最全Java多线程知识点整理
无论是开dubbo接口、http接口,还是Java Web服务端开发,亦或者是各种中间件的开发;无并发,不Java,你们懂的;必须专门开一篇以示尊重,Java不息,更新不止。
1.相关概念
1.关键字 synchronized
使用场景:
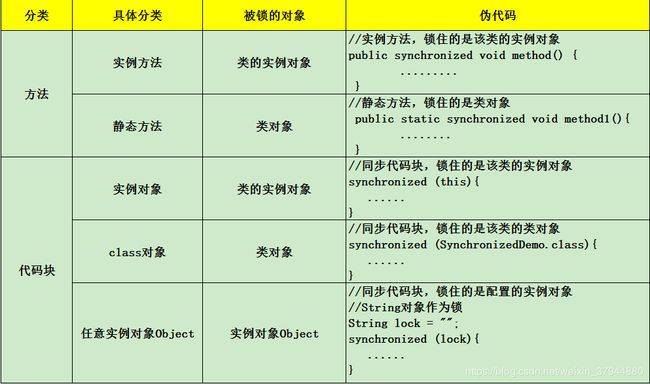
原理:
同步代码块:
反编译可以看到monitorenter,monitorexit指令(相对于不加synchronized多出来);
原理:每个对象有一个监视器锁(monitor),当monitor被占用时就会处于锁定状态,
线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、monitor的进入数为0,则该线程进入monitor,将进入数设置为1,该线程即为monitor的所有者。
2、线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3、其他线程占用monitor,则该线程进入阻塞状态,直到monitor进入数为0,再尝试monitor所有权。
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
执行后,monitor进入数减1,如果减1后进入数为0,则线程退出monitor,不再是该monitor所有者。
其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
总结:Synchronized的语义底层是通过一个monitor的对象来完成,
wait/notify等方法也依赖于monitor对象,故只有在同步的块或者方法中能调用wait/notify等方法,
否则会抛出java.lang.IllegalMonitorStateException的异常。
同步方法:
原理:不直接通过指令monitorenter和monitorexit来完成;
常量池中多了ACC_SYNCHRONIZED标示符;
方法调用时,先检查方法的ACC_SYNCHRONIZED访问标志是否被设置,
如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor;
本质上与上面没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
2.接口 Lock
ReentrantLock是唯一实现了Lock接口的类;
lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()用来获取锁;
unLock()方法用来释放锁。
原理:AbstractQueuedSynchronizer会把所有的请求线程构成一个CLH队列,
当一个线程执行完毕(lock.unlock())时会激活自己的后继节点,但正在执行的线程并不在队列中,
而那些等待执行的线程全部处于阻塞状态 。
lock源码:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
当前线程会首先尝试获得锁而不是在队列中进行排队等候,
这对于那些已经在队列中排队的线程来说显得不公平,这也是非公平锁的由来;
对于刚来竞争的线程首先会通过CAS设置状态,如果设置成功那么直接获取锁,执行临界区的代码,
反之调用acquire(1)进入同步队列中。
如果已经存在Running线程,那么CAS肯定会失败,则新的竞争线程会通过CAS的方式被追加到队尾。
总结:1、调用lock方法,会先进行cas操作看可否设置同步状态1成功,成功则执行临界区代码(抢锁成功)
2、如果不成功获取同步状态,如果状态是0那么cas设置为1(没有有锁的其他线程)
3、如果同步状态既不是0也不是自身线程持有会把当前线程构造成一个节点(其他线程有锁)
4、把当前线程节点CAS的方式放入队列中,行为上线程阻塞,内部自旋获取状态(内部无限循环)
5、线程释放锁,唤醒队列第一个节点,参与竞争。重复上述。
3.lock与synchronized的区别
Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
synchronized不需要用户去手动释放锁,Lock则必须要用户去手动释放锁;
synchronized在发生异常时,会自动释放线程占有的锁,不会导致死锁现象发生;
Lock在发生异常时,如没有通过unLock()去释放锁,则可能造成死锁现象,一般在finally块中释放锁;
Lock可以让等待锁的线程响应中断,synchronized不行(只能一直等待,不能中断等待的线程);
通过Lock可以知道有没有成功获取锁,synchronized不行;
Lock可以提高多个线程进行读操作的效率;
Lock可以读写分离(读与读不影响)
竞争资源不激烈,两者性能差不多,竞争资源非常激烈时,Lock的性能要远远优于synchronized。
4.可重入锁
如果锁具备可重入性,则称作为可重入锁;
基于线程的分配,而不是基于方法调用的分配;
synchronized和ReentrantLock都是可重入锁;
如:线程调用synchronized修饰的method1(其实锁住的为类的实例对象),
method1中调用synchronized修饰的method2时不用重新申请锁(基于线程分配锁)
5.可中断锁
可以相应中断的锁;
synchronized不是可中断锁,Lock是可中断锁;
如:中断等待线程
6.公平锁
公平锁即尽量以请求锁的顺序来获取锁;
synchronized是非公平锁,ReentrantLock和ReentrantReadWriteLock默认非公平,可设置成公平;
ReentrantLock lock = new ReentrantLock(true) 公平锁;
7.读写锁
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁;
线程之间的读操作不会发生冲突;
ReadWriteLock。
8.乐观锁和悲观锁
悲观锁:别人想拿这个数据就会阻塞直到它拿到锁;
乐观锁:不上锁,但在更新的时候会判断一下在此期间别人有没有去更新这个数据。
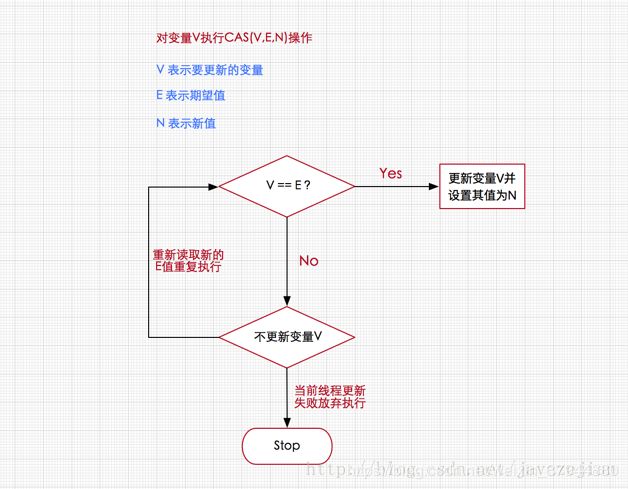
9.CAS操作
CAS操作是乐观锁;
有的CAS操作都是Unsafe类来实现的,且都为native方法(java调用非java方法,java有局限性);
demo: CAS(V,E,N)
V表示要更新的变量
E表示预期值
N表示新值
如果V值等于E值,则将V的值设为N。若V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做;
10.volatile 关键字
Java提供了volatile关键字来保证可见性;
共享变量被volatile修饰,会保证修改的值会立即被更新到主存,其他线程读取时,会去主存中读取新值;
普通共享变量被修改之后,什么时候被写入主存是不确定的;
如,当线程2进行修改,会导致线程1工作内存中缓存变量无效,只能去主存读取(没有则等待;
对禁止指令重排序有一定作用,不能将在对volatile变量访问的语句放在其后面执行,前面也一样;
原理:volatile关键字时,会多出一个lock前缀指令,相当于内存屏障。
11.ThreadLocal
每个Thread的对象都有一个ThreadLocalMap,当创建一个ThreadLocal的时候,
就会将该ThreadLocal对象添加到该Map中,键是ThreadLocal(当前线程),值可以是任意类型。
set()和get()方法:get()方法会先找到当前线程的ThreadLocalMap,
然后再找到对应的值。set()方法也是一样。
2.集合类相关
1.ConcurrentHashMap
是一个Segment数组,Segment通过继承ReentrantLock加锁,所以每次锁住一个segment,
保证每个Segment是线程安全的,就实现了全局的线程安全。
concurrencyLevel:并行级别、并发数、Segment数。默认16,ConcurrentHashMap有16个Segments,
理论上,这个时候,最多可以同时支持16个线程并发写,只要它们的操作分别分布在不同的Segment上。
可在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
每个Segment类似HashMap,内部是由数组+链表组成的。不过它要保证线程安全。
segment数组不能扩容,单个segment可以,扩容后,容量为原来的2倍。
put:
根据key的hash值找到相应的Segment(之后是Segment内部的put操作);
Segment内部put操作,加ReentrantLock锁;
如果获得锁,直接put,没有则重试MAX_SCAN_RETRIES次,之后进入阻塞队列等待,知道获得锁;
get:
计算key的hash找到Segment;
根据hash找到对应Segment中的链表(数据+链表);
顺着链表,==或者equals。
2.CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器:
往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,
复制出一个新的容器,然后新的容器里添加元素,完成后,再将原容器的引用指向新的容器;
add源码:
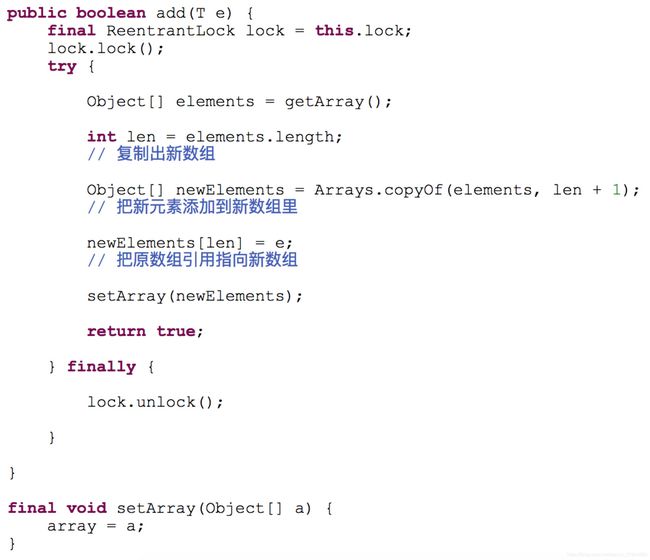
写需要加锁;读的时候不需要;
在写操作完全完成前,读的都是old数据;
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,商品类目的访问和更新场景。
3.Vector继承List接口,HashTable继承Map接口,采用synchronized保证线程安全(性能低);
3.队列相关
在Java并发包中提供了两种类型的队列,非阻塞队列与阻塞队列;
这里的非阻塞与阻塞在于有界与否,是在初始化时是否赋予默认的容量大小;
阻塞有界队列,当队列满了,则任何线程都会阻塞不能进行入队操作,反之队列为空,则不能进行出队操作;
非阻塞无界队列不会出现队列满或者队列空的情况;
两种都保证线程的安全性,即不能有一个以上的线程同时对队列进行入队或者出队操作。
0.AQS(AbstractQueuedSynchronizer)
多种多线程技术的本质原理所在,如ReentrantLock,CountDownLatch等;
维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列
(多线程争用资源被阻塞时会进入此队列,一个node代表一个线程)
方法:
isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
ReentrantLock,state初始化为0,表示未锁定状态。
A线程lock()时,会调用tryAcquire()独占该锁并将state+1。
此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止。
释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。
获取多少次就要释放多么次,这样才能保证state是能回到零态的。
CountDownLatch,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。
这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。
所有子线程都执行完(state=0),unpark()主线程,主线程就会从await()函数返回,继续执行。
1.ArrayBlockingQueue
类图:

一个由数组结构组成的有界阻塞队列;
初始化需要设置大小,默认非公平(可设置);
notEmpty,notFull分别是非空等待队列,非满等待队列;
入队操作(ReentrantLock):
offer(e) 队列未满时,返回true;满时返回false。非阻塞立即返回;
offer(e, time, unit) 指定时间内不能插入数据返回false,成功返回true;
add(e) 队列未满时,返回true;满抛出IllegalStateException(“Queue full”)异常;
put(e) 队列未满时,直接插入无返回值;队列满时会阻塞等待,一直等到队列未满时再插入;
入队源码:



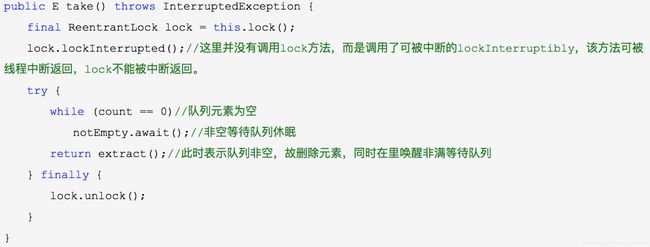
出队操作:
poll() 队列不为空时返回队首值并移除;队列为空时返回null。非阻塞立即返回;
poll(time, unit) 指定时间内队列还为空则返回null,不为空则返回队首值;
remove() 队列不为空时,返回队首值并移除;队列为空时抛出NoSuchElementException()异常;
take(e) 队列不为空返回队首值并移除;为空时会阻塞等待,一直等到队列不为空时再返回队首值;
出队源码:


2.LinkedBlockingQueue
类图:
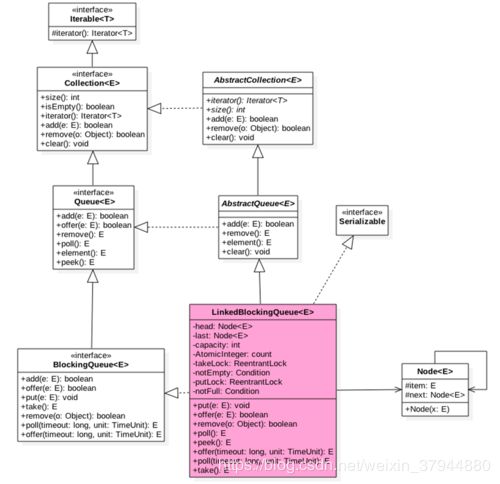
一个由链表结构(单向链表)组成的有界阻塞队列;
初始化默认最大容量,可自行设置;
有两个ReentrantLock锁,takeLock,putLock(ArrayBlockingQueue只有一个);
notEmpty,notFull分别是出队锁上的等待队列,入队锁上的等待队列;
add(e) 队列未满时,返回true;队列满则抛出IllegalStateException(“Queue full”)异常;
offer(e) 队列未满时,返回true;队列满时返回false。非阻塞立即返回;
offer(e, time, unit) 指定时间内不能往队列中插入数据返回false,插入成功返回true;
put(e) 队列未满时,直接插入没有返回值;队列满时会阻塞等待,一直等到队列未满时再插入;
入队源码:
add直接用offer(e),不满足抛出异常;


remove() 队列不为空时,返回队首值并移除;队列为空时抛出NoSuchElementException();
poll() 队列不为空时返回队首值并移除;队列为空时返回null。非阻塞立即返回;
poll(time, unit) 指定时间内队列还为空则返回null,不为空则返回队首值;
take(e) 队列不为空返回队首值并移除;为空时阻塞等待,一直等到不为空再返回队首值;
出队源码:
remove()直接调用poll(),不满足抛出异常;


3.ConcurrentLinkedQueue
类图:
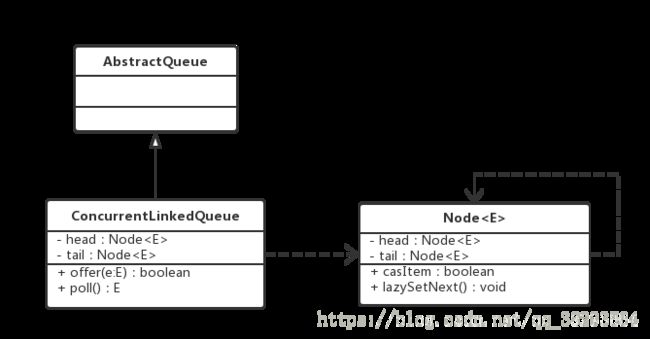
一个由链表构成的(单向链表)无界非阻塞队列;
入队和出队操作使用CAS来实现线程安全;
Node节点内部维护一个volatile修饰的变量item,存放节点值;
add(e) 其内部调用offer方法;
offer(e) 插入到队列尾部,当队列无界将永远返回true;
入队源码:

poll() 队列中有元素则将元素移除队首并返回该元素,没有则返回null;
出队源码:

3.线程池
线程池使得线程可以复用,即执行完一个任务,并不被销毁,可以继续执行其他的任务;
Exccutor类图:
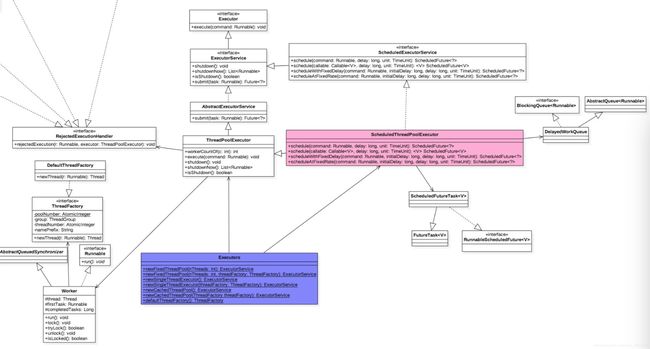
ThreadPoolExecutor继承了AbstractExecutorService,
AbstractExecutorService是一个抽象类,它实现了ExecutorService接口,
ExecutorService又是继承了Executor接口.
Exccutor构造方法:

参数解释:
1.corePoolSize:核心池的大小,创建后默认线程池中无线程(除非调用预创建方法),
任务来后,创建线程,当线程数到corePoolSize后,会把到达的任务放到缓存队列中;
2.maximumPoolSize:线程池最大线程数,表示在线程池中最多能创建多少个线程;
3.keepAliveTime:线程没有任务执行时最多保持多久时间会终止。
默认线程数大于corePoolSize才起作用,调用allowCoreThreadTimeOut(boolean)后下限为0;
4.unit:参数keepAliveTime的时间单位,有7种取值;
5.workQueue:阻塞队列,用来存储等待执行的任务,
一般来说,这里的阻塞队列有以下几种选择:
ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小;
LinkedBlockingQueue:基于链表的先进先出队列,如创建时没指定大小,则为Integer.MAX_VALUE;
SynchronousQueue:不会保存提交的任务,而是将直接新建一个线程来执行新来的任务;
没有容量,无缓冲等待队列,直接将任务给消费者,必须等队列元素被消费后才能继续添加新元素。
6.threadFactory:线程工厂,用来创建线程;
7.handler:拒绝处理任务时的策略,有以下四种取值:
AbortPolicy:丢弃任务并抛出RejectedExecutionException异常;
DiscardPolicy:也是丢弃任务,但是不抛出异常;
DiscardOldestPolicy:丢弃队列最前面的任务(最老的请求),重新尝试执行任务(重复);
CallerRunsPolicy:由调用线程处理该任务;
ThreadPoolExecutor类方法:execute()、submit()、shutdown()、shutdownNow()
1.execute()是Executor中声明的方法,ThreadPoolExecutor进行了具体实现,
该方法可以向线程池提交一个任务,交由线程池去执行。
2.submit()是在ExecutorService中声明的方法,AbstractExecutorService有具体实现,
也用来向线程池提交任务的,但和execute()方法不同,它能返回任务执行结果,
实际上还是调用execute(),并利用Future来获取任务执行结果;
3.shutdown():等所有任务缓存队列中的任务都执行完后才终止,但不会接受新的任务;
4.shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并清空缓存队列,返回尚未执行的任务;
还有getQueue() 、getPoolSize() 、getActiveCount()、getCompletedTaskCount()等获取与线程池相关属性的方法。
execute()源码:
public void execute(Runnable command) {
// 1.当前线程数量小于corePoolSize,则创建并启动线程。
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
// 成功,则返回
return;
}
// 2.步骤1失败,则尝试进入阻塞队列,
if (isRunning(c) && workQueue.offer(command)) {
// 入队列成功,检查线程池状态,如果状态部署RUNNING而且remove成功,则拒绝任务
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果当前worker数量为0,通过addWorker(null, false)创建一个线程,其任务为null
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.步骤1和2失败,则尝试将线程池的数量扩充至maxPoolSize,如果失败,则拒绝任务
else if (!addWorker(command, false))
reject(command);
}
}
流程:
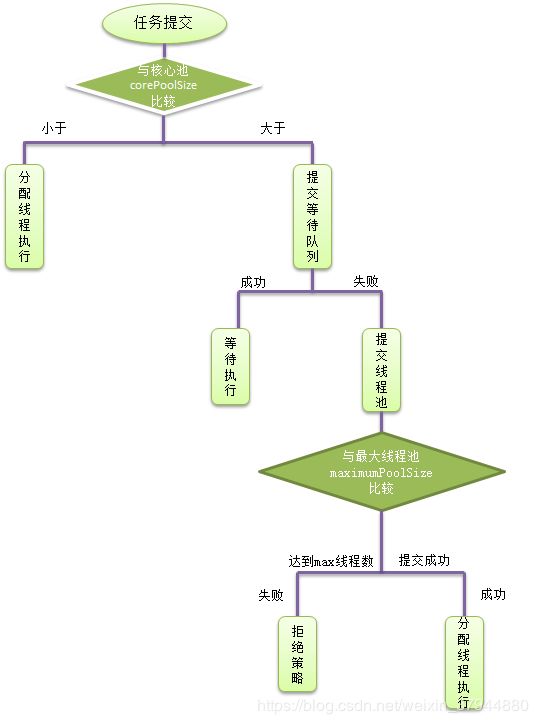
一般不提倡直接使用ThreadPoolExecutor,而是使用Executors类中提供的几个静态方法来创建线程池:
1.newFixedThreadPool(int nThreads)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
创建固定容量大小的缓冲池;
corePoolSize=maximumPoolSize,阻塞队列使用LinkedBlockingQueue,大小为整数最大值;
新任务提交时,线程池中有空闲线程则会立即执行,如果没有,则会暂存到阻塞队列。
使用无界的LinkedBlockingQueue来存放执行的任务。当提交频繁时,可能会耗尽系统资源。
在线程池空闲时,也不会释放工作线程,还会占用一定的系统资源,需要shutdown。
2.newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
只有一个线程的线程池,阻塞队列使用的是LinkedBlockingQueue;
若有多余的任务提交到线程池中,会被暂存到阻塞队列,待空闲时再去执行。按照先入先出的顺序执行任务。
3.newCachedThreadPool()
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
缓存线程池,缓存线程默认存活60秒。corePoolSize大小为0,核心池最大为Integer.MAX_VALUE,
阻塞队列使用SynchronousQueue。是一个直接提交的阻塞队列,
会迫使线程池增加新的线程去执行新的任务,当提交频繁处理不快时,有资源损耗风险,
没有任务执行时,当线程的空闲时间超过keepAliveTime(60秒),则工作线程将会终止被回收;
4.newScheduledThreadPool(int var0)
public static ScheduledExecutorService newScheduledThreadPool(int var0) {
return new ScheduledThreadPoolExecutor(var0);
}
定时线程池,该线程池可用于周期性地去执行任务,通常用于周期性的同步数据。