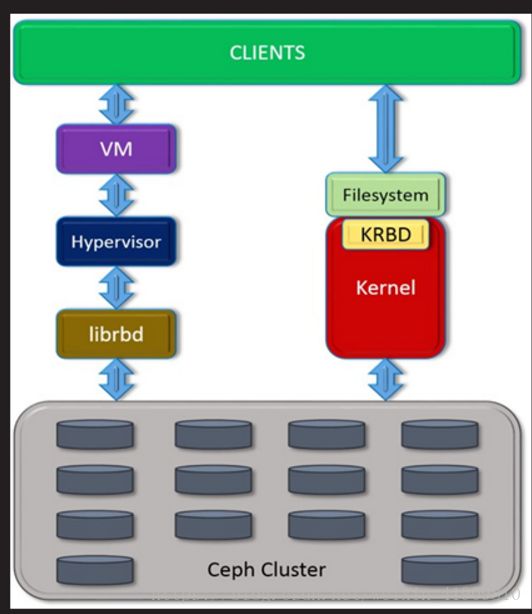
Ceph概述 部署Ceph集群 Ceph块存储(克隆,快照) 块存储应用案例 分布式文件系统 对象存储
数据记录数据信息的称为元数据(例如:-rw-r–r–. 1 root root 1931 1月 30 2018 initial-setup-ks.cfg)
删除创建的ceph
ceph-deloy uninstall node1 node2 node3 删除创建的ceph集群
rm -rf /var/lib/ceph/*
rm -rf /var/run/ceph/*
rm -rf /var/log/ceph/*
rm -rf /etc/ceph/ceph.conf
先来学习ceph的一些知识










NSD CLUSTER DAY04
案例1:实验环境
案例2:部署ceph集群
案例3:创建Ceph块存储
1 案例1:实验环境
1.1 问题
准备四台KVM虚拟机,其三台作为存储集群节点,一台安装为客户端,实现如下功能:
创建1台客户端虚拟机
创建3台存储集群虚拟机
配置主机名、IP地址、YUM源
修改所有主机的主机名
配置无密码SSH连接
配置NTP时间同步
创建虚拟机磁盘
1.2 方案
使用4台虚拟机,1台客户端、3台存储集群服务器,拓扑结构如图-1所示。
4.
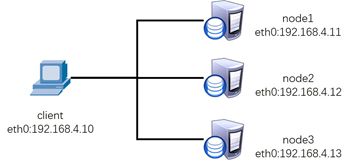
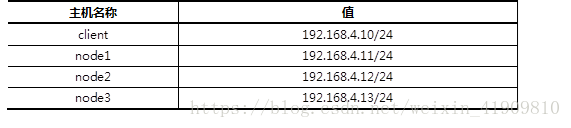
所有主机的主机名及对应的IP地址如表-1所示。
1.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:安装前准备
1)物理机为所有节点配置yum源,注意所有的虚拟主机均需要挂载安装光盘。
[root@root9pc01 ~]# yum -y install vsftpd
[root@root9pc01 ~]# mkdir /var/ftp/ceph
[root@root9pc01 ~]# mount -o loop \
rhcs2.0-rhosp9-20161113-x86_64.iso /var/ftp/ceph
[root@root9pc01 ~]# systemctl restart vsftpd
2)修改所有节点yum配置(以node1为例)
[root@node1 ~]# cat /etc/yum.repos.d/ceph.repo
[mon]
name=mon
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/MON
gpgcheck=0
[osd]
name=osd
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/OSD
gpgcheck=0
[tools]
name=tools
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/Tools
gpgcheck=0
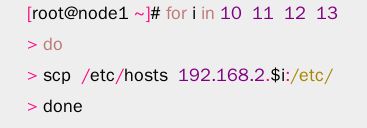
3)修改/etc/hosts并同步到所有主机。
[root@node1 ~]# cat /etc/hosts
… …
192.168.4.10 client
192.168.4.11 node1
192.168.4.12 node2
192.168.4.13 node3
3)配置无密码连接。
[root@node1 ~]# ssh-keygen -f /root/.ssh/id_rsa -N ”

步骤二:配置NTP时间同步
1)创建NTP服务器。
[root@client ~]# yum -y install chrony
[root@client ~]# cat /etc/chrony.conf
server 0.centos.pool.ntp.org iburst
allow 192.168.4.0/24
local stratum 10
[root@client ~]# systemctl restart chronyd
2)其他所有节点与NTP服务器同步时间(以node1为例)。
[root@node1 ~]# cat /etc/chrony.conf
server 192.168.4.10 iburst
[root@node1 ~]# systemctl restart chronyd
步骤三:准备存储磁盘
1)物理机上为每个虚拟机准备3块磁盘。(可以使用命令,也可以使用图形直接添加)
[root@root9pc01 ~]# cd /var/lib/libvirt/images
[root@root9pc01 ~]# qemu-img create -f qcow2 node1-vdb.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node1-vdc.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node1-vdd.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node2-vdb.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node2-vdc.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node2-vdd.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node3-vdb.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node3-vdc.vol 10G
[root@root9pc01 ~]# qemu-img create -f qcow2 node3-vdd.vol 10G
2)使用virt-manager为虚拟机添加磁盘。
[root@root9pc01 ~]# virt-manager
2 案例2:部署ceph集群
2.1 问题
沿用练习一,部署Ceph集群服务器,实现以下目标:
安装部署工具ceph-deploy
创建ceph集群
准备日志磁盘分区
创建OSD存储空间
查看ceph状态,验证
2.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:部署软件
1)在node1安装部署工具,学习工具的语法格式。
[root@node1 ~]# yum -y install ceph-deploy
[root@node1 ~]# ceph-deploy –help
2)创建目录
[root@node1 ~]# mkdir ceph-cluster
[root@node1 ~]# cd ceph-cluster/
步骤二:部署Ceph集群
1)创建Ceph集群配置。
[root@node1 ceph-cluster]# ceph-deploy new node1 node2 node3
2)给所有节点安装软件包。
[root@node1 ceph-cluster]# ceph-deploy install node1 node2 node3
3)初始化所有节点的mon服务(主机名解析必须对)
[root@node1 ceph-cluster]# ceph-deploy mon create-initial
步骤三:创建OSD
1)准备磁盘分区 (node1 node2 node3)
[root@node1 ~]# parted /dev/vdb mklabel gpt
[root@node1 ~]# parted /dev/vdb mkpart primary 1M 50%
[root@node1 ~]# parted /dev/vdb mkpart primary 50% 100%
[root@node1 ~]# chown ceph.ceph /dev/vdb1
[root@node1 ~]# chown ceph.ceph /dev/vdb2
//这两个分区用来做存储服务器的日志journal盘
由于从新开机后,/dev/vdb1 和/dev/vdb2 的所有者和所有组会变回root 所以要进行永久化。
1 cat /etc/udev/rules.d/50-ceph.rules
ACTION==”add”, KERNEL==”vdb[12]”, OWNER=”ceph”, GROUP=”ceph”
然后更新udev文件系统管理
udevadm trigger
2 vim /etc/rc.local
chown ceph:ceph /dev/vdb1
chown ceph:ceph /dev/vdb2
systemctl restart ceph*.service ceph*.target
wq:
chmod +x /etc/rc.d/rc.local
2)初始化清空磁盘数据(仅node1操作即可)
[root@node1 ~]# ceph-deploy disk zap node1:vdc node1:vdd
[root@node1 ~]# ceph-deploy disk zap node2:vdc node2:vdd
[root@node1 ~]# ceph-deploy disk zap node3:vdc node3:vdd
3)创建OSD存储空间(仅node1操作即可)
[root@node1 ~]# ceph-deploy osd create node1:vdc:/dev/vdb1 node1:vdd:/dev/vdb2
//创建osd存储设备,vdc为集群提供存储空间,vdb1提供JOURNAL日志,
//一个存储设备对应一个日志设备,日志需要SSD,不需要很大
[root@node1 ~]# ceph-deploy osd create node2:vdc:/dev/vdb1 node2:vdd:/dev/vdb2
[root@node1 ~]# ceph-deploy osd create node3:vdc:/dev/vdb1 node3:vdd:/dev/vdb2
步骤四:验证测试
1) 查看集群状态
[root@node1 ~]# ceph -s

查看集群中每个服务的运行状态 systemctl status ceph* 或 systemctl status ceph+tab键(两下)
3 案例3:创建Ceph块存储
3.1 问题
沿用练习一,使用Ceph集群的块存储功能,实现以下目标:
创建块存储镜像
客户端映射镜像
创建镜像快照
使用快照还原数据
使用快照克隆镜像
删除快照与镜像
3.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:创建镜像
1)查看存储池。
[root@node1 ~]# ceph osd lspools
0 rbd,
2)创建镜像、查看镜像
[root@node1 ~]# rbd create demo-image –image-feature layering –size 10G
[root@node1 ~]# rbd create rbd/image –image-feature layering –size 10G
[root@node1 ~]# rbd list
[root@node1 ~]# rbd info demo-image
rbd image ‘demo-image’:
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3aa2ae8944a
format: 2
features: layering
步骤二:动态调整
1)缩小容量
[root@node1 ~]# rbd resize –size 7G image –allow-shrink
[root@node1 ~]# rbd info image
2)扩容容量
[root@node1 ~]# rbd resize –size 15G image
[root@node1 ~]# rbd info image
步骤三:本机通过KRBD访问
1)集群内将镜像映射为本地磁盘
[root@node1 ~]# rbd map demo-image
/dev/rbd0
[root@node1 ~]# lsblk
… …
rbd0 251:0 0 10G 0 disk
[root@node1 ~]# mkfs.xfs /dev/rbd0
[root@node1 ~]# mount /dev/rbd0 /mnt
在远端客户端主机使用ceph集群存储数据
2)客户端通过KRBD访问
3 案例3:创建Ceph块存储
3.1 问题
沿用练习一,使用Ceph集群的块存储功能,实现以下目标:
创建块存储镜像
客户端映射镜像
创建镜像快照
使用快照还原数据
使用快照克隆镜像
删除快照与镜像
3.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:创建镜像
1)查看存储池。
[root@node1 ~]# ceph osd lspools
0 rbd,
2)创建镜像、查看镜像
[root@node1 ~]# rbd create demo-image –image-feature layering –size 10G
[root@node1 ~]# rbd create rbd/image –image-feature layering –size 10G
[root@node1 ~]# rbd list
[root@node1 ~]# rbd info demo-image
rbd image ‘demo-image’:
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3aa2ae8944a
format: 2
features: layering
步骤二:动态调整
1)缩小容量
[root@node1 ~]# rbd resize –size 7G image –allow-shrink
[root@node1 ~]# rbd info image
2)扩容容量
[root@node1 ~]# rbd resize –size 15G image
[root@node1 ~]# rbd info image
步骤三:通过KRBD访问
1)集群内将镜像映射为本地磁盘
[root@node1 ~]# rbd map demo-image
/dev/rbd0
[root@node1 ~]# lsblk
… …
rbd0 251:0 0 10G 0 disk
[root@node1 ~]# mkfs.xfs /dev/rbd0
[root@node1 ~]# mount /dev/rbd0 /mnt
2)客户端通过KRBD访问


客户端需要安装ceph-common软件包
拷贝配置文件(否则不知道集群在哪)
拷贝连接密钥(否则无连接权限)
[root@client ~]# yum -y install ceph-common
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring \
/etc/ceph/
[root@client ~]# rbd map image
[root@client ~]# lsblk
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd image - /dev/rbd0
3) 客户端格式化、挂载分区
[root@client ~]# mkfs.xfs /dev/rbd0
[root@client ~]# mount /dev/rbd0 /mnt/
[root@client ~]# echo “test” > /mnt/test.txt
步骤四:创建镜像快照(把执行快照时当前状态保存下来,用来恢复数据,)
镜像快照使用cow(写时复制)技术,对大数据快照速度会很快
cow:写时复制,说的是当对镜像里的数据进行删除写操作时,快照技术迅速的把该数据复制到快照里


1) 查看镜像快照
[root@node1 ~]# rbd snap ls image
2) 创建镜像快照
[root@node1 ~]# rbd snap create image –snap image-snap1
[root@node1 ~]# rbd snap ls image
SNAPID NAME SIZE
4 image-snap1 15360 MB
3) 删除客户端写入的测试文件
[root@client ~]# rm -rf /mnt/test.txt
4) 还原快照
[root@node1 ~]# rbd snap rollback image –snap image-snap1
客户端重新挂载分区
[root@client ~]# umount /mnt
[root@client ~]# mount /dev/rbd0 /mnt/
[root@client ~]# ls /mnt
步骤四:创建快照克隆
1)克隆快照
[root@node1 ~]# rbd snap protect image –snap image-snap1
[root@node1 ~]# rbd snap rm image –snap image-snap1 //会失败
[root@node1 ~]# rbd clone \
image –snap image-snap1 image-clone –image-feature layering
//使用image的快照image-snap1克隆一个新的image-clone镜像
2)查看克隆镜像与父镜像快照的关系
[root@node1 ~]# rbd info image-clone
rbd image ‘image-clone’:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
parent: rbd/image@image-snap1
克隆镜像很多数据都来自于快照链
如果希望克隆镜像可以独立工作,就需要将父快照中的数据,全部拷贝一份,但比较耗时!!!
[root@node1 ~]# rbd flatten image-clone
[root@node1 ~]# rbd info image-clone
rbd image ‘image-clone’:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
注意,父快照信息没了!
步骤四:其他操作
1) 客户端撤销磁盘映射
[root@client ~]# umount /mnt
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd image - /dev/rbd0
//语法格式:
[root@client ~]# rbd unmap /dev/rbd/{poolname}/{imagename}
[root@client ~]# rbd unmap /dev/rbd/rbd/image
2)删除快照与镜像
[root@node1 ~]# rbd snap rm image –snap image-snap
[root@node1 ~]# rbd list
[root@node1 ~]# rbd rm image客户端需要安装ceph-common软件包
拷贝配置文件(否则不知道集群在哪)
拷贝连接密钥(否则无连接权限)
[root@client ~]# yum -y install ceph-common
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/
[root@client ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring \
/etc/ceph/
[root@client ~]# rbd map image
[root@client ~]# lsblk
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd image - /dev/rbd0
3) 客户端格式化、挂载分区
[root@client ~]# mkfs.xfs /dev/rbd0
[root@client ~]# mount /dev/rbd0 /mnt/
[root@client ~]# echo “test” > /mnt/test.txt
步骤四:创建镜像快照
1) 查看镜像快照
[root@node1 ~]# rbd snap ls image
2) 创建镜像快照
[root@node1 ~]# rbd snap create image –snap image-snap1
[root@node1 ~]# rbd snap ls image
SNAPID NAME SIZE
4 image-snap1 15360 MB
3) 删除客户端写入的测试文件
[root@client ~]# rm -rf /mnt/test.txt
4) 还原快照
[root@node1 ~]# rbd snap rollback image –snap image-snap1
客户端重新挂载分区
[root@client ~]# umount /mnt
[root@client ~]# mount /dev/rbd0 /mnt/
[root@client ~]# ls /mnt
步骤四:创建快照克隆
1)克隆快照
[root@node1 ~]# rbd snap protect image –snap image-snap1
[root@node1 ~]# rbd snap rm image –snap image-snap1 //会失败
[root@node1 ~]# rbd clone \
image –snap image-snap1 image-clone –image-feature layering
//使用image的快照image-snap1克隆一个新的image-clone镜像
2)查看克隆镜像与父镜像快照的关系
[root@node1 ~]# rbd info image-clone
rbd image ‘image-clone’:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
parent: rbd/image@image-snap1
克隆镜像很多数据都来自于快照链
如果希望克隆镜像可以独立工作,就需要将父快照中的数据,全部拷贝一份,但比较耗时!!!
[root@node1 ~]# rbd flatten image-clone
[root@node1 ~]# rbd info image-clone
rbd image ‘image-clone’:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
注意,父快照信息没了!
步骤四:其他操作
1) 客户端撤销磁盘映射
[root@client ~]# umount /mnt
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd image - /dev/rbd0
//语法格式:
[root@client ~]# rbd unmap /dev/rbd/{poolname}/{imagename}
[root@client ~]# rbd unmap /dev/rbd/rbd/image
2)删除快照与镜像
[root@node1 ~]# rbd snap rm image –snap image-snap
[root@node1 ~]# rbd list
[root@node1 ~]# rbd rm image
NSD CLUSTER DAY05
案例1:块存储应用案例
案例2:Ceph文件系统
案例3:创建对象存储服务器
1 案例1:块存储应用案例
1.1 问题
延续Day04的实验内容,演示块存储在KVM虚拟化中的应用案例,实现以下功能:
Ceph创建块存储镜像
客户端安装部署ceph软件
客户端部署虚拟机
客户端创建secret
设置虚拟机配置文件,调用ceph存储
1.2 方案
使用Ceph存储创建镜像。
KVM虚拟机调用Ceph镜像作为虚拟机的磁盘。
1.3 步骤
实现此案例需要按照如下步骤进行。
1)创建磁盘镜像。
[root@node1 ~]# rbd create vm1-image –image-feature layering –size 10G
[root@node1 ~]# rbd create vm2-image –image-feature layering –size 10G
[root@node1 ~]# rbd list
[root@node1 ~]# rbd info vm1-image
[root@node1 ~]# qemu-img info rbd:rbd/vm1-image
image: rbd:rbd/vm1-image
file format: raw
virtual size: 10G (10737418240 bytes)
disk size: unavailable
2)Ceph认证账户。
Ceph默认开启用户认证,客户端需要账户才可以访问,
默认账户名称为client.admin,key是账户的密钥,
可以使用ceph auth添加新账户(案例我们使用默认账户)。
[root@node1 ~]# cat /etc/ceph/ceph.conf //配置文件
[global]
mon_initial_members = node1, node2, node3
mon_host = 192.168.2.10,192.168.2.20,192.168.2.30
auth_cluster_required = cephx //开启认证
auth_service_required = cephx //开启认证
auth_client_required = cephx //开启认证
[root@node1 ~]# cat /etc/ceph/ceph.client.admin.keyring //账户文件
[client.admin]
key = AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==
3)部署客户端环境。
注意:这里使用真实机当客户端!!!
客户端需要安装ceph-common软件包,拷贝配置文件(否则不知道集群在哪),
拷贝连接密钥(否则无连接权限)。
[root@room9pc01 ~]# yum -y install ceph-common
[root@room9pc01 ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/
[root@room9pc01 ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring \
/etc/ceph/
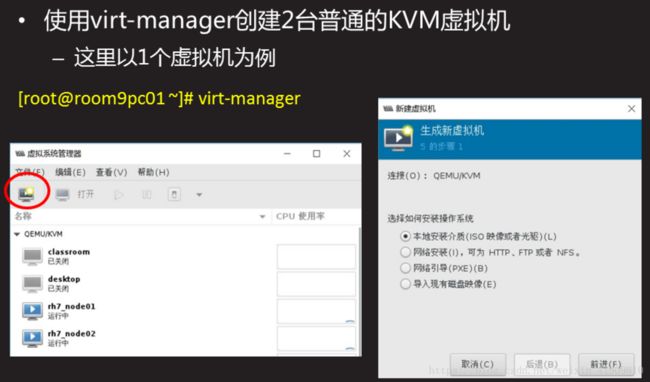
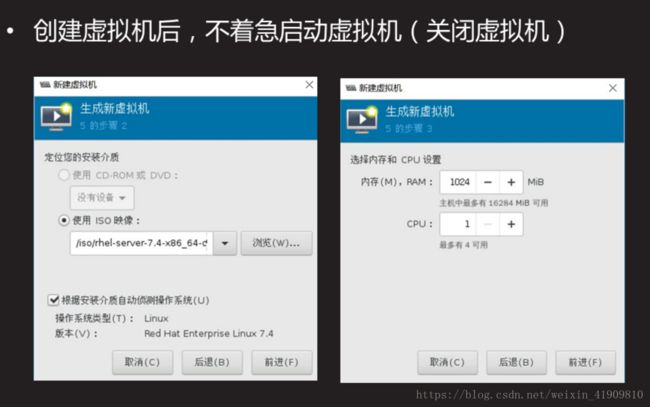
4)创建KVM虚拟机。
使用virt-manager创建2台普通的KVM虚拟机。
5)配置libvirt secret。





2 案例2:Ceph文件系统(需要例外一台元数据服务器)




2.1 问题
延续前面的实验,实现Ceph文件系统的功能。具体实现有以下功能:
部署MDSs节点
创建Ceph文件系统
客户端挂载文件系统
2.2 方案
添加一台虚拟机,部署MDS节点。
主机的主机名及对应的IP地址如表-1所示。

2.3 步骤
实现此案例需要按照如下步骤进行。
1)添加一台新的虚拟机,要求如下:
IP地址:192.168.4.14
主机名:node4
配置yum源(包括rhel、ceph的源)
与Client主机同步时间
node1允许无密码远程node4
2)部署元数据服务器
登陆node4,安装ceph-mds软件包
[root@node4 ~]# yum -y install ceph-mds
登陆node1部署节点操作
[root@node1 ~]# cd /root/ceph-cluster
//该目录,是最早部署ceph集群时,创建的目录
[root@node1 ceph-cluster]# ceph-deploy mds create node4
//给nod4拷贝配置文件,启动mds服务
同步配置文件和key
[root@node1 ceph-cluster]# ceph-deploy admin node4
3)创建存储池
[root@fdfs_storage1 FastDFS]# mkdir -pv /data/fastdfs
4)修改配置文件。
[root@node4 ~]# ceph osd pool create cephfs_data 128
//创建存储池,对应128个PG 存数据
[root@node4 ~]# ceph osd pool create cephfs_metadata 128
//创建存储池,对应128个PG 存元数据
5)创建Ceph文件系统
[root@node4 ~]# ceph mds stat //查看mds状态
e2:, 1 up:standby
[root@node4 ~]# ceph fs new myfs1 cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
//注意,现在medadata池,再写data池
//默认,只能创建1个文件系统,多余的会报错
[root@node4 ~]# ceph fs ls
name: myfs1, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@node4 ~]# ceph mds stat
e4: 1/1/1 up {0=node4=up:creating}
6)客户端挂载
redhat linux 内核支持ceph文件系统(不需要装软件)
[root@client ~]# mount -t ceph 192.168.4.11:6789:/ /mnt/cephfs/ \
-o name=admin,secret=AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==
//注意:文件系统类型为ceph
//192.168.4.11为MON节点的IP(不是MDS节点)
//admin是用户名,secret是密钥
//密钥可以在/etc/ceph/ceph.client.admin.keyring中找到
卸载 umount /mnt/cephfs
3 案例3:创建对象存储服务器


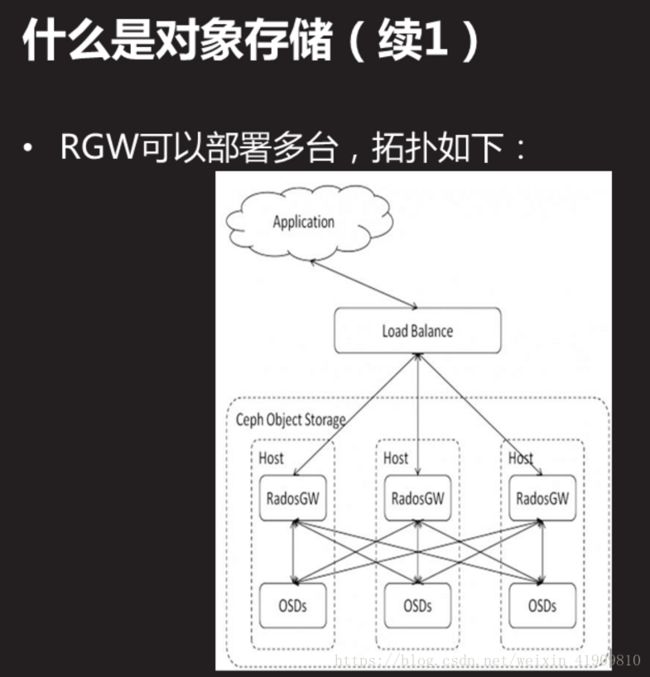
3.1 问题
延续前面的实验,实现Ceph对象存储的功能。具体实现有以下功能:
安装部署Rados Gateway
启动RGW服务
设置RGW的前端服务与端口
客户端测试
3.2 步骤
步骤一:部署对象存储服务器
1)准备实验环境,要求如下:
IP地址:192.168.4.15
主机名:node5
配置yum源(包括rhel、ceph的源)
与Client主机同步时间
node1允许无密码远程node5
修改node1的/etc/hosts,并同步到所有node主机
2)部署RGW软件包
[root@node1 ~]# ceph-deploy install –rgw node5
同步配置文件与密钥到node5
[root@node1 ~]# cd /root/ceph-cluster
[root@node1 ~]# ceph-deploy admin node5
3)新建网关实例
启动一个rgw服务
[root@node1 ~]# ceph-deploy rgw create node5
登陆node5验证服务是否启动
[root@node5 ~]# ps aux |grep radosgw
ceph 4109 0.2 1.4 2289196 14972 ? Ssl 22:53 0:00 /usr/bin/radosgw -f –cluster ceph –name client.rgw.node4 –setuser ceph –setgroup ceph
[root@node5 ~]# systemctl status ceph-radosgw@*
4)修改服务端口
登陆node5,RGW默认服务端口为7480,修改为8000或80更方便客户端记忆和使用
[root@node5 ~]# vim /etc/ceph/ceph.conf 注意此配置文件有先后顺序,所以下面的要追加到后面
[client.rgw.node5]
host = node5
rgw_frontends = “civetweb port=8000”
//node5为主机名
//civetweb是RGW内置的一个web服务
systemctl retart ceph* 重新启动
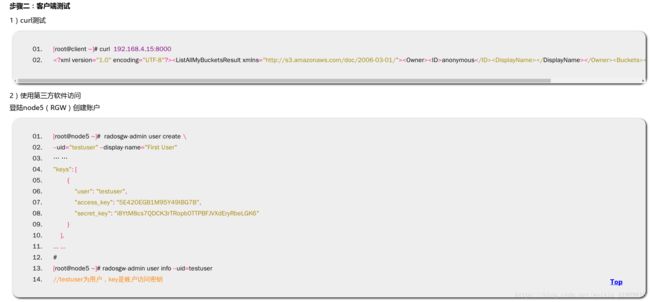
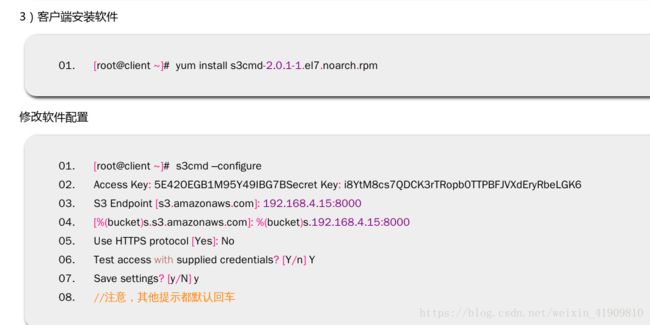
步骤二:客户端测试