盘一盘 Python 特别篇 16 - Cross Table

本文含 2573 字,16 图表截屏
建议阅读 14 分钟
我的 Python 进阶版课程马上要出了
星期五发推文,敬请关注
本文是 Python 系列的特别篇的第十六篇
特别篇 1 - PyEcharts TreeMap
特别篇 2 - 面向对象编程
特别篇 3 - 两大利「器」
特别篇 4 - 装饰器
特别篇 5 - Sklearn 0.22
特别篇 6 - Jupyter Notebook
特别篇 7 - 格式化字符串
特别篇 8 - 正则表达式
特别篇 9 - 正则表达式实战
特别篇 10 - 错误类型
特别篇 11 - 异常处理
特别篇 12 - Collection
特别篇 13 - Matplotlib Animation
特别篇 14 - All 和 Any
特别篇 15 - 透视表 Pivot Table
特别篇 16 - 交叉表 Cross Table
交叉表 (cross table) 是透视表的特例,其默认的整合函数是计算个数或频率。
初探数据
我们拿一个贷款数据举例,首先载入数据,打印出首三行尾两行。
loan = pd.read_csv('Loan Data.csv')
loan.head(3).append(loan.tail(2))

用 info()函数查阅数据信息,有 32,581 条数据,11 条特征和 1 个标签 (loan_status 那列,0 代表未违约,1 代表违约。)
loan.info()
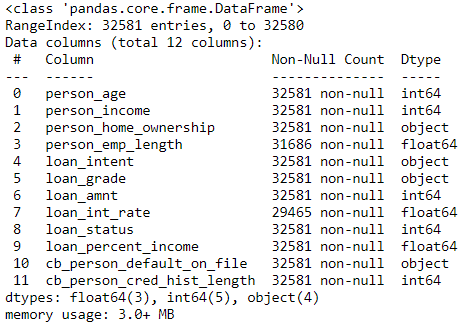
在机器学习中,我们通常用其他 11 个特征 (或特征转换) 建立模型来预测贷款的良莠。在选择特征前,用交叉表可以做单变量分析,即看看每个特征下的不同特征值对应的“违约”和“不违约”的贷款个数或比例。
按贷款种类统计个数
用交叉表来统计 person_home_ownership 列每个类别 (MORTGAGE, OTHER, OWN, RENT) 下面贷款状态的个数,0 代表未违约,1 代表违约。
pd.crosstab( index=loan['person_home_ownership'],
columns=loan['loan_status'] )
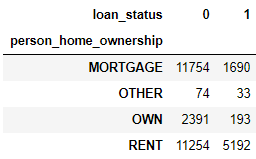
从上表可以一下看出 RENT 下面的违约贷款比例很高。
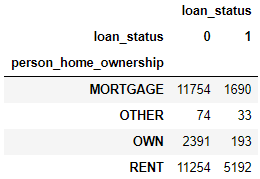
用 pivot_table() 函数可以等价实现上面用 crosstab() 的产出结果。由于是统计个数,那么整合函数用的是 len。
pd.pivot_table( loan, index='person_home_ownership',
columns='loan_status',
aggfunc={'loan_status':len},
fill_value=0 )
按贷款评级统计个数
用交叉表来统计 loan_grade 列每个类别 (从 A 到 G) 下面贷款状态的个数,显示总数 (设置 margins=True) 并起名为 Total (设置 margins_name='Total')。
pd.crosstab( index=loan['loan_grade'],
columns=loan['loan_status'],
margins=True,
margins_name='Total' )

评级越高,违约贷款比例越低,这不正是评级的含义么。
按贷款种类计算利率均值
除了统计个数,交叉表也能做透视表做的事情。下列是在不同的 person_home_ownership 和 loan_status 下计算贷款利率的均值。
pd.crosstab( index=loan['person_home_ownership'],
columns=loan['loan_status'],
values=loan['loan_int_rate'],
aggfunc='mean').round(2)
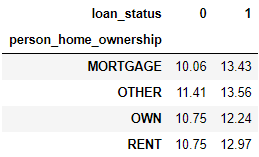
可以看出,违约贷款的利率都比没有违约贷款的利率高。
没有 fill_value 参数
在 crosstab() 函数中没有 fill_value 参数,如果结果有 NaN 值,只能紧接一个 .fillna() 函数。
pd.crosstab( index=loan['person_home_ownership'],
columns=loan['loan_grade'],
values=loan['loan_int_rate'],
aggfunc='mean')
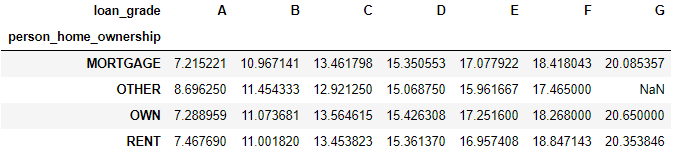
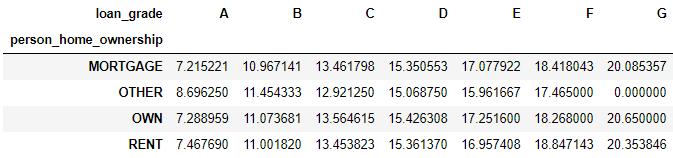
在 OTHER 类下没有评级为 G 的贷款,因此显示 NaN。由于 crosstab() 函数返回对象就是一个数据帧 (DataFrame),那么可以用其下的 fillna() 方法将 NaN 用其他值代替,比如下例用 0 值代替 NaN。
pd.crosstab( index=loan['person_home_ownership'],
columns=loan['loan_grade'],
values=loan['loan_int_rate'],
aggfunc='mean').fillna(0)
按贷款目的统计百分比
上面已经展示交叉表的计数功能,如果最终结果想用频率展示的话,可以设置 normalize 参数,其中
normalized =True或者all,在所有元素上做标准化normalized = columns,在列上做标准化normalized = index,在行上做标准化
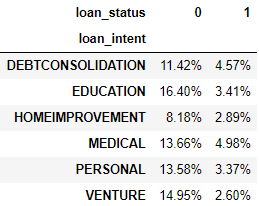
下面在不同的 loan_intent 和 loan_status 下统计贷款状态的百分比。
设置 normalize=True 按元素计算百分比,即所有元素下的百分比加起来等于 100%。
pd.crosstab( index=loan['loan_intent'],
columns=loan['loan_status'],
normalize=True ).style.format("{:.2%}")
设置 normalize=columns 按列计算百分比,即在每列的百分比加起来等于 100%。
pd.crosstab( index=loan['loan_intent'],
columns=loan['loan_status'],
normalize='columns' ).style.format("{:.2%}")
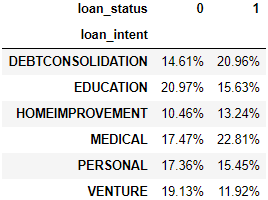
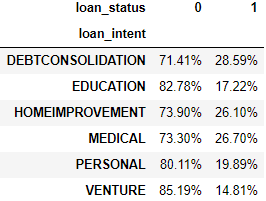
设置 normalize=index 按行计算百分比,即在每行的百分比加起来等于 100%。
pd.crosstab( index=loan['loan_intent'],
columns=loan['loan_status'],
normalize='index' ).style.format("{:.2%}")
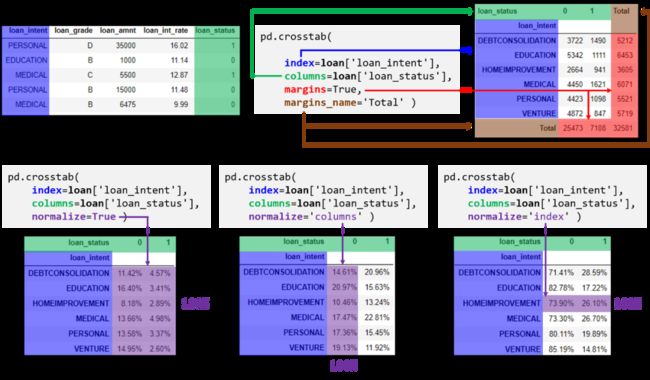
总结,一图胜千言!下图可视化 crosstab() 函数的用法。
Stay Tuned!


现在京东上有活动到 6 月 18 日截止,扫以下二维码去买书满 100 返 50。
