背景
之前做过一个项目,数据库存储采用的是mysql。当时面临着业务指数级的增长,存储容量不足。当时采用的措施是
1>短期解决容量的问题
mysql从5.6升级5.7,因为数据核心且重要,数据库主从同步采用的是全同步, 利用5.7并行复制新特性,减少了主从同步的延迟,提高了吞吐量。
当时业务量高峰是2000TPS,5.6时可承受的最大TPS是3000,升级到5.7压测可承受的最大TPD是5000.
2>流量拆分,从根本上解决容量问题
首先进行容量评估,通过对于业务开展规划、活动预估,年底的容量会翻5倍。由于目前指数级增长的特性,数据库要预留至少4倍的冗余。
要对数据库进行扩容,因为我们已经使用的是最顶配的SSD物理机了,就算可以在linux内核层面对numa进行绑核和非绑核等测试调参优化性能,提升容量也很有限。注意:一般的业务系统numa绑核会提高性能,但是mysql等数据库系统是相反的。
所以垂直扩容不成功,就看看是否可以拆分流量。mysql流量拆分方式有x轴拆分(水平拆分)、y轴拆分(垂直拆分)、z轴拆分。
其中y轴拆分(垂直拆分)就是目前都在说做垂直领域,就是在一个细分领域里做深入的意思。由此可以很容易的记住垂直拆分的意思就是按照业务领域进行拆分,专库专用。实际上能按领域拆分是最理想的,因为这种拆分业务清晰;拆分规则明确;系统之间整合或扩展容易。但是因为当时的业务已经很简单,y轴拆分已经没有什么空间,这种拆分不能达到扩容20倍的目的。
z轴拆分近几年没有听说过了,实际上大家也一直在用。这种方式是将一张大表拆分为子母表,就是分为概要信息和详细信息。这种拆分方式对解决容量问题意义不大。
比较可行的一个方案是水平拆分。就是常说的分库分表。按照容量评估,数据库水平拆分一拆十,根据业务特点找一个标准字段来进行取模。
水平拆分一个技术点在于新老切换。
采用的是数据库双写的方式,采用异步确保性的补偿型事务,发送实时和延迟两个MQ,通过开关来控制以老数据为准还是新数据库为准。开始时以老数据库为准,观察新老数据没有一致性问题之后,在一个低峰期,关闭了系统入口,等数据库没有任何变更之后切换开关,再打开系统入口。
问题
对于容量问题,上面采用的是一次性拆分到位的方法。对于一个规模稍大的公司来讲,10组物理机(1组包含1主N从)的成本还好。
1>如果量级再次升级,需要每周增加10台数据库才能支撑容量呢?
2>并且对系统可用性还有强要求,1s的停机都不可以接受呢?
解决方案分析
垂直流量拆分
首先我要分析的是每周增加10台数据库这个容量是不是合理的。是否存在放大效应或者说可以减少对mysql这种昂贵资源的使用,转为增加对HBase、Elasticsearch这种低成本高扩展性资源的使用呢?
基于这个思路,我们需要梳理下是否有可垂直拆分的流量。比如正向流量和负向流量。所谓正向流量是指比如交易下单,负向流量就是取消订单,包括已付款取消、未付款取消、已到货取消、未到货取消等等。实际上负向流量在总订单里占比很少,但是业务要比正向交易业务复杂。将正向和逆向拆分的一个主要优势是分治思想,可以降低两部分各自的复杂度。将流量拆分重心转移到正向流量上。
对于正向流量,一个业务比较常用的流量拆分思路是CQRS命令查询分离,也就是常说的读写分离。如果读流量大于写流量。可以考虑能否将读流量进一步拆分。拆分成实时和离线,将实时性要求不高的查询走ES。ES的数据可以通过同步binlog变更获得。
另外一个思路是将数据库按照历史数据来拆分。就是数据库里只保存一定时间内的实时数据。超过指定时间则进行数据归档。将数据归档到HBase等,一般对于历史的查询实时性要求也不是很高。
垂直流量拆分可能遇到的问题
以上方法都是只考虑问题1如果量级再次升级,需要每周增加10台数据库才能支撑容量的方案。如果再考虑问题2并且对系统可用性还有强要求,1s的停机都不可以接受。就需要看上述方案可能会遇到的问题。
拆分正向流量和负向流量、CQRS都需要改造,改造过程就需要过渡。过渡可以采用上面说的双写方式,观察运行情况进行切换。切换过程中也可以不关闭流量。
麻烦的是数据归档。因为数据归档后删除数据库的数据,变更生效时,针对innodb来说,意味着数据结构重建,频繁IO。这会影响OLTP在线事务的处理。可以考虑按表来归档,控制操作频率,控制单位时间内对IO的影响。
分布式关系型数据库
分布式关系型数据库本质上是通过增加代理等方式将分库分表做的更加隐蔽。
阿里巴巴分布式关系数据库(DRDS),前身是淘宝分布式数据层(TDDL),核心就是用于分库分表管理的代理层,宣称可实现平滑扩容。

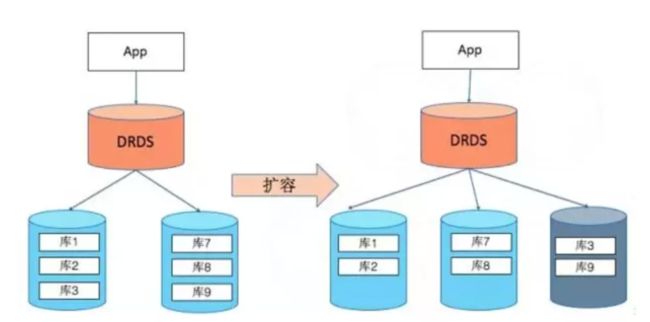
扩容过程实际是物理数据迁移的过程,引擎层按照分库迁移后的逻辑先在物理节点上建立新的分库,然后保留一个时间点进行全量的数据迁移。完成全量迁移后,开始基于先前保留的时间点进行增量的数据追赶。当增量数据追赶到两边的数据几乎一致时,对数据库进行瞬时停写,将最后的数据追平,引擎层进行分库逻辑的路由切换,路由规则切换完成后就完成了核心的扩容逻辑,整个切换过程在毫秒级别完成。
因为整个过程是毫秒级,所以可以做到业务层没有感知,等多就是看到扩容过程中请求延时增加了不到1s。从原理上来说是可行的。
NOSQL解决方案
像这么大的数据量一个很好的参考是12306。12306采用的是Geode。它是有数据库功能的内存数据网格(In-Memory Data Grid,IMDG)。其重要特性是
1)集群内存总容量,现在Geode可以实现单个节点200-300GB内存,总集群包含300个节点的大型集群,因此总容量可以达到90TB左右的级别。
2)Geode集群功能非常强大,实现了内存中数据Shard分布,自动管理,集群故障自动恢复,自动平均分布等一系列企业级的功能,而且有自带的集群间数据同步功能。
3)在CAP原理下(不了解的话可以百度一下CAP不可能三角),Geode可以保证集群内数据的强一致性,注意是真正的强一致性而不是最终一致性,再加上分区可用性,因此是一个CP型的产品,可以提供统一的数据视图,支持高并发下的acid事务。
采用新的解决方案最大问题是平滑过渡,平滑过渡方面我还是觉得上面提到的数据库双写方式安全可靠。
系统共建的解决方案
如果达到我所说的量级,基本上在一个行业中是处于垄断地位的。并不是一家纯的互联网公司。这种公司可以采用和互联网大厂合作的方式、用已经有这方面经验的大厂,来根据自己内部系统的特性共建一套合适自己的定制化数据库。