python爬虫实例之淘宝商品比价定向爬取(虽然网站已经改变,不能爬取,但是,我还是分析了一下)
python爬虫实例之淘宝商品比价定向爬取
这次就模仿之前做的总结进行初次尝试
- 目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
- 理解:
- 获取淘宝的搜索接口
- 淘宝页面的翻页处理
- 技术路线:requests——re
准备工作
- 获取淘宝搜索商品的关键字接口
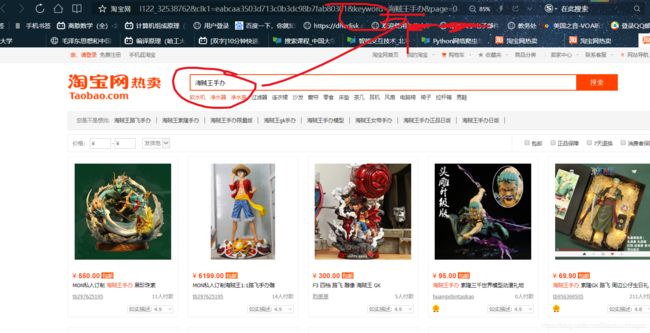
如下图,自然而然地看见网址中地keyword后面,赫然地跟着“海贼王手办”,几个大字
旧版是 q= 后面连接关键字,这里只是教你怎么看
- 获取翻页的关键字接口
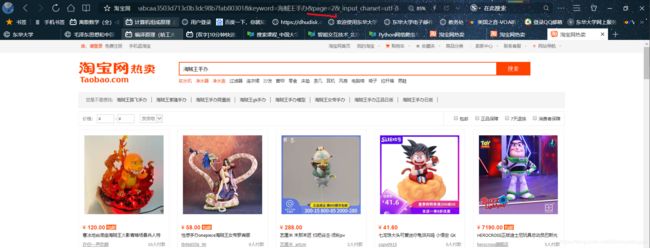
尝试翻页之后,发现page后面对应的页码变为2,所以改变page的就翻页了
这个是新版的,旧版的是s作为关键字,44的倍数一页
- 查看robots协议,查看是否允许进行爬取
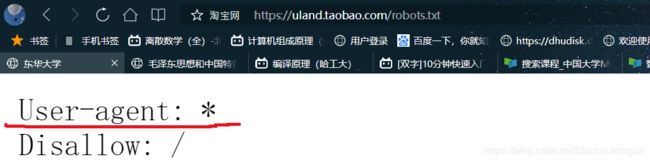
如下图,好吧,这个我也忘记了,看一下什么意思

根据基本语法知道,淘宝是不允许所有的爬虫对根目录进行爬取的,但是用于技术探讨应该是可以的
- 如果要获取商品信息的提取范式,需要查看商品信息的表达式形式,于是我打开了网页
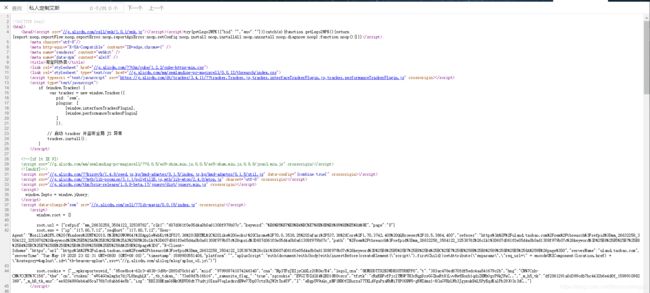
如下图,好吧,搜索之下并没有任何发现,似乎没有将信息保存在网页
于是乎我打开某个商品的页面,并查看源代码
好吧,所有的信息都是写在标签里面的,教程里面的信息并没有出现


由此发现,淘宝已经有了改良,商品的信息已经不写在html页面中,没有办法直接爬取
但是作为一个练手的项目,可以参照视频里面的版本进行一下分析和讲解,如下图
价格的图片段,“view_price”:“127.00”
分析为正则表达式:“view_price”:"[\d.]*"

名称段,“raw_title”:“超牛娜娜包”
分析成正则表达式:“raw_title”:"[.]*"
![]()
程序编写
-
第一步,确定步骤,并将所有的步骤
- 提交商品的搜索请求,获取页面 getHTMLText()
- 对于每个页面,提取商品的名称和价格信息 parsePage()
- 将信息输出到屏幕上 printGoodList()
- 采用main函数将所有的函数连接起来
代码:
# 获取相关的HTML页面信息
# url是网页的连接
def getHTMLtext(url):
return''
# 获取各个商品的信息
# html是爬取到本地的HTML内容
# ilt是用来存放商品信息的html页面
def parsePage(ilt,html):
print('')
# 将商品输入到屏幕上
# ilt是容纳对应的商品的信息的列表
def printMessage(ilt):
print()
# 用main函数将所有的网页链接起来
# 重点在于翻页的方式,获取翻页的关键字
def main():
goods = '书包'
depth = 2
start_url = 'http://a.taobao.com/search?q=' + goods
infolist = []
for i in range(2):
try:
url = start_url+'&s=' + str(44*i)
html = getHTMLtext(url)
parsePage(infolist,html)
except:
continue
printMessage(infolist)
main()
- 第二步,完善各个步骤的方法
逐步完善各个部分的代码
- 第一部分完善getHTMLtext(url),常规的爬取页面的方式,基本上不变
# 获取相关的HTML页面信息
def getHTMLtext(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return''
- 第二部分,完善parsePage()分析爬取页面(parse描述),不同于以往的BeautifulSoup库查找标签,这里用正则表达式
# 获取各个商品的信息
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
//根据很久以前的网页得到的信息格式
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
# eval()函数,将对应的数据外层的双引号或者是单引号去掉
# 注意,提取之后是作为字符串存在的,然后用”:“将之拆分,仅仅只取后面的值
title = eval(tlt[i].split(':')[1])
ilt.append([price.title])
except:
print('')
- 第三部分,采用格式输出的方式,用format函数,先规定输出的格式,然后逐个输出
# 将商品输入到屏幕上
def printMessage(ilt):
tplt = '{:4}\t{:8}\t{:16}'
# 定义输出的模板
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
代码总结
import re
import requests
# 获取相关的HTML页面信息
def getHTMLtext(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return''
# 获取各个商品的信息
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
# eval()函数,将对应的数据外层的双引号或者是单引号去掉
title = eval(tlt[i].split(':')[1])
ilt.append([price.title])
except:
print('')
# 将商品输入到屏幕上
def printMessage(ilt):
tplt = '{:4}\t{:8}\t{:16}'
# 定义输出的模板
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
# 用main函数将所有的网页链接起来
def main():
goods = '书包'
depth = 2
start_url = 'http://a.taobao.com/search?q=' + goods
infolist = []
for i in range(2):
try:
url = start_url+'&s=' + str(44*i)
html = getHTMLtext(url)
parsePage(infolist,html)
except:
continue
printMessage(infolist)
main()
总结
-
我们平常在浏览网页的时候,发现很多的页面是需要登录才能使用,那么爬虫怎么爬取?其实我也不知道,但是我想攻克,在下一篇博客我一定会写这方面的信息
-
现今为止,筛选网上的信息,我们有两种方式
- 方式一:使用BeautifulSoup库,信息包含在标签中
- 方式二:使用正则表达式,整个页面中进行爬取
-
现今为止,我们常用的输出方式,使用format函数,先是写出对应的输出格式,然后再分布填入其中
-
对于关键字,通过之前的几个例子发现,无论是翻页,还是搜索都会映射到网址中的对应的关键字,所以要回看关键字