ceph运维问题记录
一、如果出现 osd启动报try_get_map错误,可以从正常的osd去导出对应版本的epoch,然后导回就可以了
1、如何导出导入osdmap
第一步:
先停掉坏的osd,以及一个好的osd(因为
ceph-objectstore-tool执行时需要停止osd
),
第二步:执行导出导入即可
命令例子:其中84是好的osd,85是有问题的osd
ceph-objectstore-tool --op get-osdmap --epoch 145039 --data-path /data1/ceph-osd/ --journal-path /var/log/ceph/ceph-84/journal --type filestore --file osdmap145039
ceph-objectstore-tool --op set-osdmap --epoch 145039 --data-path /data2/ceph-osd/ --journal-path /var/log/ceph/ceph-85/journal --type filestore --file osdmap145039PS:其中145039为对应的版本号,data-path与journal-path填写自己osd对应的路径
2、找到正确的epoch版本
这个要通过报错的osd日志查看,在启动的时候,osd会加载一个epoch版本A,这个版本是它正在执行的,缺少的epoch版本在它之前。然后在“dump of recent events”中发现已经执行的epoch版本B,以及ecoch版本C。将在max(B,C)到A之间的版本都导入一遍(也可以导入一个版本,启动一次观察,就是太麻烦了)。我日志中A=145068,B=145011,C=145012,所以我把145013到145067之间所有的ecoph版本都导入进去了,结果正常启动了。我的日志入下图
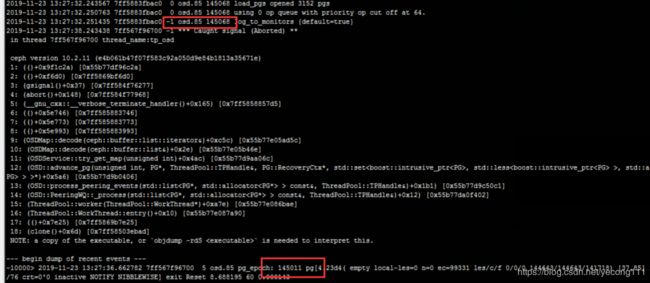
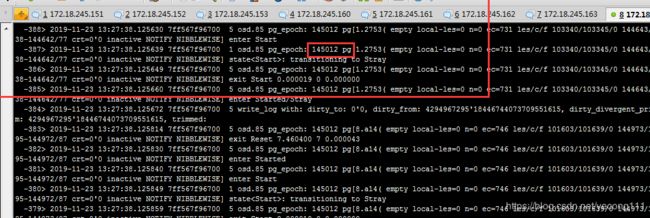
二、处理wrong node的日志报错
1、产生原因:
2个osd之间的osdmap版本如果相差过大(相差可能在50左右),会导致2个osd通讯的时候报wrong node。如果偶尔出现一次wrong node,那么问题不大,因为osd某个操作卡主了,然后恢复获取了最新版本的osdmap。如果osd日志一直在报,说明有osd同步osdmap出现问题,会导致osd down掉,心跳超时(可能),甚至出现osd大量吃内存,导致服务器挂掉。日志如下:
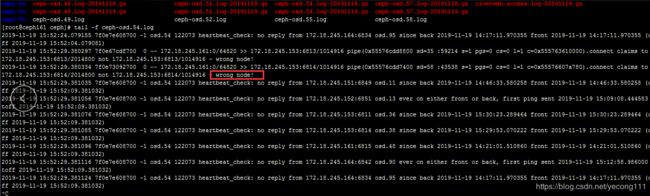
2、查看osd的osdmap版本
通过命令查看:ceph daemon osd.xx status ——xx标记对应的osd编号
命令结果例子:
{
"cluster_fsid": "df181181-2154-4816-a2b7-d6eae79980fb",
"osd_fsid": "d5edacd3-cee7-45eb-90df-e381d8684dfb",
"whoami": 15,
"state": "active",
"oldest_map": 92570,
"
newest_map
": 158146,
"num_pgs": 2105
}
其中
newest_map表示osd的最新版本号
3、查看集群的osdmap版本号
命令:ceph -s

这里:178170时最新版本号
4、确定osd版本是否有问题
多次间隔执行命令
ceph daemon osd.xx status 查看osd版本号,正确状态如下:
4.1、查询出来的版本号一直保持跟集群版本号一致
4.2、小于集群版本号,但是在不停增大,最终会达到集群版本号
5、出现osd不更新osdmap解决办法
到目前为止,我没有找到osd不更新osdmap的根本原因,我使用过
ceph daemon osd.xx
dump_blocked_ops 查看是否有阻塞的操作并解决阻塞,但是依然不行,即使返回没有阻塞,还是不更新。可能可以让osd重新更新的方式:
1、将对应的osd out出集群(osd还是up的),过一阵观察一下版本号(我的就是这样回复的)
2、重启osd
三 cephx: verify_reply couldn't decrypt with error: error decoding block for decryption
1、问题日志
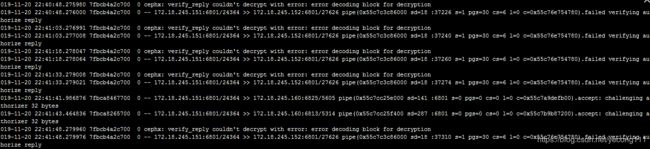
2、解决方式
:
1、检查服务器时间是否一致
2、检查集群中的
ke
y
ring
与本地osd的ke
y
ring是否一致:
使用命令:
ceph auth
list
从mon中获取所有osd的keyring,
cat /var/lib/ceph/osd/ceph-xx/keyring获取本地osd的keyring
3、去掉验证,重启所有的mon、osd,修改ceph.conf中的如下参数为
auth_cluster_required = none
auth_service_required = none
auth_client_required = none
四、heartbeat_check:no reply from xxxxx since back 报错
1、问题日志

2、解决方式
1、查看服务器时间与服务器网络(我的不是这个问题)
2、一般心跳超时是其他问题引起的,这里可以先调大心跳超时时间(我调大了心跳超时,解决了其他问题之后,就没有心跳超时了),修改配合文件ceph.conf的参数
mon_osd_report_timeout = 1800
filestore_op_thread_suicide_timeout = 1800
filestore_op_thread_timeout = 600
osd_heartbeat_grace = 600
osd_op_thread_suicide_timeout=1800
osd_op_thread_timeout=36000
这个配置可以先放到[global],等解决了问题,在去掉,也可以根据实际情况,自己调整参数
五、osd启动慢问题
1.查看日志查看osd卡在哪里
日志调整级别:修改配置文件ceph.conf参数,添加debug_osd=10(15/20),数值越高,打印越多。
如果已经启动osd,想更改日志级别,可以通过命令:ceph tell osd.xx injectargs --debug-osd 5
2、根据日志信息解决问题
我是卡在了load_pgs上,因为整个集群状态不对,而pg数量又很多,加载很慢,这时候需要考虑服务器压力,可以一个一个慢慢启动,不要一下子启动完。
六、PG状态为incomplete
1、问题原因
incomplete状态表示:Peering过程中由于无法选出权威日志或者通过choos_acting选出的acting不足以完成数据恢复,(例如针对纠删码,存活的副本数小于k值)等,导致Peering无法正常完成。即pg元数据丢失,无法恢复pg状态
2、解决问题
1、使用ceph-objectstore-tool工具将incomplete状态的pg标记为complete
2、操作步骤:
操作前提:设置集群flag:noout nodown noup noin PS:这里的目的是为了不让pg分布变化,我因为osd都起来了,只设置了noout nodown
第一步:通过命令 ceph pg dump_stuck |grep incomplete >incomplete.txt 从集群中导出incomplete状态的所有pg
第二步:通过第一步知道了pg所在的2个osd在哪里,stop这2个osd
第三步:对这2个osd上的pg通过命令做标记,命令如下
ceph-objectstore-tool --data-path /data4/ceph-osd/ --journal-path /var/log/ceph/ceph-15/journal --type filestore --pgid 9.ea8 --op mark-complete
ceph-objectstore-tool --data-path /data8/ceph-osd/ --journal-path /var/log/ceph/ceph-91/journal --type filestore --pgid 9.ea8 --op mark-complete
第四步:启动这2个osd(启动顺序没有关系)
第五步:观察集群中incomplete是否少了
第六步:重复第二步以及之后的操作,直到incomplete没有
3、特别说明
3.1、标记complete的过程,可能给导致集群degraded、misplaced增加,这是正常的

3.2、原因:因为我在标记的过程中,缺少了导入导出pg步骤。我这里没操作导入导出是因为pg数量有点多,而且pg比较大,导入导出会让2个osd停太久了,而且我觉得让集群自己恢复比较好
3.3、导入导出pg命令:
ceph-objectstore-tool --data-path /data3/ceph-osd/ --journal-path /var/log/ceph/ceph-2/journal --type filestore --pgid 4.15d5 --op export --file /data10/55/pg4.15d5
ceph-objectstore-tool --data-path /data8/ceph-osd/ --journal-path /var/log/ceph/ceph-5/journal --type filestore --pgid 4.15d5 --op import --file /data10/55/pg4.15d5选择一个osd为主,另一个为副,将一个导入到另外一个pg,导入导出需要停止osd。以上是将osd.2中的4.15d5导入到osd.5中
七、PG状态为down
1、如果能重启对应pg的osd,那是最好的,问题自然解决
2、如果osd对应的数据盘损毁或者其他原因无法启动这个osd
第一步:将这个osd删除,命令
ceph osd crush reweight osd.xx 0
ceph osd out osd.xx
ceph osd crush remove osd.xx
ceph osd rm osd.xx
ceph auth del osd.xx
第二步:清理当前osd的硬盘或者新加一个硬盘
第三步:新启动一个编号相同的osd
第四部:重复上面的操作,处理掉所有有问题的osd,如果还有down,没事,等集群自己恢复处理(我就是启动了一个新的osd,有pg处理incomlepte+down,我标记完了
incomlepte,down就自己消失了)
八、PG状态为stale
1、原因
这个状态的PG没有被 ceph-osd 更新,表明存储这个 PG 的所有节点可能都 down 了。拥有 PG 拷贝的 OSD 可能会全部失败,这种情况下,那一部分的对象存储不可用, monitor 也就不会收到那些 PG 的状态更新了,这些pg就被标记为stale
2、解决方法
第一种:osd down了之后能正常起来,那只要启动
第二种:
1.使用命令ceph pg dump |grep stale找出stale的pg
2.使用命令ceph pg force_create_pg $pg_id,这时pg状态变为creating
3.重启集群中所有的osd
3、特殊说明
我当时是第二种情况,然后我按上面的步骤操作了。结果所有的osd启动都卡主了。我猜测可能原因:当时我force_create_pg的数量有3000个,这个数量有点多,所以osd就大量卡住了,很久很久才能启动,可能有几个小时。所以这个操作要慎重,建议如下
1、这个stale的pg最后处理
2、一次不要force_create_pg太多,osd重启时,一个重启成功之后,在重启另一个
九、PG状态为inconsistent
这个比较简单,直接执行命令:ceph pg repair $pg_id 修复
十、PG状态一直有peering和activating
说明集群中osd有问题,需要解决osd问题,我就是有3个osd问题,我out了这3个osd,这2个状态就很快消失了
十一、mon出现 store is getting too big
1、问题发现:ceph -s 或者mon进程死掉看到日志
2、产生原因
产生了大量的epoch,导致mon的store.db的数据极速膨胀。这个是我集群出现问题之后才出现的。我之前集群正常时没有这个现象。不知道等集群正常之后,会不会自己恢复正常。
3、解决方法
第一种:对数据进行压缩,使用命令 ceph tell mon.ceph163 compact (ceph163是我mon的名称) 。
第二种:使用
ceph-mon -i HOST --
compact
进行压缩启动 ,这里的host我使用的是ceph163,主机名称
说明:不管使用哪一种,
都要注意一点:操作压缩时,硬盘都会先扩大然后再缩小的,所以要留足空间。第二种的优势在于可以使修改ceph.conf中的参数mon_data=/data10/ceph153路径生效。我后来的mon数据太大了,我就更新路径到了数据盘:只要把对应的mon数据存数据mv到其他目录即可
第三种:等集群正常了,修改mon的配置参数试试(未验证,参数可以调小一些)
mon_min_osdmap_epochs=500
mon_max_pgmap_epochs=500
mon_max_mdsmap_epochs=500
4、特别注意:
默认当mon所在存储应硬盘剩余5%空闲时,mon进程会自杀。
十二、osd节点正常移除
将对应osd节点设置为out即可(osd进程依然存在),它会自动移除数据并把对应数据盘的数据删除,等到数据移除完毕,正常关闭删除osd即可
命令:ceph osd out osd.xx
十三、集群整体暂时关闭(比如要迁移机房)
当需要迁移服务器,需要关闭集群时,先设置ceph osd set nodown ceph osd set noup ceph osd set noout ceph osd set nobackfill ceph osd set norecover 保持集群不变,然后关闭各个osd,关闭mon,关闭rgw。
十四、集群出现问题时,常规操作命令
ceph osd set norebalance :禁止集群pg做从均衡,当出现问题时,可以设置,用于排查问题
ceph osd set nobackfill :禁止修复数据 backfill,当出现问题时,暂时不想修复数据,可以使用,配合nobackfill 一起使用
ceph osd set norecover :禁止修复数据 recover,当出现问题时,暂时不想修复数据,可以使用,配合nobackfill,一起使用
ceph osd set nodown :当集群出现问题,osd一会儿up,一个down的时候,可以使用这个命令,禁止osd down
ceph osd set noup :当集群出现问题,osd一会儿up,一个down的时候,可以使用这个命令,禁止osd up
ceph osd set noout :禁止集群中的osd自动因为长时间down,而out
ceph osd set nodeeep-scrub :不做深度处理
取消以上命令使用unset,比如ceph osd unset noout
ceph osd out osd.xx 设置单个osd的状态为out
ceph osd in osd.xx 设置单个osd的状态为in
ceph osd down osd.xx 设置单个osd的状态为down
ceph tell osd.xx injectargs --debug-osd 20 实时修改osd.xx的日志级别,不需要重启osd
ceph tell mon.xx injectargs --debug-mon 20 实时修改mon的日志级别,不需要重启mon
ceph tell osd.* injectargs --osd_recovery_sleep 1 单位秒,刚开始设置为1,怕服务器有压力,观察之后可以去掉设置为0
ceph tell osd.* injectargs --osd_max_backfills 1 调整恢复线程数,可以根据实际情况调整
ceph tell osd.* injectargs --osd_recovery_op_priority 60 调整恢复线程的级别
ceph daemon osd.xx status 查看osd.xx的状态,主要看osdmap版本号
ceph pg dump 查看所有的pg信息
ceph pg dump_stuck stale 查看pg状态为stale的数据
ceph pg dump_stuck inactive 查看pg状态为inactive的数据
ceph pg dump_stuck unclean 查看pg状态为unclean的数据
ceph -s 查看集群情况
ceph osd tree 查看osd状态树
ceph health detail 查看集群健康详情
ceph pg pg_id query 查看某个pg信息
ceph osd getmap -o osdmap.bin 查看osdmap图
ceph-dencoder type OSDMap import osdmap_197 decode dump_json 将osdmap导出成json格式
当前使用版本::ceph version 10.2.11(jewel)