十分钟学会pandas《10 Minutes to pandas》
pandas官方网站上的《10 Minutes to pandas》点这里查看,讲解浅显易懂,本文在官网的基础上作了补充。详细的介绍请参考:Cookbook 。pandas是非常强大的数据分析包,pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包。就好比 Numpy 的核心是 ndarray,pandas 围绕着 Series 和 DataFrame 两个核心数据结构展开 。Series 和 DataFrame 分别对应于一维的序列和二维表结构。
1. 创建对象
2. 查看数据
3. 选择
4. 缺失值处理
5. 相关操作
6. 合并
7. 分组
8. Reshaping
9. 时间序列
10. Categorical
11. 可视化
12. 导入导出数据
pandas 约定俗成的导入方法如下:
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: import matplotlib.pyplot as plt
1. 创建对象
这里详细讲讲几类对象:
1.1 Series
Series 可以看做一个定长的有序字典,它是能够保存任何数据类型(整数,字符串,浮点数,Python对象等)的一维标记数组。Series 对象包含两个主要的属性:index 和 values。 创建一个Series对象的基本方法是调用:
In [1]: s = pd.Series(data, index=index)在这里,数据可以是很多不同的东西:
Python字典
ndarray
scalar value标量值(如5)
传递的索引是轴标签列表。 因此,根据什么数据分为几种情况:
从ndarray
如果数据是ndarray,则索引的长度必须与数据相同。 如果没有传递索引,将创建一个具有值[0,…,len(data) - 1]的索引。
1. dict
In [7]: d = {'a' : 0., 'b' : 1., 'c' : 2.}
In [8]: pd.Series(d)
Out[8]:
a 0.0
b 1.0
c 2.0
dtype: float64
In [9]: pd.Series(d, index=['b', 'c', 'd', 'a'])
Out[9]:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float642. ndarray
#指定索引
In [5]: s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
In [6]: s
Out[6]:
a 0.2941
b 0.2869
c 1.7098
d -0.2126
e 0.2696
dtype: float64
In [7]: s.index
Out[7]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
#不指定索引的默认情况
In [8]: pd.Series(np.random.randn(5))
Out[8]:
0 -0.4531
1 -1.8215
2 -0.1263
3 -0.1533
4 0.4055
dtype: float643. scalar value
In [10]: pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
Out[10]:
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float644. 引用
In [8]: s = pd.Series(np.random.randn(5), index=['a', 'b', 'c
...: ', 'd', 'e'])
In [9]: s[0]
Out[9]: -0.054946649009729349
In [10]: s[:3]
Out[10]:
a -0.054947
b -0.662185
c 0.932696
dtype: float64
In [11]: s[s > s.median()]
Out[11]:
a -0.054947
c 0.932696
dtype: float64
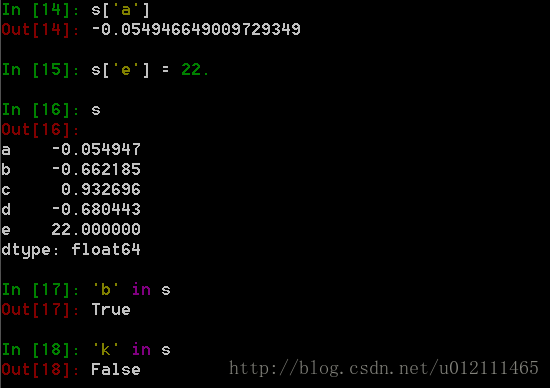

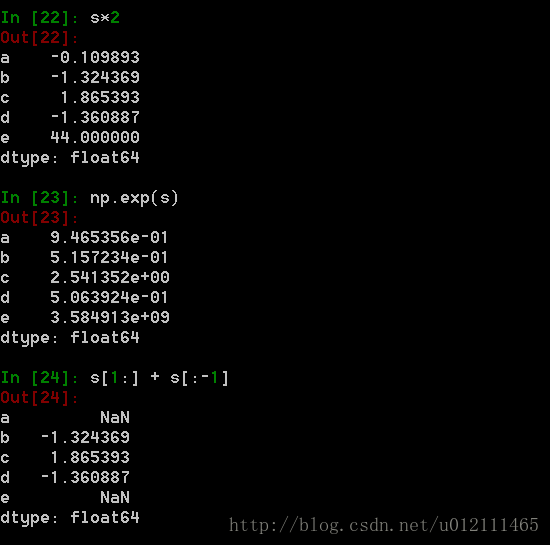
名字属性,及其修改

1.2 DataFrame
DataFrame是二维标记数据结构。 您可以将其视为电子表格或SQL表,或Series对象。 它通常是最常用的pandans对象。 像Series一样,DataFrame接受许多不同种类的输入:
Dict of 1D ndarrays, lists, dicts, or Series
2-D numpy.ndarray
Structured or record ndarray
A Series
Another DataFrame
1. From dict of Series or dicts
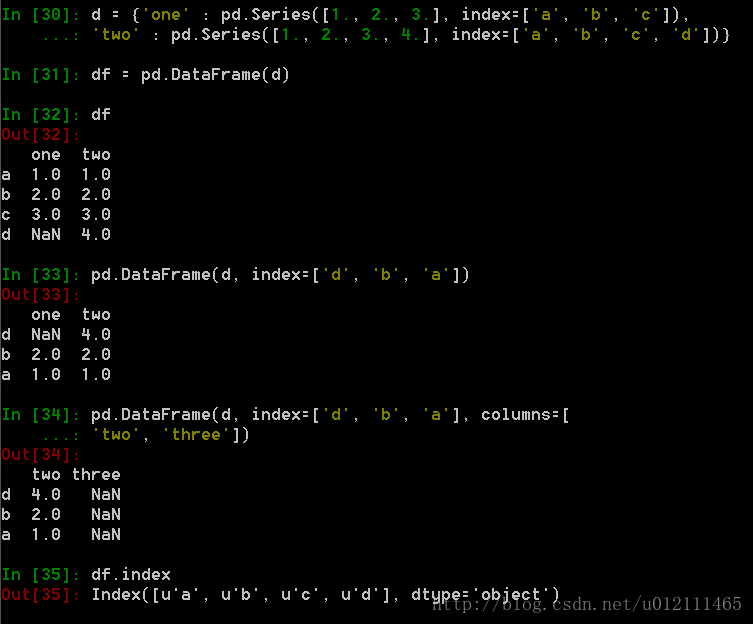

2. From dict of ndarrays / lists
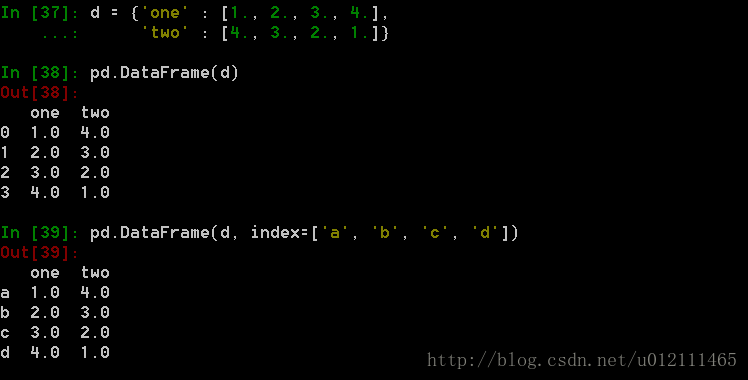
3. From structured or record array

4. From a list of dicts
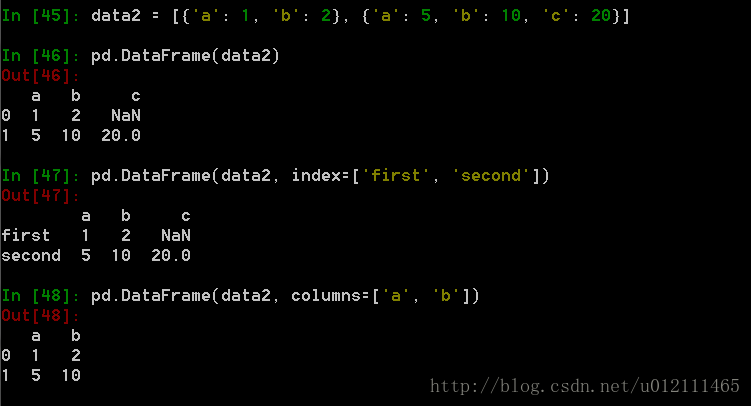
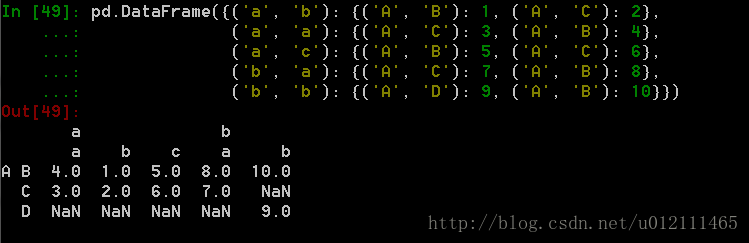
5. From a dict of tuples
2. 查看数据
1. 查看frame中头部和尾部的行

2. 显示索引、列和底层的numpy数据

3. describe()函数对于数据的快速统计汇总

4. 对数据的转置

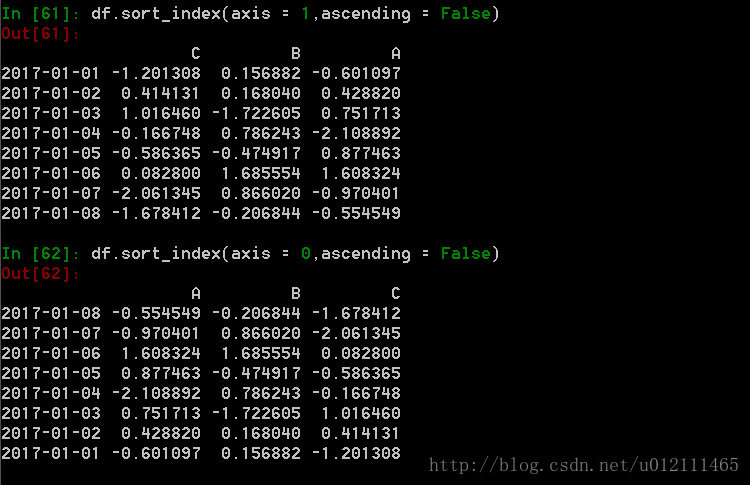
5. 按轴进行排序
6. 按值进行排序

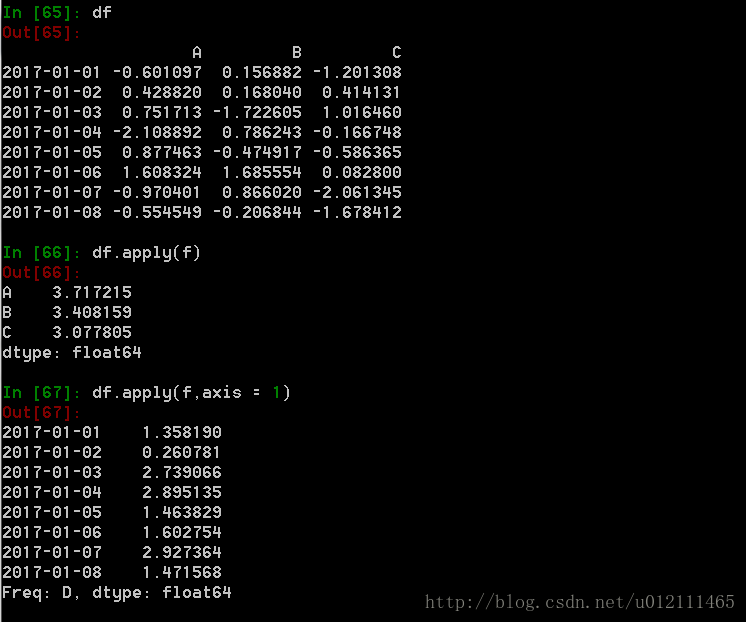
7. 函数应用和映射
Numpy 的 ufuncs(元素级数组方法)也可用于操作 pandas 对象。当希望将函数应用到 DataFrame 对象的某一行或列时,可以使用 .apply(func, axis=0, args=(), **kwds) 方法。
3. 选择
1. 获取
1. 选择一个单独的列,这将会返回一个Series,等同于df.A:

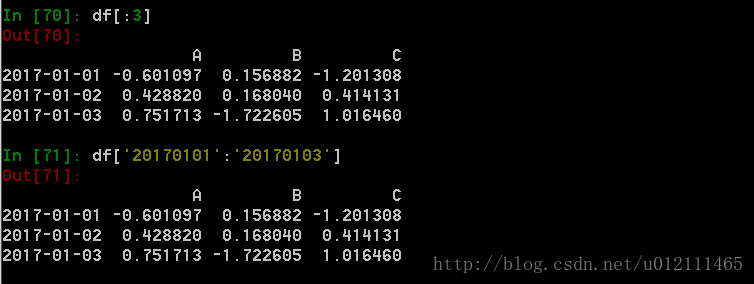
2. 通过[]进行选择,这将会对行进行切片
2. 通过标签选择
1. 使用标签来获取一个交叉的区域

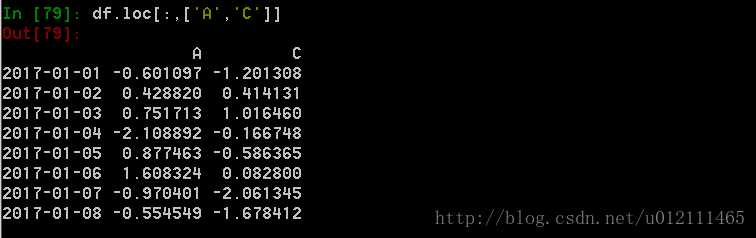
2. 通过标签来在多个轴上进行选择
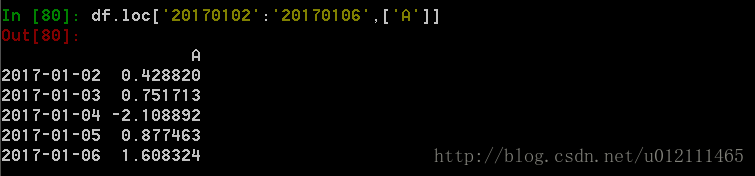
3. 标签切片
4. 对于返回的对象进行维度缩减

5. 获取一个标量

6. 快速访问一个标量(与上一个方法等价)

3. 通过位置选择
1. 通过传递数值进行位置选择(选择的是行)

2. 通过数值进行切片,与numpy/python中的情况类似

3. 通过指定一个位置的列表,与numpy/python中的情况类似

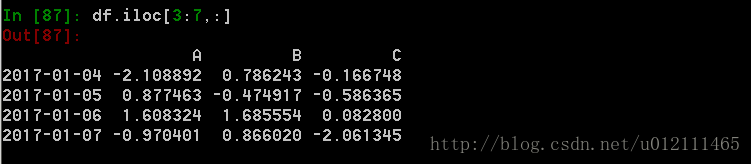
4. 对行进行切片
5. 对列进行切片

6. 获取特定的值
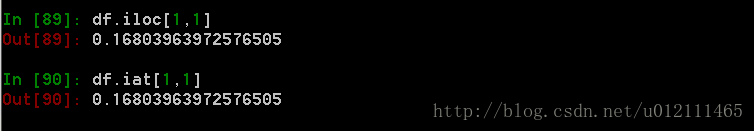
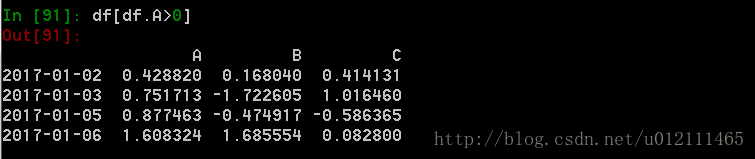
4. 布尔索引
1. 使用一个单独列的值来选择数据:
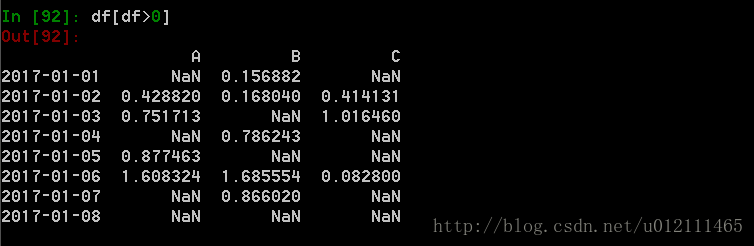
2. 使用where操作来选择数据:
3. 使用isin()方法来过滤:


5. 设置
1. 设置一个新的列:

2. 通过标签设置新的值:

3. 过位置设置新的值:
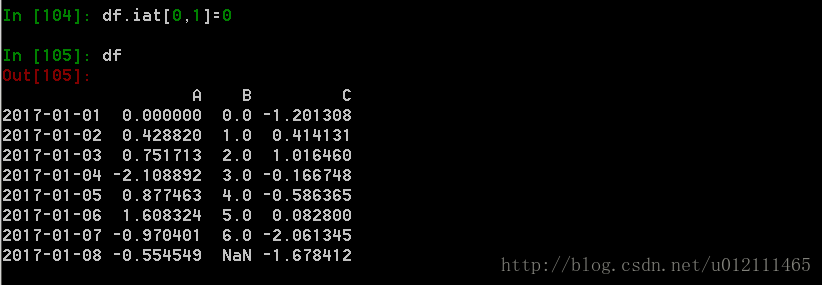
4. 通过一个numpy数组设置一组新值:

5. 通过where操作来设置新的值:
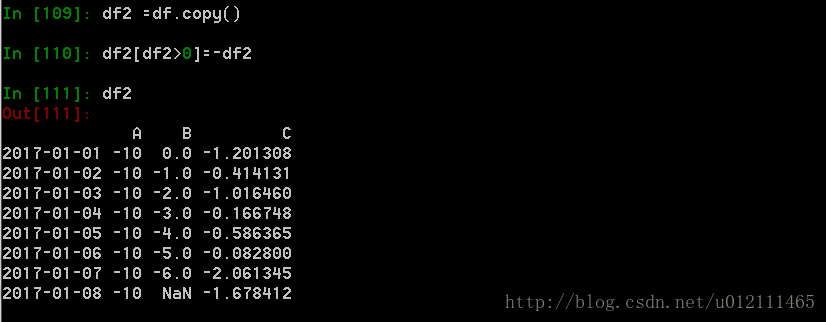
4. 缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:Missing Data Section。
1. reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝

2. 去掉包含缺失值的行

3. 对缺失值进行填充

4. 对数据进行布尔填充
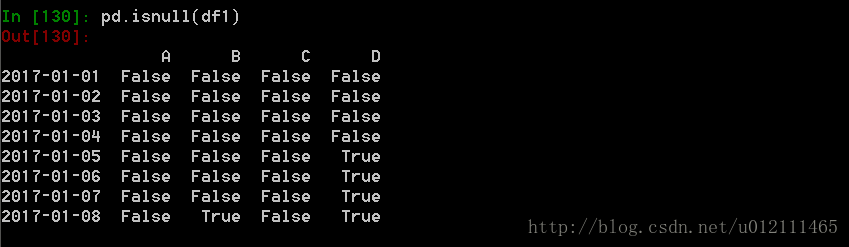
5. 相关操作
其他更详细的操作请参考文档 Basic Section On Binary.
1. 统计
- 执行描述性统计

- 在其他轴上进行相同的操作

- 对于拥有不同维度,需要对齐的对象进行操作。Pandas会自动的沿着指定的维度进行广播

2. Apply
对数据运用函数

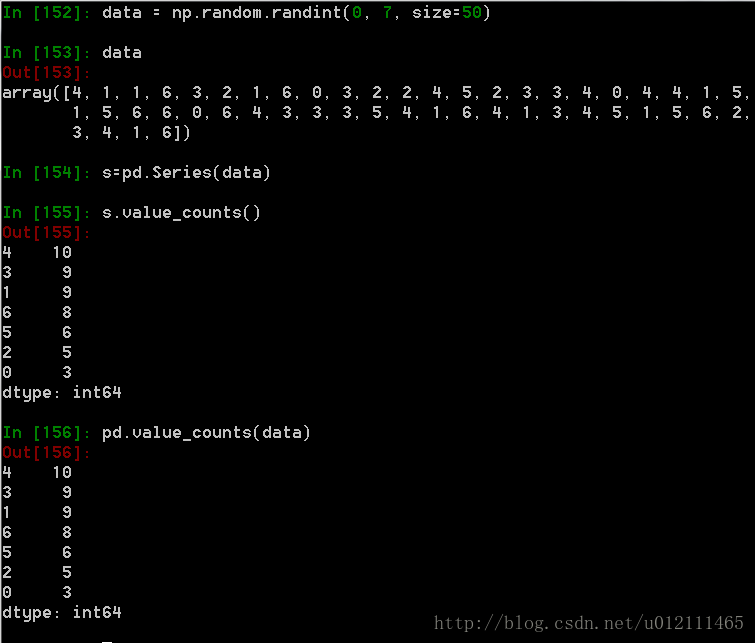
3. 直方图
具体请参考文档:Histogramming and Discretization.
value_counts()系列方法和高级函数计算一维数组值的直方图。 它也可以用作常规数组的函数:
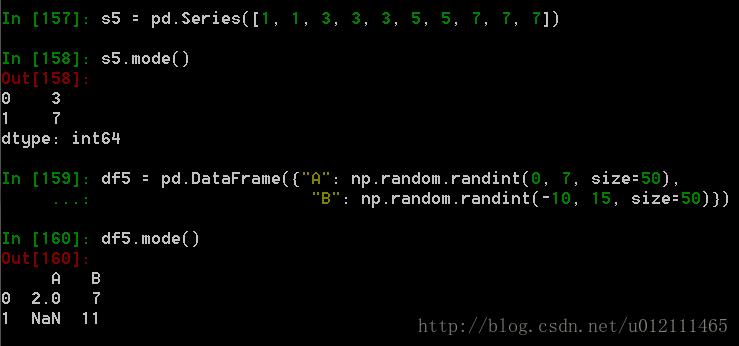
类似地,可以获取Series或DataFrame中值的最常出现的值(模式):
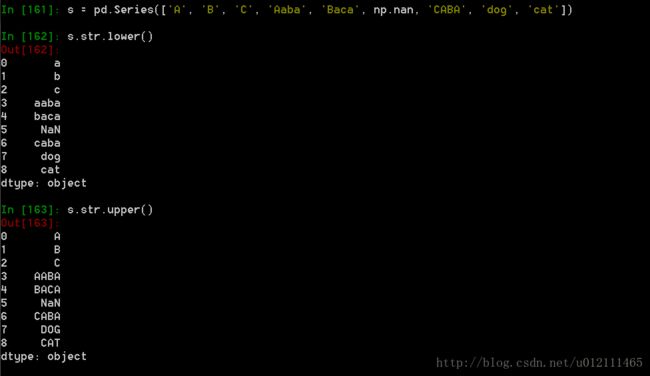
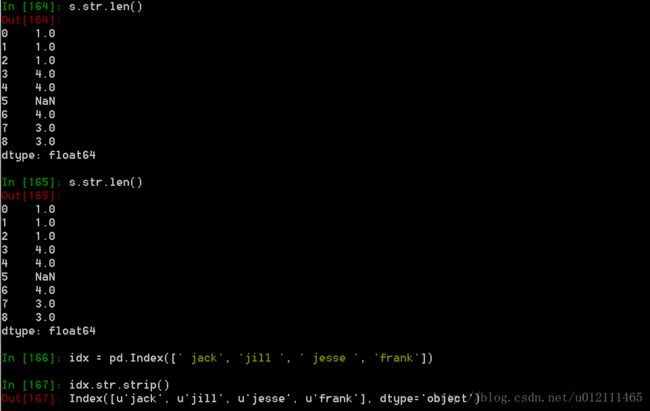
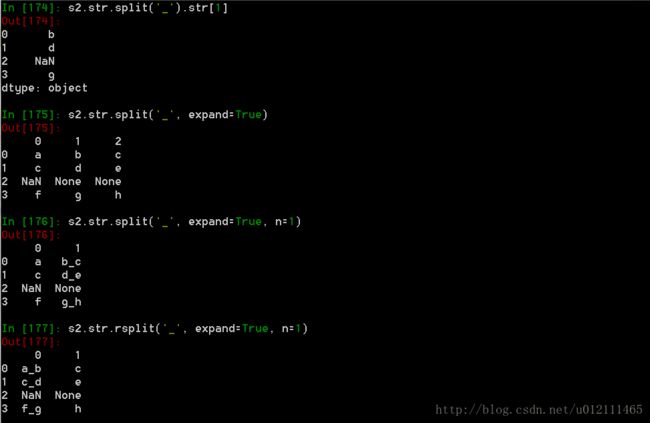
4. 字符串方法
Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素。更多详情请参考:Vectorized String Methods.

6. 合并
Pandas提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:Merging section
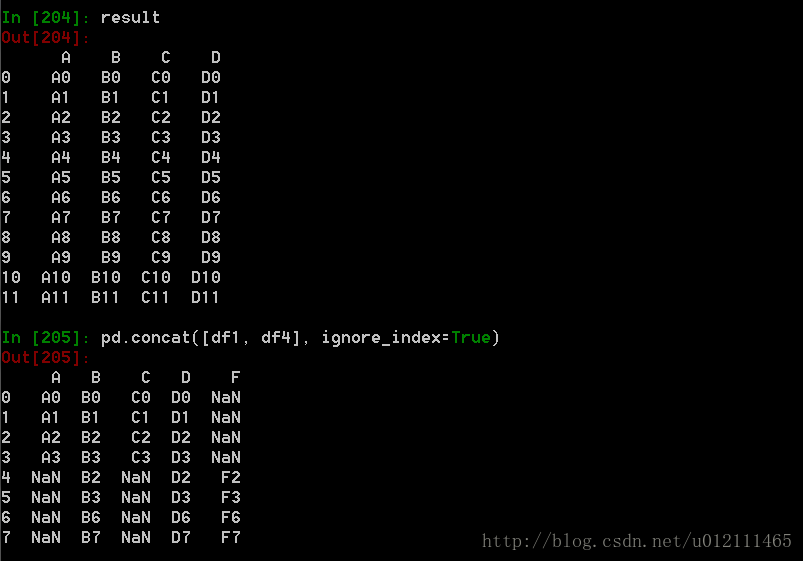
1. Concat
函数格式:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True)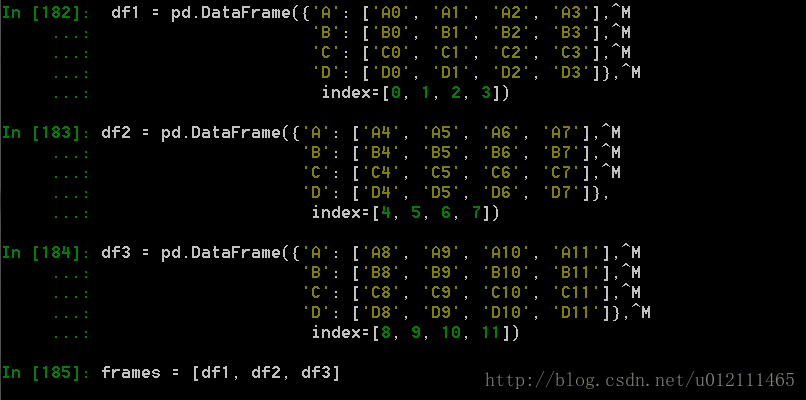
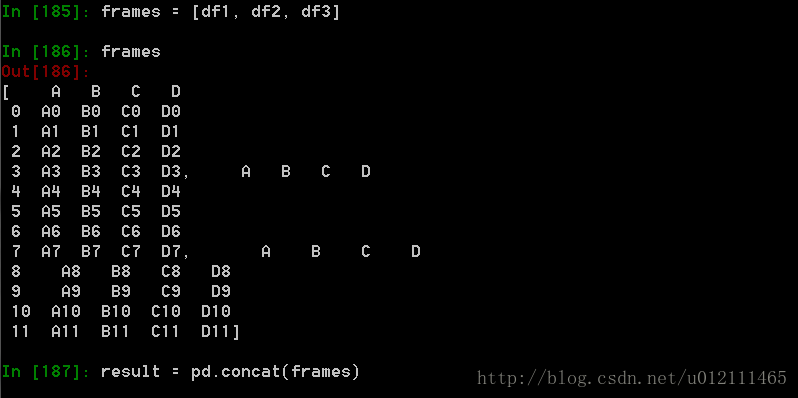

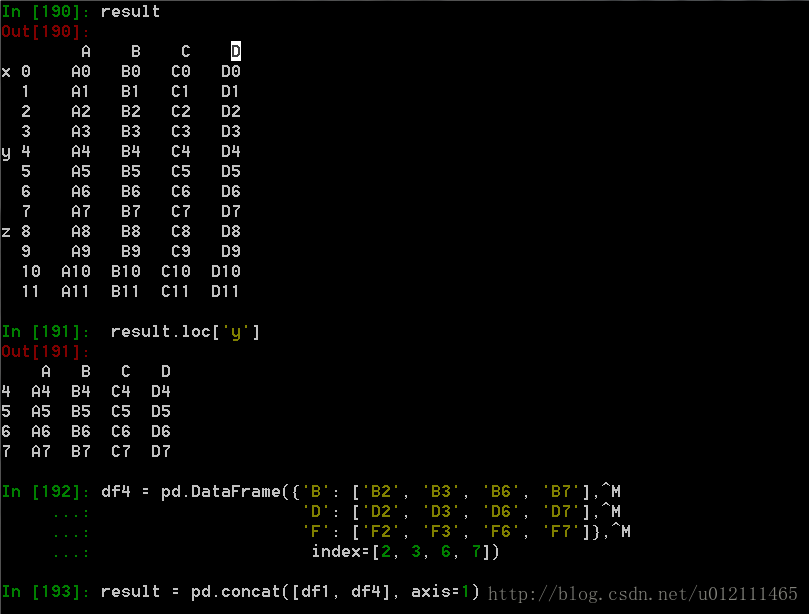
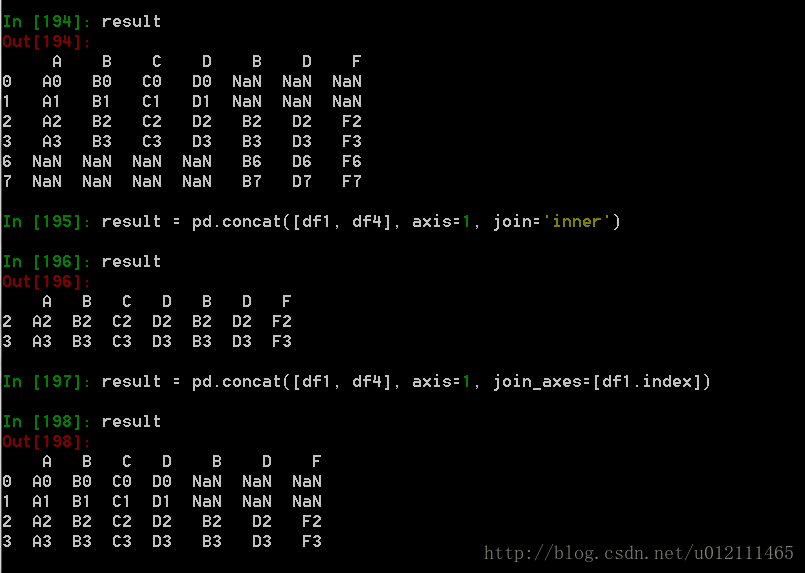
Appending


merge
函数格式:
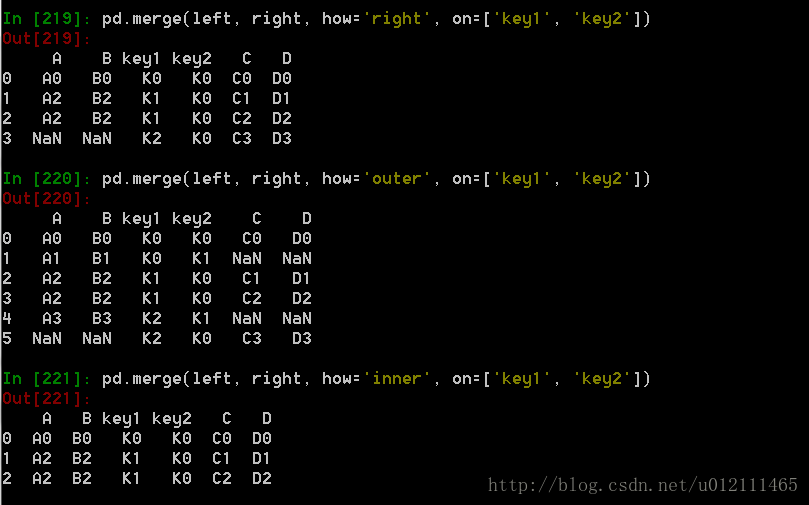
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True, indicator=False)


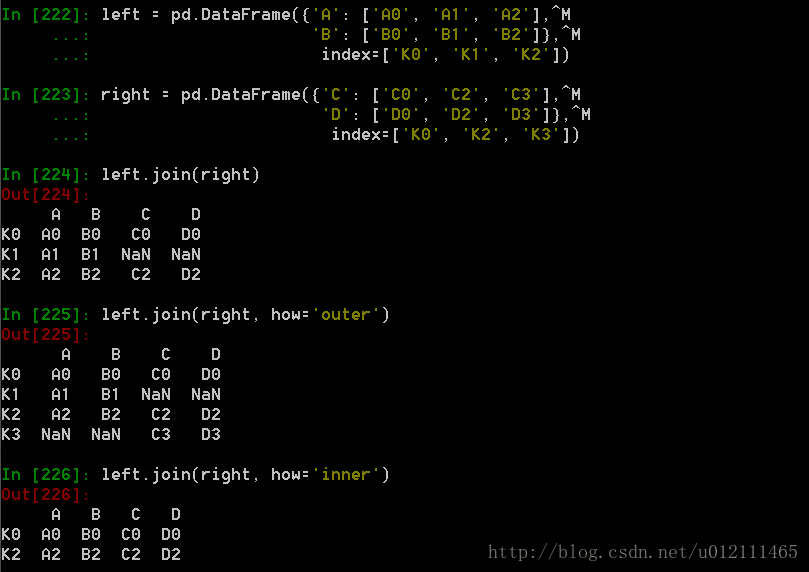
3. join
Join 类似于SQL类型的合并,具体详情请参阅:Database style joining

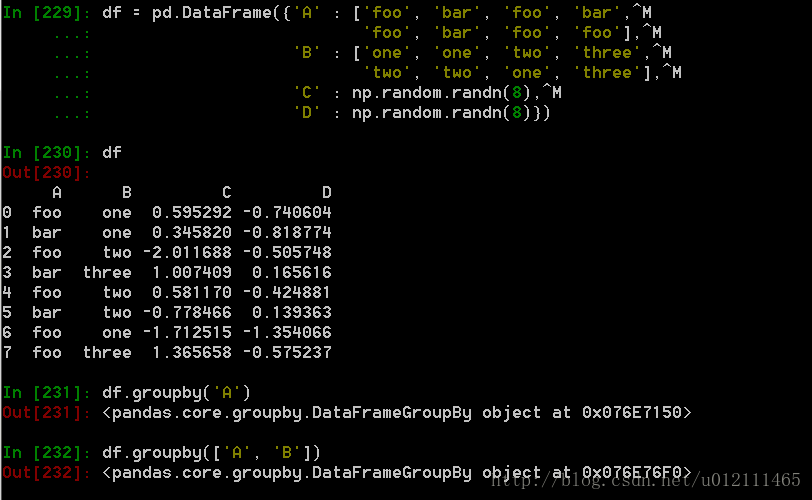
7. 分组
对于”group by”操作,我们通常是指以下一个或多个操作步骤:
(Splitting)按照一些规则将数据分为不同的组;
(Applying)对于每组数据分别执行一个函数;
(Combining)将结果组合到一个数据结构中;
详情请参阅:
Grouping section
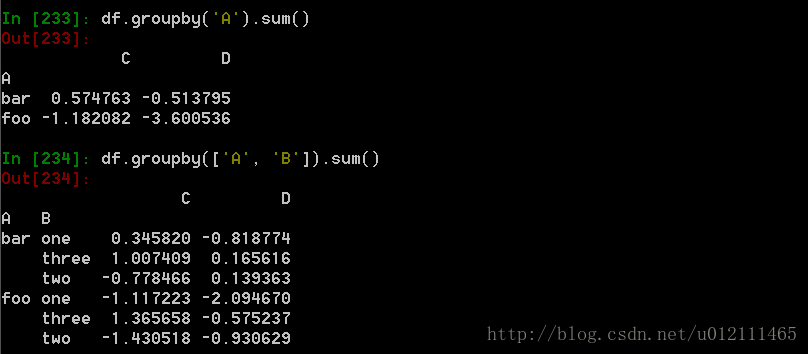
执行sum函数
8. Reshaping
详情请参阅here
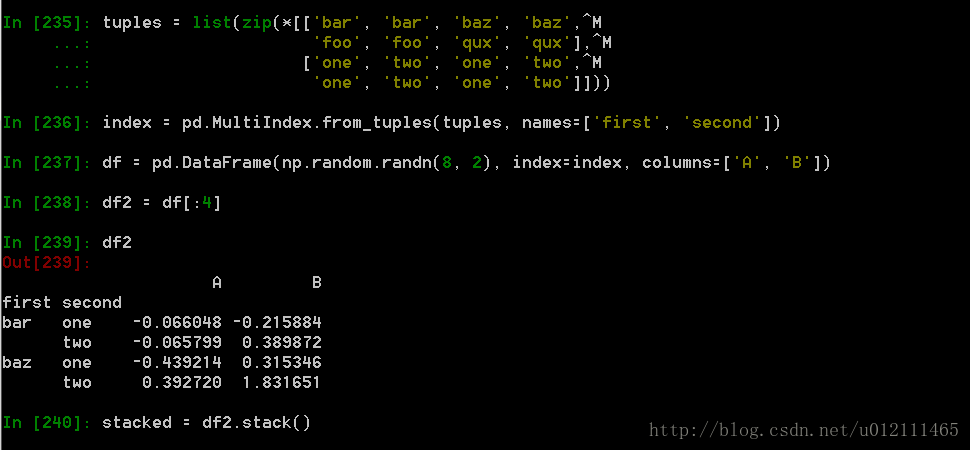
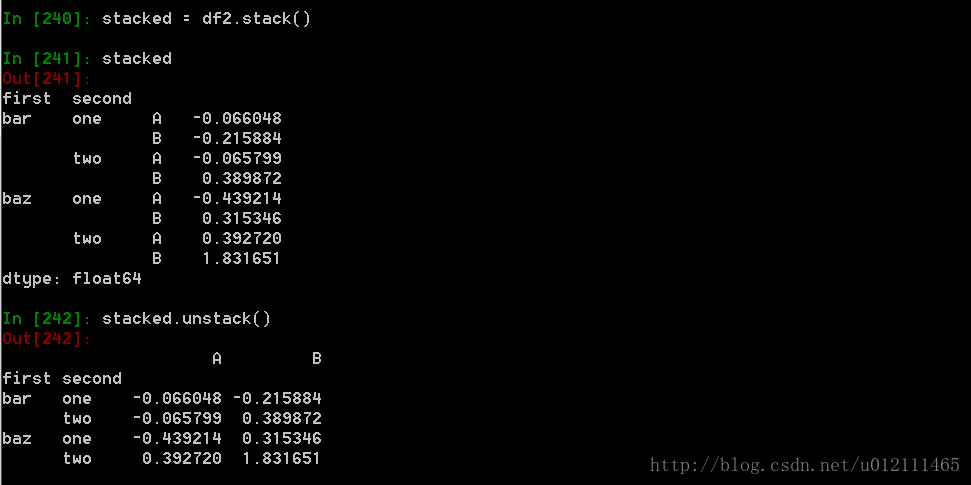
Stack

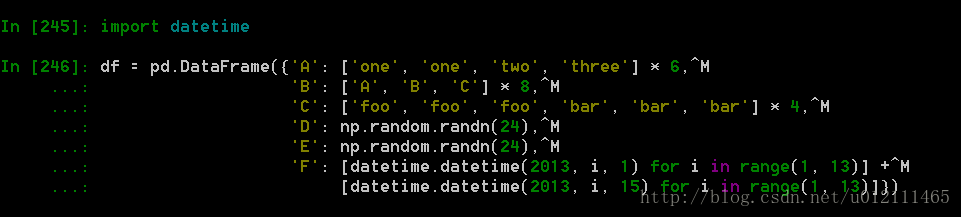
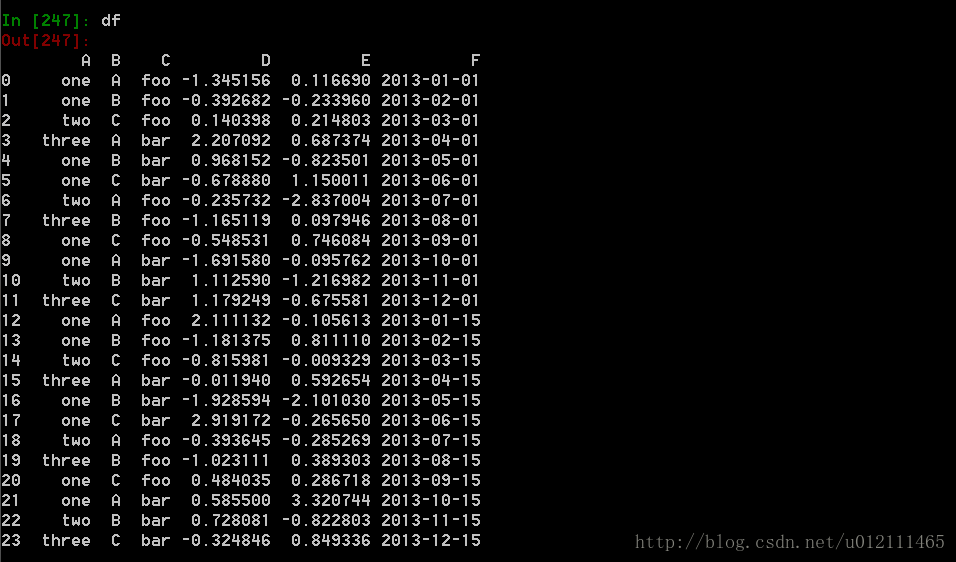
数据透视表
详情请参阅:here
可以从这个数据中轻松的生成数据透视表:
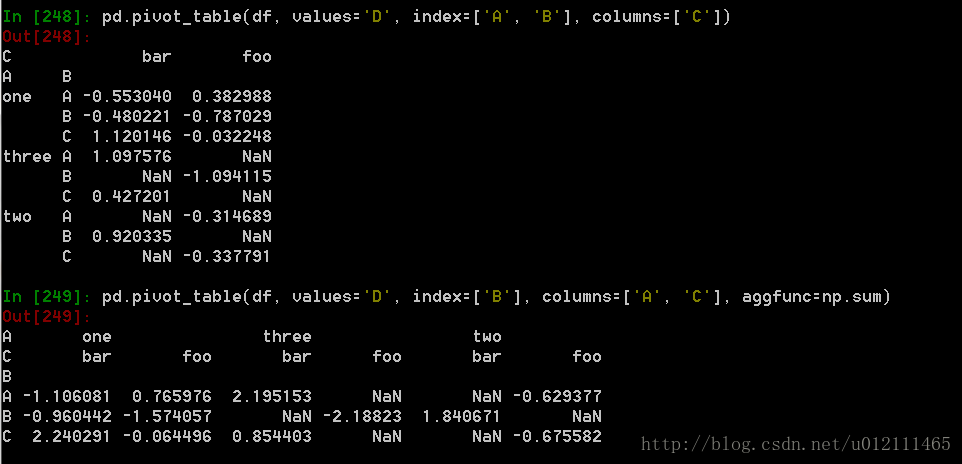
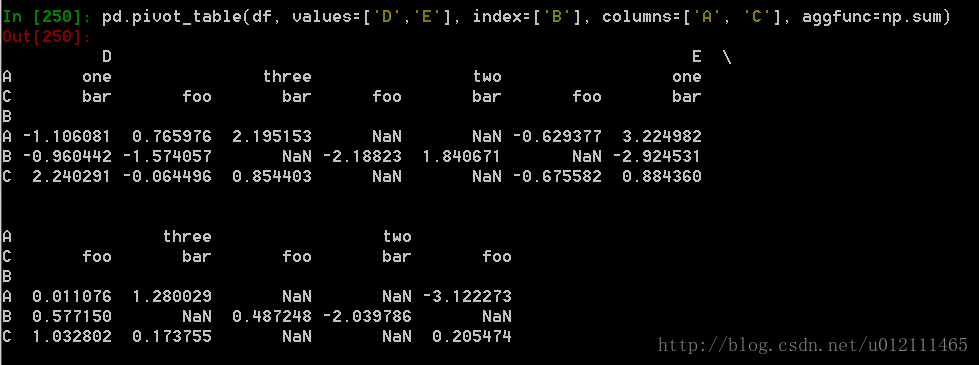
9. 时间序列
Pandas在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。详情参考:here。
时区表示

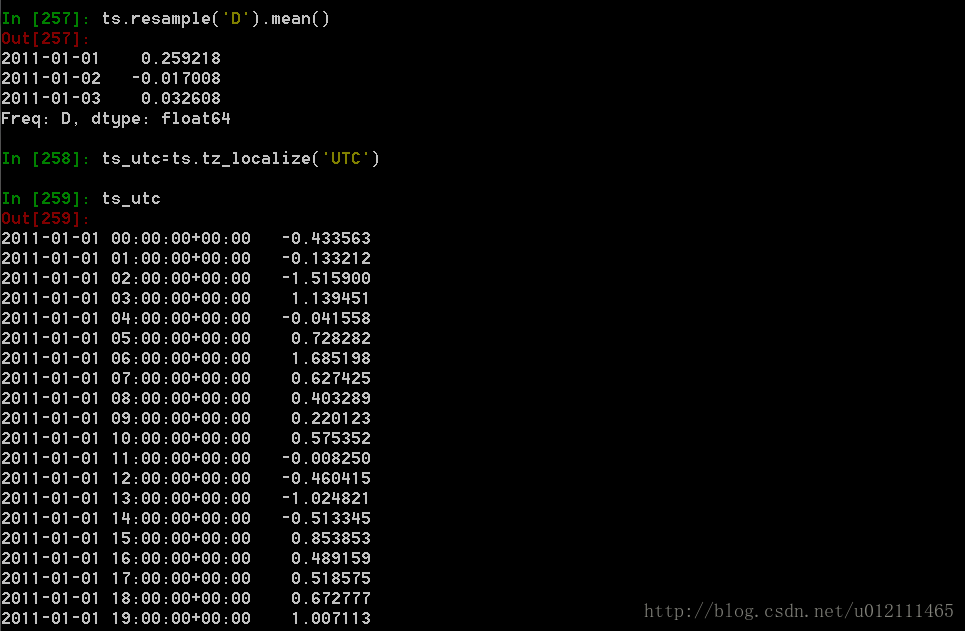
时区转换

时间跨度转换

时期和时间戳之间的转换使得可以使用一些方便的算术函数

10. Categorical
从0.15版本开始,pandas可以在DataFrame中支持Categorical类型的数据,详细 介绍参看:categorical introduction/API documentation
1. 将原始的grade转换为Categorical数据类型
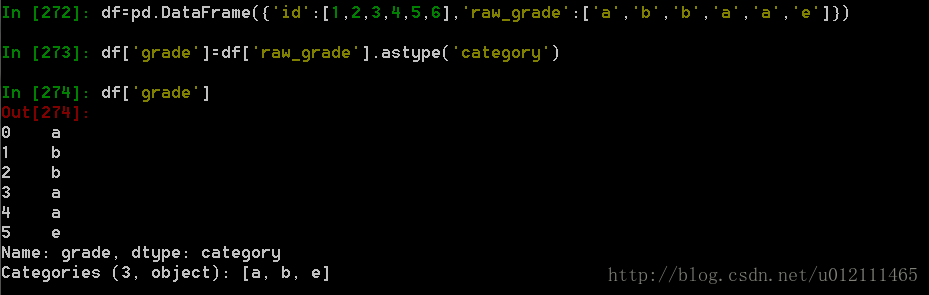
2. 将Categorical类型数据重命名为更有意义的名称
![]()
3. 对类别进行重新排序,增加缺失的类别
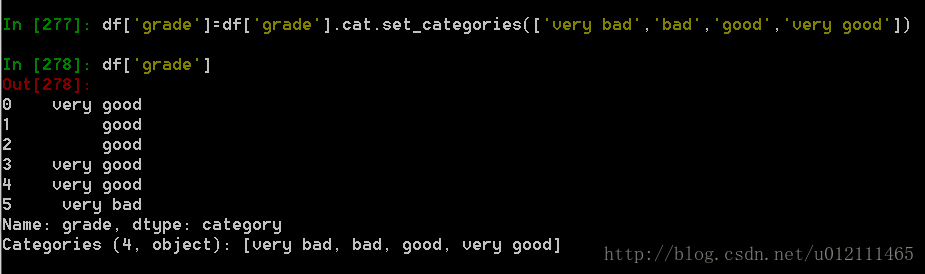
4. 排序是按照Categorical的顺序进行的而不是按照字典顺序进行
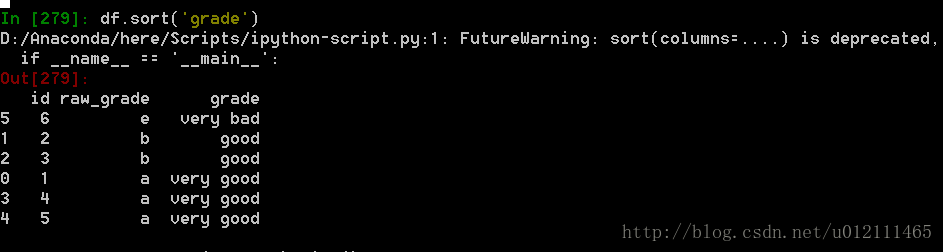
5. 对Categorical列进行排序时存在空的类别

11. 可视化
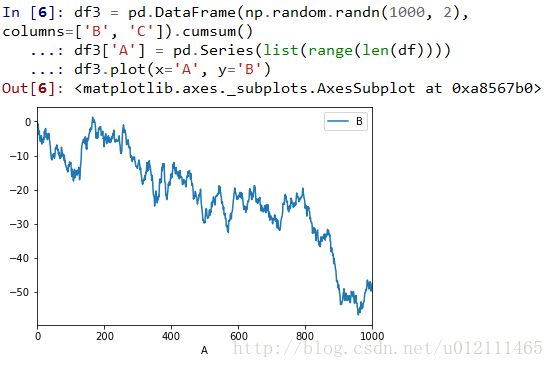
Basic Plotting: plot


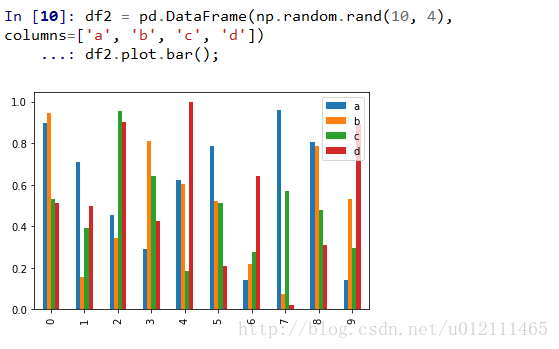
bar plot




Histograms




Box Plots

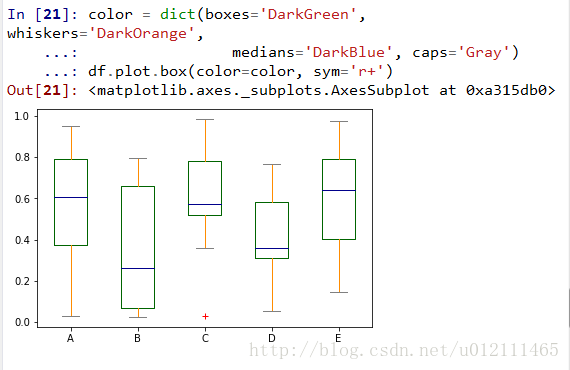
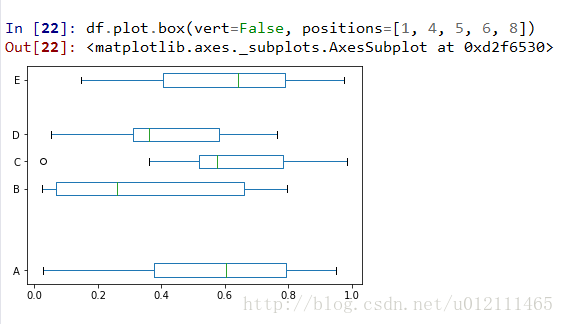
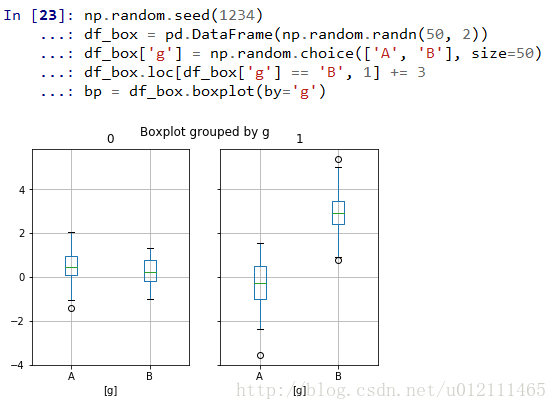
Area Plot
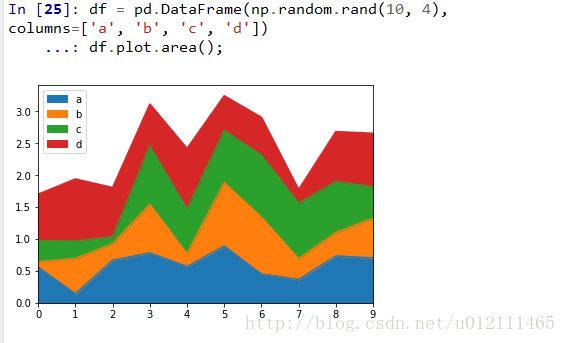

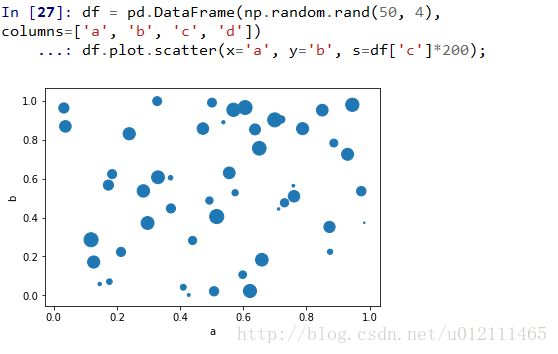
Scatter Plot
Hexagonal Bin Plot

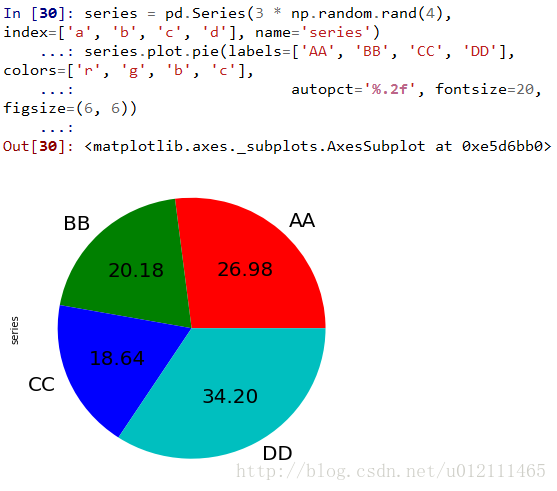
Pie plot

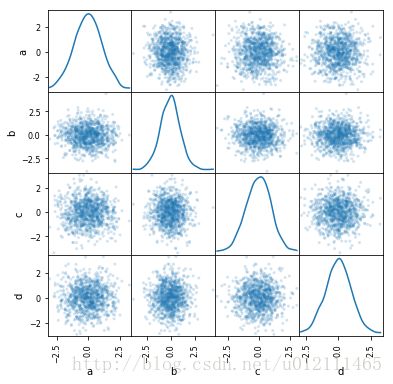
Scatter Matrix Plot

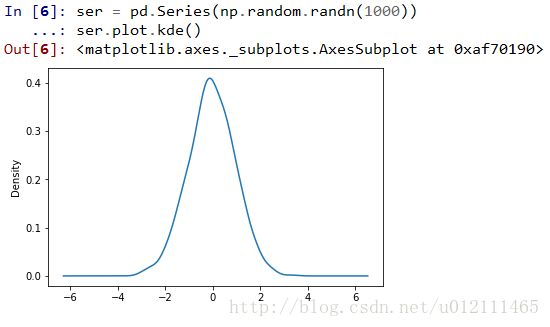
Density Plot
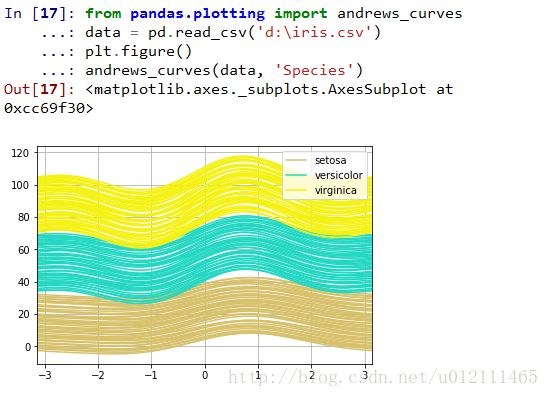
Andrews Curves
Parallel Coordinates

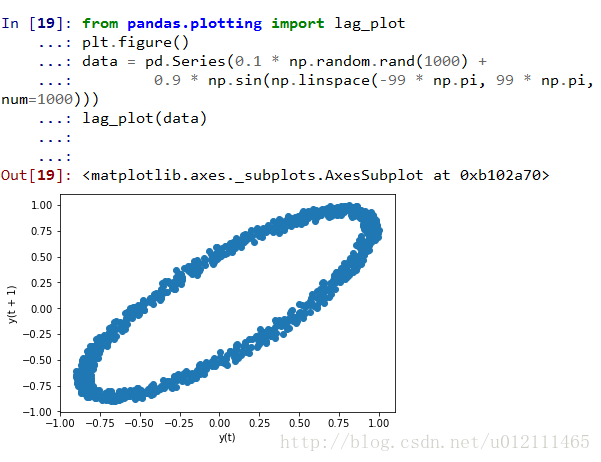
Lag Plot
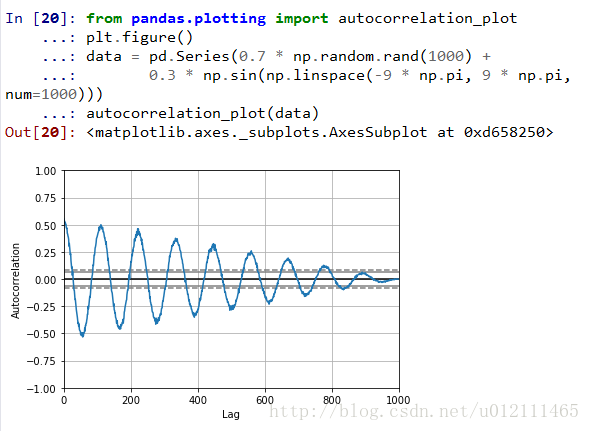
Autocorrelation Plot
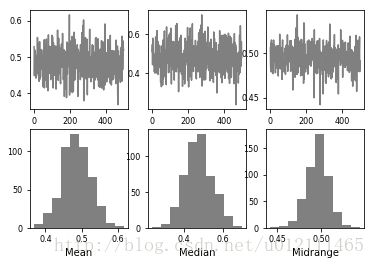
Bootstrap Plot

RadViz

Plot Formatting

Controlling the Legend
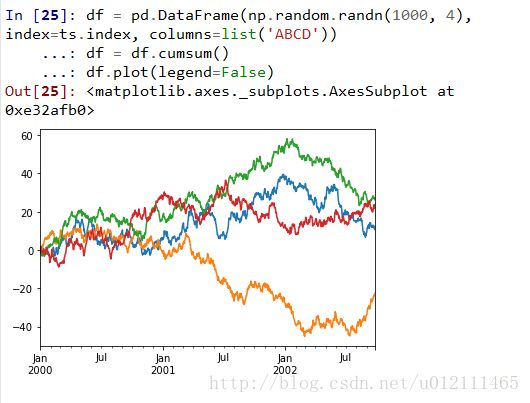
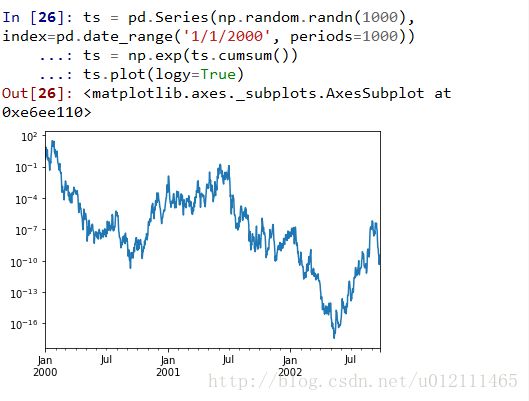
Scales
Plotting on a Secondary Y-axis


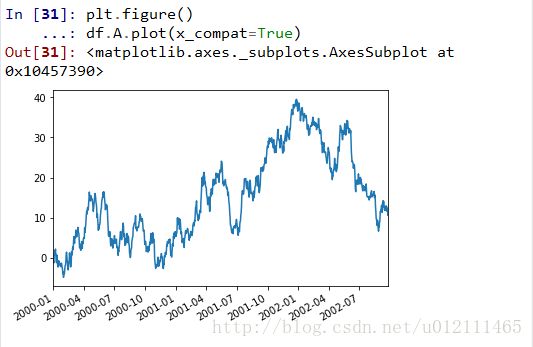
Suppressing Tick Resolution Adjustment


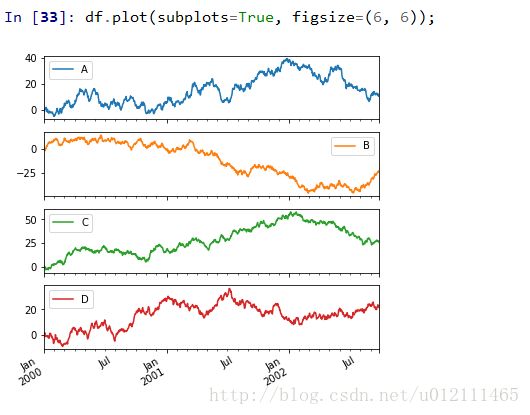
Subplots
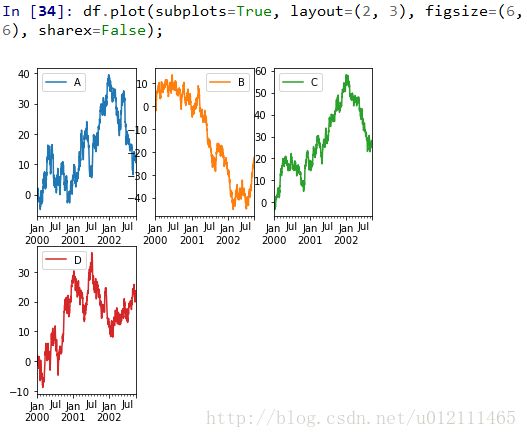
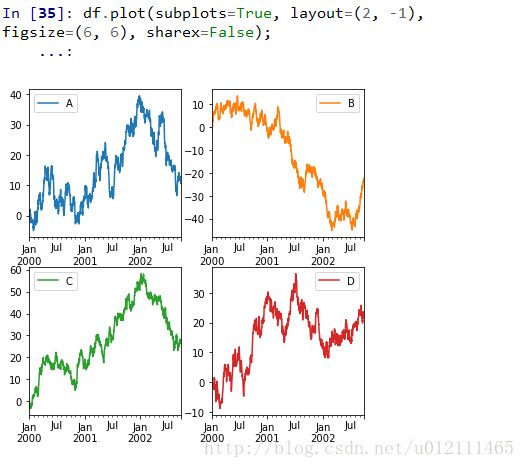
Using Layout and Targeting Multiple Axes


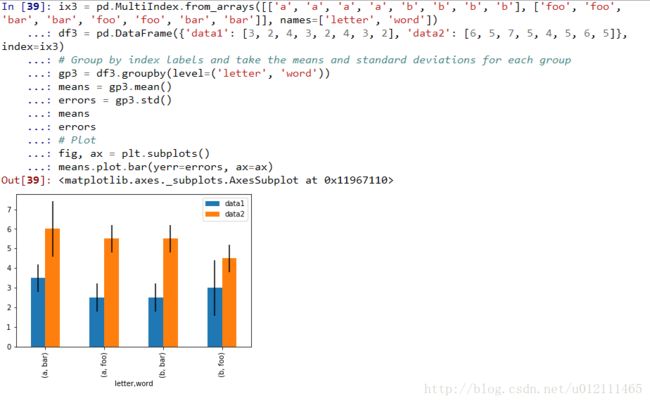
Plotting With Error Bars
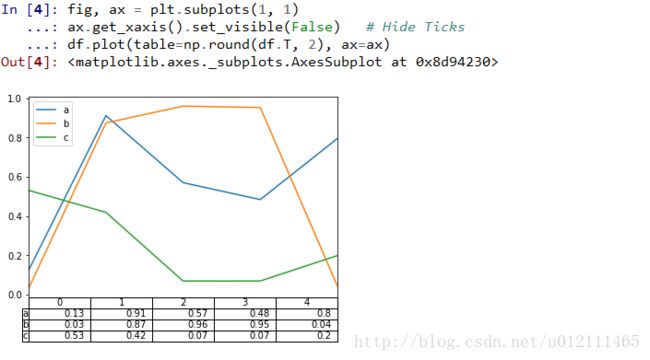
Plotting Tables


Colormaps
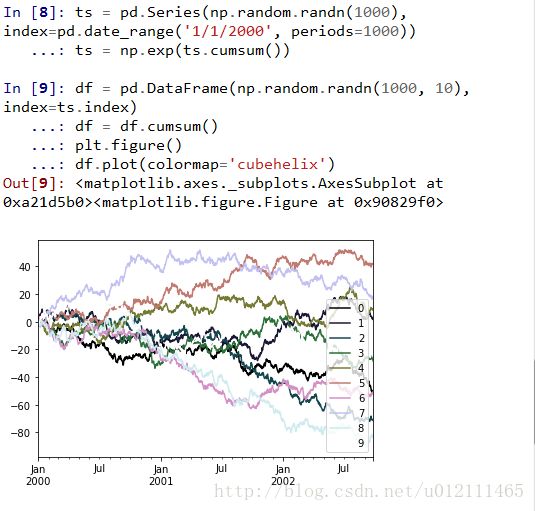

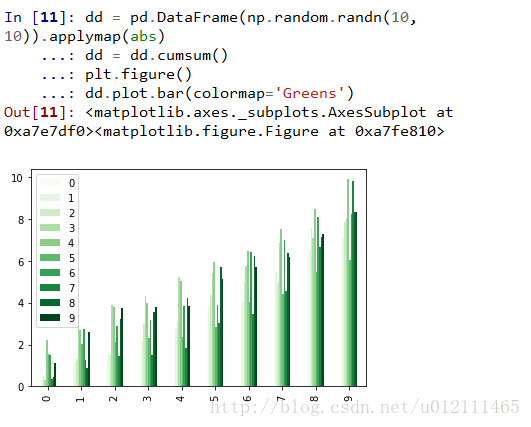
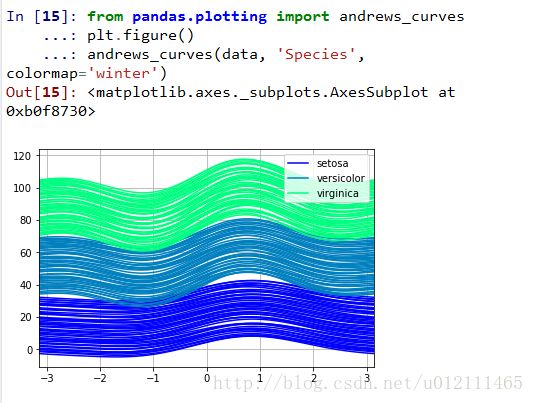
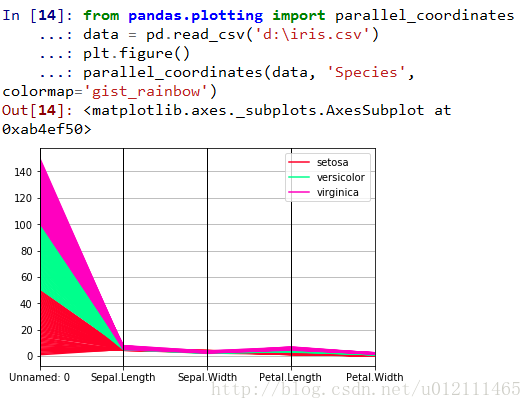
Plotting directly with matplotlib

12. 导入导出数据
1. CSV文件参考here
1. 写入csv文件:
dt.to_csv(file)2. 从csv文件中读取:
pd.read_csv(file)2. HDF5文件参考here
1. 写入HDF5存储:
dt.to_hdf(file,'dt')2. 从HDF5存储中读取:
dt.read_hdf(file,'dt')3. Excel文件参here:MS Excel
1. 写入excel文件:
df.to_excel('path_to_file.xlsx', sheet_name='Sheet1')2. 从excel文件中读取:
read_excel('path_to_file.xls', sheetname='Sheet1')