大数据Hive的学习积累
hive是怎样保存元数据&内部表和外部表的区别:
https://www.jianshu.com/p/2ea08633b790
Hive的分区表
https://www.jianshu.com/p/69efe36d068b
Hive建表时指定分隔符或使用多字符分隔
https://blog.csdn.net/u013150378/article/details/90766209
分区表的使用:
- 分区表一般在数据量比较大,且有明确的分区字段时使用,这样用分区字段作为查询条件查询效率会比较高。
分区表的介绍:
分区表指的是在创建表时指定的partition的分区空间,一个表可以拥有一个或者多个分区,每个partition分区以文件夹的形式单独存在表文件夹的目录下。
示例:
建立分区表:
create table test.ora2hive (
id int,
name string,
salary double,
time string
)
PARTITIONED BY (`pday` string)
stored as parquet tblproperties('parquet.compression'='snappy');准备数据:
另一张表名为oracle,数据为:

插入数据:
INSERT into test.ora2hive PARTITION(pday)
SELECT
id,
name,
salary,
`time`,
from_unixtime(unix_timestamp(time,'yyyy/MM/dd'),'yyyy-MM-dd') as pday
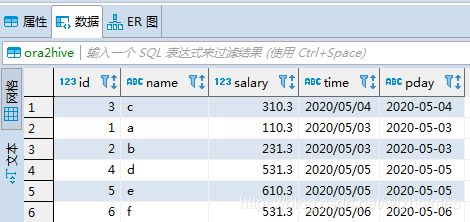
FROM test.oracleINSERT into test.ora2hive PARTITION(pday='2020-05-08') VALUES(8,'h',2341.23,'2020/05/08 12:24:32')查看ora2hive的数据:
查看HDFS上ora2hive表的目录,可以看到根据time时间字段进行了相应分区,每个分区为独立一个目录

查看分区信息
show partitions test_partition添加新分区
alter table ora2hive add partition (pday='2020-05-09')删除分区
alter table ora2hive drop partition(pday='2020-05-09');分区修复命令MSCK
将数据拷贝到我们Hive的目录下面,如果不是分区表,则新建的表可以正常使用,但是如果是分区表的,一般都是使用alter table add partition命令将分区信息添加到新建的表中,每添加一条分区信息就执行一个alter table add partition命令。
如果分区数量少还好办,但是遇到分区数量多的情况,特别是分区数量大于50的情况,如果还是使用alter命令添加分区,那是一件耗时耗力的事情,还容易出错。Hive提供了MSCK命令,用于修复表的分区,该命令将关于分区的元信息添加到Hive metastore中,这是对于那些没有元信息的分区来说的。换句话说,就是将任何存在于HDFS上但不在metastore上的分区添加到metastore。
示例

通过kettle将Oracle中的数据导入至hive的parquet表后,show partitions test_partition并没有显示分区,而通过hdfs dfs -ls /命令查看HDFS目录下是有分区文件的,需要通过alter table add partition (pday='2020-05-09')来手动添加增加的分区。
分区数量较多时,通过命令:
MSCK REPAIR TABLE test.ora2hive;将ora2hive表的全部的分区信息添加到Hive metastore,省时省力。注意,MSCK命令只能在hive下使用,在impala命令下不存在该命令。