前向传播和反向传播(以简单神经网络为例)
在神经网络模型中包括前向传播和反向传播
那么究竟什么是前向传播,什么是反向传播呢
前向传播:说的通俗一点就是从输入到得到损失值的过程,当然不仅仅是这么简单,中间还经过了一些处理,那么这些处理包括什么呢:
1:从输入层开始:假设是一个形状是(2,3)
2:经过权重参数(w(3,取决你的中间隐层1的形状)偏置参数(b)的处理后再经过一个激活函数处理得到中间隐层1,
3:同理再经过第二个参数处理和激活函数得到中间隐层2
4:最后在通过输出处理得到输出(也就是样本值也成为预测值)
5:通过定义一个损失函数得到一个损失值
1)定义损失函数的方式有很多,不同的模型对应的损失函数的方法不同
2)对于线性回归模型(包括多元线性回归)通用的方法就是最小二乘法
3)对于分类性问题,一般采用交叉熵的方式
这个过程就是前向传播的过程;
至于反向传播,说的通俗一点就是通过损失函数的值不断调参的过程;
反向传播的起点就是从loss函数开始的;
通过一个优化器和指定学习率,然后通过最小化损失值来求出最佳的参数
这个就是反向传播的过程了,当然其中一些具体的步骤:包括链式法则,门单元的处理方式(包括,加法,乘法,max等)的处理方式:
其实说白了,反向传播的过程就是一个求偏导数(其实就是求导,就是除了未知量,其他都是常数)的过程,如果有激活函数
激活函数也要求导;
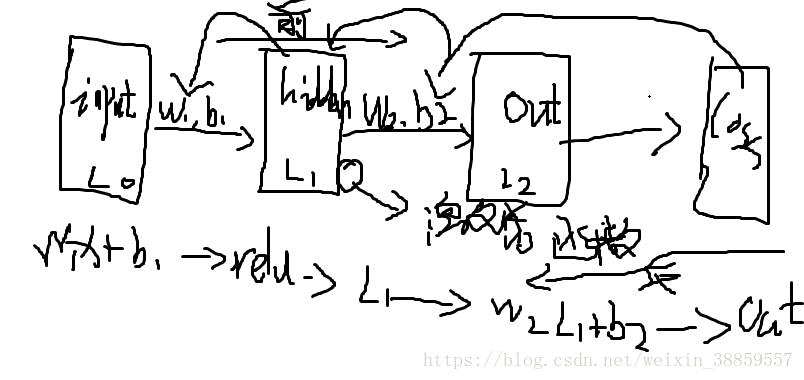
图有点丑,将就看吧;
在像tensorflow的框架中,反向传播过程是特别简单的,自己都不需要写,框架已经帮我们封装好了,但是在没有框架的情况下呢;举一个简单的例子看图:
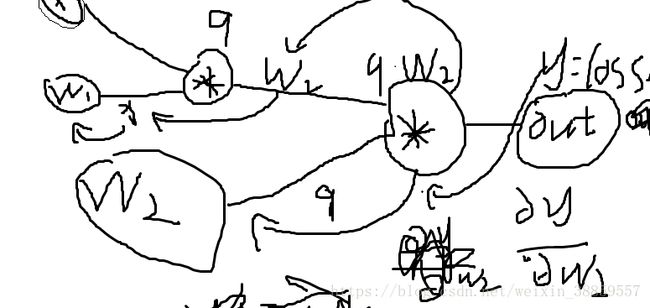
注意上面的对w2求偏导数的y是out值,不是loss值,但是loss值是可以和out值相乘后进入反向传播的过程的;
这是乘法的例子:对于乘法门单元,就相当于互换,当是加法时是均值分配,当是max时给最大的
本人拙见,有错误请斧正!