NLP for Quant:使用NLP和深度学习预测股价(附代码)
今天,你AI了没?
关注:决策智能与机器学习,每天学点AI干货
美国证券交易委员会(SEC)的文件长期以来一直被用作出投资决策的宝贵信息来源。一些论文和项目已经演示了如何使用自然语言处理技术从SEC文件和新闻中提取信息,以预测股票波动。本文在其他工作的基础上,通过使用GloVE嵌入技术、MLP、CNN和RNN深度学习体系结构,预测8-K文件发布后的股票价格变化。
全部代码文末下载
介绍
在金融服务和银行业,大量的资源致力于倾注、分析和试图量化新闻和SEC授权报告中的定性数据。随着新闻周期的缩短和对上市公司的报告要求变得更加繁重,这个问题也不断加剧。几项研究还表明,股票价格波动的最高质量信号并非来自第三方新闻报道,而是来自公司本身及其向SEC的报告。此外,几篇论文已经证明了神经网络在NLP中的效果,并且证明了使用NLP从SEC报告中做信息抽取,来预测股票价格变化的作用。
在这个项目中,我们试图用深度学习的方法证明,在SEC8-K文档中使用自然语言处理的词嵌入技术,来预测公司经历重大事件后股票价格波动的可行性。根据谷歌和斯坦福大学的一篇论文《文本分析对于股票价格预测的重要性》建立了这个项目,并通过探索预先训练过的单嵌入和深度学习的神经网络架构来构建它。
论文:

其他几篇论文下载地址如下:
1、https://www.aaai.org/ocs/index.php/FLAIRS/FLAIRS15/paper/download/10430/10279.
2、https://careeradvancement.uchicago.edu/sites/default/files/ucib-journal/filings-volume-and-volatility.pdf3 3、https://arxiv.org/pdf/1703.03091.pdf
4、 https://arxiv.org/abs/1702.01923
5 、https://nlp.stanford.edu/pubs/lrec2014-stock.pdf
数据收集
截至2018年5月,标准普尔500指数中所有公司的8-K文件都是从SEC Edgar数据库中使用BeautifulSoup python软件包获取的。文件发布的日期和时间,以及披露的类别,被提取出来,而表格和图表则被丢弃。由于数据的大小和收集所需的时间,最终设置了一个具有8个Intel Xeon内核和52 GB内存的Google云实例以及一个Google云。从AlphaVantage API收集了同一公司的历史开盘价和调整后收盘价数据。VIX和GSPC(S&P 500)的历史指数价格从雅虎金融(YahooFinance)下载。
部分代码:
特征工程
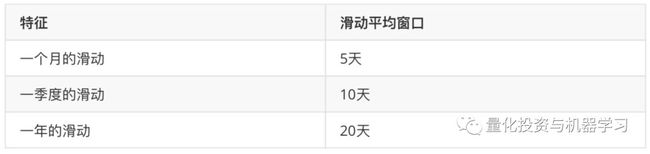
对于每份发布的文件,根据文件发布前的时间计算一年、一季度和一个月的历史滑动平均价格变动,并通过标准普尔500指数的变化进行归一化。所有窗口均指纽约证交所和纳斯达克实际营业的日期(非假日工作日)。
表1. 计算历史滑动价格的滑动平均窗口
目标特征计算为文件发布前后的股权价格变化,使用标准普尔500指数将其标准化。例如,对于于2018年2月5日发布文件的公司,计算其开盘价和调整后收盘价的变化,并减去标准普尔500指数同期的变化。标准化变化被标记为“向上”(>1%)、向下”(<1%)或“不变”(介于-1和1%之间)。
文本处理
所有的文本都是通过删除停用词、标点和数字、词形还原和转换为小写进行预处理的。这是通过使用NLTK WordNet语料库阅读器与DASK结合来实现多线程加速的。
所有文件都用零填充,长度统一为34603个字。为了保留大多数文本信息,但防止数据集变得不必要的大,在文档长度的90%处选择了此截止值。斯坦福大学NLP维基百科2014+Gigaword 5100维度被选作欲训练词嵌入,前提是它将携带从维基百科语料库培训而来的文本中发现的专门的、行业特定的单词的信息。
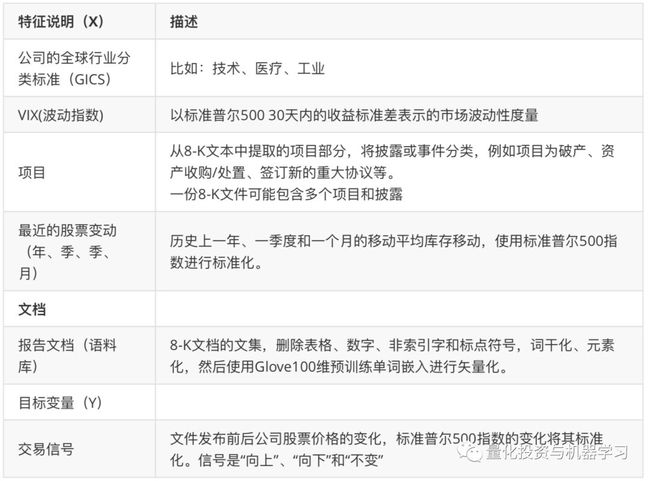
表2. 数据特征列列表
在丢弃重复样品和无法提取发布日期的文本后,最终数据集包括2011年至2018年500家公司的约17000份文件。
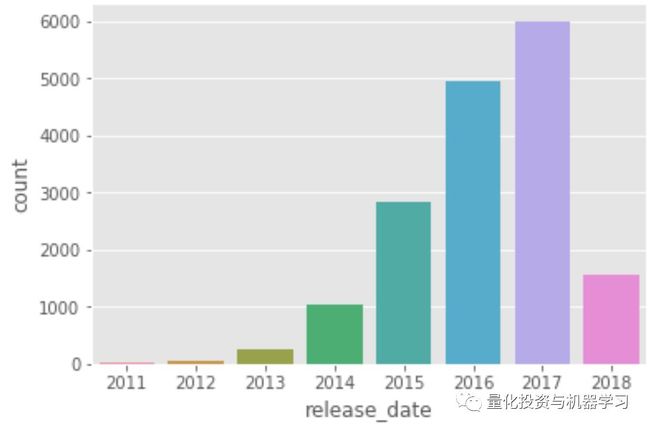
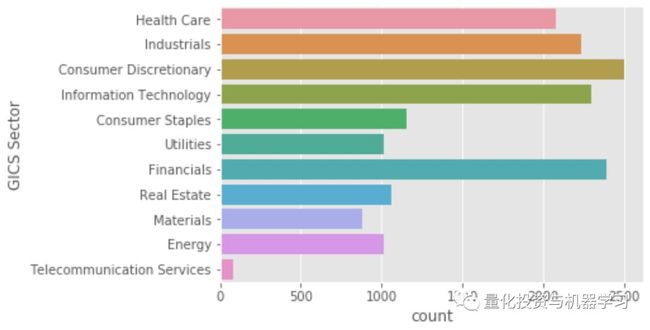
图1&2 数据集样本规模为一年发布8K发布,运营部门公司
部分代码:
机器学习
所有分类特征都是一个热编码特征,连续特征。如最近的股票走势和VIX的收盘价,都被标准化为平均值为0,标准偏差为1。
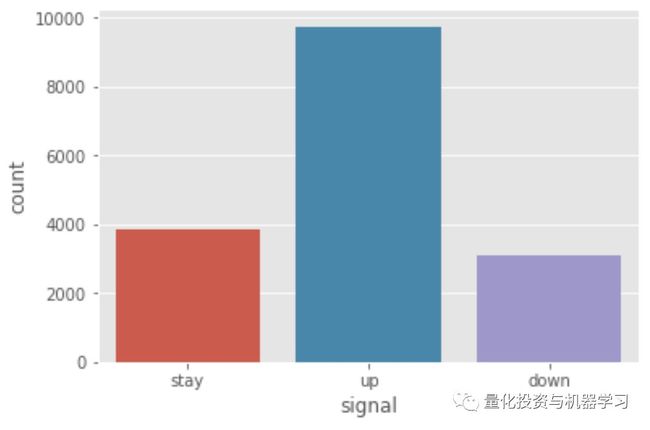
图3 目标类别计数,数据集中类别不平衡
然后将数据集随机打乱,并分成80%的训练集和20%的测试集。数据集的类别不平衡,超过50%的样本被标记为“向上”(up),考虑到过去十年标准普尔500指数的稳步上升,这在直觉上是合理的。为了纠正这一点,我们使用了训练数据的过采样,在每一个类别中随机选择的样本进行了重复,以使三个类别中每个类别的样本数相等。
使用带有TensorFlow后端的Keras构建了四种不同的机器学习体系结构,包括两个输入层(一个用于文本文档,一个用于功能),一个带有预训练GloVE向量的嵌入层,以及:
一个多层感知器完全连接的网络—MLP
两个一维卷积层—CNN
双向GRU层—RNN
一维卷积层,然后是GRU层—CNN-RNN
每个网络在两个Nvidia K80 GPU上接受了10个时期的训练,每个批次大小为32。
表3. 10次训练后验证集上的评价
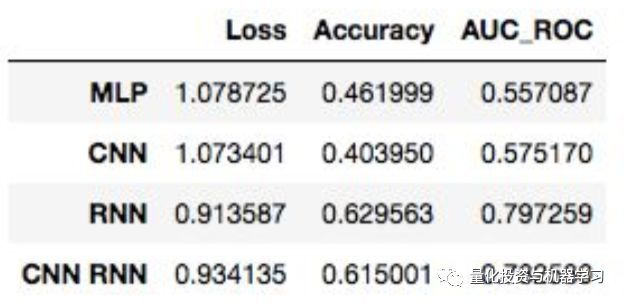
RNN和CNN-RNN网络在验证数据集上获得了最高的准确性和AUC ROC得分。然而,CNN-RNN模型需要RNN模型一半的训练时间。继续训练CNN-RNN模型,再进行15次,验证集上的损失最小。
部分模型代码:
Build & Train Models

Model Evaluation
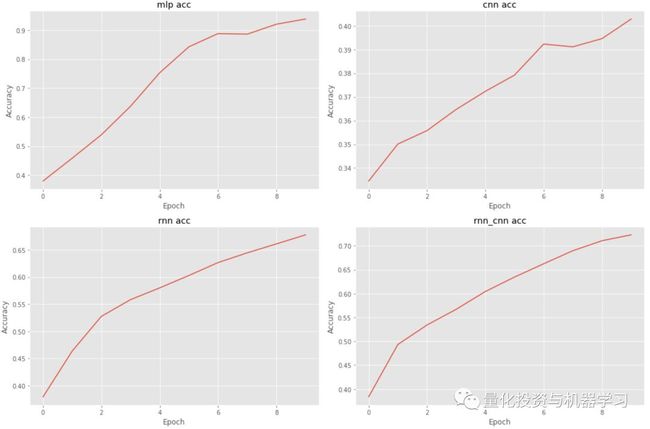
结果
CNN-RNN网络在验证数据上的准确率为64.5%,AUC-ROC为0.90。
表4. 23轮训练后CNN RNN模型的最好表现
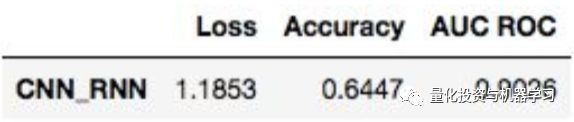
这个模型比基线随机选择算法提高了94%,比斯坦福大学和谷歌的论文提高了16%。这些结果表明,虽然字嵌入和神经网络需要更多的时间和计算资源来建立和训练,但在准确性方面的有一定的提升。
讨论
本文触及了如何利用最新的自然语言处理技术和深度学习模型从SEC报告中提取有意义的信息以及公司股价的波动。为了从文本中收集更细微的信息,可以探索更专门的单词嵌入集或高级技术如Sense2Vec。
股票市场价格的变化只在文件发布前后立即进行测量,尽管市场很可能以不同的速度对不同类型的新闻作出反应。本文的拓展可以是在披露后的几天内考虑价格变动。
最后,尽管CNN、RNN和混合体系结构目前被认为是最先进的NLP模型,但在这些模型中,关于RNN、LSTM和GRU单元,以及关于RNN和CNN层的深度、大小和超参数,以及使用池化层还存在很多问题。时间和金钱的限制(使用多个GPU和处理大型数据集可以很快在谷歌云中累积)让我们不得不停止探索这些研究的可能性。尽管如此,64%的准确率表明,这些努力可能值得一试,即快速从大量文本数据中提取数据,并做出交易决策 。
本文其他的一些参考资料:
6、https://www.sec.gov/fast-answers/answersform8khtm.html
7、https://arxiv.org/abs/1511.06388
来源:量化投资与机器学习
本文由量化投资与机器学习首发,转载经授权
从线性模型到神经网络 | 入门AI系列
机器翻译技术现状评述与展望 | 行业观察
基于深度强化学习的新闻推荐模型DRN
深度强化学习 | 用TensorFlow构建你的第一个游戏AI
AI到底是能力First还是可解释性First? | 行业观察
“强化学习教父”Rich Sutton:不要再寄希望于AI“被手工设计”,利用算力才是王道 | 技术观察
通过自动强化学习(AutoRL)进行远程机器人导航 | 强化学习系列
商业智能与智能商业 | 行业观察系列
微信群&交流合作
伙伴招募:寻找真正对AI技术感兴趣的伙伴,共同维护公众号,一起组织各种技术交流活动,请留言与我们联系。
行业沙龙群:加入沙龙群,拓展行业人脉,对接需求,请在公众号留言:“微信号+名字+研究领域/专业/学校/公司”,我们将很快与您联系。
各种合作:请发邮件至[email protected]或在公众号留言联系。
