国产数据库岁末大盘点
笔者长年在金融机构工作,虽然现在已恍如隔世,不过当笔者做为一名金融IT人,提起对外技术依赖时就不能不说起我们的银行业的核心-支付系统(CNAPS),其实都是世界银行的援建产物,甚至直到2013年底,我们才用自研二代支付系统将其取代。

不过现在我们的移动支付水平之高,已经到了独步世界的程度。而近日,金山办公正式登陆科创版,圆了雷军和金山所有员工20年的自主创新“英雄梦”。可以看到这种应用级别的自主掌控对于我国已经不是难事了。而这也反应出近年来我国IT的一个现象,那就是应用模式创新多,但是基础领域突破少。
去 IOE”这个概念,最早由阿里的王坚院士首先提出,目标是将阿里IT 体系中去掉 IBM 的小型机、Oracle 数据库、EMC 存储设备,代之以自主研发的系统。而随着我国IT技术栈的不断演进,去IOE已经由一个企业的目标,变成了整个行业的目标,也就是我国必须将数据安全运行在自研系统之上,以防止数据丢失造成的一系列严重后果。
虽然国产数据库相比前几年大火的O2O、共享经济等概念并没有获得资本的大力追捧,但是我们还是欣喜的看到依旧有很多IT人始终坚持此道。前几天的大数据大会(BDTC)上,笔者遇到了涛思的陶建辉、天元数据的雷涛等业内前辈专家,接下来就带大家一起来盘点一下国产数据库的发展现状。
完全自研的OceanBase
OceanBase 是蚂蚁金服自研的金融级分布式关系数据库,号称每一行代码都是自主编写的。由于Oracle数据库并不能满足阿里在促销时的并发场景需求,所以阿里的IT人决定自主研发一款分布式金融级数据库,在普通硬件上实现金融级高可用,在金融行业首创“三地五中心”城市级故障自动无损容灾新标准,同时具备在线水平扩展能力,创造了 4200 万次/秒处理峰值的纪录。笔者在《200 行代码解读国产数据库阿里 OceanBase 的速度源头!》以及《揭秘 OceanBase 勇夺 TPC 榜首的王者攻略!》曾经详细介绍过OceanBase数据库的技术构架,这里就不同志赘述了。
深植于场景需求混布数据库Hubble
Hubble是天元数据研发的HTAP数据产品。所谓HTAP其实就是混合了TP和AP两种模式的数据库。
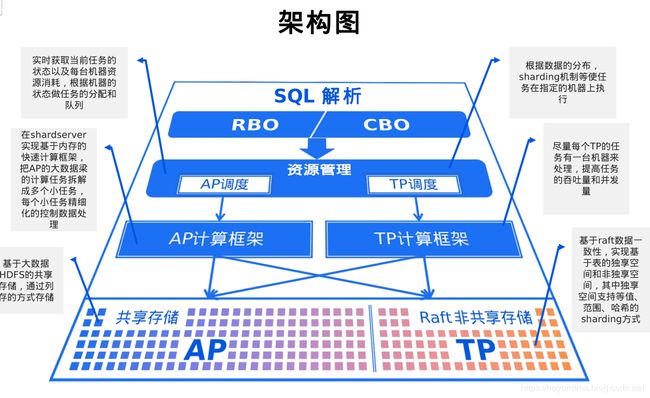
坦率的讲笔者在刚开始听到一种产品既能提供TP服务又提能供AP服务时,感到的非常的惊讶。因为我们知道OLAP(On-Line Analytical Processing)是指联机分析技术,打个比方来说OLAP就像是私人飞机服务,不计较成本但是非常在意响应速度,主要用于用户联机交易的处理响应。而OLTP(on-line transaction processing,则是指联机事务处理,而OLTP的最大诉求就是低成本的处理海量数据,有点像海上运输,虽然处理数据量大但是速度慢,适合于客户历史帐单查询、客户画像分析等大数据方面的应用。
以前AP应用的流程比较固定,就像一个仪表盘,只有一两个数仓的管理员在看,但现在原来投在大屏的可视化项目,全部被推送到了移动端,这也就是TP+AP的个性化数字仓库的需求。比如一个营业厅应用有六万多人,同时在线需要至少五百个并发/秒,理财经理要在某一时刻看到大客户的结息、净值等一系列的数据服务,且都是个性化的。所以这也就意味着目前在应用领域有强烈的需求把AP推到TP的场景里,使这两者有机结合,不过这对于大多数人来说还只是个想法。不过这两个看似矛盾的目标竟然真的被天元数据结合到一起了。其关键技术有以下几个方面:
一是在KV数据再加一层KV索引以适应高并发的TP需求。

二是通过将全局事务向本地事务锁进行转换保证系统的分布式计算一致性。

三是通过资源控制模块完成TP与AP的结合使用
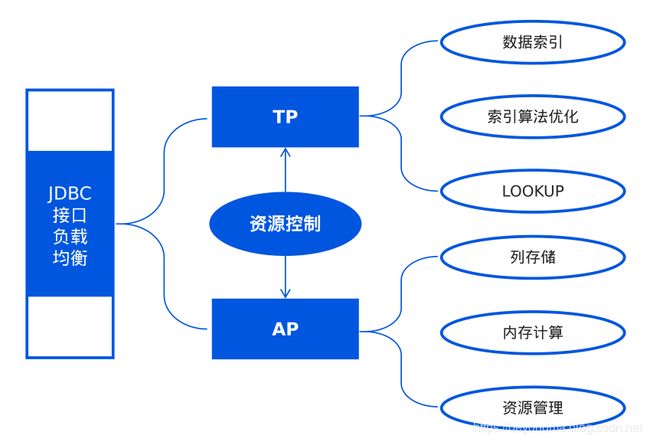
Hubble的很多设计都非常有意思,后续有机会再和各位读者再详聊一下这款HTAP产品的设计思路。
SQL引擎与 NoSQL存储的结合-巨杉数据库
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,也是一款开源产品(Github地址:https://github.com/SequoiaDB/SequoiaDB)。笔者认为Sequoiadb最大的贡献在于将标准SQL、事务与NoSQL的分布式存储相结合。巨杉数据库使用JSON为标准存储格式,既可以描述关系型结构,最大限度保留现有的应用资产;也可以描述非关系型结构。同时这也使巨彬可以把非结构化的文件和结构化的描述项一起存储,而不是索引+文件存储;适当降低范式维度,降低JOIN操作的复杂度。而且在分布式存储的基础上,还添加了分布式SQL引擎,提供高并发、低延时和批量计算SQL能力以及ACID和事务支持。
其整体架构如下:
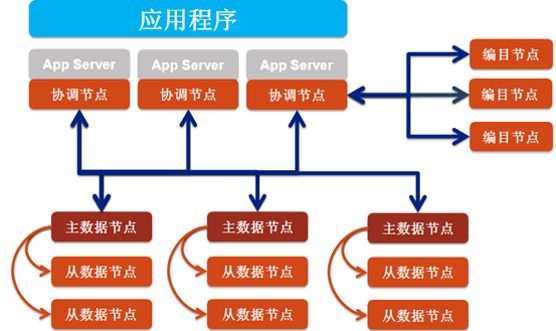
其中协调节点:负责调度、分配、汇总,是SequoiaDB的数据分发节点,本身不存储任何数据,主要负责接收应用程序的访问请求
编目节点:负责存储整个数据库的部署结构与节点状态信息,并且记录集合空间与集合的参数信息,同时记录每个集合的数据切分状况
数据节点:承载数据存储、计算的进程,提供高性能的读写服务,且在多索引的支持下针对海量数据查询性能优越。多个数据节点可以组成一个数据节点组,根据选举算法自动选择一个主数据节点,其余节点为备数据节点。
巨彬数据库在金融领域应用案例很多,相信他们SQL引擎与 NoSQL存储的理念还会支撑他们越走越远。
产品线齐全的数据库Gbase和达梦
武汉达梦和天津南大通用绝对是国内数据库的产品线最齐全的两家厂商了。据笔者不完全统计,他们南大通用打造了GBase 8a、8t、8m、8s、8d、UP、InfiniData一体机等多款数据库软硬件产品,而达梦也不遑多让他们打造了达梦7、8、ETL、TDD、HS、MPP等多款产品。我们下面挑重点向大家介绍。
GBase 8a:就是我们日常所熟知的用于大数据分析的系统库。
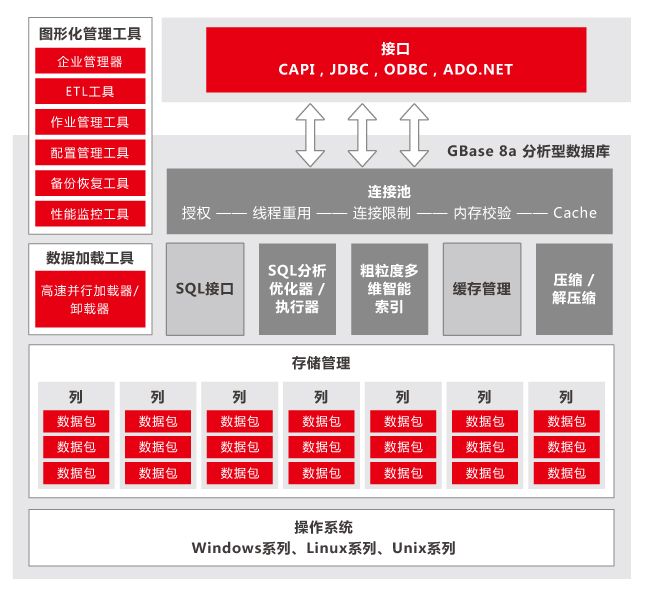
GBase 8a能够实现大数据存储管理和高效分析,据测试能在PB级数据规模下实现数据查询的秒级响应;实现千亿级文本条目全文检索的秒级响应;并且提供全过程可视化的数据查询分析及展现工具。
GBase 8t:一款对标Oracle的数据库。据称其OLTP事务处理性能已达到Oracle数据库的水平,能够在90%以上的场景中替代Oracle。

其关键技术有如下几方面:
一、事务机制:完全支持传统主流事务数据库的事务机制锁技术,有效支撑高度并发的事务密集型应用场景。
二、存储技术:GBase 8t产品的存储有物理的和逻辑的两种结构。物理结构中包含数据卷(Chunk)、数据段(Extent)和数据页(Page);逻辑结构包含数据空间(DbSpace)和表空间(TableSpace)。连接的数据页组成一个数据段,同一个数据段中存储同一个数据库表的数据,数据段中包含的数据页可以在创建表时指定。数据卷是存储数据的连续空间,一个数据卷可以是一个裸设备或者一个Unix文件。一个数据空间中可以包含一个或者多个数据卷。表空间是同一个数据库表的所有数据段(可能分布在不同的数据卷上)的逻辑集合。
三、索引技术:GBase 8t产品提供了索引技术来提升数据查询操作的性能。GBase 8t产品支持的索引包括B-Tree索引、R-Tree索引、函数索引和用户自定义索引,同时,为进一步提升大数据量下的查询性能,GBase 8t产品还在B-Tree索引基础上提供了FOT(森林树)索引。
四、高可用技术:GBase 8t产品提供了高可用集群技术,使用这些技术可以满足数据复制、共享存储、同城备份、远程容灾和两地三中心的整体灾备解决方案的要求。GBase 8t高可用集群提供了连接管理器(Connection Manager)部件,为高可用集群提供了按需服务、负载均衡和透明的故障接管能力。
达梦大型通用数据库管理系统(DM7):同时支持OLTP与OLAP的数据库,这一点上与我们之前介绍的天元的HUBBLE数据库比较类似,其架构如下,具体就不再赘述了。

Gbase和达梦的产品均已经在金融、电信、电力等多个行业得到应用与验证了,使用场景非常广泛可谓我国国产数据库的双子星座了。
物联网时代的数据库TDEngine、CTSDB
随着互联网的高速发展、大数据的迅速膨胀和物联网的飞速崛起,我们发现生活和工作中的大部分数据渐渐和时间产生了关联。比如微信运动的实时步数、股票每天的收盘价格、共享单车的设备状态等等。为了存储这些与时间相关的数据使用传统数据库其实问题很多。
比如传统关系型数据库在存储海量的时序数据场景下存在如下问题
-
- 存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
- 维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
- 写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
- 查询性能差:适用于交易处理,海量数据的聚合分析性能差。
而Hadoop等NoSQL数据库也有问题
-
- 数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
- 查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
有关TDEngine的内容的内容笔者《这位创造GitHub冠军项目的“老男人”,堪称10倍程序员本尊》、《巨头垂涎却不能染指,loT 数据库风口已至》已经做过详细介绍,也不加赘述了。
这里主要带大家了解一下腾讯时序数据库CTSDB:CTSDB(Cloud Time Series Database)是一种分布式、高性能、多分片、自均衡的时序数据库,针对时序数据的高并发写入、存在明显的冷热数据、IoT用户场景等做了大量优化,同时也支持各行业的日志解析和存储,其架构如下图所示。
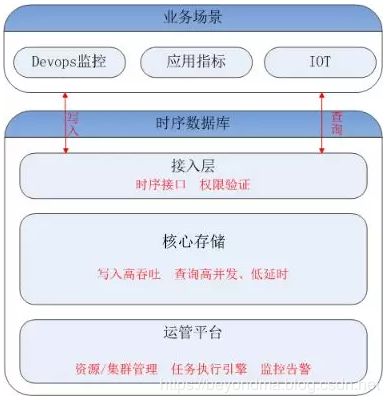
CTSDB的技术亮点:
1、高性能:支持批量写入、高并发查询;通过集群扩展,随时线性提升系统性能;支持sharding、routing,加速查询。
2) 高可靠:支持多副本;机架感知,自动错开机架分配主从副本。
3) 易使用:丰富的数据类型,REST接口,数据写入查询均使用json格式;原生分布式,弹性可伸缩,数据自动均衡;
4) 低成本:支持列存储,高压缩比(0.1左右),降低存储成本;支持数据预降精度:降低存储成本的同时,提高查询性能。
CTSDB的处理请求的流程:
在CTSDB和磁盘之间有一层FileSystem Cache的系统缓存,以使得能够更快地处理搜索请求。插入请求到来时document会先被放入到indexing buffer,然后被重写为一个segment直接写入到filesystem cache,这个操作是非常轻量级的,相对耗时较少,之后经过一定的间隔或外部触发后才会被flush到磁盘上,这个操作非常耗时。但只要sengment文件被写入cache后就可以被打开和查询,在短时间内就可以搜到,而不用执行一个flush也就是fsync操作。其请求处理流程如下图:

作为腾讯唯一的时序数据库,CTSDB支撑了腾讯内部20多个核心业务(微信彩票、财付通、云监控、云数据库、云负载等)。其中,云监控系统的记录了腾讯内部各种软硬件系统的实时状态,CTSDB承载了它所有的数据存储,在每秒千万级数据点的写入压力、每天20TB+数据量的写入场景下稳定运行,足以证明CTSDB可以稳定支撑物联网的海量数据场景。