使用ELK搭建统一日志分析平台
使用ELK(Logstash+ElasticSearch+Kibana)搭建统一日志分析平台
一、背景分析
为了应付我们日益复杂的业务需求,系统设计趋近模块化,每个模块各司其职由不同人员开发,打印的日志格式也大都不一样,有些面向用户的接口模块还可能会多台一起做负载,这样就给运维带来了很大的工作量,定位一个问题需要四处翻日志,现有ELK这三个开源的部件(从日志的收集,统一存储,多维度展现等多个方面)为我们提供了一整套的日志分析解决方案。
二、关系流程图
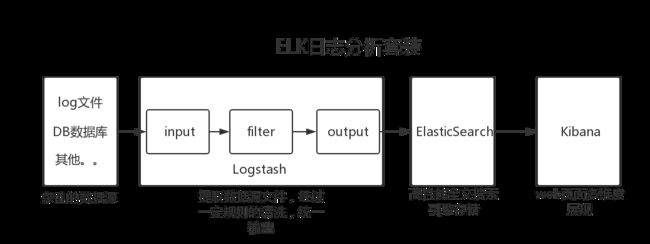
三、工具准备
工具当然要从官网获取!地址如下:https://www.elastic.co/cn/products
附上我自己的版本列表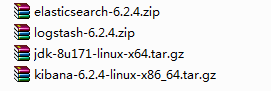 注意:jdk需要1.8版本
注意:jdk需要1.8版本
四、ElasticSearch部署
解压安装包:
[root@wuhan-216 local]# unzip elasticsearch-6.2.4.zip修改配置文件
[root@wuhan-216 elasticsearch-6.2.4]# vim config/elasticsearch.yml这里只列出我简单修改的单机配置
#es名称
cluster.name: my-elasticsearch
#节点名称
node.name: node-1
#索引数据存放地址
path.data: /path/to/data
#es日志存放地址
path.logs: /path/to/logs
#绑定的ip(一般为本机ip)配置这个才能让别人访问到
network.host: *.*.*.*
#绑定的端口
http.port: 9200
#部分操作系统启动报错,增加如下设置
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
由于es的安全策略,不允许从root启动,这里我们要创建一个用户
#添加用户
groupadd
useradd es -g es
passwd es
#给该用户分配操作权限
chown -R es:es elasticsearch-6.2.4
#给该用户分配日志和数据操作的权限
chown -R es:es path
启动服务
[root@wuhan-216 bin]# ./elasticsearch
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/elasticsearch/tools/launchers/JavaVersionChecker : Unsupported major.minor version 51.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClassCond(ClassLoader.java:632)
at java.lang.ClassLoader.defineClass(ClassLoader.java:616)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:141)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:283)
at java.net.URLClassLoader.access$000(URLClassLoader.java:58)
at java.net.URLClassLoader$1.run(URLClassLoader.java:197)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:248)
Could not find the main class: org.elasticsearch.tools.launchers.JavaVersionChecker. Program will exit. at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClassCond(ClassLoader.java:632)
at java.lang.ClassLoader.defineClass(ClassLoader.java:616)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:141)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:283)
at java.net.URLClassLoader.access$000(URLClassLoader.java:58)
at java.net.URLClassLoader$1.run(URLClassLoader.java:197)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:248)
Could not find the main class: org.elasticsearch.tools.launchers.JavaVersionChecker. Program will exit.看到如下错误提示:有经验的同学应该对此不陌生,报这个错一般都是jdk不匹配
查看系统jdk版本:
[root@wuhan-216 bin]# java -version
java version "1.6.0_24"
Java(TM) SE Runtime Environment (build 1.6.0_24-b07)
Java HotSpot(TM) 64-Bit Server VM (build 19.1-b02, mixed mode)可以看到目前系统是1.6的jdk,而我们需要1.8的环境,改了系统环境又会对其他的项目产生影响,这个时候我们唯一能做的就是指定elasticsearch的jdk(不改动系统jdk)
安装jdk1.8
[root@wuhan-216 java]# tar -zxvf jdk-8u171-linux-x64.tar.gz![]()
vim bin/elasticsearch 修改es指定的jdk
# 添加以下代码
export JAVA_HOME=/usr/java/jdk1.8.0_171/
export PATH=$JAVA_HOME/bin:$PATH
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/usr/java/jdk1.8.0_171//bin/java"
else
JAVA=`which java`
fi再次启动,总会喜闻乐见的遇到这么几个错误
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [10000] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65536] is too low, increase to at least [262144]
[3]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk这里收集了网上的一些解决办法(亲测有效)
1、max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
2、max number of threads [1024] for user [lishang] likely too low, increase to at least [2048]
解决方法:切换到root用户,编辑limits.conf 添加类似如下内容
vim /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
注意,要退出重新登陆才能生效。3、max number of threads [1024] for user [lish] likely too low, increase to at least [2048]
解决:切换到root用户,进入limits.d目录下修改配置文件。
vim /etc/security/limits.d/90-nproc.conf
修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 20484、max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决:切换到root用户修改配置sysctl.conf
vim /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p5、system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决:
在elasticsearch.yml中配置
bootstrap.memory_lock: false
bootstrap.system_call_filter: false后台启动
[root@wuhan-216 bin]# ./elasticsearch &
---------
--------
-----
[2018-06-13T11:33:28,150][INFO ][o.e.n.Node ] [2mE2yhD] started
启动成功浏览器访问该ip的9200端口
 成功
成功
五、Logstash部署
解压安装包:
[root@dhm216_2 java]# unzip logstash-6.2.4.zip进入bin目录启动
[root@wuhan-216 bin]# ./logstash
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/logstash/Logstash : Unsupported major.minor version 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClassCond(ClassLoader.java:632)
at java.lang.ClassLoader.defineClass(ClassLoader.java:616)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:141)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:283)
at java.net.URLClassLoader.access$000(URLClassLoader.java:58)
at java.net.URLClassLoader$1.run(URLClassLoader.java:197)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
at java.lang.ClassLoader.loadClass(ClassLoader.java:248)
Could not find the main class: org.logstash.Logstash. Program will exit.给logstash指定1.8的jdk
logstash启动过程会引入lib文件bin/logstash.lib.sh,编辑该文件
setup_java() {
# set the path to java into JAVACMD which will be picked up by JRuby to launch itself
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVACMD="$JAVA_HOME/bin/java"
else
set +e
JAVACMD=`which java`
set -e
fi可以看到这里引入了系统环境变量$JAVA_HOME,所以这里我们只需指定该变量的路径即可,在文件的行首添加该变量的引用
export JAVA_HOME="/usr/java/jdk1.8.0_171"再次启动
[root@wuhan-216 bin]# ./logstash
Sending Logstash's logs to /usr/local/logstash-6.2.4/logs which is now configured via log4j2.properties
[2018-06-13T10:12:10,168][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/usr/local/logstash-6.2.4/modules/fb_apache/configuration"}
[2018-06-13T10:12:10,202][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/usr/local/logstash-6.2.4/modules/netflow/configuration"}
[2018-06-13T10:12:10,364][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/usr/local/logstash-6.2.4/data/queue"}
[2018-06-13T10:12:10,372][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/local/logstash-6.2.4/data/dead_letter_queue"}
ERROR: Pipelines YAML file is empty. Location: /usr/local/logstash-6.2.4/config/pipelines.yml
usage:
bin/logstash -f CONFIG_PATH [-t] [-r] [] [-w COUNT] [-l LOG]
bin/logstash --modules MODULE_NAME [-M "MODULE_NAME.var.PLUGIN_TYPE.PLUGIN_NAME.VARIABLE_NAME=VALUE"] [-t] [-w COUNT] [-l LOG]
bin/logstash -e CONFIG_STR [-t] [--log.level fatal|error|warn|info|debug|trace] [-w COUNT] [-l LOG]
bin/logstash -i SHELL [--log.level fatal|error|warn|info|debug|trace]
bin/logstash -V [--log.level fatal|error|warn|info|debug|trace]
bin/logstash --help
[2018-06-13T10:12:11,250][ERROR][org.logstash.Logstash ] java.lang.IllegalStateException: org.jruby.exceptions.RaiseException: (Syste出现这样的提示就表示你的环境已经OK只是需要指定输入输出的规则
在这里个人喜欢准备2个配置文件,1个用于调试filter过滤规则(控制台输入输出),1个正式使用(读取log文件输出到ES)
在这里把两个文件都贴出来
1.test.conf,用于调试filter过滤规则(控制台输入输出)
input { stdin { } }
output { stdout {} }指定文件启动:
[root@wuhan-216 bin]# ./logstash -f test.conf
Sending Logstash's logs to /usr/local/ELK/logstash-6.2.4/logs which is now configured via log4j2.properties
[2018-06-13T14:36:15,387][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/usr/local/ELK/logstash-6.2.4/modules/netflow/configuration"}
[2018-06-13T14:36:15,415][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/usr/local/ELK/logstash-6.2.4/modules/fb_apache/configuration"}
[2018-06-13T14:36:16,152][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2018-06-13T14:36:16,207][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"39402e25-e423-4b73-8195-807dca23679f", :path=>"/usr/local/ELK/logstash-6.2.4/data/uuid"}
[2018-06-13T14:36:16,979][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.4"}
[2018-06-13T14:36:17,546][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-06-13T14:36:21,061][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2018-06-13T14:36:21,423][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#"}
The stdin plugin is now waiting for input:
[2018-06-13T14:36:21,584][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
可以看到这里是等待控制台输入,我们随便输入点内容:hello,它自动给我们解析出了版本号,时间戳,主机,信息等字段
hello
{
"@version" => "1",
"@timestamp" => 2018-06-13T06:38:06.223Z,
"host" => "wuhan-216.1",
"message" => "hello"
}这里以我需要解析的日志格式为例,系统打印的日志是这样的:
/stbntinfo?client=00060460540&areaCode=100&netWorkId=11&transactionID=0000ca0a69a4"所以,在test.conf配置文件中增加过滤条件filter
input { stdin { } }
filter {
grok {
match => {
"message" => "%{WORD:request}\?client=%{WORD:client}&areaCode=%{NUMBER:area}&netWorkId=%{NUMBER:net}"
}
remove_field => ["message"]
}
}
output { stdout {} }重新启动:再输入hello,可以看到,因为我们配置了filter过滤规则,遇到与上文规则不匹配的内容就会解析失败
hello
{
"host" => "wuhan-216.1",
"tags" => [
[0] "_grokparsefailure"
],
"@timestamp" => 2018-06-13T06:50:49.706Z,
"@version" => "1",
"message" => "hello"
}
再次输入我们的日志格式,可以看到logstash按照filter中定义的规则吧日志中的每个字段都给解析出来并输出到控制台了
/stbntinfo?client=00060460540&areaCode=100&netWorkId=11&transactionID=0000ca0a69a4
{
"@version" => "1",
"area" => "100",
"net" => "11",
"host" => "wuhan-216.1",
"@timestamp" => 2018-06-13T06:53:08.459Z,
"request" => "stbntinfo",
"client" => "00060460540"
}到此为止,我们调试好过滤规则了,现在我们正式从日志文件中读取记录并输出到es存储,贴出我的配置文件
input {
file {
path => ["/000000000000000000app-info.log"]
type => "system"
start_position => "beginning"
#表示多就去path路径下查看是够有新的文件产生。默认是15秒检查一次。
discover_interval => 15
close_older => 3600
#已经监听的文件,若超过这个时间内没有更新,就关闭监听该文件的句柄,默认一天
ignore_older => 86400
#logstash 每隔多 久检查一次被监听文件状态( 是否有更新) , 默认是 1 秒。
stat_interval => 1
}
}
filter {
grok {
match => {
"message" => "%{WORD:request}\?client=%{WORD:client}&areaCode=%{NUMBER:area}&netWorkId=%{NUMBER:net}"
}
remove_field => ["message"]
#存储的结果中删除message属性
}
}
output {
if "_grokparsefailure" not in [tags]{
#根据规则转化成功的日志才输出到es
elasticsearch {
# 导出到es,最常用的插件
codec => "json"
hosts => ["00.000.0.00:9200"]
index => "%{request}"
#根据请求接口名动态生成动态
document_type => "test"
#flush_size => 500
#idle_flush_time => 1
}
#这里除了es,还可以把转换好的内容输出到其他路径
}else{
#转换失败的日志就不做处理
}
}
再次启动加"&"表示后台启动
./logstash -f es.conf &在es中查询该索引记录:可见 我们配置的工具成功的吧日志文件中不规则的记录解析进我们的es里了。

六、Kibana展现
解压压缩包
[root@wuhan-216 ELK]# tar -zxvf kibana-6.2.4-linux-x86_64.tar.gz编辑配置文件
vim config/kibana.yml这里仅仅列出比较关键的配置项
server.port: 5601
#端口
server.host: "00.0.000.0"
#指定本机ip让外部能访问
elasticsearch.url: "http://00.0.000.0:9200"
#指定ES数据源访问方式,在浏览器中输入:ip:5601 当显示出如下画面,就代表你已经启动成功了
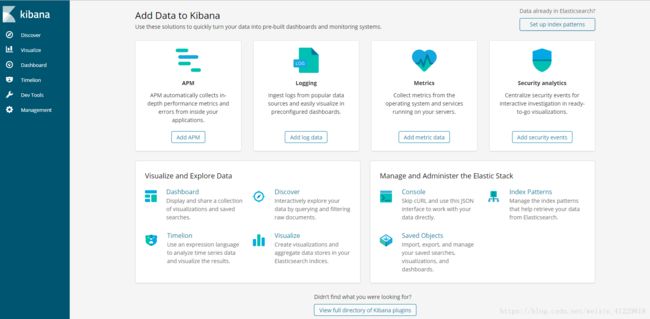
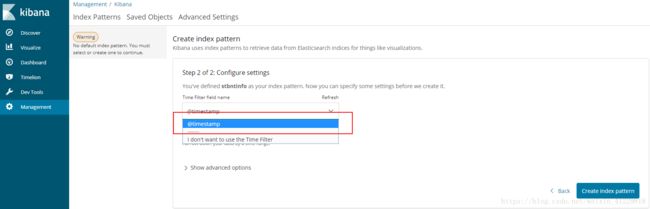
这里需要配置展现的默认索引,选择我们刚刚录入的记录的索引名

选择系统默认帮我们生成的时间戳(当然你也可以在logstash中自己生成时间戳)
创建完毕,接下来的各种查询方式就不一一介绍了,让我们一起感受kibana的强大吧