使用Python自动更新不对称Excel表格
大家好,又到了Python办公自动化专题。
在之前我们详细讲解过如何使用Python自动更新Excel表格并调整样式,在上次的自动化案例中要求两个或多个Excel表格数据要匹配/对称才能够自动更新,今天我们再次来解决在数据不对称的情况下如何自动更新表格,这是更常见的情况,也是我遇到的一个具体需求。
需求分析
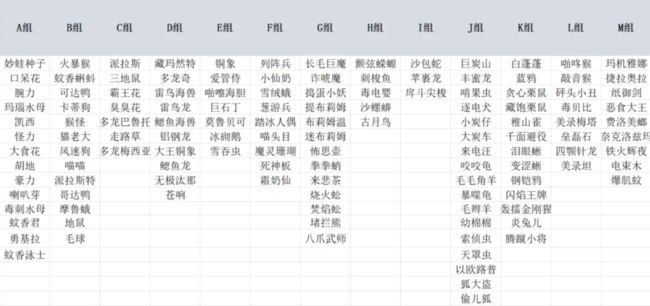
现在我们有类似如下一份记录了口袋妖怪名字的分组名单:(未全部展示,实际有A-U组+1个"未分组")
现在有一份更新的名单(仅含名字)
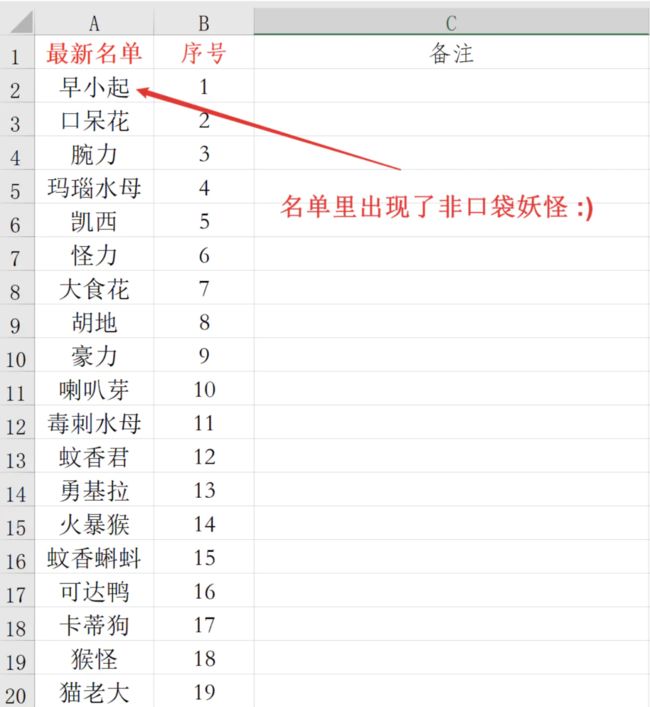
需要根据这份新名单对原来的总表进行更新,即对新名单中的名字按照总表的分组进行更新,剔除不在新名单中的名字,并将新名单中新出现的名字划分到“未分组”中,如上图中的“早小起”
这位读者的需求是一个需要长期重复的任务,每隔一段时间就会拿到一个新名单,需要对总名单进行调整。如果用Excel操作,可能需要反复查找新名单的名字在哪个分组,如果不存在则手动添加到“未分组”,存在则做标记。最后把未做标记的名字删除再删除空隙即可,整个过程十分繁琐,而且若总名单有千万个名字则工作量非常大。因此该工作很适合用Python辅助自动化
Python实现
第一步是导入需要的库并把路径设置好,我还是习惯用函数定位到桌面上利于复用
import os
import pandas as pd
import numpy as np
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + '\\data\\'接着读取两份文件
df1 = pd.read_excel(path + '总名单.xlsx',encoding = 'utf-8',sheet_name = 0,skiprows=1)
df2 = df1.iloc[:,1:23]
df3 = pd.read_excel(path + '新名单.xlsx',encoding = 'utf-8',sheet_name = 0)

接下来是根据新名单中出现的名字找各自在总表中的分组,思路是用np.where,如下所示
np.where(df2 == '死神板')
# (array([7], dtype=int64), array([5], dtype=int64))返回元组,行列信息都在里面,那么用如下命令即可获得口袋妖怪“死神板”所在的分组
col = np.where(df2 == '死神板')[1][0]
df2.columns[col]
# 'F组'有了个思路就可以写个函数,并用apply逐个运用到新名单里的名字上
这里要注意,新名单中的名字在总名单中可能没有,因此需要判断后再取最里面一层数字,否则会出错
def find(x):
results = np.where(df2 == x)[1]
try:
return df2.columns[results[0]]
except:
return '未分组'
df3['备注'] = df3['最新名单'].apply(find)
 接下来这个操作就是根据分组把上面的数据框“劈开”
接下来这个操作就是根据分组把上面的数据框“劈开”
results_lst = []
for index,i in enumerate(df2.columns):
results = df3.iloc[np.where(df3['备注']==i)[0].tolist(),0]
# 重置索引很重要,为什么重要往下看
results = results.reset_index(drop=True)
results_lst.append(results)
results_lst
可以看到,结果是一个Series列表,这不正好是pd.concat的对象嘛,由于接下来要横向合并,因此每个Series需要重置索引保证都是从0开始
df_final = pd.concat(results_lst,axis=1)
# 记得把列名还原
df_final.columns = df2.columns
整个需求就大致完成了 (两个非口袋妖怪的生物也被识别出来了)
df_final.to_excel(f'{path}整理后表格.xlsx',
encoding='gbk', # 编码不一定是gbk
index=False,
header=True)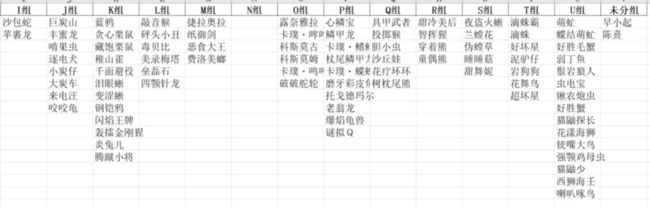
最后就是保存并将结果以excel形式输出,如上图所示,我们就使用Python成功完成了一次Excel非对称表格的自动更新,接下来应该使用openpyxl进行样式的修改,而这一部分在之前的文章中有很详细的讲解,本文就不再展开。