pytorch框架yolov3算法训练自己数据集 win7~win10
文章目录
- 1. 环境搭建
- 2. 数据集构建
- 1. xml文件生成需要Labelimg软件
- 2. VOC2007 数据集格式
- 3. 创建*.names
- 4. 更新data/mask.data
- 5. 更新cfg文件,修改类别相关信息
- 3. 训练模型
- 4. 测试图片和视频.
- 5. 测试摄像头
- 6. 可视化
- 完整代码百度云链接
1. 环境搭建
首先需要安装的工具pytorch,这是一个从torch改进过来的框架,进入官网的网站,选择自己的电脑系统,下载方式,语言,还有对应的CUDA,此时会给出一行pip命令,复制命令,打开cmd命令行,粘贴,同时加上国内源提高下载速度,等待2个钟头左右,pytorch安装完毕。
不同的pytorch有不同的CUDA和CUDNN的版本。CUDA和CUDNN英伟达出品的并行计算架构,简单通俗的说就是可以让GPU代替CPU的计算,当然由于是并发,所以处理大量运算的时候速度更快,在下载CUDA的时候一定要注意是否和之前pytorch下载的时候选择的CUDA版本一致,下载地址就在英伟达的官方网站首页。Cudnn是一个加速库,面向神经网络,同样可以在英伟达的官网找到,也要注意支持的CUDA版本。
在全部下载完毕后,输出代码torch.cuda.device(0)和torch.cuda.is.available()测试GPU是否能正常使用,如果不行说明CUDA没有安装好,或者显卡不支持。
pytorch安装连接 https://pytorch.org/
2. 数据集构建
1. xml文件生成需要Labelimg软件
在Windows下使用LabelImg软件进行标注,快捷键:
Ctrl + u 加载目录中的所有图像,鼠标点击Open dir同功能
Ctrl + r 更改默认注释目标目录(xml文件保存的地址)
Ctrl + s 保存
Ctrl + d 复制当前标签和矩形框 space 将当前图像标记为已验证 w
创建一个矩形框
d 下一张图片
a 上一张图片
del 删除选定的矩形框
Ctrl++ 放大
Ctrl-- 缩小
↑→↓← 键盘箭头移动选定的矩形框
2. VOC2007 数据集格式
-data
---- VOCdevkit2007
---- VOC2007
---- Annotations (标签XML文件,用对应的图片处理工具人工生成的)
---- ImageSets (生成的方法是用sh或者MATLAB语言生成)
---- ---- test.txt
---- ---- train.txt
---- ---- trainval.txt
---- ---- val.txt
- JPEGImages(原始文件)
- labels (xml文件对应的txt文件)
imageSets下面的文件可以由makeTxt.py生成
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml对应的txt文件由voc_label.py生成 代码如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ["face","face_mask"] # 我们只是检测细胞,因此只有一个类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
height=root.find('height')
w=1024
h=1024
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# out_file.write(str(cls_id) + " " + " ".join([str(a) for a in b]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
此时为了避免错误检查一下xml文件,是否有size=0的情况,可以通关python进行批量删除,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
path='data/Annotations/%s.xml' % (image_id)
path2='data/Annotations/%s.xml' % (image_id)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
if(size is None):
print(image_id)
in_file.close()
os.remove(path)
else:
w=int(size.find('width').text)
h = int(size.find('height').text)
if(w==0 or h==0):
print(image_id)
in_file.close()
os.remove(path)
image_ids =[x for x in range(100,6366)]
for image_id in image_ids:
convert_annotation(image_id)
若有size=0的情况,可重新执行上面两段代码
3. 创建*.names
其中保存的是你的所有的类别,每行一个类别,如data/mask.names:
face face_mask
4. 更新data/mask.data
classes = 2 # 改成你的数据集的类别个数
train = data/train.txt # 通过voc_label.py文件生成的txt文件
valid = data/test.txt # 通过voc_label.py文件生成的txt文件
names = data/mask.names # 记录类别
backup = backup/ # 记录checkpoint存放位置
eval = coco # 选择map计算方式
5. 更新cfg文件,修改类别相关信息
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=2
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=2
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=2
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
简单来说tiny中就是把classes改为需要测的分类,此处为2 classes上一层[convolutional]中的filters改为3*(5+classes)
3. 训练模型
首先打开cmd命令,进入项目的路径。使用python train.py运行训练代码,效果如图所示:
4. 测试图片和视频.
python detect.py --weights weights/best.pt
import argparse
import time
from sys import platform
from models import *
from project.datasets import *
from project.utils import *
def detect(
cfg,
data_cfg,
weights,
images='data/samples', # input folder
output='output', # output folder
fourcc='mp4v',
img_size=416,
conf_thres=0.5,
nms_thres=0.5,
save_txt=False,
save_images=True,
webcam=False
):
device = torch_utils.select_device()
if os.path.exists(output):
shutil.rmtree(output) # delete output folder
os.makedirs(output) # make new output folder
# Initialize model
if ONNX_EXPORT:
s = (320, 192) # onnx model image size (height, width)
model = Darknet(cfg, s)
else:
model = Darknet(cfg, img_size)
# Load weights
if weights.endswith('.pt'): # pytorch format
model.load_state_dict(torch.load(weights, map_location=device)['model'])
else: # darknet format
_ = load_darknet_weights(model, weights)
# Fuse Conv2d + BatchNorm2d layers
model.fuse()
# Eval mode
model.to(device).eval()
if ONNX_EXPORT:
img = torch.zeros((1, 3, s[0], s[1]))
torch.onnx.export(model, img, 'weights/export.onnx', verbose=True)
return
# Set Dataloader
vid_path, vid_writer =None,None
if webcam:
save_images = True
dataloader = LoadWebcam(img_size=img_size)
else:
dataloader = LoadImages(images, img_size=img_size)
# Get classes and colors
classes = load_classes(parse_data_cfg(data_cfg)['names'])
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(classes))]
for i, (path, img, im0, vid_cap) in enumerate(dataloader):
t = time.time()
save_path = str(Path(output) / Path(path).name)
# Get detections
img = torch.from_numpy(img).unsqueeze(0).to(device)
pred, _ = model(img)
det = non_max_suppression(pred, conf_thres, nms_thres)[0]
if det is not None and len(det) > 0:
# Rescale boxes from 416 to true image size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results to screen
print('%gx%g ' % img.shape[2:], end='') # print image size
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum()
print('%g %ss' % (n, classes[int(c)]), end=', ')
# Draw bounding boxes and labels of detections
for *xyxy, conf, cls_conf, cls in det:
if save_txt: # Write to file
with open(save_path + '.txt', 'a') as file:
file.write(('%g ' * 6 + '\n') % (*xyxy, cls, conf))
# Add bbox to the image
label = '%s %.2f' % (classes[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)])
print('Done. (%.3fs)' % (time.time() - t))
if webcam: # Show live webcam
cv2.imshow(weights, im0)
if save_images: # Save image with detections
if dataloader.mode == 'images':
cv2.imwrite(save_path, im0)
else:
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
fps = vid_cap.get(cv2.CAP_PROP_FPS)
width = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (width, height))
vid_writer.write(im0)
if save_images:
print('Results saved to %s' % os.getcwd() + os.sep + output)
if platform == 'darwin': # macos
os.system('open ' + output + ' ' + save_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='cfg/yolov3-tiny.cfg', help='cfg file path')
parser.add_argument('--data-cfg', type=str, default='data/mask.data', help='coco.data file path')
parser.add_argument('--weights', type=str, default='weights/latest.pt', help='path to weights file')
parser.add_argument('--images', type=str, default='data/samples', help='path to images')
parser.add_argument('--img-size', type=int, default=416, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.5, help='object confidence threshold')
parser.add_argument('--nms-thres', type=float, default=0.5, help='iou threshold for non-maximum suppression')
parser.add_argument('--fourcc', type=str, default='mp4v', help='specifies the fourcc code for output video encoding (make sure ffmpeg supports specified fourcc codec)')
parser.add_argument('--output', type=str, default='output',help='specifies the output path for images and videos')
opt = parser.parse_args()
print(opt)
with torch.no_grad():
detect(
opt.cfg,
opt.data_cfg,
opt.weights,
images=opt.images,
img_size=opt.img_size,
conf_thres=opt.conf_thres,
nms_thres=opt.nms_thres,
fourcc=opt.fourcc,
output=opt.output
)
5. 测试摄像头
把detect.py中的webcam改为False。此时会报错NoneType,打开datasets.py文件
import glob
import math
import os
import random
import shutil
from pathlib import Path
import cv2
import numpy as np
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
from project.utils import xyxy2xywh
class LoadImages: # for inference
def __init__(self, path, img_size=416):
self.height = img_size
img_formats = ['.jpg', '.jpeg', '.png', '.tif']
vid_formats = ['.mov', '.avi', '.mp4']
files = []
if os.path.isdir(path):
files = sorted(glob.glob('%s/*.*' % path))
elif os.path.isfile(path):
files = [path]
images = [x for x in files if os.path.splitext(x)[-1].lower() in img_formats]
videos = [x for x in files if os.path.splitext(x)[-1].lower() in vid_formats]
nI, nV = len(images), len(videos)
self.files = images + videos
self.nF = nI + nV # number of files
self.video_flag = [False] * nI + [True] * nV
self.mode = 'images'
if any(videos):
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nF > 0, 'No images or videos found in ' + path
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == self.nF:
raise StopIteration
path = self.files[self.count]
if self.video_flag[self.count]:
# Read video
self.mode = 'video'
ret_val, img0 = self.cap.read()
if not ret_val:
self.count += 1
self.cap.release()
if self.count == self.nF: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1
print('video %g/%g (%g/%g) %s: ' % (self.count + 1, self.nF, self.frame, self.nframes, path), end='')
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'File Not Found ' + path
print('image %g/%g %s: ' % (self.count, self.nF, path), end='')
# Padded resize
img, _, _, _ = letterbox(img0, new_shape=self.height)
# Normalize RGB
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB
img = np.ascontiguousarray(img, dtype=np.float32) # uint8 to float32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
# cv2.imwrite(path + '.letterbox.jpg', 255 * img.transpose((1, 2, 0))[:, :, ::-1]) # save letterbox image
return path, img, img0, self.cap
def new_video(self, path):
self.frame = 0
self.cap = cv2.VideoCapture(path)#path
self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
def __len__(self):
return self.nF # number of files
class LoadWebcam: # for inference
def __init__(self, img_size=416):
vid_formats = ['.mov', '.avi', '.mp4']#64
files = []#64
self.cam = cv2.VideoCapture(0)
self.height = img_size
videos = [x for x in files if os.path.splitext(x)[-1].lower() in vid_formats]#64
self.mode = 'images'#64
if any(videos):#64
self.new_video(videos[0]) # new video#64
else:#64
self.cap = None#64
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == 27: # esc to quit
cv2.destroyAllWindows()
raise StopIteration
# Read image
ret_val, img0 = self.cam.read()
assert ret_val, 'Webcam Error'
img_path = 'webcam_%g.jpg' % self.count
img0 = cv2.flip(img0, 1) # flip left-right
print('webcam %g: ' % self.count, end='')
# Padded resize
img, _, _, _ = letterbox(img0, new_shape=self.height)
# Normalize RGB
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB
img = np.ascontiguousarray(img, dtype=np.float32) # uint8 to float32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
return img_path, img, img0, None
def __len__(self):
return 0
class LoadImagesAndLabels(Dataset): # for training/testing
def __init__(self, path, img_size=416, batch_size=16, augment=False, rect=True, image_weights=False):
with open(path, 'r') as f:
img_files = f.read().splitlines()
self.img_files = list(filter(lambda x: len(x) > 0, img_files))
n = len(self.img_files)
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
nb = bi[-1] + 1 # number of batches
assert n > 0, 'No images found in %s' % path
self.n = n
self.batch = bi # batch index of image
self.img_size = img_size
self.augment = augment
self.image_weights = image_weights
self.rect = False if image_weights else rect
self.label_files = [x.replace('images', 'labels').
replace('.jpeg', '.txt').
replace('.jpg', '.txt').
replace('.bmp', '.txt').
replace('.png', '.txt') for x in self.img_files]
# Rectangular Training https://github.com/ultralytics/yolov3/issues/232
if self.rect:
from PIL import Image
# Read image shapes
#sp = 'data' + os.sep + path.replace('.txt', '.shapes').split(os.sep)[-1] # shapefile path
#sp = os.sep + path.replace('.txt', '.shapes').split(os.sep)[-1] # shapefile path
sp=path. replace('.txt','shapes'). split(os.sep)[-1]
if os.path.exists(sp): # read existing shapefile
with open(sp, 'r') as f:
s = np.array([x.split() for x in f.read().splitlines()], dtype=np.float32)
assert len(s) == n, 'Shapefile out of sync, please delete %s and rerun' % sp
else: # no shapefile, so read shape using PIL and write shapefile for next time (faster)
s = np.array([Image.open(f).size for f in tqdm(self.img_files, desc='Reading image shapes')])
np.savetxt(sp, s, fmt='%g')
# Sort by aspect ratio
ar = s[:, 1] / s[:, 0] # aspect ratio
i = ar.argsort()
ar = ar[i]
self.img_files = [self.img_files[i] for i in i]
self.label_files = [self.label_files[i] for i in i]
# Set training image shapes
shapes = [[1, 1]] * nb
for i in range(nb):
ari = ar[bi == i]
mini, maxi = ari.min(), ari.max()
if maxi < 1:
shapes[i] = [maxi, 1]
elif mini > 1:
shapes[i] = [1, 1 / mini]
self.batch_shapes = np.ceil(np.array(shapes) * img_size / 32.).astype(np.int) * 32
# Preload labels (required for weighted CE training)
self.imgs = [None] * n
self.labels = [np.zeros((0, 5))] * n
iter = tqdm(self.label_files, desc='Reading labels') if n > 1000 else self.label_files
for i, file in enumerate(iter):
try:
with open(file, 'r') as f:
l = np.array([x.split() for x in f.read().splitlines()], dtype=np.float32)
if l.shape[0]:
assert l.shape[1] == 5, '> 5 label columns: %s' % file
assert (l >= 0).all(), 'negative labels: %s' % file
assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels: %s' % file
self.labels[i] = l
except:
pass # print('Warning: missing labels for %s' % self.img_files[i]) # missing label file
assert len(np.concatenate(self.labels, 0)) > 0, 'No labels found. Incorrect label paths provided.'
def __len__(self):
return len(self.img_files)
# def __iter__(self):
# self.count = -1
# print('ran dataset iter')
# self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
# return self
def __getitem__(self, index):
if self.image_weights:
index = self.indices[index]
img_path = self.img_files[index]
label_path = self.label_files[index]
# Load image
img = self.imgs[index]
if img is None:
img = cv2.imread(img_path) # BGR
assert img is not None, 'File Not Found ' + img_path
if self.n < 1001:
self.imgs[index] = img # cache image into memory
# Augment colorspace
augment_hsv = True
if self.augment and augment_hsv:
# SV augmentation by 50%
fraction = 0.50 # must be < 1.0
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # hue, sat, val
S = img_hsv[:, :, 1].astype(np.float32) # saturation
V = img_hsv[:, :, 2].astype(np.float32) # value
a = (random.random() * 2 - 1) * fraction + 1
b = (random.random() * 2 - 1) * fraction + 1
S *= a
V *= b
img_hsv[:, :, 1] = S if a < 1 else S.clip(None, 255)
img_hsv[:, :, 2] = V if b < 1 else V.clip(None, 255)
cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img)
# Letterbox
h, w, _ = img.shape
if self.rect:
shape = self.batch_shapes[self.batch[index]]
img, ratio, padw, padh = letterbox(img, new_shape=shape, mode='rect')
else:
shape = self.img_size
img, ratio, padw, padh = letterbox(img, new_shape=shape, mode='square')
# Load labels
labels = []
if os.path.isfile(label_path):
# with open(label_path, 'r') as f:
# x = np.array([x.split() for x in f.read().splitlines()], dtype=np.float32)
x = self.labels[index]
if x.size > 0:
# Normalized xywh to pixel xyxy format
labels = x.copy()
labels[:, 1] = ratio * w * (x[:, 1] - x[:, 3] / 2) + padw
labels[:, 2] = ratio * h * (x[:, 2] - x[:, 4] / 2) + padh
labels[:, 3] = ratio * w * (x[:, 1] + x[:, 3] / 2) + padw
labels[:, 4] = ratio * h * (x[:, 2] + x[:, 4] / 2) + padh
# Augment image and labels
if self.augment:
img, labels = random_affine(img, labels, degrees=(-5, 5), translate=(0.10, 0.10), scale=(0.90, 1.10))
nL = len(labels) # number of labels
if nL:
# convert xyxy to xywh
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])
# Normalize coordinates 0 - 1
labels[:, [2, 4]] /= img.shape[0] # height
labels[:, [1, 3]] /= img.shape[1] # width
if self.augment:
# random left-right flip
lr_flip = True
if lr_flip and random.random() > 0.5:
img = np.fliplr(img)
if nL:
labels[:, 1] = 1 - labels[:, 1]
# random up-down flip
ud_flip = False
if ud_flip and random.random() > 0.5:
img = np.flipud(img)
if nL:
labels[:, 2] = 1 - labels[:, 2]
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels)
# Normalize
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img, dtype=np.float32) # uint8 to float32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
return torch.from_numpy(img), labels_out, img_path, (h, w)
@staticmethod
def collate_fn(batch):
img, label, path, hw = list(zip(*batch)) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img, 0), torch.cat(label, 0), path, hw
def letterbox(img, new_shape=416, color=(127.5, 127.5, 127.5), mode='auto'):
# Resize a rectangular image to a 32 pixel multiple rectangle
# https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
ratio = float(new_shape) / max(shape)
else:
ratio = max(new_shape) / max(shape) # ratio = new / old
new_unpad = (int(round(shape[1] * ratio)), int(round(shape[0] * ratio)))
# Compute padding https://github.com/ultralytics/yolov3/issues/232
if mode is 'auto': # minimum rectangle
dw = np.mod(new_shape - new_unpad[0], 32) / 2 # width padding
dh = np.mod(new_shape - new_unpad[1], 32) / 2 # height padding
elif mode is 'square': # square
dw = (new_shape - new_unpad[0]) / 2 # width padding
dh = (new_shape - new_unpad[1]) / 2 # height padding
elif mode is 'rect': # square
dw = (new_shape[1] - new_unpad[0]) / 2 # width padding
dh = (new_shape[0] - new_unpad[1]) / 2 # height padding
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR) # resized, no border
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # padded square
return img, ratio, dw, dh
def random_affine(img, targets=(), degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-2, 2),
borderValue=(127.5, 127.5, 127.5)):
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
# https://medium.com/uruvideo/dataset-augmentation-with-random-homographies-a8f4b44830d4
if targets is None:
targets = []
border = 0 # width of added border (optional)
height = img.shape[0] + border * 2
width = img.shape[1] + border * 2
# Rotation and Scale
R = np.eye(3)
a = random.random() * (degrees[1] - degrees[0]) + degrees[0]
# a += random.choice([-180, -90, 0, 90]) # 90deg rotations added to small rotations
s = random.random() * (scale[1] - scale[0]) + scale[0]
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s)
# Translation
T = np.eye(3)
T[0, 2] = (random.random() * 2 - 1) * translate[0] * img.shape[0] + border # x translation (pixels)
T[1, 2] = (random.random() * 2 - 1) * translate[1] * img.shape[1] + border # y translation (pixels)
# Shear
S = np.eye(3)
S[0, 1] = math.tan((random.random() * (shear[1] - shear[0]) + shear[0]) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan((random.random() * (shear[1] - shear[0]) + shear[0]) * math.pi / 180) # y shear (deg)
M = S @ T @ R # Combined rotation matrix. ORDER IS IMPORTANT HERE!!
imw = cv2.warpAffine(img, M[:2], dsize=(width, height), flags=cv2.INTER_LINEAR,
borderValue=borderValue) # BGR order borderValue
# Return warped points also
if len(targets) > 0:
n = targets.shape[0]
points = targets[:, 1:5].copy()
area0 = (points[:, 2] - points[:, 0]) * (points[:, 3] - points[:, 1])
# warp points
xy = np.ones((n * 4, 3))
xy[:, :2] = points[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = (xy @ M.T)[:, :2].reshape(n, 8)
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# # apply angle-based reduction of bounding boxes
# radians = a * math.pi / 180
# reduction = max(abs(math.sin(radians)), abs(math.cos(radians))) ** 0.5
# x = (xy[:, 2] + xy[:, 0]) / 2
# y = (xy[:, 3] + xy[:, 1]) / 2
# w = (xy[:, 2] - xy[:, 0]) * reduction
# h = (xy[:, 3] - xy[:, 1]) * reduction
# xy = np.concatenate((x - w / 2, y - h / 2, x + w / 2, y + h / 2)).reshape(4, n).T
# reject warped points outside of image
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
w = xy[:, 2] - xy[:, 0]
h = xy[:, 3] - xy[:, 1]
area = w * h
ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16))
i = (w > 4) & (h > 4) & (area / (area0 + 1e-16) > 0.1) & (ar < 10)
targets = targets[i]
targets[:, 1:5] = xy[i]
return imw, targets
def convert_images2bmp():
# cv2.imread() jpg at 230 img/s, *.bmp at 400 img/s
for path in ['../coco/images/val2014/', '../coco/images/train2014/']:
folder = os.sep + Path(path).name
output = path.replace(folder, folder + 'bmp')
if os.path.exists(output):
shutil.rmtree(output) # delete output folder
os.makedirs(output) # make new output folder
for f in tqdm(glob.glob('%s*.jpg' % path)):
save_name = f.replace('.jpg', '.bmp').replace(folder, folder + 'bmp')
cv2.imwrite(save_name, cv2.imread(f))
for label_path in ['../coco/trainvalno5k.txt', '../coco/5k.txt']:
with open(label_path, 'r') as file:
lines = file.read()
lines = lines.replace('2014/', '2014bmp/').replace('.jpg', '.bmp').replace(
'/Users/glennjocher/PycharmProjects/', '../')
with open(label_path.replace('5k', '5k_bmp'), 'w') as file:
file.write(lines)
增加一段代码,上面已经添加了。
在class LoadWebcam的init中 ,修改为:
def __init__(self, img_size=416):
vid_formats = ['.mov', '.avi', '.mp4']#64
files = []#64
self.cam = cv2.VideoCapture(0)
self.height = img_size
videos = [x for x in files if os.path.splitext(x)[-1].lower() in vid_formats]#64
self.mode = 'images'#64
if any(videos):#64
self.new_video(videos[0]) # new video#64
else:#64
self.cap = None#64
报错解决,此时摄像头会把拍到的脸变成图片的形式存在output中
6. 可视化
python -c from utils import utils;utils.plot_results()
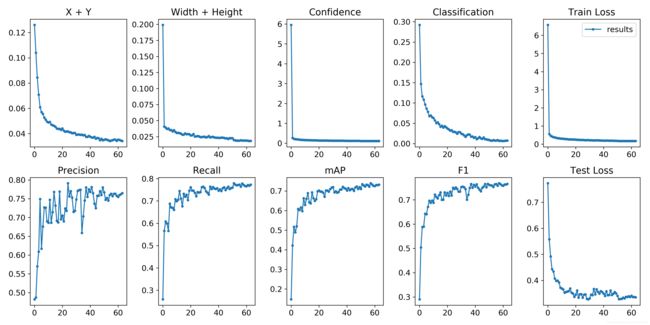 比如face和mask
比如face和mask
准确度precision=tp/(tp+fp) 识别出来的face占识别出来face和识别出来的面具的比率
召回率recall=tp/(tp+fn)识别出来的face占face总数的比率
完整代码百度云链接
链接:https://pan.baidu.com/s/1J5lEbPULafJNCTFMuLQ88g
提取码:74sb