姓名:刘成龙 学号:16020199016
转载自:https://www.jiqizhixin.com/articles/2018-11-02-10,有删节。
【嵌牛导读】:个贼简单的神经机器翻译架构
【嵌牛鼻子】: NMT LSTM
【嵌牛提问】:你还在Attention吗?
【嵌牛正文】:
自从编码器解码器架构崛起以来,主流的神经机器翻译(NMT)模型都使用这种架构,因为它允许原文序列长度和译文序列长度不一样。而自 Bahdanau 等研究者在 14 年提出基于注意力的 NMT 模型后,基于编码器解码器架构的 NMT 模型差不多都会加上注意力机制。尤其是在 2017 年谷歌发表论文「Attention is all your need」后,注意力机制更是坐上了宝座,这篇论文相当于进一步形式化表达了注意力机制,并提出了只使用 Multi-head Attention 的翻译模型 Transformer。
随后 Transformer 在神经机器翻译领域一发不可收拾,目前大多数主流的机器翻译系统都使用这种完全基于注意力机制的架构。此外,Transformer 在很多 NLP 任务上都有非常好的表现,例如 BERT 预训练模型、计算句子间的相似性以及问答系统等。总的而言,Transformer 可以视为一种「全连接」网络,它会关注句子间所有词的相互关系,这样相当于无视了词的空间距离,因此能建模词与词之间的长期依赖关系。
但是最近 Ofir Press 等研究者表示也许我们可以不要注意力机制,也不要编码器解码器架构,神经机器翻译的效果甚至会更好。他们在论文中总结到几乎所有流行的 NMT 模型都有下面两个属性:
解码器在原文的隐藏向量上执行一个注意力机制。
编码器和解码器是两种不同的模块,且在解码器开始运算前编码器需要先编码原文语句的信息。
在这篇文章中,我们介绍了 Ofir Press 等研究者的探索,他们尝试在不使用上面两种机制的情况下测试 NMT 模型的性能到底有多好。它们先从 Bahdanau 等人在 2014 年的研究出发移除注意力机制,并且将编码器和解码器统一为一个「贼简单」的完整模型,它的轻量程度甚至和一般的语言模型差不多。
简化模型的后果就是翻译的速度「异常」迅速,基本上只要在读取第一个词后就能马上提供对应的译文,并且在读取完最后一个原文词后就能完成整句的翻译。
具体而言,这种即时翻译(eager translation)模型使用恒定的记忆量,因为在每一个时间步上,它只会使用前一个时间步而不是前面所有时间步的隐藏状态。他们的方法不是将整个原文句子塞入单个隐藏向量,而是将原文句子的前缀向量和前一时间步的翻译结果填充到一个动态的记忆向量,并即时预测对应的译文(目标 Token)。这一过程会重复进行,且每次会读取一个原文词。
如下展示了即时翻译模型的主要结构,因为它将编码器解码器架构统一为类似语言模型的结构,所以为了处理原文序列和译文序列序列的长度不相等情况,他们会采用 ε 作为一种占位符补全译文长度,并在全部翻译完后删除所有ε。但是如果原文序列不够长而译文序列很长呢?那么就需要给原文末尾也要加上ε了。

图 1:即时翻译模型将句子「The white dog」翻译为西班牙语。原文(译文)token 用蓝色(红色)字体表示。ε是 padding token,在后处理中要移除。上图展示了两层 LSTM 的即时翻译模型。
在实践中,即时翻译所要求的大多数修正都会影响到预处理过程,所以总而言之它需要大量的数据预处理过程,包括词对齐等。在 Ofir Press 等人的试验中,他们证明了这种极简的即时翻译模型与基于注意力的机器翻译模型(Bahdanau et al., 2014)效果相当,它在长序列翻译任务上比基于注意力的要更优秀,但在短序列上效果更差。
论文:You May Not Need Attention

论文地址:https://arxiv.org/pdf/1810.13409.pdf
项目地址:https://github.com/ofirpress/YouMayNotNeedAttention
摘要:在神经机器翻译即 NMT 中,如果没有注意力机制和分离的编码器-解码器结构,我们能得到多好的结果?为了回答这个问题,我们引入了一个循环神经翻译模型,它没有使用注意力机制,并且也没有分离的编码器-解码器结构。我们的即时翻译(eager translation)模型具有低延迟,能在读取第一个源 token 的时候写出目标 token,并在解码过程中只需要常量的内存。该模型的性能和 Bahdanau 等人在 2014 年提出的基于注意力机制的模型相当,并在长句子翻译中表现得更好。
即时翻译模型的训练需要先对训练集进行预处理。首先我们需要推断源/目标句对之间的对应关系,假定一个目标词对应(至多)一个源词,正如 Brown et al. (1993) 所做的。然后我们要让源/目标句 (s_i , t_j ) 对进行位移处理,使得对于所有 (s_i , t_j ), i ≤ j。
为此,我们首先使用现成的对齐模型 (fast align; Dyer et al., 2013),然后插入最少数量的 ε token 到目标句中,如图 2 所示。这些 ε token 在训练和推断中会用到,但在生成翻译的后处理步骤中会移除。当句子对长度不同时,也会插入ε token 使它们变得相同。
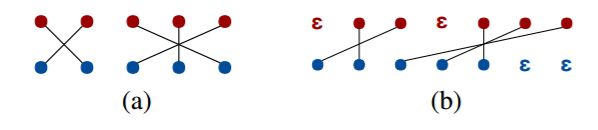
图 2:源(蓝)和目标(红)序列在预处理前(a)和后(b)的对齐状态。
实验结果
在英到法(EN→FR)和英到德(EN→DE)翻译任务上,我们都是在 WMT 2014 数据集上训练的,使用 newstest2013 作为验证数据集,并在 newstest2014 上测试。
我们使用 4 个有 1000 个单元的 LSTM 层作为我们的即时模型,并且嵌入向量的大小是 500。模型在训练中对 LSTM 和嵌入使用 dropout 正则化,使用 Merity et al. (2017) 的方法。
作为参考模型,我们使用 Bahdanau et al. (2014) 实现的 OpenNMT (Klein et al., 2017)。我们使用的模型的编码器具有两个 LSTM 层,解码器也是,都有 1000 个单元,嵌入大小为 500。这意味着参考模型和即时模型的参数数量相近。
即时模型的实验结果如表 2 所示。在法到英和英到法翻译任务中,该模型的 BLEU 分数至多比参考模型少 0.8%。在更难的德到英和英到德翻译任务中,该模型的 BLEU 分数至多比参考模型少 4.8%。
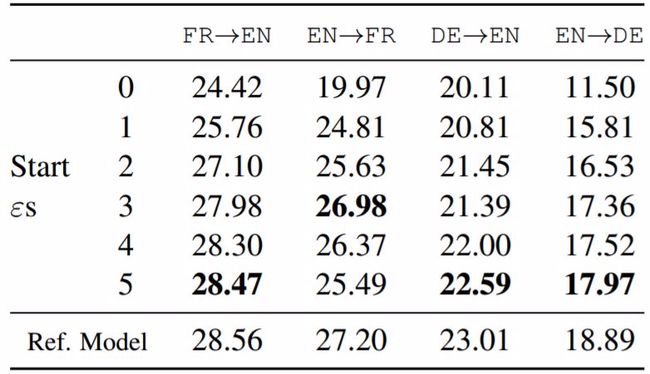
表 2:在测试数据集上的参考模型和即时模型的 BLEU 分数(初始的ε padding token 依此为从 0 到 5)。
表 3 中,当句子长度足够大时,在法到英和德到英翻译任务中,我们的模型击败了参考模型,表明即时模型在较短序列上表现较差,在较长序列上表现较好,而长序列翻译已知对于基于注意力机制的模型是较困难的(Koehn and Knowles, 2017)。表 5 展示了全部 4 个任务中长序列翻译结果的更多细节。
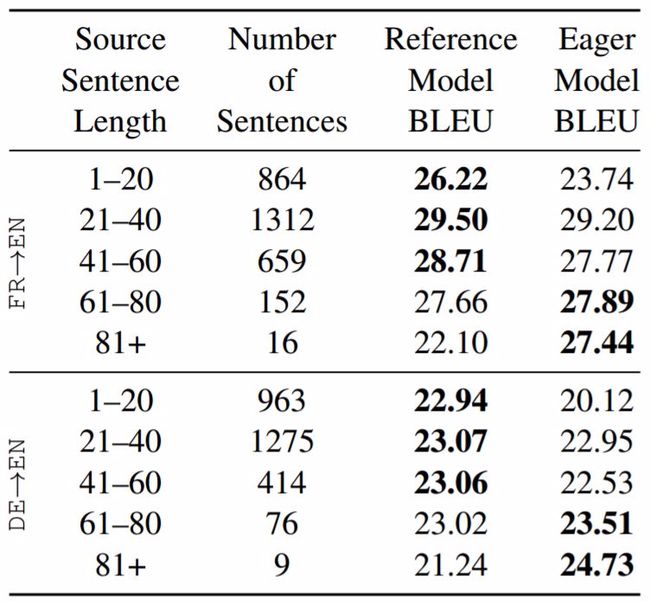
表 3:在法到英和德到英翻译任务测试中,参考模型和即时模型的 BLEU 分数随句子长度的变化。
表 5:在所有 4 个任务上,BLEU 分数随句子长度的变化。
讨论
在 Reddit 上,网友们对该模型提出了质疑:认为即时模型的预处理过程实际上是作为注意力机制的替代品,而没有使模型更简单,并且注意力机制具有更加优雅和普适的优势。「你可能不需要注意力,如果你有词对齐……」
对此,作者的回答是:注意力模型需要在内存中存储所有源句 token 的编码,而即时模型不需要。在内存不足的条件下很有用,这也是这类模型相对于注意力模型的优势之一。
当前在 Reddit 页面上已经有了数十条评论,更多讨论可以参见原网页。
Reddit 地址:https://www.reddit.com/r/MachineLearning/comments/9t88jj/r_you_may_not_need_attention_summary_pytorch_code/