英特尔推出OpenVINO工具包,聚焦边缘计算的视觉处理方案有哪些新意?
雷锋网按,7月27日,英特尔举办以“智能端到端,英特尔变革物联网”为主题的视觉解决方案及策略发布会,正式推出OpenVINO视觉推理和神经网络优化工具套件。
首先,英特尔副总裁兼物联网事业部中国区总经理陈伟博士阐述了聚焦研发边缘计算和计算机视觉解决方案的战略意图;其次,英特尔中国区物联网事业部首席技术官兼首席工程师张宇博士介绍了OpenVINO的技术细节;此外,英特尔中国销售总经理王稚聪分享了OpenVINO具体市场应用。最后,合作伙伴代表介绍了与英特尔的合作历程,以及使用英特尔硬件和包括OpenVINO工具包在内的软件工具等开发的行业应用产品。
战略:聚焦研发边缘计算和计算机视觉解决方案

雷锋网(公众号:雷锋网)注:英特尔副总裁兼物联网事业部中国区总经理 陈伟博士
首先,英特尔副总裁兼物联网事业部中国区总经理陈伟博士阐述了英特尔聚焦研发边缘计算和计算机视觉解决方案的战略意图。
陈伟指出,过去几年,由于数据的蓬勃发展,不管是消费者数据还是行业数字化产生的数据,都是在边缘产生的,直接挤压到了对存储和带宽的要求,以至于物联网行业内都在讨论边缘计算的概念,对于边缘大数据也有了新的思考。英特尔聚焦在视频领域是因为视频的数据量最大、最复杂,浓度也最高,确实挤压到了端到端的架构,“在英特尔,在物联网事业部,我们把视频技术当成是一个横向的技术,作为我们的主要战略”。
但是,把所谓边缘的人工智能真正推向边缘并不是一个很简单的事情,在今天来看也没有一个一劳永逸的方案。为此,英特尔通过提供业界最全面的计算平台助力人工智能。英特尔首席研究员、英特尔中国研究院认知计算实验室主任陈玉荣在2018CCF-GAIR大会上详细介绍了该平台的具体内容。

英特尔的硬件支持从混合型到专用型,从云端到终端的最广泛的AI应用负载。并提供多种软件工具组合来帮助加速AI解决方案的开发周期。还采取基于社区和解决方案驱动的方法,以拓展AI和丰富每个人的生活。
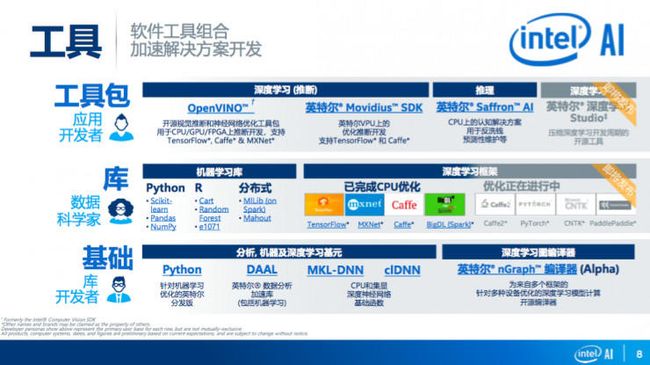
在工具方面,对于应用开发者,英特尔提供了很多工具来提升性能和帮助加速解决方案的部署。针对深度学习,开源的OpenVINO和英特尔Movidius SDK 可以通过模型的转换和优化,提供针对英特尔各个目标硬件优化的深度学习推断部署。
据陈伟博士介绍,OpenVINO于5月16日在全球发布,经过过去几个月的合作、研发、优化,7月27号下午正式面向中国市场发布。具有跨平台的灵活性,支持和兼容主流的深度学习框架,使边缘计算解决方案能够提高性能。“开源也是在我们的计划之中,开源的目的是使得OpenVINO变成生态链的一个主要部分。”
技术:推出OpenVINO工具包,助力计算机视觉和深度学习开发

雷锋网注:英特尔中国区物联网事业部首席技术官兼首席工程师 张宇博士
接着,英特尔中国区物联网事业部首席技术官兼首席工程师张宇博士介绍了OpenVINO的技术细节。
据介绍,OpenVINO是一个可以加快高性能计算机视觉和深度学习视觉应用开发的工具套件,它能够支持英特尔平台的各种加速器,包括CPU、GPU、FPGA以及Movidius的VPU,来进行深度学习,同时能够直接支持异构的执行。
使用的对象是软件开发人员以及开发、监控、零售、医疗、办公自动化以及自动驾驶等领域的数据科学家。
OpenVINO对深度学习和传统的计算机视觉这两类方法都有很好的支持,包含一个深度学习的部署工具套件,这个工具套件可以帮助开发者,把已经训练好的网络模型部署到目标平台之上进行推理操作。
这样的一个深度学习的部署套件主要包括两个网元,一个网元称之为模型优化器,另外一个被称之为推理引擎。模型优化可以把开发者基于一些开放的深度学习的框架所开发的网络模型,针对所选用的目标平台进行优化,把这些优化的结果转换成一个中间表示文件,建成IR文件。
下一步,推理引擎会读取这个IR文件,然后利用相应的硬件插件把这些IR文件下载到相应目标平台上进行执行。同时,在OpenVINO里面,还包含一个传统的计算机视觉的工具库,在这个工具库里包含了经过预编译的而且在英特尔CPU上已经经过优化的OpenCV3.3的版本。
除了对OpenCV的支持以外,在OpenVINO中还包含了对OpenVX以及OpenVX在神经网络扩展的支持,同时在媒体、视频、图像处理领域还包含了已经非常成熟的英特尔的媒体软件开发套件Media SDK,它可以帮助开发者非常方便的利用英特尔CPU里面集成显卡的资源来实现视频的编码、解码以及转码的操作,而且支持多种视频编解码的格式,如H.264、H.265等。

张宇博士也介绍了如何利用英特尔的深度学习部署工具套件开发深度学习的应用。
目前比较流行的深度学习的框架主要有三个,即Caffe、Tensor Flow、MxNet,英特尔在设计OpenVINO的时候考虑到了目前开发者的习惯,所以模型优化器通过配置以后可以把这三个主要的开发框架上所开发的网络导入到英特尔的平台上,而且导入的过程中,会根据目标平台的特性做一定的优化,把这些优化的结果转换成IR文件。
文件里会包含优化以后的网络拓扑结构,以及优化之后的模型参数和模型变量。这个IR文件后面会被推理引擎进行读取,推理引擎会根据开发者所选用的目标平台去选用相应的硬件插件,把最终的文件下载到开发者的目标平台之上。

目前所支持的插件包括CPU的插件,核心显卡的GPU插件,FPGA的插件以及Myriad VPU的插件。插件使用完之后,可以把相应的IR文件下载到目标平台之上,开发者可以通过一些测试程序或者应用来验证它的正确性。在验证完之后可以把这些推理引擎和中间表述文件一起下载到或者集成到最终应用里进行部署,这是完整的进行深度学习应用开发的流程。
目前,英特尔通过向FPGA的插件,可以把中间文件下载到英特尔Arria10的FPGA板卡之上,调用DLA的库,实现在FPGA上的网络的推理操作;或者通过MKLDN的插件,把中间文件下载到英特尔的凌动处理器、酷睿处理器或者是至强处理器之下,在这些通用的CPU之上实现深度学习的运行;再或者,通过CLDNN以及OpenCL的接口,把一些神经网络运行在英特尔的集成显卡之上;或者是利用Movidius的插件,把神经网络运行在基于Myriad2的深度学习计算棒,或在今年年底将要推出的Myriad X上。
通过这样一些插件,可以选择不同的异构的计算结构,而且到今后,如果有一个新的硬件的架构需要支持的话,也可以设计一个相应的插件来实现这样的一些支持的扩展,而不需要改变插件之上的一些软件,从而降低开发者的开发成本。

OpenVINO工具套件访问实际上是分层的,不同的开发者可以根据自己的使用要求以及开发的能力去选择不同的API接口进行调用OpenVINO。比如公司做一个考勤系统,完全可以调用OpenVINO带的人脸识别示例,根据公司员工数据库做一个相应的样本集,根据样本集的调用可以找到当前这个员工是不是这个数据库里的员工。
OpenVINO已经提供了一些网络的实现,即Model Zoo,可以在这个实现基础之上实现相应的应用。

总的来说,OpenVINO的优势有以下几点。
首先,性能方面,通过OpenVINO,可以使用英特尔的各种硬件的加速资源,包括CPU、GPU、VPU、FPGA,这些资源能够帮助开发者提升深度学习的算法在做推理的时候的性能,而且执行的过程中支持异构处理和异步执行,能够减少由于系统资源等待所占用的时间。
另外,OpenVINO使用了经过优化以后的OpenCV和OpenVX,同时提供了很多应用示例,可以缩短开发时间。这些库都支持异构的执行,编写一次以后可以通过异构的接口支撑跑在其他的硬件平台之上。
在深度学习方面,OpenVINO带有模型优化器、推理引擎以及超过20个预先训练的模型,开发者可以利用提供的这些工具,快速的实现自己基于深度学习的应用,而且OpenVINO使用了OpenCV、OpeenVX的基础库,可以利用这些基础库去开发自己特定的算法,实现自己的定制和创新。

最后,张宇展示了目前使用OpenVINO能达到的性能水平。张宇团队用了像Google Nex这样一些开放的网络,在英特尔不同的硬件平台之上做了一些性能方面的测试,把这些测试的结果跟现在市面上的一些比较流行的平台的结果做了简单的对比,在英特尔的酷睿i77800X这个处理器平台上去跑上述开放网络的话,它的相应的性价比是目前市面上解决方案的两倍以上。
如果选用FPGA的产品,它的性能、功耗、成本比值的综合考量的因素性能大概能达到1.4倍以上。如果是用Movidius的话,这样的性能进一步提升能达到5倍以上。英特尔Movidius VPU是低功耗计算机视觉和深度推断的解决方案。在边缘计算方面,可以通过使用多个Movidius VPU,实现高强度、高效的媒体和视觉推断。在终端,Movidius VPU在超低能耗下可以提供优异的推断吞吐量,可以用于物联网传感器、个人计算机和其他终端产品中进行视觉处理和推断。
应用:提出六大应用方向和前景方案

雷锋网注:英特尔中国销售总经理王稚聪
发布会的第三个环节,英特尔中国销售总经理王稚聪分享了OpenVINO和人工智能技术具体的市场应用。
在中国,英特尔提出了六大应用方向和前景方案。
交通监控。采用英特尔FPGA和Movidius VPU的摄像头可捕捉数据,并自动将其发送至下游十字路口系统,帮助交通部门优化交通和做好规划。这些信息可通过车载系统或应用直接传达给司机,帮助他们规划路线。
公共安全。借助使用OpenVINO工具包开发的Myriad VPU和算法,经过训练的深度神经网络现在可利用推理功能通用面部识别分析并识别失踪儿童。采用了这一技术的城市执法机构可在经过训练的数据集匹配到人群中已报告失踪儿童的脸部时,即时收到相关通知。
工业自动化。英特尔视觉解决方案可帮助智能工厂融合OT和IT,重塑工业业务模式和增长战略。生产控制将可自动、流畅运转,缩短上市时间。
机器视觉。借助人工智能增强工业机器视觉,支持更精准的工厂自动化应用。解决方案组合摄像头、电脑和算法,以分析图像和视频,在边缘提供可以用于指导行动的重要信息。
响应式零售。在边缘使用英特尔计算机视觉解决方案的零售商,可以快速识别特定客户或客户行为模式,从而提供个性化的精准营销服务。
运营管理。通过使用基于英特尔架构的计算机视觉解决方案,零售商可简化运营、管理库存、优化供应链和增强推销能力,并帮助他们发掘数据的更高价值。
陈伟博士表示,“当下,由数据驱动的技术正在重塑着我们所处的世界并为我们描绘着未来的无限可能。值得一提的是,中国市场在人工智能和计算机视觉方面的应用处于全球领先位置,我们已经把中国市场的需求信息规划到未来的产品线里。相信在不久的将来,我们会看到更多来自中国市场的智能视觉创新应用。”
最后,云从科技项目总监李军,大华公司研发中心副总裁殷俊,宇视研发副总裁AI产品线总监汤立波,科达研究院执行院长曹李军,中科英泰副总裁刘福利,大疆创新科技资深产品专家William Wu,阿里巴巴OS事业部智能硬件研发负责人马飞飞等英特尔合作伙伴代表纷纷登台,介绍了与英特尔的合作历程,以及使用英特尔硬件和包括OpenVINO工具包在内的软件工具等开发的具体的行业应用产品。
会后采访:
会后,包括雷锋网在内的多家媒体对此次参会的多位英特尔负责人进行了采访,谈到OpenVINO跟英特尔其他以前推出来的SDK有什么本质的区别,陈伟博士答道:“以英特尔物联网事业部来说,我们之前也推出过其他的一些SDK,比如Movidius SDK,主要做媒体处理。OpenVINO实际上在这次发布的时候包含了Movidius SDK,我们在这个基础之上做了进一步的功能扩充。”
“功能的扩充主要体现在几个方面:一是增加了对深度学习的功能支持,你可以看到我们有一个深度学习的部署工具套件,里面包括了模型优化器和推理引擎,这完全是新的。另外,我们在Movidius SDK基础之上,增加了对OpenCV、OpenVX等等这些现在在传统的计算机视觉领域用的比较普遍的函数库的支持,而且这些函数库都是在英特尔的CPU上做了优化的。”
“所以跟原有的Movidius SDK相比,原来只是做编码、解码的加速,现在不仅能做编解码的加速,也能做一些视频处理工作,我们把MovidiusSDK结合在一起的目的是什么?我们看到一个完整的视频处理系统,从它的处理流程来看,第一步要做编解码,解码以后,把解码的图片交给相应的处理引擎做深度学习或者是传统的计算机视觉的一些处理操作,到最终的结果。我们把在整个流水线里面所用到的所有工具打包在一起放到OpenVINO里面,让开发者只用一个工具就能把所有的需求都满足。”
雷锋网对此次采访其他涉及OpenVINO的关键问题进行了不改变原意的编辑与整理:
1.对于英特尔,是否有相关的参考设计方案,或者是从端到端的参考方案能够提供给客户,更快速的应用到OpenVINO这个系统?同时,在OpenVINO工具里,如果我的设备里同时存在FPGA、GPU、CPU以及其他的处理单元,怎么去规划它的计算力使用的优先级?
顾典(英特尔技术专家):我首先回答第一个问题。为了更加速客户的产品开发和部署,我们有没有实力供给客户做参考。在张博士的演讲当中也略微提到了几点。
第一,我们有一些预训练的模型,会在OpenVINO的安装包里涵盖。这个模型正在不断地扩容,早些时候的一个版本是100多个模型,在我们当前这个版本当中已经扩展到了150个模型。
大家刚刚也提到英特尔在发布自己的SDK上和以往有什么不一样。其实另外一个比较细节化的不一样,因为我们知道人工智能和深度学习发展非常快,所以网络模型更新迭代也是非常快。
我们发布这样的软件工具,在更新迭代的速率上也会做和以往做不一样的提速处理。比如OpenVINO在今年上半年做了一个发布,在下半年我们还规划了两次很大的更新,所以大家也可以从更新的速率上看出来,我们也是为了方便客户的开发,缩短客户的时间。
另外,OpenVINO里面有一个叫Open Model Zoo,这不是一个简单的网络参考,而是基于一些网络组合的融合,已经把具体的客户的应用实例开发出来,当然这个开发实例不是完整完善的应用,这只是一个参考,但客户完全可以基于Open Model Zoo现成的应用样本进一步的做好开发。
第二个问题,如果我们设计目标系统里有不同的硬件组件,比如我有FPGA或者是GPU,在OpenVINO工具包里有一个特殊的插件,叫异构计算插件,刚刚张博士的演讲里提到一点,我们如果目标系统里面涵盖了不同的硬件设备,可以通过异构的插件进行非常灵活的配置。
我这里强调了配置,不是重新写很复杂的代码,把工作负载分配到不同的硬件软件上,我们会有相对简单的API,大家可以在里面写,哪一个部分的Workload可以在GPU上面实现,哪一部分不被硬件支持。这个配置相当简单、相当灵活,也带有一定的客制化的冗余,所以刚开始的时候会有一定的学习成本,但是上手以后,对于开发难度来说大大降低,对于客户和合作伙伴来讲,开发周期也会起到非常好的缩短效果。
2.整个图像处理的算法一直很复杂,我们在处理四元异构加速问题上一直存在,存在了七八年的时间,我不太知道为什么在这样一个节点推出这样一个产品,是不是在解决异构加速上的关键问题,关键问题是如何解决的?
顾典:在历史上以往所谓的处理计算机视觉的异构计算里,我们往往强调的是图像处理本身,比如包括一些通用的核心处理,这些部分构成了传统意义上的异构计算,即更偏图像异构处理的计算,从SOC的设计角度来说,这部分的图像异构计算在过去相当长的发展历史阶段已经得到了比较充分的满足。
为什么今天还会强调异构计算,是因为人工智能带来了一种新的计算需求。比如说卷积神经网络或者是深度学习网络。网络类型的计算对于图象处理是新的挑战,在这样一个新的计算需求下,我们重新再提出异构计算这个概念。
从英特尔自身的优势来说,因为结合了CPU,显核GPU还有FPGA和VPU不同的产品组合,所以从自身推广自己的产品平台角度来说,我们也认为这是需要帮助客户解决的问题。
从这两个出发点来说,异构计算还是因为需求问题存在,也是因为本身我们要推广产品的一个需要。里面关键的一个问题是,我们在OpenVINO的开发工具里面做了很多考虑怎么样使异构计算变得更容易的一些方式,包括刚刚讲的可配置的异构计算插件的解决方式。
张宇:我补充一点。如果你看整个趋势的话,英特尔产品线的变化趋势,体现了我们对整个人工智能处理的判断,从之前来看,我们的产品线主要集中在通用处理器和显核和GPU上,这两种主要做一些相对来说比较通用的逻辑计算和一些视频编解码的计算。
到了人工智能,我们看到一些相对来说比较专业的处理器,像Movidius和一些高清的FPGA的处理器,有很普遍适用的场景,所以我们认为人工智能计算适应的架构是根据节点要求的多样化架构,很难有单一的一种类型的行为架构来满足所有节点对人工智能计算的要求,这是我们的判断。
基于这个判断,英特尔产品线在这几年变的丰富了,我们的FPGA和Movidius是通过这几年的收购来进入到英特尔的产品当中来,为什么在这个时间节点推出OpenVINO,因为硬件产品线丰富了,就有一个要求,开发者在使用硬件的时候,他不希望有不同的开发工具,不同的开发语言,这样会增加他的开发成本,所以我们认为需要给开发者一个通用的、统一的开发接口来降低整个开发开销,所以我们认为OpenVINO在这个时候推出是适宜的。
3.问一下张博士,在您刚才介绍的时候,您对OpenVINO的定义是它能够加速高性能计算视觉,包括深度学习视觉部署开发速度的套件,但是在终端性的应用里不光是开发速度,可能对于运算的效率、功耗都更为重要,所以OpenVINO在这些方面有没有一些计划?另外,算法也是不断演进的,在兼容不同的算法方面有什么考虑?
张宇:在这一方面我们既考虑到开发的应用性,同时也考虑它开发之后的高效性。应用性主要体现在我们对一些开放的人工智能架构的支持,因为现在开发者基本上都是在Caffe、Tensor Flow、MxNet以及一些其它的网络框架上来进行开发,所以我们直接提供了对这些框架的支持,保证开发者在这个框架下所写的模型,通过我们的工具能够很快的转换在硬件平台之上。
高效性的体现主要是体现在对硬件的支持上,以前你写的模型只是跑在通用处理器上,但是终端的设备里面有一些加速引擎或者是核显,或者是有Movidius、FPGA,我们会帮助你,把你所写的模型跑到这些加速引擎之上,来达到更好的效果,这是我们在做的一些工作。
顾典:做一些补充。除了刚刚张博士讲的,从算法的效率角度来说,我们在OpenVINO工具设计上还做了非常细致的考虑,在刚刚的介绍里面提到OpenVINO的架构里有一些组件,比如有一个组件叫模型优化器,叫Model Optimizer,在Model Optimizer这个层级的API里面,我们会基于和广大生态合作伙伴积累的经验实施一些比较通用的优化策略。刚刚张博士演讲当中也提到了一些量化的策略,我们会通过模型的优化器去实现。这一个层级算法效率的提升,它的实现和底层硬件没有任何关系,这是一些通用策略。
另外,目前我们的OpenVINO的版本已经开源了模型优化器,这个是开源版,基于开发者的经验可以自己自定义优化策略,把优化策略通过自己加一些代码就可以形成自定义的扩展,把扩展加进去,再把模型导入以后,你的模型就可以被增加的这部分功能优化。这是第一个层面。
第二个层面,如果我们把转化过的模型推送到推定引擎的时候,因为推定引擎最终会使代码下到最底层的硬件,这一层面上我们会就下到哪一个硬件类型,去做关于硬件这部分的优化。和硬件相关的这部分优化是需要开发者对于相应的硬件IP有一定深入的了解。
4.从英特尔的角度来看,您是否会觉得人工智能在现阶段FPGA是一个比较好的载体?另外,这种集成了CPU、GPU类型的FPGA,跟通过软件来去协同共同的CPU、GPU、VPU这种类型的架构的项目之间有何区别?
张宇:我认为目前人工智能处在初始阶段,我把它定义为一个实验科学,而不是理论科学,因为现在大家做的很多算法实际上是通过摸索、实验出来的,比如我用SSD做检测,效果不错,但是这个算法的上限在哪?这个很多人说不清楚,因为现在的人工智能还缺少一个理论的支撑。
现在如果我们看人工智能,其实没有一个完整的理论体系,大家更多的是利用各种实验的方式找到这个方式是比较好的,用到某一个具体的领域,但是这个方法适用度到什么程度,换一个领域是不是能够适用,只能通过实验的方式进行验证,而不能用理论的方式进行验证,这是目前人工智能的现状。
在这种情况下,我看到整个人工智能芯片的发展,目前还是FPGA、CPU,在算法不固定的情况下,还是用通用处理器比较多一些。但是在一些前端的设备里,因为算法相对固定了,通过一些实验验证完的算法可以把它固定下来,这个时候用的ASIC比较多一些,比如现在在我的摄像机里用Movidius这样的ASIC芯片去实现特定的算法,这是比较高效的,因为算法固定,ASIC的效率一定是最高的,而且它的功耗低,能够满足前端设备对低功耗的要求。
所以刚才您的问题,FPGA有FPGA的适用场景,ASIC有ASIC的使用场景,通用处理器也有通用处理器的使用场景,尤其是在训练阶段。所以这是我觉得目前整个人工智能发展现状的局限。
到了今后,如果理论进一步完善了,也可能会有新一代的处理器架构出现,那个时候到底人工智能芯片是什么样子?我们现在很难说,但是我们可以用一个方式进行影射,用什么方法进行影射呢?我们可以对比一下区块链。
大家知道,以比特币为例,虽然比特币商业价值我们不说,我们看它的理论价值,比特币的理论价值相对来说是比较完善的,因为它是以哈希算法为基础,相对来说算法固定了就可以用一些相对来说比较固定的硬件架构实现。
所以你看整个比特币矿机芯片的发展阶段,第一个阶段用的是GPU和CPU,第二个阶段是FPGA。因为FPGA既有一定的灵活度,同时性能功耗比比较高。到了第三个阶段是ASIC。现在像比特大陆等等这些矿机厂商都在做自己的芯片,原因在于他们的理论已经比较完善了,所以人工智能很可能也是类似的,但是因为这个理论不太成熟,所以很难去预估今后人工智能芯片价格到底是什么样子,在目前这个阶段还是根据特定的应用场景训练来选择的视觉运算。
做目前视频类的人工智能运算的时候,不仅仅有卷积神经网络这一个要素,因为做视频处理涉及到其他的要素,比如视频过来之后要做编解码,跟卷积神经网络是不一样的,不可能用同样的架构来实现,所以如果要一个高效系统的话,应该有一个专门去做编解码的硬核。
另外,做深度学习的时候,有的时候还要做一些图形的转换,比如缩放或者做一些处理,本身这些处理不属于卷积范畴,如果有一些相应的配合的硬核去做的话效果会更高。
所以如果从整个系统的角度来看,如果有FPGA的资源,有一些针对特定运算加速的资源,对系统来说肯定会更高。所以我们做芯片设计的时候,今年年底要推出的新一代的Movidius芯片,叫Myriad X,这也是一个融合的架构,是异构的,里面既有对卷积神经网络加速的单元,也有一些对图像编解码的加速单元,以及图像处理的加速单元,这样可以给用户提供一个完整的算例,来帮助他们实现深度学习所需的操作。
相关文章:
英特尔2020年将推独立GPU,但CPU霸主研发高端GPU的历史有些“辛酸”
英特尔戴金权:详解全新大数据分析+AI平台Analytics Zoo | CCF-GAIR 2018
英特尔宣布收购eASIC,进一步增强“结构化ASIC”设计能力
英特尔陈玉荣:全面解析英特尔人工智能计算平台 | CCF-GAIR 2018