嘘,你抢的不是红包而是云
最近疫情的消息稳定占据新闻版面的头条位置,站在技术角度笔者也发了一篇博客来说明面对疫情,AI能做什么。但是从技术角度上讲今年的春节还有一大看点,就是红包大战了。
堪称是新春佳节中最精彩的开年大戏,2015年腾讯以超过5000万元的天价拿下央视春晚独家合作权,一夜之间为微信支付带来1亿多张新增银行卡绑定,仅用一天就完成了支付宝几年走过的道路,被马云称为阿里史上的珍珠港事件,也自此开启了互联网巨头春节红包营销的序幕。
2016年春晚,支付宝砸下2.69亿夺得央视春晚的独家合作权,并开启了史上最经典的集五福红包玩法,当年支付宝宣布向全国观众豪派8亿元红包,除夕当天,支付宝上加好友、换福卡、发红包的次数达到677亿次。
而今年春节快手早早就与央视春晚达成独家合作关系,本以为今年红包大战的C位已经没有悬念,但是阿里突然在1月11日宣布成为淘宝春晚独家电商合作伙伴,虽不发红包,但是阿里带来了10亿元的购物补贴,并将抽取5万名消费者清空购物车,为红包大战再添了一把火。同时今年令人纠心的疫情也必将使线下活动有所减少,同时会增加线上活动的热度,这些客观因素都必将使今年的红包大战更具看点。其实从技术角度讲红包大战最大的看点是云计算。
抢红包背后的技术看点之一-分布式架构
如果想承接抢红包这样一个短时上亿并发量的场景,即便是世界最强超算也力不从心,所以这就要求红包系统首先要满足分式式架构的需求,而分布式系统也有一个重要的原则-CAP定理。
CAP定理:是指在一个分布式系统(distributed system)中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance),呈不可能三角关系,既三个目标只能同时做到两点,不可能三者兼顾。
其实CAP定理并不难理解,因为如果满足一致性、高可用性,那么一旦集群内有节点故障,那么为保证数据一致,必将使系统整体陷入中断。如果既有既满足可用性又满足分区容错性,那么必然存在某个节点在系统对外提供服务时出现宕机,而这时各节点的数据一致性又无法完全保证了。
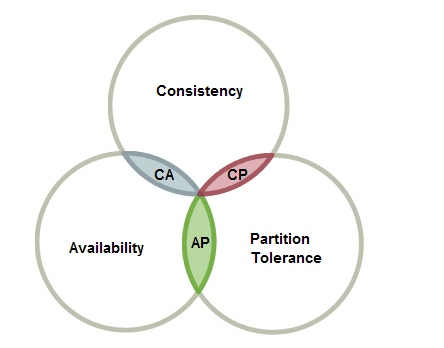
那么结合红包系统的需求分析,系统可用性肯定是要首先保证的,如果真是春晚当天页面无法访问,那恐怕营销不成,反而会让用户路转黑了,而且在大流量的冲击下节点故障也是难免,因此分区容错性也需要保证,所以这样看来能稍微放一放的只有数据一致性,因此从这个角度上讲红包的总额必然会围绕期望值上下浮动。
目前分布式系统交易分发一般有两种方式,一是哈希法,将服务请求序列化后计算哈希值,然后根据这个哈希值将请求分配到不同的节点上,当然直接把请求按照顺序循环发送集群内的服务器也可以看作是哈希法的变种,不过这会使入口处的负载设备成为瓶颈,二是将所有请求人为分成几份,每个集群只处理自己接到的请求,以此为降低入口流量的压力,但这样的缺点是很难将请求平均分配。
抢红包这样的系统只能将以上两种方案结合。首先根据历史经验将交易量相量的地区结合,分为一组,比如北京、天津和辽宁、长春分为一组、上海、苏州、南京分为二组等等以此类推,与之对应的云集群都有自己独立的红包额度,也只处理发给自己的请求。这样能避免入口的瓶颈,也尽量平均分配了请求的处理量。
接下来每个集群也会将额度分配给内部的服务器,然后每个服务器会将自己库存范围内的请求直接标志为成功,并在自己库存范围的基础上还会多预留一定比例的需求为待定,待统一减库存后再确定能否待请求能否成功。
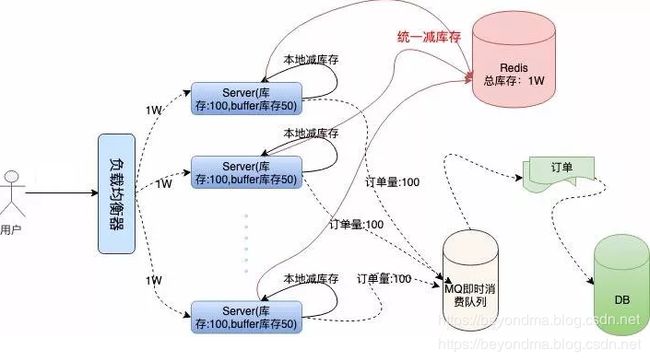
所以从分布式的角度来看,分区域与分库存是系统设计的基础环节,而接下来要做的就是上云了。
抢红包背后的技术看点之一云计算
今年双十一盘点时阿里宣布自身全部核心系统已经完成上云,这是一个非常惊人的成就,随着传统的软硬件分离迭代的模式逐步显现出局限性,现今的应用越来越复杂,对算力的要求越来越高,而算法、软件和硬件的隔阂造成巨大算力的浪费,已经无法满足在超大规模计算机场景下提升IT计算效率、降低计算成本的诉求。这时“云”的价值开始体现,但是云时代软件开发的方法论与模式与之前时代是完全不同的,因为云最大的特点就是可持续交付和微服务化,完全上云不但有巨大的好处,也意味着巨大的挑战。
分布式与云计算就像一对孪生兄弟,必须要结合使用才能发挥出最大的价值,分布式系统的各节点最好都是整齐化一,这样调度成本都可能会降到最低,而如果出现有的节点算力强,有的节点算力弱,那么受木桶原理制约,系统的性能就很可能被算力最弱的节点所限制,而云这种屏底层,向客户交付标准化硬件的技术在分布式的架构下就会大显神威了。
也恰恰是由于以上原因,我们可以看到参与这种红包活动的企业往往都是纯线上企业,因此一旦企业有线下网点的布局,那么在参与红包活动时都需要考虑给网点的发起请求调高优先级,进行区别对待,这种非标标准的请求会让系统复杂度呈几何级数增长。所以从云的角度上看,用户抢的不是红包,而是在各自区域请求中队列中的云资源。
国产云计算发展的坎坷之路
虽然“云”的好处很多,但是其发展并不算特别顺利,在十年前概念提出伊始,普遍不为人看好,甚至被某IT大佬戏称,“云计算只是新瓶装旧酒”,其背后的原因还是虚拟化层所耗的资源无法避免。
在阿里云创始人王坚院士参加央视的《朗读者》节目时曾经表示,阿里云他的客户、他的工程师拿命来填的,因为第一个用电的人,第一个坐飞机的人也是拿命来填的。这还真不是危言耸听,在成立最初几年阿里云的年离职率高达60%以下,甚至在2012年阿里的年会上王坚还因为看到了那些离开的同事,而失声痛哭。
但情况从2015年开始改观,阿里云在SortBenchmark的排序竞赛中阿里云用不到7分钟就完成了100TB的数据排序,打破了ApacheSpark之前23.4分钟的纪录。后来又在2017年中国电子学会设立科技进步奖的特等奖,这也是该奖项设立以来的首个特等奖。
接下来神龙服务器和飞天操作系统的延生基本克服了云的弱点,并将云的规模效应发挥到极致。
神龙服务器:阿里云降低虚拟层消耗的秘决在于神龙服务器上这块完全自研的MOC卡,正是MOC的居中调度让阿里神龙服务器不再使用宝贵的CPU资源进行虚拟化层的调度工作,从而大大降低了云转换的成本。

飞天操作系统:正所谓韩信点兵,多多益善,飞天能将百万级服务器连成一台超级计算机,还能有条不紊的通过云计算向用户提供计算能力。我们看到在飞天的基础公共模块之上,有两个最核心的服务,一个是盘古,另一个是伏羲。盘古是存储管理服务,伏羲是资源调度服务,飞天内核之上应用的存储和资源的分配都是由盘古和伏羲管理。具体见下图:;
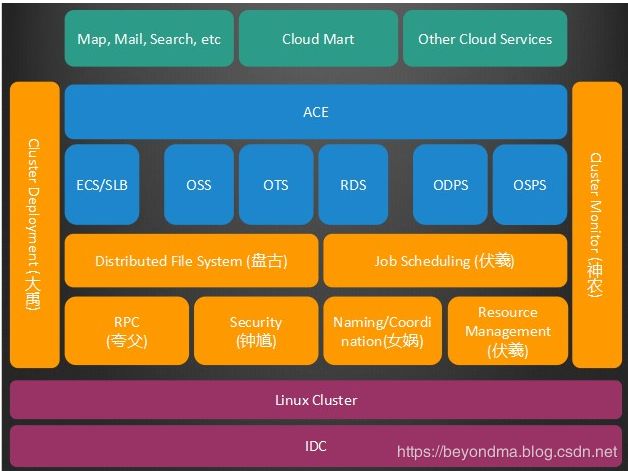
可以看到飞天中的众多模块都是以上古天神命名的,其中
夸父:负责网络通信,由于飞天是要将众多服务器连接在一起的,夸父正是完成他们之间的通信功能。
女娲:与负责命名与协同工作,与神话中造人的工作不同,做为飞天中的唯一女性女娲负责将所有子模块的命名与协调工作。
盘古:负责分布式存储。
神农:负责监控,随时治病救人。
伏羲:负责任务调度及资源管理,这也和精通音律和伏羲氏有点渊源。
大禹:负责集群布署。
钟馗:负责安全,负责捉鬼。
当然在国产云计算行业其它大厂也都有各自的特长,比如腾讯做为全球社区的巨头腾讯,其QQ类的社交软件面对着比其它应用多出几倍的流量短暂时突发场景,在面对这样的问题时,以虚拟机为单位补充资源,还是浪费资源。
因此我们看到腾讯在更轻量级的资源分配形式-容器化方面做了很多细节工作,以满足这种突发、短时的弹性需求。
而腾讯近期开源的TencentOS Kernel在容器运行所需的资源调度弹性、系统性能及安全等层面做了很多优化,可谓是开源+“容器云”的典范。
后计-未来可期
通过自主掌控的技术,国内的科技巨头在云计算领域已经走向了世界的前列,通过云大幅提升计算效率,实现能够突破传统IT时代的算力瓶颈,凸显云计算的整体优势。云正在与区块链结合成为Baas,正在与AI结合成为Aaas,云正在不断下沉,变成互联网时间的空气和水一样基础设施。而未来我们可以不再关心云计算背后的细节,就像不用关心水是如何过滤、运送一样,打开水笼头就可以使用到云,未来云计算的发展空间和使用场景还会不断拓宽,未来可期,拭目以待。