mysql索引相关总结
索引实现
mysql索引主要由b + tree 或hash结构实现,两者之中一般选用b + tree。b + tree 结构如下:
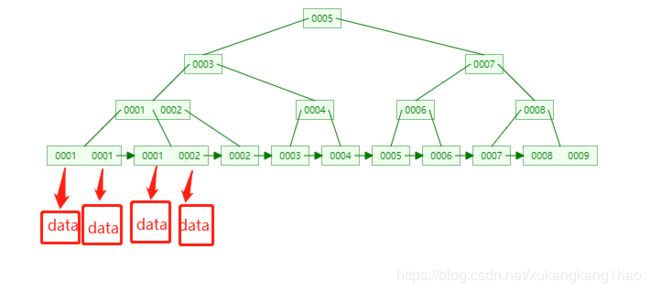
b + tree有如下特点:
1,如果一个节点有M个子树,则这个节点有M个关键字,其中每个元素有对应指针,这个指针指向子树,子树的最小关键字大于等于当前关键字且最大关键字小于下一个关键字。
2,每个节点的每个关键字不包含关键字对应的data(关键字对应data都在叶子节点中存储),所以在一个块内(一个块对应机械磁盘上多个扇区)能存放更多的关键字,而b tree每个关键字都包含了关键字对应的data,所以一个块内存放的数据也就更少,和b + tree相比查找同样数量的关键字需要的I/0次数也就更多,所以b + tree效率更好。
3,b + tree在非叶子节点中存储的关键字,最终在叶子节点中也会存储。所以b + tree的查找最终都会落到叶子节点上,所以b + tree的查找效率很稳定。
4,b + tree的每个叶子节点都指向下一个叶子节点,通过这样的节点顺序链接,可以方便的进行如下操作
(1)排序(直接按照指针的顺序读取就行了),但是如果使用b tree的话,排序则需要进行中序遍历
(2)分组(分组之前是需要先排序的)
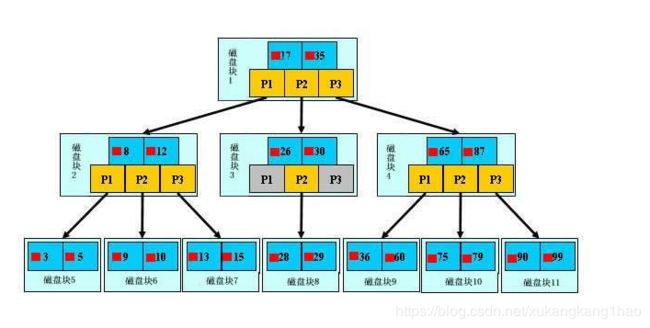
其中b tree结构图如下:
问题:为什么不选用二叉树和红黑树作为所以存储结构?
答:二叉树是一种非平衡树,如果出现如下情况,则搜索效率就变为线性查找的效率。

红黑树可能会出现如下情况:
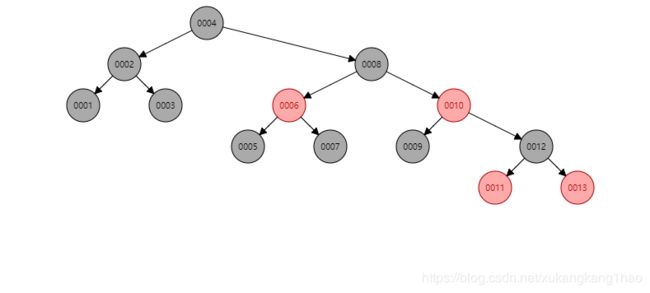
从图中看,红黑树也只是相对平衡。
而且,二叉树和红黑树每个节点都包含关键字对应的data,单个块内存储的关键字也比b + tree少。对于排序和范围查询的的过程和b tree比较类似,都需要中序遍历。
explain执行计划
explain执行计划命令格式如下:
explain
select
s.id
from
staffs s , (select * from r_user where id = 1) u
where
name="z4"
and
age > 11
and
pos="manager"
and
dep_id in (select id from department)
即只需要在sql开头加上explain即可,以上命令执行结果如下:

各个字段的含义如下:
id:sql中各个查询执行的顺序。id大的先执行,id相同的从上到下执行
select_type:查询的类型
table:对哪个表查询
type:重要,可以看做对查询用到的索引的性能描述,从最好到最差的次序依次是 system > const > eq_ref > ref > range > index > all,其中system表示:系统表,且表中只有一条数据会出现system。const -> 针对主键或者唯一索引用常量进行查询的情况,示例:company.id = 2。eq_ref -> 当联接使用索引的所有部分(指组合索引)并且索引是主键或惟一非空索引时,将使用该索引,示例:company.id = employee.company_id,(一个公司多个雇员)。ref是针对普通索引或者组合索引的最左前缀进行查询的情况,car.user_id = user.id 或者car.user_id = 1,(一个用户多辆车)。range是针对范围查询的情况。index是扫描整个索引树,这种情况一般是索引包含查询了查询字段的情况(覆盖索引),指扫描索引的原因是索引不包含行数据,每一次IO能读到大量的数据。all就是全表扫描。
possible_keys:可能会用到的索引
key:实际用到的索引
key_len:用到的索引的长度,跟索引的定义相关。比如说索引列定义类型为varchar(10),并且允许为null,则key_len为 10 * 3 + 2 + 1= 33,其中3为utf-8每个字符占用的字节数,2个字节代表字符串的实际长度,1个字节代表允许为null(如果不允许为null,则没有这一个字节)
ref:显示哪些列或者常量被用于索引查找
rows:rows表示MySQL认为执行查询必须检查的行数。对于InnoDB表,这个数字是一个估计数,可能不总是exac
extra:其它信息,以下三个为重要的提示信息:
(1)using filesort ,说明无法利用索引顺序进行排序,所以在一个文件中进行重新排序
(2)using temporary,用临时表保存中间结果
(3)using index,表明使用了覆盖索引,效率不错。如果同时出现using where ,表明索引被用来执行索引建的查找;如果同时没有出现using where ,表明只是用索引读取数据行而非进行查找动作
sql优化步骤
1,开启慢查询日志,通过mysqldumpslow命令,可以将慢查询sql查出来
2,通过explain执行计划,对慢sql进行分析,再结合业务相关数据,此时一般可以将问题分析出来
3,如果第二步还不能找出问题,则可以通过show profile,来查看到底sql哪里出了问题导致sql变慢,show profile使用步骤如下:
(1)profile默认关闭,需要开启profile,开启命令set profiling=on
(2)执行show profile,查看系统有哪些慢查询

(3)执行show profile cpu,block io for query Query_ID,其中query是上面截图的Query_ID,执行结果示例如下:
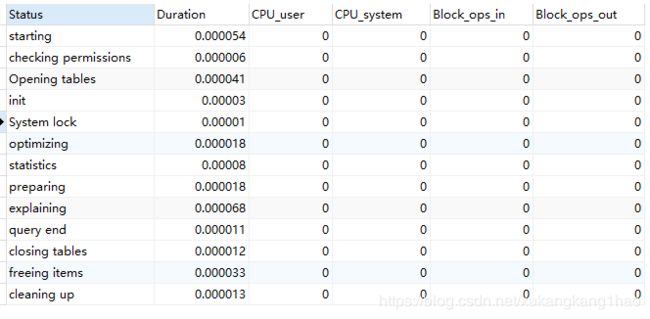
从执行结果中可以分析sql各个执行阶段的耗时来排查问题,如果status列出现了下面四个问题,则sql就很可能会变慢:
converting HEAP to MyISAM 查询结果太大,内存都存不上往磁盘上搬了
Creating tmp table 创建临时表(拷贝数据到临时表,用完再删除)
Copying to tmp table on disk 把内存中临时表复制到磁盘,危险!!!
locked
锁
MyISAM存储引擎中的锁
MyISAM使用的是表锁,表锁分为共享锁和排它锁。不支持事物。
使用共享锁锁表时,当前会话只可以对锁住的表进行读操作,不能进行写操作,不能对其它表进行读和写操作(想要操作其它表,先释放锁住表的锁)。其他会话可以对锁住的表进行读操作,也可以加共享锁,但是不能进行写操作(通过配置可以进行insert操作)。使用Myisam存储引擎,在select时会自动加上共享锁。
使用排它锁锁表时,当前会话只可以对锁住的表进行读和写操作,不能对其它表进行读和写操作(想要操作其它表,先释放锁住表的锁),其它会话不能对锁定的表进行读和写(包括insert)操作,同时也可以对没有锁住的表进行操作。使用MyISAM存储引擎,在写操作时会自动加上排它锁。
MyISAM写数据的时候,不会立刻将数据写入磁盘,会先写到操作系统文件缓存中,然后等待操作系统定期将数据刷到磁盘上。所以数据丢失的风险比较大。
MySIAM表压缩
MyISAM存储引擎存储的数据可以被压缩,从而减少磁盘占用的空间。以现在的硬件能力,对大多数的应用场景,读取压缩表数据然后解压并不会对性能有影响,但是带来的I/O好处则要大得多(一次磁盘I/O可以读取更多的数据)。被压缩后的MyISAM表示不能修改的,所以压缩后的MyISAM表是只读的。
MyISAM的特点:采用的是表锁,加锁快,无死锁,但是冲突的概率比较大,两个链接同时写(update,delete)一张表就会冲突,同时只能有一个链接能执行写操作,另一个则需要等待。
MyISAM使用场景
MyISAM表使用场景:日志表。日志一般只涉及到插入和读取操作,MyISAM表的插入和读取效率是很高的,所以连续插入大量的日志数据一般是没有问题的,而且可以每隔一段时间对日志数据进行压缩,然后再开启一个新的日志表进行数据的插入,这样就节省了磁盘空间。
InnoDB存储引擎中的锁
InnoDB存储引擎采用的是行锁,行锁分为共享锁和排它锁。支持事物。
InnoDB在读操作时可以通过加上lock in share mode来表明加了一个共享锁,例如select * from tb_table where id = 2 lock in share mode,这时候id等于2的数据行被共享锁锁定,其它数据库连接只能对id=2这行数据加共享锁读取,或者不加锁读取,即其它数据库连接不能对id=2这行数据update或者delete,也不能加排它锁。
InnoDB在写操作时,会自动给相关涉及到的行加上排它锁,其它数据库连接在执行写操作时,如果对应的行被排它锁锁定,则需要等待。如果其它数据库连接对被锁定的行加共享锁(lock in share model),则需要等待。但是可以不加锁读取被锁定的行。
InnoDB间隙锁
InnoDB中存在间隙锁,如下Case:
数据库连接1执行:
begin
update tb_table set name = "张三" where id > 1 and id < 6
//commit
但是数据库中只有id 为 1,3,4,5,6的数据,没有id为2的数据。此时数据库连接2执行如下insert:
insert tb_table (id,name,...) values(2,"李四",...)
此时上面这条insert会等待上面的update语句commit之后才能继续执行。
InnoDB索引失效导致的锁表问题
假设表tb_table有个varchar类型的字段name,然后一个数据库连接在事物中进行了update: update tb_table set age = 10 where name = 2000,由于2000没有加双引号,所以mysql会自动将张三转为带双引号的"2000",但是这时候字段name的索引会失效,接着这条update语句会导致锁全表,而不是只锁定某些行。其他写操作想要操作这个表时,会因为整个表被锁定了额而等待。