【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】如果你对数据挖掘感兴趣,欢迎先浏览我的另一篇随笔:数据挖掘比赛/项目全流程介绍
【再啰嗦一下】如果你对金融科技感兴趣,欢迎浏览我的另一篇随笔:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
【最后再说一下】本文结合了博主、内部赛优秀团队以及外部赛冠/亚/季军的方案分享!
如何进行金融行业数据分析与建模,是挖掘金融行业数据价值的重要手段。金融行业数据分析与建模方法主要包括七个重要环节,每个环节紧密相连。

1. 赛题介绍
1.1 赛题名称
贷款风险预测(逾期还款分三种情况:要么用户不愿意还款、要么没有钱还款、要么忘了还款)
1.2 问题描述
根据数据集中8万用户的相关信息,预测用户未来是否会逾期还款。
1.3 提供数据
用户基本信息、银行卡流水、信用卡账单信息以及用户行为数据,字段内容均为脱敏数据。
1.4 评估指标
Kolmogorov-Smirnov(KS)是风险评分领域常用的评估指标,反应模型对正负样本的辨识能力,KS越高表明模型对正负样本的辨识能力越强。
KS = max { | f(s|P) - f(s|N) | }
其中,f(s|P) 为正样本预测值的累计分布函数,f(s|N) 为负样本在预测值上的累计分布函数。

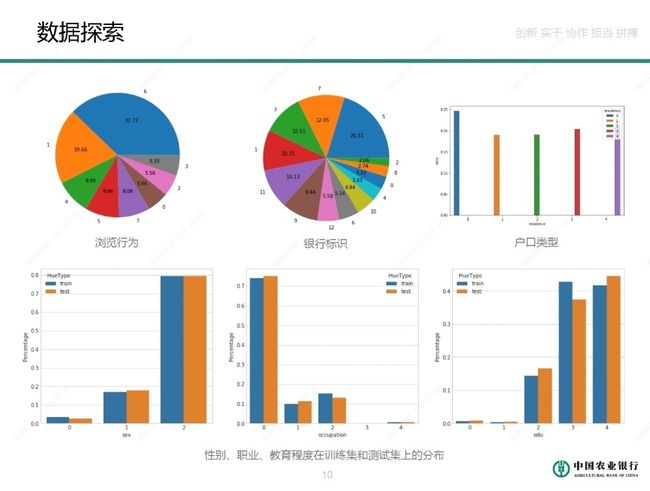
2. 数据探索
通过数据可视化查看数据样本的分布以及特征的统计规律。
- 正/负样本比例1:4(应该是人工采样过,实际业务中逾期样本比例很少)
- 训练集/测试集样本比例6w:8k
- ......
3. 数据预处理
主要包括数据的缺失值处理、异常值处理、拼接、去重等基本处理。同时,还有汇率转换和单位净值*份额等基本数据操作。
4. 特征工程
4.1 基本特征
根据类别型和数值型数据在标签上的分布进行预处理,包括标准化、归一化、离散化、平滑化、one-hot编码等。
4.2 时序变化特征
- 银行卡流水:计算用户在全局、特定条件下(交易类型,非工资收入/工资收入,支出/收入)的金额和时间的统计特征(sum/count/mean/median/std/min/max)
- 信用卡账单:计算用户在全局、特定条件下(银行标识,还款状态)的金额(上期账单金额,上期还款金额,本期账单余额,信用卡额度)和账单时间戳的统计信息
- 浏览行为:计算用户每天每种行为类型/子类型的count、浏览行为数和浏览时间的统计信息
- 日期的转换:根据上半年/下半年、季度、月份等时间维度,提取大量可能的日期特征衍生
- 滑动窗口处理:根据不同时间区间(近一个月、近两个月等),计算用户对应的银行流水、信用卡账单、浏览行为的基础特征/统计特征
- 屏蔽采样时间差异的特征:取前五条和最后五条处理等
- ......
4.3 交叉特征
- 除法:例如某浏览行为类型占总浏览的比例、工资收入/非工资收入等
- 减法:最大时间戳-最小时间戳(表示某种行为的时间跨度)等
- 拼接:例如行为类型-子类型1/2,拼接后计算特征等
- 用户的个人信息之间的交叉特征衍生
- ......
4.4 业务理解特征
- 上期未还款金额 = 上期账单金额 - 上期还款金额
- 相邻两期账单金额差 = 本期账单余额 - 上期账单金额
- if 上期账单金额 > 信用卡额度,爆卡 = 1 else 爆卡 = 0
- if 上期还款金额 < 上期账单金额,未足额还款 = 1 else 未足额还款 = 0
- 缺失副表的数量
- ......
5. 特征选择
- 删除相关性高的特征(例如取阈值0.98)
- 使用低成本特征选择算子,过滤掉不重要的特征(例如取50%)
- 使用预训练的lightgbm模型获得特征重要性(例如取top3500)
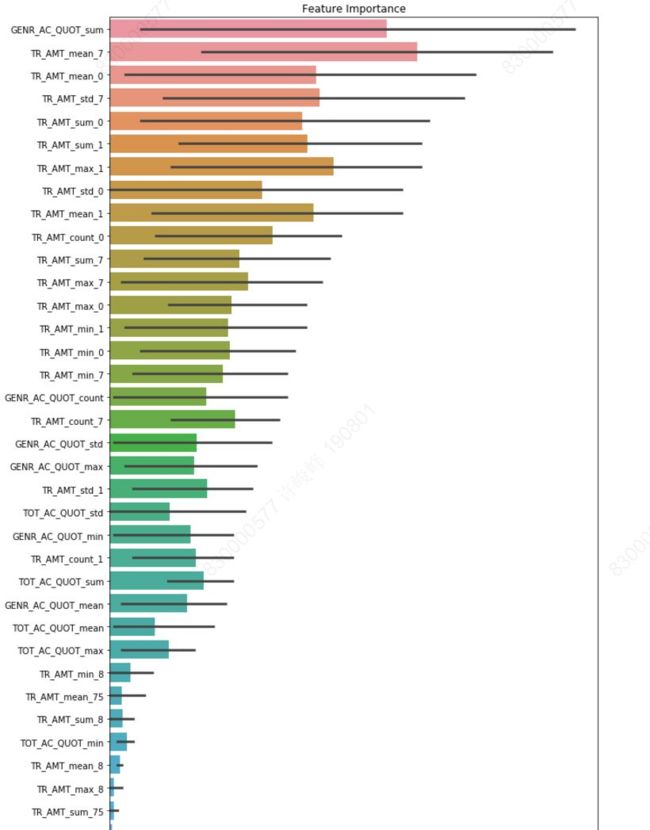
6. 模型选择及调参
- 经过实验选择了lightgbm模型
- 使用网格搜索/贝叶斯优化对其进行调参(调整叶子节点数、最大深度、行/列采样比例、正则项系数等)
- 通过KS指标/自定义评价函数,通过交叉验证,获取较为准确的模型迭代轮次
7. 模型融合
- bagging
- stacking
- ......
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍
如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路