计算机视觉入门系列(一) 综述
计算机视觉入门系列(一) 综述
自大二下学期以来,学习计算机视觉及机器学习方面的各种课程和论文,也亲身参与了一些项目,回想起来求学过程中难免走了不少弯路和坎坷,至今方才敢说堪堪入门。因此准备写一个计算机视觉方面的入门文章,一来是时间长了以后为了巩固和温习一下所学,另一方面也希望能给新入门的同学们介绍一些经验,还有自然是希望各位牛人能够批评指正不吝赐教。由于临近大四毕业,更新的时间难以保证,这个系列除了在理论上面会有一些介绍以外,也会提供几个小项目进行实践,我会尽可能不断更新下去。
因诸多学术理论及概念的原始论文都发表在英文期刊上,因此在尽可能将专业术语翻译成中文的情况下,都会在括号内保留其原始的英文短语以供参考。
目录
- 简介
- 方向
- 热点
简介
计算机视觉(Computer Vision)又称为机器视觉(Machine Vision),顾名思义是一门“教”会计算机如何去“看”世界的学科。在机器学习大热的前景之下,计算机视觉与自然语言处理(Natural Language Process, NLP)及语音识别(Speech Recognition)并列为机器学习方向的三大热点方向。而计算机视觉也由诸如梯度方向直方图(Histogram of Gradient, HOG)以及尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)等传统的手办特征(Hand-Crafted Feature)与浅层模型的组合逐渐转向了以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习模型。
| 方式 | 特征提取 | 决策模型 |
|---|---|---|
| 传统方式 | SIFT,HOG, Raw Pixel … | SVM, Random Forest, Linear Regression … |
| 深度学习 | CNN … | CNN … |
svm(Support Vector Machine) : 支持向量机
Random Forest : 随机森林
Linear Regression : 线性回归
Raw Pixel : 原始像素
传统的计算机视觉对待问题的解决方案基本上都是遵循: 图像预处理 → 提取特征 → 建立模型(分类器/回归器) → 输出 的流程。 而在深度学习中,大多问题都会采用端到端(End to End)的解决思路,即从输入到输出一气呵成。本次计算机视觉的入门系列,将会从浅层学习入手,由浅入深过渡到深度学习方面。
方向
计算机视觉本身又包括了诸多不同的研究方向,比较基础和热门的几个方向主要包括了:物体识别和检测(Object Detection),语义分割(Semantic Segmentation),运动和跟踪(Motion & Tracking),三维重建(3D Reconstruction),视觉问答(Visual Question & Answering),动作识别(Action Recognition)等。
物体识别和检测
物体检测一直是计算机视觉中非常基础且重要的一个研究方向,大多数新的算法或深度学习网络结构都首先在物体检测中得以应用如VGG-net, GoogLeNet, ResNet等等,每年在imagenet数据集上面都不断有新的算法涌现,一次次突破历史,创下新的记录,而这些新的算法或网络结构很快就会成为这一年的热点,并被改进应用到计算机视觉中的其它应用中去,可以说很多灌水的文章也应运而生。
物体识别和检测,顾名思义,即给定一张输入图片,算法能够自动找出图片中的常见物体,并将其所属类别及位置输出出来。当然也就衍生出了诸如人脸检测(Face Detection),车辆检测(Viechle Detection)等细分类的检测算法。
近年代表论文
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Liu, Wei, et al. “SSD: Single shot multibox detector.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
数据集
- IMAGENET
- PASCAL VOC
- MS COCO
- Caltech
语义分割
语义分割是近年来非常热门的方向,简单来说,它其实可以看做一种特殊的分类——将输入图像的每一个像素点进行归类,用一张图就可以很清晰地描述出来。
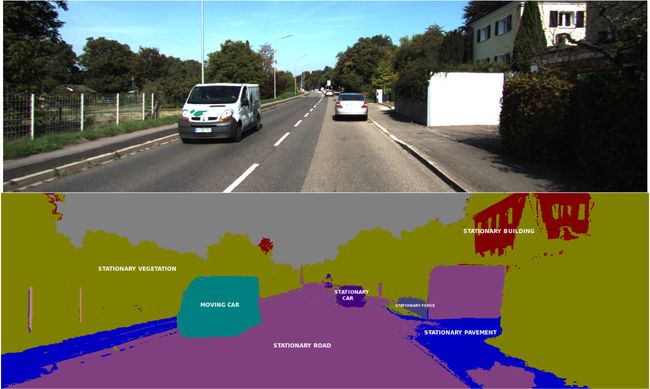
很清楚地就可以看出,物体检测和识别通常是将物体在原图像上框出,可以说是“宏观”上的物体,而语义分割是从每一个像素上进行分类,图像中的每一个像素都有属于自己的类别。
近年代表论文
- Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062 (2014).
- Noh, Hyeonwoo, Seunghoon Hong, and Bohyung Han. “Learning deconvolution network for semantic segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Zheng, Shuai, et al. “Conditional random fields as recurrent neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
数据集
- PASCAL VOC
- MS COCO
运动和跟踪
跟踪也属于计算机视觉领域内的基础问题之一,在近年来也得到了非常充足的发展,方法也由过去的非深度算法跨越向了深度学习算法,精度也越来越高,不过实时的深度学习跟踪算法精度一直难以提升,而精度非常高的跟踪算法的速度又十分之慢,因此在实际应用中也很难派上用场。
那么什么是跟踪呢?就目前而言,学术界对待跟踪的评判标准主要是在一段给定的视频中,在第一帧给出被跟踪物体的位置及尺度大小,在后续的视频当中,跟踪算法需要从视频中去寻找到被跟踪物体的位置,并适应各类光照变换,运动模糊以及表观的变化等。但实际上跟踪是一个不适定问题(ill posed problem),比如跟踪一辆车,如果从车的尾部开始跟踪,若是车辆在行进过程中表观发生了非常大的变化,如旋转了180度变成了侧面,那么现有的跟踪算法很大的可能性是跟踪不到的,因为它们的模型大多基于第一帧的学习,虽然在随后的跟踪过程中也会更新,但受限于训练样本过少,所以难以得到一个良好的跟踪模型,在被跟踪物体的表观发生巨大变化时,就难以适应了。所以,就目前而言,跟踪算不上是计算机视觉内特别热门的一个研究方向,很多算法都改进自检测或识别算法。
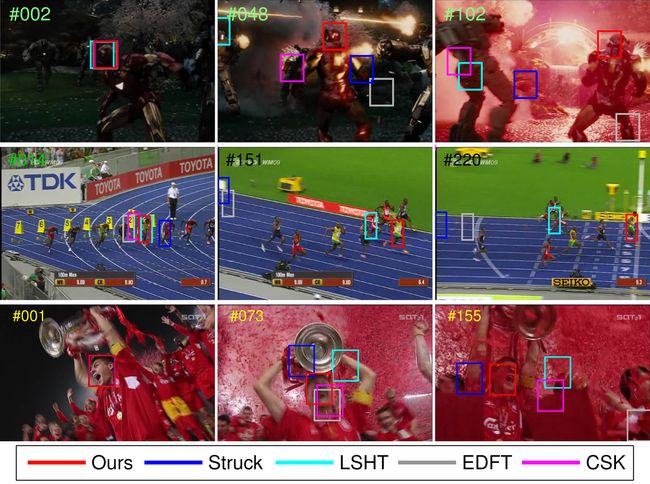
近年代表论文
- Nam, Hyeonseob, and Bohyung Han. “Learning multi-domain convolutional neural networks for visual tracking.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Held, David, Sebastian Thrun, and Silvio Savarese. “Learning to track at 100 fps with deep regression networks.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Henriques, João F., et al. “High-speed tracking with kernelized correlation filters.” IEEE Transactions on Pattern Analysis and Machine Intelligence 37.3 (2015): 583-596.
- Ma, Chao, et al. “Hierarchical convolutional features for visual tracking.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Bertinetto, Luca, et al. “Fully-convolutional siamese networks for object tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Danelljan, Martin, et al. “Beyond correlation filters: Learning continuous convolution operators for visual tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Li, Hanxi, Yi Li, and Fatih Porikli. “Deeptrack: Learning discriminative feature representations online for robust visual tracking.” IEEE Transactions on Image Processing 25.4 (2016): 1834-1848.
数据集
- OTB(Object Tracking Benchmark)
- VOT(Visual Object Tracking)
视觉问答
视觉问答也简称VQA(Visual Question Answering),是近年来非常热门的一个方向,其研究目的旨在根据输入图像,由用户进行提问,而算法自动根据提问内容进行回答。除了问答以外,还有一种算法被称为标题生成算法(Caption Generation),即计算机根据图像自动生成一段描述该图像的文本,而不进行问答。对于这类跨越两种数据形态(如文本和图像)的算法,有时候也可以称之为多模态,或跨模态问题。

近年代表论文
- Xiong, Caiming, Stephen Merity, and Richard Socher. “Dynamic memory networks for visual and textual question answering.” arXiv 1603 (2016).
- Wu, Qi, et al. “Ask me anything: Free-form visual question answering based on knowledge from external sources.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Zhu, Yuke, et al. “Visual7w: Grounded question answering in images.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
数据集
- VQA
热点
随着深度学习的大举侵入,现在几乎所有人工智能方向的研究论文几乎都被深度学习占领了,传统方法已经很难见到了。有时候在深度网络上改进一个非常小的地方,就可以发一篇还不错的论文。并且,随着深度学习的发展,很多领域的现有数据集内的记录都在不断刷新,已经向人类记录步步紧逼,有的方面甚至已经超越了人类的识别能力。那么,下一步的研究热点到底会在什么方向呢?就我个人的一些观点如下:
- 多模态研究: 目前的许多领域还是仅仅停留在单一的模态上,如单一分物体检测,物体识别等,而众所周知的是现实世界就是有多模态数据构成的,语音,图像,文字等等。 VQA 在近年来兴起的趋势可见,未来几年内,多模态的研究方向还是比较有前景的,如语音和图像结合,图像和文字结合,文字和语音结合等等。
- 数据生成: 现在机器学习领域的许多数据还是由现实世界拍摄的视频及图片经过人工标注后用作于训练或测试数据的,标注人员的职业素养和经验,以及多人标注下的规则统一难度在一定程度上也直接影响了模型的最终结果。而利用深度模型自动生成数据已经成为了一个新的研究热点方向,如何使用算法来自动生成数据相信在未来一段时间内都是不错的研究热点。
无监督学习:人脑的在学习过程中有许多时间都是无监督(Un-supervised Learning)的,而现有的算法无论是检测也好识别也好,在训练上都是依赖于人工标注的有监督(Supervised Learning)。如何将机器学习从有监督学习转变向无监督学习,应该是一个比较有挑战性的研究方向,当然这里的无监督学习当然不是指简单的如聚类算法(Clustering)这样的无监督算法。而LeCun也曾说: 如果将人工智能比喻作一块蛋糕的话,有监督学习只能算是蛋糕上的糖霜,而增强学习(Reinforce Learning)则是蛋糕上的樱桃,无监督学习才是真正蛋糕的本体。
最后,想要把握领域内最新的研究成果和动态,还需要多看论文,多写代码。
计算机视觉领域内的三大顶级会议有:Conference on Computer Vision and Pattern Recognition (CVPR)
International Conference on Computer Vision (ICCV)
European Conference on Computer Vision (ECCV)较好的会议有以下几个:
The British Machine Vision Conference (BMVC)
International Conference on Image Processing (ICIP)
Winter Conference on Applications of Computer Vision (WACV)
Asian Conference on Computer Vision (ACCV)
当然,毕竟文章的发表需要历经审稿和出版的阶段,因此当会议论文集出版的时候很可能已经过了小半年了,如果想要了解最新的研究,建议每天都上ArXiv的cv板块看看,ArXiv上都是预出版的文章,并不一定最终会被各类会议和期刊接收,所以质量也就良莠不齐,对于没有分辨能力的入门新手而言,还是建议从顶会和顶级期刊上的经典论文入手。
这是一篇对计算机视觉目前研究领域的几个热门方向的一个非常非常简单的介绍,希望能对想要入坑计算机视觉方向的同学有一定的帮助。由于个人水平十分有限,错误在所难免,欢迎大家对文中的错误进行批评和指正。