3.方式三:
把 hdfs中文件夹中所有数据文件 导入到 某hive表中 或 某分区的hive中
格式一:load data inpath 'hdfs文件系统下绝对路径' [overwrite] into table 表名 partition(分区字段名='分区字段值');
格式二:load data inpath 'hdfs文件系统下绝对路径' [overwrite] into table 表名;
例子:load data inpath '/weblog/preprocessed/' overwrite into table ods_weblog_origin partition(datestr='20130918');
属性解析:
1.有LOCAL 表示从本地文件系统加载(文件会被拷贝到HDFS中)
2.无LOCAL 表示从HDFS中加载数据(注意:文件直接被移动,而不是拷贝,并且文件名都不带改的)
3.没有OVERWRITE 会直接APPEND,有OVERWRITE 表示是否覆盖表中数据(或指定分区的数据)
4.两种方式 把查询的数据导入到表中:
1.create table 表名 as select ...from 表名
2.insert into table 表名 select ...from 表名
insert overwrite table 表名 select ...from 表名 # overwrite 会覆盖表中原有的所有数据,没有overwrite 有into 表示追加
例子:insert into table 表名 select ...from (多行多列select ... from ...) a join 表名 b on a.字段=b.字段 and a.字段=b.字段
group by a.字段,a.字段 having a.字段=xx值 and a.字段 is not null and 聚合函数 order by a.字段 asc,a.字段 desc;
3.insert into table 表名 partition(分区字段名='分区字段值') select ...from 表名
insert overwrite table 表名 partition(分区字段名='分区字段值') select ...from 表名 # overwrite 会覆盖表中原有的所有数据,没有overwrite 有into 表示追加
3.查询表中数据:
“表”映射“结构化数据的文件中的”结构化数据
格式:select * from 表名;
select * from 表名 where 分区字段名='分区字段值';
select 表名.* from 表名 where 表名.分区字段名='分区字段值';
4.创建表时指定 分区字段:
1.单分区建表语句:
创表语句中只带有一个分区字段,那么hdfs文件系统中的完整路径是:/user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值
create table 表名(id int, 字段名 类型) partitioned by (分区字段名 类型) row format delimited fields terminated by '分隔符';
2.双分区建表语句:
创表语句中带有两个分区字段。
那么hdfs文件系统中的完整路径是:/user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值/分区字段名2=分区字段值
create table 表名(id int, 字段名 类型) partitioned by (分区字段名1 类型, 分区字段名2 类型) row format delimited fields terminated by '分隔符';
3.partitioned by (分区字段名 类型):
1.分区字段是虚拟的字段,分区字段不存在于结构化数据的文件中,但分区字段存在于表结构中。
2.创建表的同时带有分区字段的话,那么该表被称为分区表,并且会在hdfs文件系统中的“/user/hive/warehouse/数据库名.db/表名”目录下
创建名为“分区字段名=分区字段值”文件夹。
3.分区字段的作用:
“分区字段名=分区字段值”用于作为where子句中的查询条件。
辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
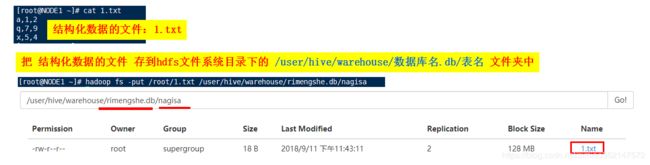
4.把结构化数据的文件存储到单分区表中:
即把结构化数据的文件存储到“/user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值/分区字段名2=分区字段值”的目录下
1.第一种方式:LOAD DATA local INPATH '结构化数据文件所在的绝对路径' INTO TABLE 表名 partition(分区字段名='分区字段值');
2.第二种方式:hdfs dfs -put /root/xx.txt /user/hive/warehouse/数据库名.db/表名/分区字段名=分区字段值
5.把结构化数据的文件存储到双分区表中:
即把结构化数据的文件存储到“/user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值”的目录下
1.第一种方式:LOAD DATA local INPATH '结构化数据文件所在的绝对路径' INTO TABLE 表名 partition(分区字段名1='分区字段值', 分区字段名2='分区字段值');
2.第二种方式:hdfs dfs -put /root/xx.txt /user/hive/warehouse/数据库名.db/表名/分区字段名1=分区字段值/分区字段名2=分区字段值
6.分区字段的查询:
“分区字段名=分区字段值”用于作为where子句中的查询条件。
如:select * from 表名 where 分区字段名='分区字段值';
select 表名.* from 表名 where 表名.分区字段名='分区字段值';
7.查看表中所有的分区:
show partitions 表名;
4.创建表时指定 分隔符:
1.格式:create table 表名(id int, 字段名 类型) partitioned by (分区字段名 类型) row format delimited fields terminated by '分隔符';
2.row format delimited fields terminated by '分隔符':
对应的是结构化数据中的分隔符。如果结构化数据中带有分隔符的话,那么创建表时也必须指定分隔符。
因为只有这样,结构化数据才能映射到表中,否则表中显示的数据都为null。
3.复杂类型的数据表指定分隔符
ROW FORMAT DELIMITED 每行中的分隔格式
[FIELDS TERMINATED BY char] 以某字符来分割每个字段值
[COLLECTION ITEMS TERMINATED BY char] Array数组中以某字符作为每个元素的分割符/以某字符来分割每个Map集合
[MAP KEYS TERMINATED BY char] Map集合中以某字符来作为键值对的分割符
[LINES TERMINATED BY char] 以某字符来分割每行
1.结构化数据如下:
zhangsan beijing,shanghai,tianjin,hangzhou
wangwu shanghai,chengdu,wuhan,haerbin
那么该表中创建分隔符的语句是:
create table 表名(name string,字段名 array) row format delimited fields terminated by '\t' collection items terminated by ',';
参数:
1.字段名 array:表示该字段的类型是array数组,该数组中的每个元素的类型是string,每个元素值是字符串
2.row format delimited fields terminated by '\t':每个字段值之间的分隔符是'\t'
3.collection items terminated by ',':
collection items 可把字段值数据转化为 Array数组 / Map集合。
此处字段值中的分隔符是',',那么由','进行分割出来的每个值作为数组中的元素值。
2.结构化数据如下:
1,zhangsan,唱歌:非常喜欢-跳舞:喜欢-游泳:一般般
2,lisi,打游戏:非常喜欢-篮球:不喜欢
那么该表中创建分隔符的语句是:
create table t_map(id int, name string, 字段名 map)
row format delimited fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;
参数:
1.字段名 map:表示该字段的类型是map集合,该map集合的key和value分别都是string
2.map keys terminated by ':'
Map集合中的键值对数据以':'作为分隔符,分割出key和value。
3.row format delimited fields terminated by ',':每个字段值之间的分隔符是','
4.collection items terminated by '-':
collection items 可把字段值数据转化为数组/Map集合。
此处字段值中的分隔符是'-',那么由'-'进行分割出来的每个值作为Map集合中的键值对。
3.本地模式:
# 设置本地模式(仅需当前机器)执行查询语句,不设置的话则需要使用yarn集群(多台集群的机器)执行查询语句
# 本地模式只推荐在开发环境开启,以便提高查询效率,但在生产上线环境下应重新设置为使用yarm集群模式
set hive.exec.mode.local.auto=true;
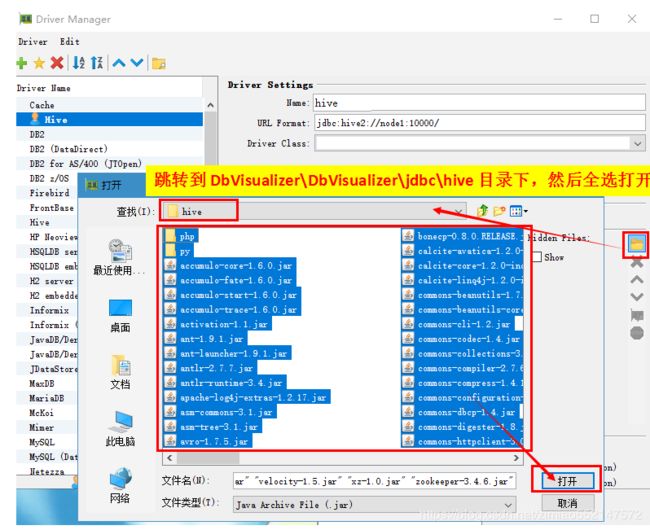
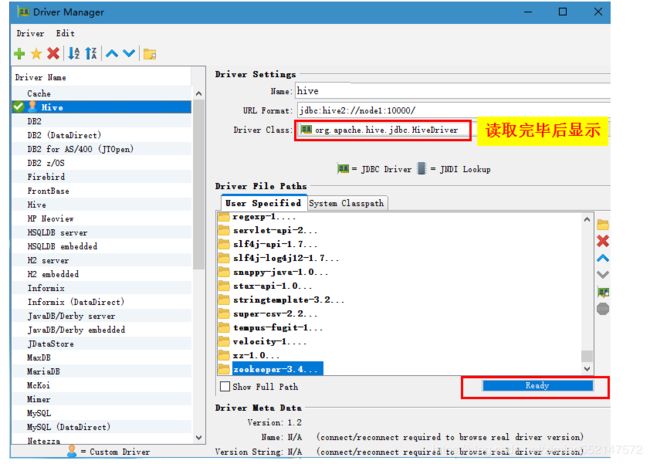
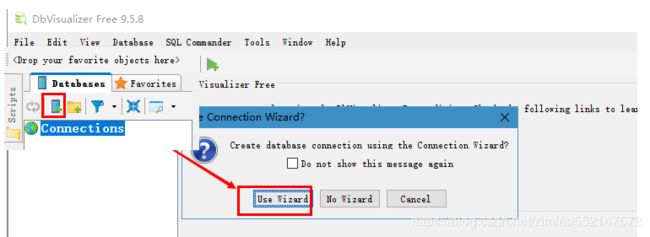
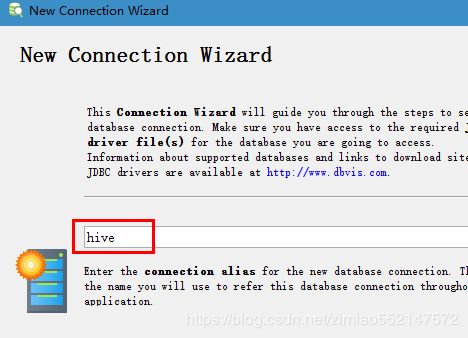
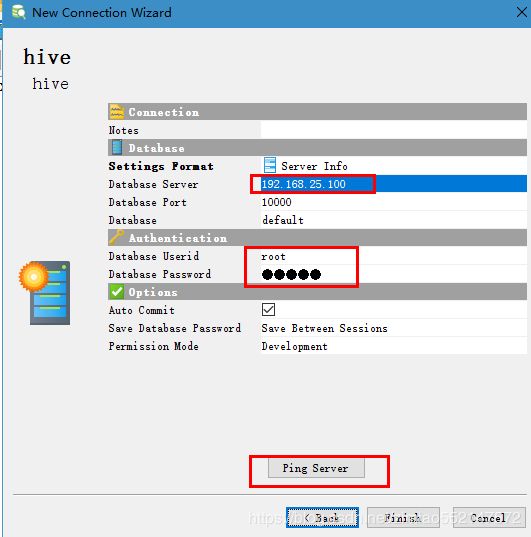
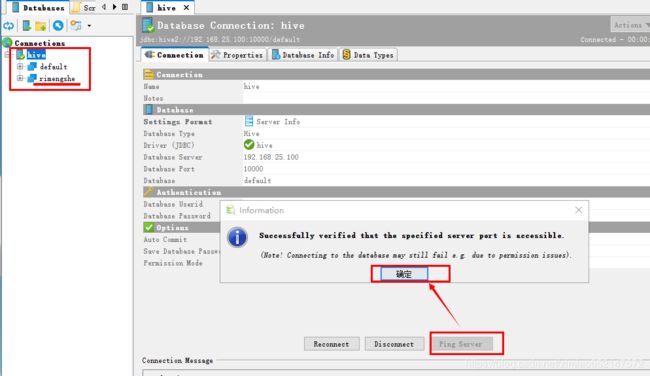
4.bVisualizer 连接Hive软件的使用:
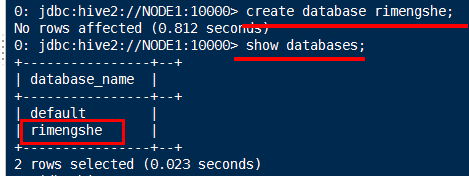
show databases;
use rimengshe;
show tables;
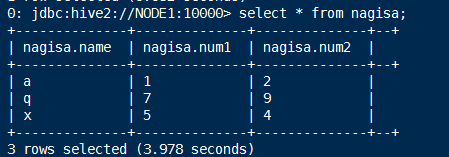
select * from nagisa;
# 设置本地模式(仅需当前机器)执行查询语句,不设置的话则需要使用yarn集群(多台集群的机器)执行查询语句
# 本地模式只推荐在开发环境开启,以便提高查询效率,但在生产上线环境下应重新设置为使用yarm集群模式
set hive.exec.mode.local.auto=true;
select count(*) from nagisa;
5.分桶字段、分桶表:
1.分桶表 创建之前 需要开启分桶功能
2.分桶表(分簇表)创建的时候 分桶字段必须是表中已经存储(存在)的字段
3.分桶表数据的导入方式insert+select语句,实际是插入的数据来自查询的结果,查询的时候执行(Yarn集群)MR程序,如果是spark集群整合了hive的话,
则执行insert+select语句时执行的不再是(Yarn集群)MR程序,执行的而是spark job,效率比(Yarn集群)MR程序还高。
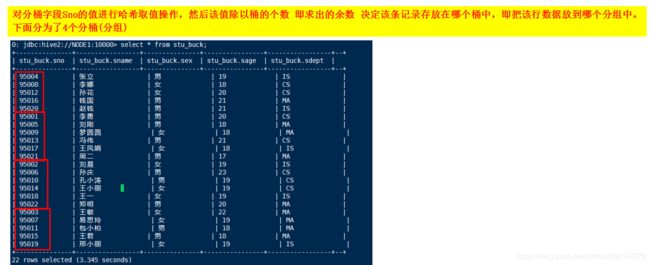
4.分桶的规则原理:Hive 采用对分桶字段值进行哈希取值操作,然后该值除以桶的个数 即求出的余数 决定该条记录存放在哪个桶中,即把该行数据放到哪个分组中。
5.分桶表和分桶字段的使用:针对join的连接字段进行分桶操作,即把join的连接字段作为分桶字段
6.分桶的好处:
如果多行数据中的join连接字段值都相同的话,那么通过分桶操作后(join的连接字段作为分桶字段),根据分桶的规则原理,
该多行数据都会被一起放进同一个分组(分桶)中,那么当两张表进行join连接操作时,只针对表对应的“列值(join连接字段值)相同的”分组数据(分桶数据)进行连接,
不需要对全表数据查找判断,减少join的操作量,从而提高效率。
1.分桶设置
1.查看分桶设置:
set hive.enforce.bucketing; # 查看是否开启分桶机制
set mapreduce.job.reduces; # 查看分桶数量
2.设置开启分桶(注意每次重新连接都需要重新开启分桶,因为每次断开连接后配置都会失效)
set hive.enforce.bucketing = true;
set mapreduce.job.reduces = 分桶数量;
# 设置分桶数量:代表整张表数据会被分为多少份,同时“/user/hive/warehouse/数据库名.db/表名”的文件夹下便会生成多少份文件
2.分桶表 和 分桶字段的创建:
1.按照分桶字段值的哈希值,把表数据分为N组:
create table 表名(字段1 类型, 字段2 类型)
clustered by(分桶字段)
into 分桶数量 buckets
row format delimited fields terminated by '分隔符';
例子:
1.先执行:use 数据库名;
2.分桶表 和 分桶字段的创建:同时自动创建出“/user/hive/warehouse/stu_buck”文件夹
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string)
clustered by(Sno)
into 4 buckets
row format delimited fields terminated by ',';
3.show tables;
4.把结构化数据文件导入到表中所在的路径下:格式一 和 格式二 作用相同
格式一:LOAD DATA local INPATH '结构化数据文件所在的绝对路径' INTO TABLE 表名;
格式二:hadoop fs -put 本地结构化数据文件所在路径 hdfs文件系统中“表”所在路径;
此处例子:LOAD DATA local INPATH '/root/hivedata/students.txt' INTO TABLE stu_buck;
10.创建ORC表、查看ORC的文件元数据
1.创建ORC表:
1.CREATE TABLE 表名lxw1234_orc1 (
id INT,
name STRING
) stored AS ORC; # hive创建表时stored as orc:指定hive表存储文件的格式。一般默认为txt格式。
2.通过INSERT + SELECT 把查询数据插入到ORC表lxw1234_orc1中
INSERT overwrite TABLE 表名lxw1234_orc1
SELECT CAST(siteid AS INT) AS id, pcid
FROM 表名lxw1234_text
limit 10;
注意:CAST( 字段 AS 目标数据类型)函数的参数是一个表达式,它包括用AS关键字分隔的源值和目标数据类型。
以下例子用于将文本字符串'12'转换为int整型:SELECT CAST('12' AS int)
3.查询ORC表lxw1234_orc1:SELECT * FROM lxw1234_orc1 ORDER BY id;
查询数据如下:
139 89578071000037563815CC
139 E811C27809708556F87C79
633 82E0D8720C8D1556C75ABA
819 726B86DB00026B56F3F151
1134 8153CD6F059210539E4552
1154 5E26977B0EEE5456F7E7FB
1160 583C0271044D3D56F95436
1351 FA05CFDD05622756F953EE
1351 16A5707006C43356F95392
1361 3C17A17C076A7E56F87CCC
2.查看ORC的文件元数据
1.ORC表lxw1234_orc1对应的HDFS文件为:/hivedata/warehouse2/lxw1234_orc1/000000_0
新版本的Hive中提供了更详细的查看ORC文件信息的工具 orcfiledump。
执行命令 格式:./hive –orcfiledump -j -p ORC表对应的HDFS文件的绝对路径
例子:./hive –orcfiledump -j -p /hivedata/warehouse2/lxw1234_orc1/000000_0
返回一段JSON,将其格式化后:
11.ORC查询优化
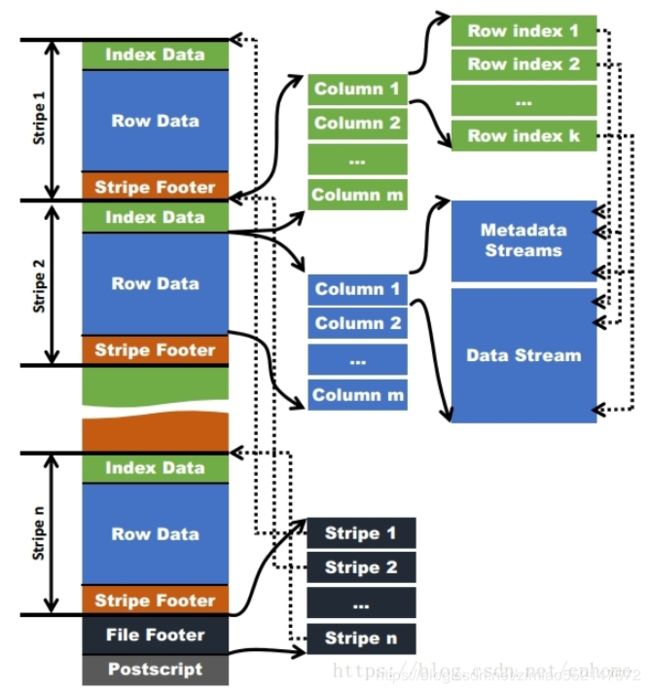
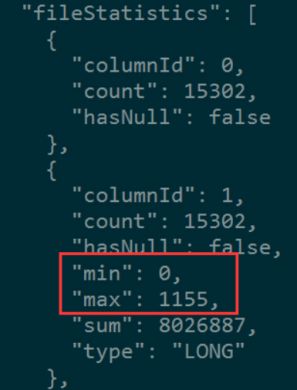
1.经过上面ORC文件的元数据 了解了一个 ORC文件会被分成多个stripe,而且ORC文件的元数据中有每个字段的统计信息(min/max,hasNull等等),
这就为ORC的查询优化做好了基础准备。假如我的查询过滤条件为 WHERE id = 0 在Map Task读到一个ORC文件时,首先从ORC文件的统计信息中看看id字段的min/max值,
如果0不包含在内,那么这个文件就可以直接跳过了。
2.基于这点,还有一个更有效的优化手段是在数据入库的时候,根据id字段排序后入库,这样尽量能使id=0的数据位于同一个文件甚至是同一个stripe中,
那么在查询时候,只有负责读取该文件的Map Task需要扫描文件,其他的Map Task都会跳过扫描,大大节省Map Task的执行时间。
海量数据下,使用SORT BY 排序字段id ASC/DESC可能不太现实,另一个有效手段是使用DISTRIBUTE BY 分桶字段id SORT BY 排序字段id ASC/DESC;
3.使用下面的HQL构造一个较大的ORC表进行ORC查询优化:
1.# hive创建表时stored as orc:指定hive表存储文件的格式。一般默认为txt格式。
CREATE TABLE 表名lxw1234_orc2 stored AS ORC
AS SELECT CAST(siteid AS INT) AS id, pcid
FROM 表名lxw1234_text DISTRIBUTE BY 分桶字段id SORT BY 排序字段id ASC/DESC;
2.该分桶字段+排序字段的语句保证相同的id位于同一个ORC文件中,并且是排序的。
SELECT DISTINCT INPUT__FILE__NAME FROM ORC表lxw1234_orc2 WHERE id = 0;
id=0的数据只存在于这一个ORC文件(hdfs://cdh5/hivedata/warehouse2/lxw1234_orc2/000000_0)中,而这个ORC表lxw1234_orc2有 33个ORC文件。
3.也可以通过命令查看文件的统计信息:
格式:./hive –orcfiledump -j -p ORC表对应的HDFS文件的绝对路径
例子:./hive –orcfiledump -j -p hdfs://cdh5/hivedata/warehouse2/lxw1234_orc2/000000_0
查询出的文件信息:
该文件中id的最小值为0,最大值为1155。因此,对于HQL查询”SELECT COUNT(1) FROM ORC表lxw1234_orc2 WHERE id = 0”,
优化器在执行时候,只会扫描这一个文件,其他文件都应该跳过。
4.在验证之前,先介绍一个参数:hive.optimize.index.filter,是否自动使用索引,默认为false(不使用);
如果不设置该参数为true,那么ORC的索引当然也不会使用。
在Hive中执行 set hive.optimize.index.filter=true; # 设置该参数为true,启用ORC的索引
执行查询:SELECT COUNT(1) FROM ORC表lxw1234_orc2 WHERE id = 0;
查看日志信息:该查询一共有13个MapTask,找到包含/hivedata/warehouse2/lxw1234_orc2/000000_0的MapTask进行查看,然后查看其它MapTask,均没有扫描记录的日志。
不使用索引,再执行一次:
设置不使用索引,HIVE中执行:set hive.optimize.index.filter=false;
执行查询:SELECT COUNT(1) FROM ORC表lxw1234_orc2 WHERE id = 0;
再查看日志时,每个MapTask中都有扫描记录的日志,说明每个MapTask都对自己的分片进行了扫描。
两次执行,MapTask的执行时间也能说明问题。
由此可见,Hive中的ORC不仅仅有着高压缩比,很大程序的节省存储空间和计算资源,而且在其上还做了许多优化(这里仅仅介绍了row_index)。
如果使用Hive作为大数据仓库,强烈建议主要使用ORC文件格式作为表的存储格式。
==========Hive数据导入方案—使用ORC格式存储hive数据============
1.目的:将上网日志导入到hive中,要求速度快,压缩高,查询快,表易维护。推荐使用ORC格式的表存储数据
2.思路:因为在hive指定 RCFILE(升级版为ORC FILE)格式的表,不能直接load数据到RCFILE(升级版为ORC FILE)格式的表中,
只能通过对text file表进行insert + select插入“查询数据”到 RCFILE(升级版为ORC FILE)格式的表中。
考虑先建立text File格式内部临时表tmp_testp,使用hdfs fs -put命令向tmp_testp表路径拷贝数据(不是load),再建立ORC格式外部表http_orc,
使用insert + select命令把text File格式内部临时表tmp_test表数据 导入到 ORC格式外部表http_orc中,最后删除掉临时表数据。过程消耗的时间。
3.优化方案:如何提高hdfs文件上传效率
1.文件不要太大(测试用文件从200m到1G不均),启动多个客户端并行上传文件
2.考虑减少hive数据副本为2
3.优化mapReduce及hadoop集群,提高I/O,减少内存使用
3.执行:
1.建立text File格式的内部临时表,使表的location关联到一个日志文件的文件夹下:
create table IF NOT EXISTS tmp_testp(p_id INT,tm BIGINT,idate BIGINT,phone BIGINT)
partitioned by (dt string)
row format delimited fields terminated by '\,'
location '/hdfs/incoming';
2.通过hdfs上传文件124G文件,同时手动建立分区映射关系来导入数据。
给text File格式的内部临时表 添加分区:ALTER TABLE tmp_testp ADD PARTITION(dt='2013-09-30');
把源数据文件上传到内部临时表中的分区文件夹中:hadoop fs -put /hdfs/incoming/*d /hdfs/incoming/dt=2013-09-30
记录耗时:上传速度缓慢,内存消耗巨大
12:44 - 14:58 =两小时14分钟
Mem: 3906648k total, 3753584k used, 153064k free, 54088k buffers
内存利用率96%
3.测试text File格式的内部临时表是否可以直接读取数据
select * from tmp_testp where dt='2013-09-30';
4.建立ORC格式的外部表
create external table IF NOT EXISTS http_orc(p_id INT,tm BIGINT,idate BIGINT,phone BIGINT )
partitioned by (dt string)
row format delimited fields terminated by '\,'
stored as orc; # hive创建表时stored as orc:指定hive表存储文件的格式。一般默认为txt格式。
5.通过insert + select 方式将text File格式的内部临时表中数据 导入到 ORC格式的外部表中
insert overwrite table http_orc partition(dt='2013-09-30') select p_id,tm,idate,phone from tmp_testp where dt='2013-09-30';
记录耗时:Time taken: 3511.626 seconds = 59分钟,
注意:insert这一步,可以选择字段导入到orc表中,达到精简字段,多次利用临时表建立不同纬度分析表的效果,不需要提前处理原始log文件,
缺点是上传到hdfs原始文件时间太长
6.计算ORC表压缩率:
HDFS Read: 134096430275 HDFS Write: 519817638 SUCCESS
压缩率:519817638/134096430275=0.386% 哎呀,都压缩没了
7.删除text File格式的内部临时表,保证hdfs中只存一份ORC压缩后的文件
drop table tmp_testp;
8.简单测试一下ORC压缩表操作看看,ORC压缩表与txtFile不压缩表的性能对比
1.ORC格式的外部表执行:select count(*) from http_orc;
结果:469407190 Time taken: 669.639 seconds, Fetched: 1 row(s)
2.text File格式的内部临时表执行:select count(*) from tmp_testp;
结果:469407190 Time taken: 727.944 seconds, Fetched: 1 row(s)
3.结论:ORC效果不错,比text File效果好一点点。平均每s上传文件:124G / (2hour14min+59min)= 11M/s。可以清楚看到向hdfs上传文件浪费了大量时间。
============ hive表的源文件存储格式 ============
1.hive表的源文件存储格式有几类:
1.TEXT FILE
默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。源文件可以直接通过hadoop fs -cat 查看
2.SEQUENCE FILE
1.一种Hadoop API提供的二进制文件,使用方便、可分割、可压缩等特点。
SEQUENCEFILE将数据以的形式序列化到文件中。序列化和反序列化使用Hadoop 的标准的Writable 接口实现。
key为空,用value 存放实际的值,这样可以避免map 阶段的排序过程。
2.三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
使用时设置参数:
1.SET hive.exec.compress.output=true;
2.SET io.seqfile.compression.type=BLOCK; # 可以是 NONE/RECORD/BLOCK
3.create table test2(str STRING) STORED AS SEQUENCEFILE;
3.RC FILE
1.一种行列存储相结合的存储方式。
首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
理论上具有高查询效率(但hive官方说效果不明显,只有存储上能省10%的空间,所以不好用,可以不用)。
2.RCFile结合行存储查询的快速和列存储节省空间的特点
1.同一行的数据位于同一节点,因此元组重构的开销很低;
2.块内列存储,可以进行列维度的数据压缩,跳过不必要的列读取。
3.查询过程中,在IO上跳过不关心的列。实际过程是,在map阶段从远端拷贝仍然拷贝整个数据块到本地目录,也并不是真正直接跳过列,
而是通过扫描每一个row group的头部定义来实现的。但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。
所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
4.ORC FILE(RCFILE的升级版)
hive给出的新格式,属于RCFILE的升级版。
2.自定义格式
用户的数据文件格式不能被当前 Hive 所识别的,通过实现inputformat和outputformat来自定义输入输出格式
2.只有TEXT FILE表能直接加载数据,必须本地load数据,和external外部表直接加载运路径数据一样,都只能用TEXT FILE表。
更深一步,hive默认支持的压缩文件(hadoop默认支持的压缩格式),也只能用TEXT FILE表直接读取。其他格式不行。可以通过TEXT FILE表加载后insert到其他表中。
换句话说,Sequence File、RC File、ORC File表不能直接加载数据,数据要先导入到TEXT FILE表,再通过insert + select 把TEXT FILE表 导入到 Sequence File、RC File、ORC File表。
Sequence File、RC File、ORC File表的源文件不能直接查看,而是在hive中用select看。
RCFile源文件可以用 hive --service rcfilecat /xxxxxxxxxxxxxxxxxxxxxxxxxxx/000000_0查看,但是格式不同,很乱。
3.ORC FILE格式(RCFILE的升级版)
ORC是RCfile的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩比和Lzo压缩差不多,比text文件压缩比可以达到70%的空间。而且读性能非常高,可以实现高效查询。
4.ORC FILE表的创建:
1.方式一
1.create table if not exists test_orc( advertiser_id string, ad_plan_id string, cnt BIGINT )
partitioned by (day string, type TINYINT COMMENT '0 as bid, 1 as win, 2 as ck', hour TINYINT)
STORED AS ORC;
2.alter table test_orc set serdeproperties('serialization.null.format' = '');
1.在hive里面默认的情况下会使用’/N’来表示null值,但是这样的表示并不符合我们平时的习惯。
所以需要通过serialization.null.format的设置来修改表的默认的null表示方式。
2.例子1:没有指定serialization.null.format,在查询时NULL值数据被转写成’/N’显示
CREATE TABLE 表名(id int,name STRING) STORED AS TEXTFILE;
查看表对应的hdfs的文件中数据:hadoop fs -cat /xx/表名/attempt_201105020924_0011_m_000000_0
id name
/N mary
101 tom
3.例子2:指定serialization.null.format,在查询时NULL值没有被转写成’/N’,而是以空字符串显示NULL值
CREATE TABLE 表名(id int,name STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
WITH SERDEPROPERTIES ( field.delim’='/t’, ‘escape.delim’='//’, ‘serialization.null.format’='' )
STORED AS TEXTFILE;
查看表对应的hdfs的文件中数据:hadoop fs -cat /xx/表名/attempt_201105020924_0011_m_000000_0
id name
mary
101 tom
3.hive中空值判断基本分两种
1.NULL 与 \N
1.hive在底层数据中如何保存和标识NULL,是由 alter table name SET SERDEPROPERTIES('serialization.null.format' = '\N') 参数控制的。
在hive里面默认的情况下会使用’/N’来表示null值。
2.设置 alter table name SET SERDEPROPERTIES('serialization.null.format' = '\N');
则底层数据保存的是'NULL',通过查询显示的是'\N'
这时如果查询为空值的字段可通过 语句:a is null 或者 a='\\N'
3.设置 alter tablename SET SERDEPROPERTIES('serialization.null.format' = 'NULL');
则底层数据保存的是'NULL',通过查询显示的是'NULL'
这时如果查询为空值的字段可通过 语句:a is null 或者 a='NULL'
4.设置 alter tablename SET SERDEPROPERTIES('serialization.null.format' = '');
则底层数据保存的是'NULL',通过查询显示的是空字符串''
这时如果查询为空值的字段可通过 语句:a is null
2.空字符串'' 与 length(xx)=0
空字符串'' 表示的是字段不为null且为空字符串,此时用 a is null 是无法查询这种值的,必须通过 a=''或者 length(a)=0 查询
3.查看结果
hive> show create table test_orc;
CREATE TABLE `test_orc`(
`advertiser_id` string,
`ad_plan_id` string,
`cnt` bigint)
PARTITIONED BY (
`day` string,
`type` tinyint COMMENT '0 as bid, 1 as win, 2 as ck',
`hour` tinyint)
ROW FORMAT DELIMITED
NULL DEFINED AS ''
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://namenode/hivedata/warehouse/pmp.db/test_orc'
TBLPROPERTIES (
'last_modified_by'='pmp_bi',
'last_modified_time'='1465992624',
'transient_lastDdlTime'='1465992624')
2.方式二
1.drop table test_orc;
2.create table if not exists test_orc( advertiser_id string, ad_plan_id string, cnt BIGINT )
partitioned by (day string, type TINYINT COMMENT '0 as bid, 1 as win, 2 as ck', hour TINYINT)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
with serdeproperties('serialization.null.format' = '') # 表示查询出NULL值数据时显示为空字符串
STORED AS ORC;
3.查看结果
hive> show create table test_orc;
CREATE TABLE `test_orc`(
`advertiser_id` string,
`ad_plan_id` string,
`cnt` bigint)
PARTITIONED BY (
`day` string,
`type` tinyint COMMENT '0 as bid, 1 as win, 2 as ck',
`hour` tinyint)
ROW FORMAT DELIMITED
NULL DEFINED AS ''
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://namenode/hivedata/warehouse/pmp.db/test_orc'
TBLPROPERTIES (
'transient_lastDdlTime'='1465992726')
3.方式三
1.drop table test_orc;
2.create table if not exists test_orc( advertiser_id string, ad_plan_id string, cnt BIGINT )
partitioned by (day string, type TINYINT COMMENT '0 as bid, 1 as win, 2 as ck', hour TINYINT)
ROW FORMAT DELIMITED NULL DEFINED AS '' # 表示查询出NULL值数据时显示为空字符串
STORED AS ORC;
3.查看结果
hive> show create table test_orc;
CREATE TABLE `test_orc`(
`advertiser_id` string,
`ad_plan_id` string,
`cnt` bigint)
PARTITIONED BY (
`day` string,
`type` tinyint COMMENT '0 as bid, 1 as win, 2 as ck',
`hour` tinyint)
ROW FORMAT DELIMITED
NULL DEFINED AS ''
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://namenode/hivedata/warehouse/pmp.db/test_orc'
TBLPROPERTIES (
'transient_lastDdlTime'='1465992916')
show databases;
use rimengshe;
show tables;
select * from nagisa;
set hive.exec.mode.local.auto=true; # 设置本地模式(仅需当前机器)执行查询语句,不设置的话则需要使用yarn集群(多台集群的机器)执行查询语句
select count(*) from nagisa;
package spark.examples.scala.grammars.caseclasses
object CaseClass_Test00 {
def simpleMatch(arg: Any) = arg match {
case v: Int => "This is an Int"
case v: (Int, String)
 日萌社
日萌社