微信全文搜索优化之路
前言
基于本地数据的全文搜索(Full-Text-Search,简称 FTS)在移动应用上扮演着重要角色,与基于服务端提供的搜索服务不同,移动端受硬件条件限制,尤其在数据量相对较大的情况下,搜索性能问题表现得十分突出。本文以移动平台广泛采用的 SQLite FTS Extension 为例,介绍了移动平台 FTS 的基本原理,并结合微信 Android 客户端自身实践,重点讲述微信在 FTS 上的一些性能优化经验。
SQLite FTS Extension
SQLite FTS Extension 是 SQLite 为全文搜索开发的插件,内嵌在标准的 SQLite 发布版本当中,主要具有如下特点:
- 搜索速度快:使用倒排索引加速查找过程;
- 稳定性好:目前 SQLite 在移动端的稳定性较为良好,FTS Extension 即是在 SQLite 基础上搭建而成的;
- **接入简单:**Android 和 iOS 平台本身就支持 SQLite,且 FTS Extension 的使用与 SQLite 表无异;
- 兼容性好:得益于 SQLite 本身良好的兼容性,SQLite FTS Extension 也拥有很好的兼容性。
目前 SQLite FTS Extension 已经发布了 5 个版本,在此简单介绍下主流的 3 个版本:
- FTS3:基础版本,具有完整的 FTS 特性,支持自定义分词器,库函数包括 Offsets、Snippet。
- FTS4:在 FTS3 的基础上,性能有较大优化,增加相关性函数计算 MatchInfo;
- FTS5:和 FTS4 相比有较大变动,储存格式上有较大改进,最明显就是 Instance-List 的分段存储,能够支持更大的 Instance-List 存储;并且开放 ExtensionAPI,支持自定义辅助函数。
微信全文搜索存储架构
微信全文搜索最初主要服务于联系人和聊天记录的业务搜索。在方案设计之初,为了让这个功能有很好的体验,同时考虑到未来接入业务会不断增多,我们将设计目标定为:
1. 搜索速度快
微信全文搜索使用 SQLite FTS4 Extension,通过倒排索引提高搜索速度。
2. 业务独立性
微信的核心业务是联系人和消息,而微信全文搜索无论是在建立索引、更新索引或者删除索引时,都需要处理大量数据,为了使全文搜索不影响微信的核心业务,采用了如图 1 所示的存储架构。

具体体现为:
独立 DB、读写分离:微信全文搜索在整体架构上独立于主业务,搜索 DB 也是独立于主业务 DB;当主业务数据发生更新时,主业务通过 EventBus 方式通知搜索对应的业务数据处理模块,该模块会通过一个独立的 ReadOnly 数据库连接访问主业务数据库,不和主业务存储层共享数据库连接。
减少数据库操作:在搜索模块中,会有专门处理业务数据的模块,对一些复杂的数据结构进行特殊处理。例如,对于一个 500 人的群聊,如果将所有成员分次插入搜索 DB 中,会造成过多的数据库操作。所以,微信会把所有的群成员拼接为单个字符串,插入搜索 DB 中。
热数据延迟更新:针对更新频率非常高的热数据,采用延迟更新策略。所有的索引数据分为正常数据和脏数据,当数据发生更新时,先把对应的数据标记为脏数据,然后有一个定时器,每隔 10min 将数据更新到索引中。
3. 可扩展性高
高可扩展性要求搜索表结构和业务解耦。SQLite FTS 官网上的例子,都是以单索引表的方式,每一列对应业务的某一个属性,当对应业务发生变化时,就需要修改索引表的结构。为了解决业务变化而带来的表结构修改问题,微信将业务属性数字化,设计出如表 1 和表 2 的表结构。
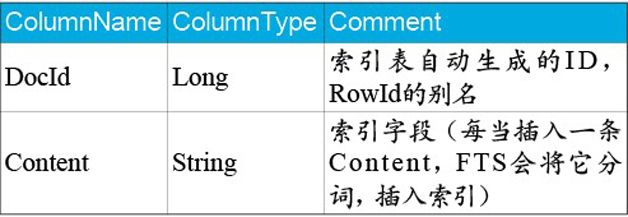

其中,IndexTable 负责全文搜索的索引建立,它和逻辑无关,在搜索关键词时,只需要找到对应的 DocId 即可。MetaTable 负责业务逻辑的过滤,通过 Type 和 SubType 来过滤对应业务的数据,最后输出 BusItemId。
搜索优化
从 2014 年 1 月 5.4 版到 2017 年春节后的 6.5.7 版,微信总体用户量从 4 亿增加到 9 亿,伴随着重度用户数量的大幅增长,微信本地搜索的数据量也大幅积累下来,导致搜索速度不断下降,用户投诉持续增加。据统计,在 5.4 版本到 6.5.7 版本期间,微信全文搜索各个任务的平均搜索时间,增长超过 10 倍,给微信全文搜索带来巨大挑战。
为了优化搜索时长,先看下如图 2 所示的搜索流程。
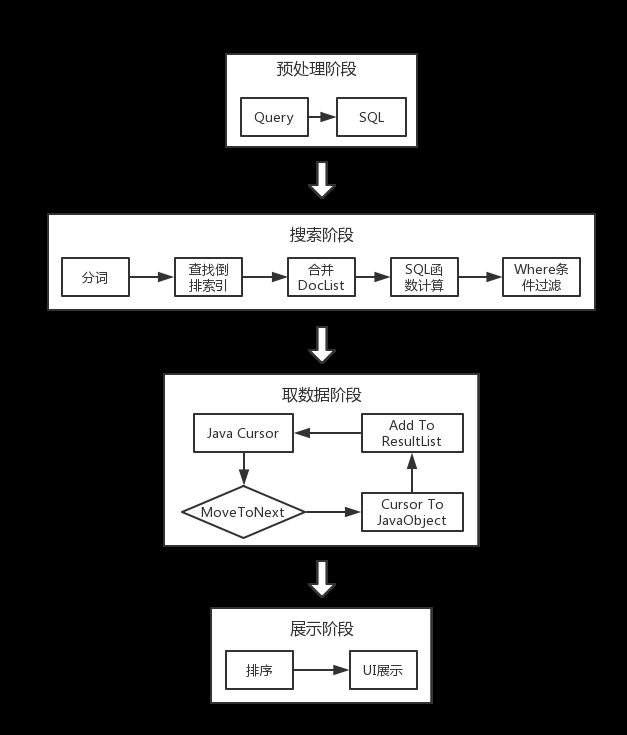
通过每个阶段的耗时,发现在取数据阶段,时间占比达到 80%以上,并且搜索的结果集数据量越大,时间占比越高,最高可达 95%。取数据阶段是一个循环的过程,所以优化一个循环需要从两方面着手,减少单次循环耗时和总体循环次数。
减少单次循环执行耗时
深入 SQLite FTS4 Extension 源码,发现 FTS4 的库函数 Offsets 耗时占单次循环执行耗时 70%以上,并且数据量越大耗时越长。
FTS4 库函数 Offsets:用于把词语偏移转为字节偏移,微信当中使用字节做结果排序及高亮。
函数输入:
- Query:用户查找的关键词;
- 命中 Doc:关键词所命中的文档,即全文搜索中的基本单位,可以是一个网页,一篇文章或一条聊天记录;
- 目标词语偏移:在搜索阶段,通过关键词查找搜索索引可以拿到目标词语偏移。
函数输出:
- 目标字节偏移:表示关键词在命中 Doc 中的字节偏移。
例如:
Query=我 命中 Doc=我和我弟弟去逛街 目标词语偏移=0、2将命中 Doc 经过分词器分词,可以得到表 3。最后计算可以得出,目标字节偏移=0、6。

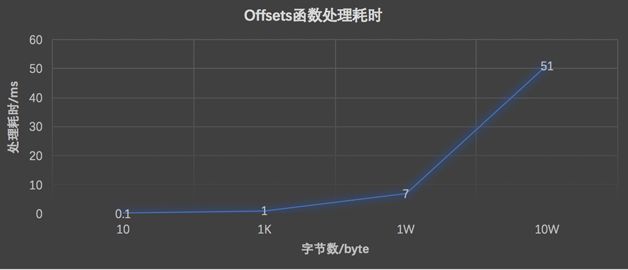
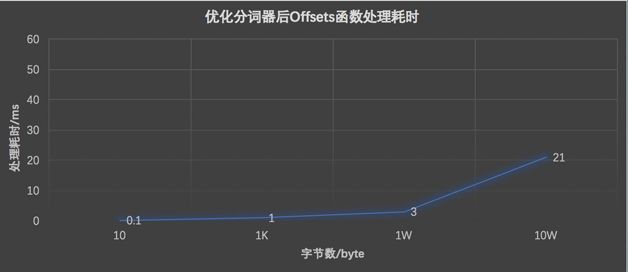
如图 3 所示是 Offsets 函数处理命中 Doc 字节数和耗时的关系。Offsets 函数的处理过程中包括分词,所以第一步就优化分词器。
要优化分词器,分词规则是重中之重。微信的分词规则为英文和数字合并分词,非英文和数字单独分词。举个例子,如对于昵称“Hello520 中国”,分词结果为“Hello”、“520”、“中”、“国”。这个分词规则的原因要归结于微信对全文搜索的结果排序需求主要是其他的属性排序,而非依据文档的相关性排序。即,全文搜索部分只需要找到存在关键词的文档,并不关心文档中存在几个关键词。且用户的输入 Query 大部分情况都不能组成词语,存在方言,所以把整个词语全部拆开建立索引是最佳的处理方式。
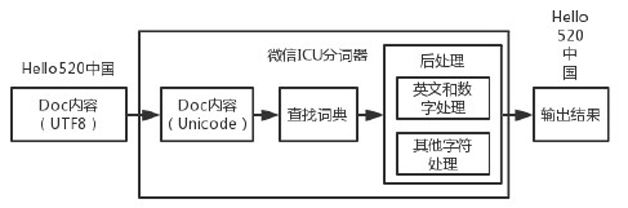
微信全文搜索开发起始于 2013 年年底,当时只能使用 FTS4,但其自带的分词器无法良好地支持中文,只能使用 ICU 分词器。且相对来说,ICU 分词器接入比较简单,对中文支持较好。如图 4 所示,昵称“Hello520 中国”输入分词器中,从开始的 UTF8 编码,分词器会将其转化为 Unicode 编码,紧接着查找词典,最后进行后处理输出得到分词结果。但从输入输出中我们可以发现,转化编码和查找词典这两步其实是多余的。
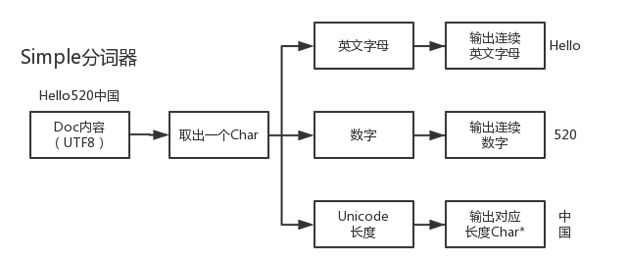
因此,最终微信舍弃了 ICU 分词器,转而自定义了 Simple 分词器。如图 5 所示,Simple 分词器直接处理 UTF8 编码的 Doc 内容,通过单个 Char,判断当前字符的 Unicode 编码范围及长度,并根据不同的情况做出不同的处理。
在经过分词器优化后,Offsets 函数耗时有了显著降低,从图 6 可见,处理 10 万 Byte 的耗时已经降低至 21ms。但这样的优化还远远不够,当处理超过 10 个 10W 结果 Doc 时,仍然会超过 200ms,所以也就有了下一步的优化。
在移动端,由于屏幕的限制,往往在最后显示搜索结果时,只会高亮少量命中的关键词,而 Offsets 函数会计算命中 Doc 中所有目标词语偏移,因此,我们需要对 Offsets 函数进行改造。
最开始,我们尝试的方案是直接修改 Offsets 函数源码,但不幸地发现 FTS4 对 API 的封装较难使用,且 Offsets 函数的依赖也较多,修改出来的代码很难维护,可读性也不好,所以需要寻找新的方法来优化。在经过一番研究后,我们发现 FTS5 支持自定义辅助函数,且有着较好的 API 封装,所以最后使用 FTS5 自定义辅助函数(MMHighLight)重新实现 Offsets 函数的功能,并加入了优化逻辑。
再以前文示例来看,输入:
Query=我 命中 Doc=我和我弟弟去逛街 目标词语偏移=0、2 目标返回个数=1此时分词器分步回调,当分词器第一次返回“我”,符合目标词语偏移的第一个 0,并且此时已经满足目标返回个数 1,函数直接返回目标字节偏移=0,如图 7 所示,耗时实现了 10 万 Byte 低至 2ms 的结果。

减少总体循环次数
减少取数据阶段的总体循环次数,比较容易想到的是在 SQL 层做数据的分页返回。这也就意味着我们需要在 DB 层排序,而其决定因素则为排序因子。但是微信全文搜索面对的业务排序因子非常繁杂,无法直接使用 SQL 中的 ORDER BY,所以需要通过一个中间函数转化,将所有的排序因子通过一个可比较的数字体现,最后再使用 ORDER BY 排序。
比较复杂的排序因子如下:
- 时间分段排序:时间范围在半年内,排序因子取决于下一级排序因子;时间范围在半年外,取决于时间的远近。
- 函数结果排序:排序因子是一个函数计算的结果,而非一个直接的数据库 Column,并且函数计算结果不可直接使用 ORDER BY,例如字符串形式的数字。
通过以上的分析,减少总体循环次数的核心点就在于,将 Java 层的排序转移到 SQL 层去做,优点如下:
- 减少 I/O;
- 减少 C 层到 Java 层的数据拷贝。
所以,这里关键的实现点在于中间转化函数,微信的中间转化函数 MMRank 是通过 FTS5 的辅助函数实现的。
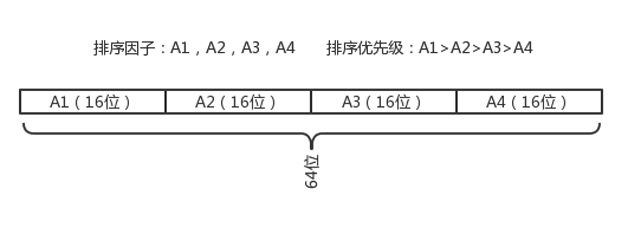
如图 8 所示,MMRank 的实现原理就是通过把所有的排序因子转化到一个 64 位的 Long 数值当中,高优先级的排序因子置高位,低优先级的排序因子置低位。最后的 SQL 如下:
SELECT MMRank(A1, A2, A3, A4) AS Rank FROM IndexTable ORDER BY RANK DESC;特殊优化——聊天记录搜索优化
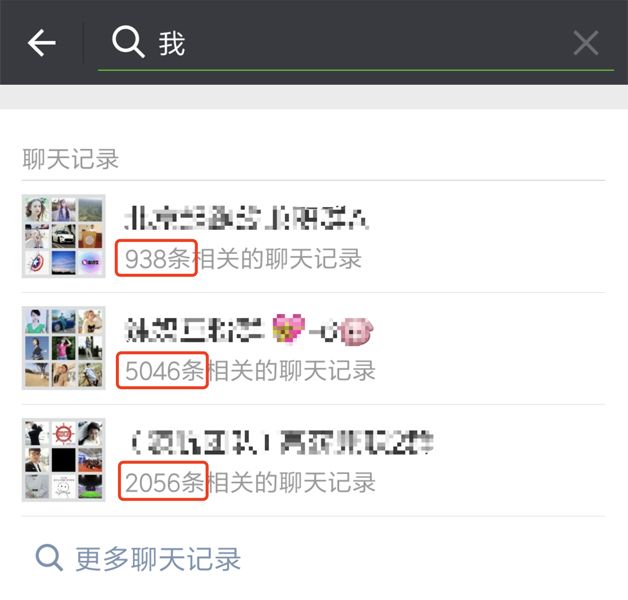
微信全文搜索中有一个比较特殊的搜索任务,就是聊天记录。如图 9 所示,红色圈内的数字表示,此会话中,包含关键字“我”的聊天记录的个数,而会话的排序规则就是会话的活跃时间。
微信聊天记录的搜索有以下两个特点:
- 有统计属性;
- 数量非常多(单关键词命中最高可达到 20 万条)。
从前文搜索流程图可以看出,微信最初采用的方案是在 Java 层统计个数和排序,此方法在大数据的情况下不可取。鉴于之前分析过减少循环次数可以通过分页返回,其核心点在于把排序从 Java 层转移到 SQL 层,所以就有了优化方案一。
优化方案一:Group By
实现 SQL 如下:
SELECT count(conv), MAX(timestamp) AS MaxTime FROM IndexTable GROUP BY conv ORDER BY MaxTime DESC LIMIT 4;此方案通过 Group By 在 SQL 层直接统计出命中聊天记录的个数,并按照最近的时间排序,但是也有明显缺陷:
- 无法使用索引加速:当 Group By 和 Order By 同时使用时,Order By 中必须包含 Group By 的字段才可以命中索引,原因是使用 Group By 会生成中间子表;
- 全量计算:Group By 在 SQL 层统计命中聊天记录个数是统计了所有会话,图 9 中只需要统计 3 个会话,浪费了大量资源。
优化方案二:分步计算
鉴于方案一全量计算的问题,我们采用分步计算的方式。
第一步:找出最近活跃的 3 个会话。
SELECT count(*) FROM IndexTable ORDER BY timestamp DESC LIMIT 3;得到会话 conv1、conv2、conv3,然后执行以下 SQL 命令,可以分别得到 3 个会话的命中个数。
SELECT count(*) FROM IndexTable WHERE conv='conv1'; SELECT count(*) FROM IndexTable WHERE conv='conv2'; SELECT count(*) FROM IndexTable WHERE conv='conv3';但是这种方法也存在问题,需要执行多条 SQL,存在多次 I/O。
优化方案三:MessageCount
鉴于方案二需要多条 SQL 的问题,可以通过自定义聚合函数实现一次性统计。执行步骤如下:
第一步:找出最近活跃的 3 个会话。
SELECT count(*) FROM IndexTable ORDER BY timestamp DESC LIMIT 3;得到会话 conv1、conv2、conv3,然后执行以下 SQL。
SELECT MessageCount(3) FROM IndexTable WHERE conv IN ('conv1','conv2','conv3');可以一次性得到 3 个会话的命中个数。
总结
经过一系列优化后,微信全文搜索全体用户各个任务平均耗时都在 50ms 以下,而重度用户各个任务的平均搜索耗时都在 200ms 以下,平均时间优化的幅度达到 5 倍以上。但后续还是有很多值得优化的地方,譬如在计算高亮时,如果在 DocList 的数据结构中,直接加入字节偏移,还可以节省一部分时间。最后,希望这篇文章的一些经验摸索能够对大家在实际的研发工作中有所裨益。
作者:陈家敏,微信终端开发工程师,目前主要负责微信 Android 客户端全文搜索、微信运动的开发工作。先后参与了微信多人通话、微信搜一搜以及微信安全模式的开发。
责编:唐小引([email protected])