标记
4、筛选回收
G1
初始标记和CMS一样先标记GC Roots直接关联对象,然后并发深入标记,遍历关联对象。最终标记和CMS重新标记一个概念,筛选回收也就是筛选下决定回收哪个Region价值更大。