使用深度学习训练聊天机器人与人对话
聊天机器人是“通过听觉或文本方法进行对话的计算机程序”,苹果的Siri, 微软的Cortana, 谷歌助手和亚马逊的Alexa是当下最流行的四种会话代理,它们能帮助你获得出行路线,检查运动项目的得分。
这些产品都有听觉接口,会话代理通过语音信息与你对话。在这篇文章中,我们将更多地关注只采用文本操作的聊天机器人。Facebook一直在大力投资FB Messenger机器人,它允许小型企业和组织创建机器人来提供用户支持和提出问题。聊天机器人已经存在了相当长的一段时间(Siri在2011年发布),但直到最近,深度学习成为了创建聊天机器人互动的首选方法。
在这篇文章中,我们将讨论如何使用深度学习模型在我过去的社交媒体对话中训练聊天机器人,希望能让聊天机器人按照我的方式来回应信息。
问题空间
聊天机器人的工作是对它收到的消息给出最佳响应。这种“最佳”的响应应该是(1)回答发件人的问题,(2)给发件人相关的信息,(3)询问后续问题,或者(4)以现实的方式继续对话。这是一个非常艰巨的任务。聊天机器人需要能够理解发件人发送信息的意图,确定响应信息的类型(后续问题、直接响应等),并在编写回应语句时遵循正确的语法和词汇规则。
可以肯定地说,现代聊天机器人完成这些任务是很困难的。
聊天机器人往往无法理解我们的意图,很难给我们提供正确的信息。正如我们在这篇文章中所看到的,深度学习是解决这一艰巨任务的最有效方法之一。
深度学习
使用深度学习的聊天机器人几乎都使用sequence to sequence(Seq2Seq)模型的某些变体。2014年,Ilya Sutskever、Oriol Vinyals和Quoc Le发表了关于这一领域的开创性的论文,论文名为《Sequence to Sequence Learning with Neural Networks》,特别指出了机器翻译的巨大成果,但Seq2Seq模型已经发展到包含各种NLP任务。

Seq2Seq模型由2个主要组件组成,一个编码器RNN和一个解码器RNN。编码器的工作是将输入文本的信息封装成固定的表示形式。解码器的作用是获取该表示形式,并生成一个可对其作出最佳响应的可变长度文本。

让我们来看看如何在更详细的层次上工作。RNN包含许多隐藏的状态向量,它们表示前一个时间步骤的信息。例如,第3次步中隐藏的状态向量将是前3个单词的函数。按照这种逻辑,可以将编码器RNN的最终隐藏状态向量看作是整个输入文本的精确表示。
解码器是另一个RNN,它接收编码器的最终隐藏状态向量,并利用它来预测输出回复的单词。我们来看看第一个单元格。单元格的工作是接收向量表示v,并决定在其词汇表中哪个词最适合于输出响应。从数学意义上讲,这意味着我们计算了词汇中每个单词的概率,并选择了值的argmax。
第二个单元格将是向量表示v的函数,以及前一个单元格的输出。LSTM的目标是估计以下条件概率。
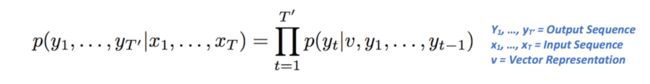
我们来解析这个方程的含义。左边是输出序列的概率,对给定的输入序列进行条件限制。右侧包含术语p(yt| v,y1,…,yt-1),这是所有单词的向量的概率,对前一次时间步长的向量表示和输出进行条件限制。Pi表示法就是简单的Sigma(或求和)的乘法等价。右边可以简化为p(y1 | v)* p(y2 | v,y1)* p(y3 | v,y1,y2)…等等。
在继续之前,让我们看一个简单的例子。我们取第一个图像中看到的输入文本:“你明天有空吗?”让我们想想大多数人是如何回答这个问题的。在训练完网络之后,概率p(y1 | v)的分布看起来会像下面一样。

我们需要计算的第二个概率:p(y2 | v,y1),这是一个关于分布y1和向量表示v的函数的函数。Pi(产品)运算的结果将给我们最可能的单词序列,我们将用它作为最终的响应。
Seq2Seq模型最重要的特征之一是它提供的多功能性。传统的ML方法(线性回归,SVMs)和像CNNs这样的深度学习方法,它们的模型需要一个固定大小的输入,并产生固定大小的输出。输入的长度必须事先知道。这对于机器翻译、语音识别和问题回答等任务有很大的局限性。
对于这些任务,我们不知道输入短语的大小,我们希望能够产生可变长度的响应,而不是仅仅局限于一个特定的输出表示。Seq2Seq模型允许这种灵活性。
自2014年以来,Seq2Seq模型已经有了很多改进。
数据集选择
考虑到要将机器学习应用到各种类型的任务中,我们需要做的第一件事就是选择训练模型的数据集的类型。对于Seq2Seq模型,我们需要大量的对话日志。编码器解码器网络需要能够理解每个查询(编码器输入)所期望的响应类型(译码器输出)。常见的数据集有Cornell 电影对话语料库、Ubuntu 语料库和Microsoft的社交媒体对话语料库.。
虽然大多数人训练聊天机器人来回答公司的具体信息或提供某种服务,但我对有趣的应用程序更感兴趣。在这个特别的帖子里,我想看看我是否可以用我自己生活中的对话记录来训练一个Seq2Seq模型,训练它以我想要的方式来回应信息。
数据来自哪里?

好的,我们来看看怎么做。我们需要创建一个大型数据集(我在网上与人们的对话)。在社交媒体上,我使用Facebook、谷歌Hangouts、SMS、LinkedIn、Twitter、Tinder和Slack来与人保持联系。
Facebook:这是大部分训练数据的来源。Facebook有一个很酷的功能,可以下载所有的Facebook数据的副本。这个下载将包含你所有的信息,你的照片,和你的all-caps,你在中学时记录的难堪的状态。
谷歌Hangouts:在高中的时候,我确实经常和一群亲密的朋友使用这个。你可以按照这个 神奇的博客文章.的指示来提取你的聊天数据。
SMS/Texting:这是一种很确定的可以获得所有之前的聊天记录的一种方法(SMS备份+是一个很好的应用程序),但是我很少使用文本,所以不要认为这是值得的。
LinkedIn: 提供了一个获取数据存档的工具.。
Twitter:没有足够的私人信息。
Tinder:这些对话不是数据集。
Slack:最近刚开始使用这个,只有一些私人信息,所以打算手动复制convos。
创建数据集
机器学习的一个重要部分是数据集预处理。这些数据源中的每个数据源都有不同的格式,并且包含我们不需要的部分(例如,FB数据的图片部分)。
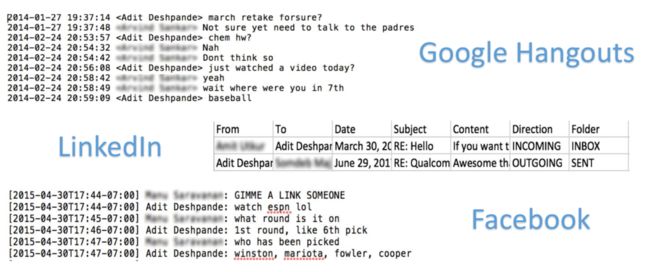
如你所见,Hangouts数据的格式与Facebook数据稍有不同,而LinkedIn数据则采用CSV格式。我们的目标是创建一个统的一文件,包含成对的(FRIENDS_MESSAGE,YOUR_RESPONSE)形式的句子。
为此,我编写了一个Python脚本,你可以查看这里. 。这个脚本将创建两个不同的文件。一个将Numpy对象(conversationDictionary.npy),其中包含所有的输入输出对。另一个将是一个大型的txt文件(会话data.txt),其中包含了一个接一个的成对的句子形式。通常情况下,我喜欢分享数据集,但对于这个特定的数据集,因为它有很多私密的对话,所以我把它保密。这里有一个关于最终数据集的快照。

词向量
LOL. Lmao. Wtf. 。这些都是在我们的对话数据文件中经常出现的词。虽然它们在社交媒体领域很常见,但它们并不属于传统的数据集。通常情况下,在接近NLP任务时,我的第一反应是使用预先训练的向量,因为它们在大型语料库中进行了大量的迭代训练。由于我们有很多词和首字母缩略词,它们并没有在预先训练的词向量列表中,因此生成我们自己的词向量是至关重要的,它能够确保词被正确地表达。
我们使用Word2Vec模型的经典方法生成词向量。模型通过观察句子中出现的词来创造词向量。将具有相似上下文的词放置在位置接近的向量空间中。
在这个Python脚本中,我训练了Word2Vec模型,它将词向量保存在一个Numpy对象中。
* *更新:事后,我了解到Tensorflow Seq2Seq函数从头开始训练词嵌入,所以即使我不使用这些词向量,它仍然是很好的练习* *
创建带有Tensorflow的Seq2Seq模型
现在我们已经创建了数据集并生成了词向量,我们可以继续编写Seq2Seq模型。我在这个Python脚本中创建并训练了这个模型。我试着尽我所能去注释代码,希望你能跟上。模型的关键在于它的嵌入函数。你可以在这里.找到文件。
追踪训练进度
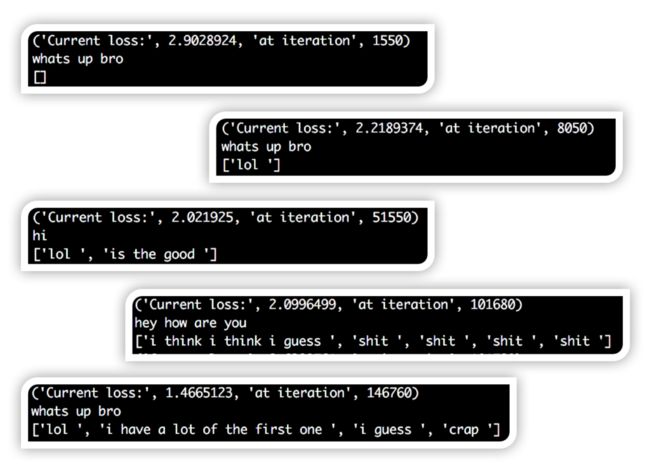
这个项目的有趣的一点是,可以观察响应如何随网络训练而改变。在训练循环的不同点上,我在输入字符串上测试了网络,并输出了输出中的所有非pad和非eos标记。首先,你可以看到响应大部分是空白的,因为网络不断地输出填充和EOS标记。这是正常的,填充标记是整个数据集中最常用的标记。然后,你可以看到,网络开始为每个输入字符串输出“lol”。这是有一定道理的,因为“lol”经常被使用,它是任何事物都可以接受的回应。慢慢地,你会看到更多完整的想法和语法结构出现在回应中。也可能是由于有点过度拟合。
建立Facebook Messenger聊天机器人
现在我们已经有了一个经过良好训练的Seq2Seq模型,让我们来看看如何建立一个简单的FB messenger聊天机器人。这个过程并不太难,因为它花了我不到30分钟的时间就完成了这个教程的所有步骤。基本思路是,使用简单的Express应用程序设置服务器,将其托管在Heroku上,然后设置一个Facebook App / Page连接它。我不会讲太多的细节,因为我认为作者已经一步一步详细地讲解了每件事,你应该有一个这样的Facebook应用。
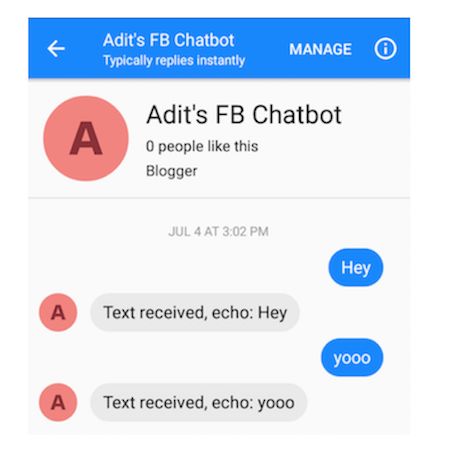
你应该给你的机器人发送信息(初期行为只是回应接收到的所有信息)。
部署Tensorflow模型
现在把所有东西组合在一起。由于我还没有在Tensorflow和Node之间找到一个好的接口(不知道是否有一个官方支持的包装),所以我决定使用Flask服务器部署我的模型,并让聊天机器人的Express应用程序与它交互。
你可以查看这里的Flask服务器代码和聊天机器人的索引。js文件。
测试模型
如果你想和这个机器人聊天,就去到这个链接或者到这个Facebook页面,点击发送消息按钮。第一次响应可能需要一段时间,因为服务器需要启动。
很难判断机器人是否能像我一样回复(在网络上,没有很多人跟我说过LOL),但我认为它做得很好!这种语法是符合社会媒体的标准。你可以挑选一些好的结果,但大多数都很荒谬。
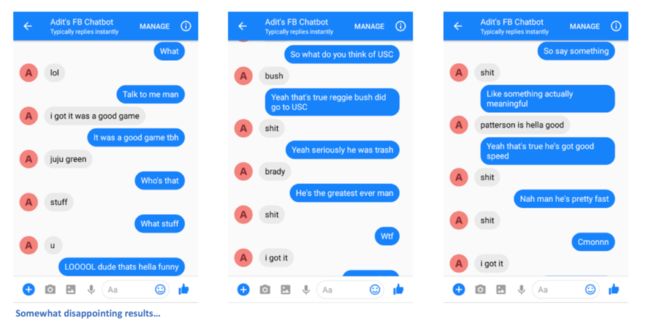
我认为第一个对话特别有趣,因为“juju green”实际上似乎是钢人队的外接手Juju Smith-Schuster和金州勇士队的前锋Draymond Green 名字的组合。真是一个有趣的组合。
模型的表现并不是很好。让我们想想如何改进它!
如何改善
从聊天机器人的互动中可以看出,仍有很大的改进的空间。在几条信息之后,很快就会发现,聊天机器人无法进行持续的对话。它不能把想法联系在一起,有些反应似乎是随机的,语无伦次。这里有一些方法可以提高我们聊天机器人的性能。
- 合并其他数据集,以帮助网络从更大的会话语料库中学习。这将消除聊天机器人的“个人特性”(在我的会话语料库中进行过严格的训练)。这将有助于产生更真实的对话。
- 处理编码器消息中与解码器消息无关的场景。例如,当结束了第一天的一个对话后,第二天开始一个新的对话。两个对话的话题可能完全无关。这可能会影响模型的训练。
- 使用双向LSTMs、注意机制和套接。
- 优化超参数,如LSTM单元的数量、LSTM层的数量、优化器的选择、训练迭代次数等。
如何建立自己的聊天机器人
你应该大概了解创建一个自己的聊天机器人所需要的东西。让我们再看一遍最后的步骤。在GitHub repo README中有详细的说明。
1.找到所有你与某人交谈过的社交媒体网站,下载你的数据副本。
2.从CreateDataset中提取所有(消息、响应)对。py或你自己的脚本。
3.(可选)通过Word2Vec.py为每一个在我们的对话中出现的词生成词向量。
4.在Seq2Seq.py中创建、训练和保存序列模型。
5.创建Facebook聊天机器人。
6.在部署保存的Seq2Seq模型中创建一个Flask服务器。
7.编辑索引.js文件在你的Express应用程序中,以便与Flask服务器通信。
本文转载自ATYUN人工智能信息平台,原文链接:使用深度学习训练聊天机器人与人对话
更多推荐
你真的适合学习AI吗?
2017年数据科学和大数据的六大走向
给机器学习和深度学习工程师的“小抄”
google图片识别模型在Android平台小案例
“好奇号”火星探测器正在利用AI自主寻找探测目标
 欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]
欢迎关注ATYUN官方公众号,商务合作及内容投稿请联系邮箱:[email protected]