上海沙龙回顾 | Apache Kylin 原理介绍与新架构分享(Kylin On Parquet)
10月26日,字节跳动技术沙龙 | 大数据架构专场 在上海字节跳动总部圆满结束。我们邀请到字节跳动数据仓库架构负责人郭俊,Kyligence 大数据研发工程师陶加涛,字节跳动存储工程师徐明敏,阿里云高级技术专家白宸和大家进行分享交流。
以下是 Kyligence 大数据研发工程师陶加涛的分享主题沉淀,《Apache Kylin 原理介绍与新架构分享(Kylin On Parquet)》。

大家好,我是来自 Kyligence 的大数据开发工程师陶加涛,毕业之后就一直在 Kyligence 从事 Apache Kylin 的商业版本的研发。主要参与实现基于 Spark 的新一代的查询和构建引擎。今天议程分为三个方面:首先我会简单介绍下 Apache Kylin 以及它的查询原理,接下来我会介绍我们团队一直在做的 Parquet Storage,这个预计会在今年年底贡献回开源社区,最后我会介绍社区用户使用非常广泛的精确去重以及其在 Kylin 中的实现以及一些扩展。

Kylin 使用场景

Apache Kylin™ 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay Inc 开发并贡献至开源社区,它能在亚秒内查询巨大的 Hive 表。
作为一个 SQL 加速层,Kylin 可以下接各种数据源,例如 Hive/Kafka,上接各种 BI 系统,比如 Tableau,PowerBI,也可以直接进行 Ad hoc 的查询。
如果你们的产品/业务方找到你,说有一批查询太慢了希望能够加速,要求查询速度要快;查询并发要高;资源占用要少;完整支持 SQL 语法并且能够无缝集成 BI,然后又没有更多的机器给你,那么这个时候你可以考虑使用 Apache Kylin。
Apache Kylin 基本原理


Kylin 的核心思想是预计算,将数据按照指定的维度和指标,预先计算出所有可能的查询结果,利用空间换时间来加速查询模式固定的 OLAP 查询。
Kylin 的理论基础是 Cube 理论,每一种维度组合称之为 Cuboid,所有 Cuboid 的集合是 Cube。其中由所有维度组成的 Cuboid 称为 Base Cuboid,图中(time,item,location,supplier)即为 Base Cuboid,所有的 Cuboid 都可以基于 Base Cuboid 计算出来。Cuboid 我们可以理解为就是一张预计算过后的大宽表,在查询时,Kylin 会自动选择满足条件的最合适的 Cuboid,比如上图的查询就会去找Cuboid(time,item,location),相比于从用户的原始表进行计算,从 Cuboid 取数据进行计算能极大的降低扫描的数据量和计算量。
Apache Kylin 查询基本流程

下面我来简单介绍下 Kylin 查询的基本原理,前三步是所有 Query engine 的常规操作,我们这边借助了 Apache Calcite 框架来完成这个操作,网上相关的资料有很多这里不做过多展开,感兴趣的读者可以自行查阅。
这边介绍重点在最后两步:Kylin 适配和 Query 执行。为什么要做 Kylin 适配?因为我们前面得到的查询计划是直接根据用户的查询转化来的,这个查询计划不能直接查询预计算过的数据,这里需要 rewrite 这个执行计划,使得它可以查询预计算过后的数据(也就是Cube数据),来看下面的例子:

用户有一张商品访问表(stock),其中 Item 商品,user_id 表示商品被哪个用户访问过,用户希望分析商品的 PV。用户定义了一个 Cube,维度是 item,度量是COUNT(user_id),用户如果想分析商品的 PV,会发出如下的 SQL:
1SELECT item,COUNT(user_id) FROM stock GROUP BY item;
这条 SQL 发给 Kylin 后,Kylin 不能直接的用它原始的语义去查我们的 Cube 数据,这是因为的数据经过预计算后,每个 item 的 key 只会存在一行数据,原始表中相同 item key 的行已经被提前聚合掉了,生成了一列新的 measure 列,存放每个 item key 有多少 user_id 访问,所以 rewrite 的 SQL 会类似这样:
1 SELECT item,SUM(M_C) FROM stockGROUP BY item;
为什么这里还会有一步 SUM/ GROUP BY 的操作,而不是直接取出数据直接返回就 OK 了呢?因为可能查询击中的 Cuboid 不止 item 一个维度,即击中的不是最精确的 Cuboid,所以还需从这些维度中再聚合一次,但是部分聚合的数据量相比起用户原始表中的数据,还是减少了非常多的数据量和计算。并且如果查询精确的命中Cuboid,我们是可以直接跳过 Agg/GROUP BY 的流程,如下图:

上图是无预计算的场景,全部需要现场计算,Agg 和 Join 因为都会牵涉到 shuffle 操作,故当数据量很大的时候,性能就会比较差,同时也会占用更多的资源,这也会影响查询的并发。

而进行了预计算过后,原来最耗时的两步操作 Agg/Join 在后面改写过的执行计划上都消失了(Cuboid 精准匹配),甚至更进一步,我们在定义 cube 的时候还可以选择按 order by 的列进行排序,那么 Sort 操作也不用计算,整个的计算只是一个 stage,没有一次 shuffle,启动很少的 task 就可以完成计算,查询的并发度也能够提高。
Kylin On HBase
基本原理

在目前开源版本的实现中,构建完的数据是存储在 HBase 中的,在上面小节中,我们得到了一个能够查询 Cube 数据的逻辑执行计划,Calcite 框架会根据这个逻辑执行计划生成对应的物理执行计划,最终每个算子都会通过代码生成生成自己算子的可执行代码,这个过程是一个迭代器模型,数据从最底层的 TableScan 算子向上游算子流动,整个过程就像火山喷发一样,故又名 Volcano Iterator Mode。而这个 TableScan 生成的代码会从 HBase 中取出 Cube 数据,当数据返回到 Kylin 的 Query Server 端之后,再被上层的算子一层层消费。
Kylin On HBase瓶颈

这套方案对于简单的 SQL 并没有什么大问题,因为在精确匹配 Cuboid 的情况下,从 HBase 取回数据后,在 Kylin Query Server 端并不会做太多计算,但当一些比较复杂的查询,例如一句查询 join 了两个子查询,每个子查询都命中了各自的 cube,并在最外层做一些比较复杂的 Aggregate 操作,比如 COUNT DISTINCT 等,在这种情况下,Kylin Query Server 端不仅要从 HBase拉回大量的数据,并且还要在 Kylin Query Server 端计算 Join/Aggregate 等非常耗时耗资源的操作,当数据量变大,Kylin 的Query Server 端就可能会 OOM,解决的方式是提高 Query Server 端的内存,但这是个垂直扩容的过程,这就成了一个单点瓶颈,而大数据方案中存在单点瓶颈,是一个非常严重的问题,可能直接导致公司在架构选型的时候一键 pass 掉这个方案。
另外这套方案在使用中还有很多其他的局限:
例如 HBase 的运维是出了名的难,一旦 HBase 性能不好,那么可想而知 Kylin 的性能也不会好。
HBase 的资源隔离能力也比较弱,当某个时刻有比较大的负载的时候,其他使用 HBase 的业务也会受到影响,体现到 Kylin 可能会是查询的性能比较不稳定,benchmark 会有毛刺,解释起来比较麻烦并且需要集群 metric 的支持,对前线人员要求比较高。
HBase 里存储的都是经过编码后的 Byte Array 类型,序列化反序列化的开销也不能忽视。而对于我们开发人员来说,Calcite 代码生成比较难以调试,并且我们 HBase 的技能树修的比较少,想对 HBase 做源码级别的性能改进也比较困难。
Kylin On Parquet

由于上述 Kylin on HBase 方案的诸多局限性,我们公司很早的时候就在商业版本中研发新一代基于 Spark + Parquet 的方案用以替代开源的方案。下面介绍下该方案的整体架构:
其实整体来说,新的设计非常简洁:使用 visitor 模式遍历之前生成的能够查询 Cube 数据的逻辑执行计划树,执行计划树的节点代表一个算子,里面其实无非就是保存了一些信息,比如要扫哪个表,要 filter/project 哪些列等等。将原来树上的每一个算子都翻译成一个 Spark 对于 Dataframe 的一个操作,每个上游节点都问自己的下游节点它处理完之后的一个 DF,一直到最下游的TableScan节点,由它生成初始的 DF,可以简单理解成 cuboidDF= spark.read.parquet(path),得到初始的 DF之后,向它的上游返回,上游节点再对这个下游的 DF apply 上自己的操作,再返回给自己的上游,最后最上层节点对这个 DF 进行 collect 就触发了整个计算流程。这套框架的思想很简单,不过中间 Calcite 和 Spark 的 gap 的坑比我们想象的要多一些,比如数据类型/两边支持函/行为定义不一致等等。后期我们也有打算替换 Calcite 为 Catalyst,整套的架构会更加精致自然。

这一套 Kylin On Parquet 的方案,依托了 Spark:
所有计算都是分布式的,不存在单点瓶颈,可以通过横向扩容提高系统的计算能力;
资源调度有各种方案可以选择:Yarn/K8S/ Mesos,满足企业对于资源隔离的需求;
Spark 在性能方面的努力可以天然享受到,上文提到 Kylin On HBase 的序列化反序列化开销,就可以由 Spark 的 Tungsten 项目进行优化;
减少了 HBase 的依赖,带来了运维极大的方便,所有上下游依赖可以由 Spark 帮我们搞定,减少了自己的依赖,也方便上云;
对于开发人员来讲,可以对每个算子生成的 DF 直接进行进行 collect,观察数据在这一层有没有出现问题,并且 Spark + Parquet 是目前非常流行的 SQL On Hadoop 方案,我们团队对这两个项目也比较熟悉,维护了一个自己的 Spark 和 Parquet 分支,在上面进行了很多针对于我们特定场景的性能优化和稳定性提升的工作。
目前该方案正在贡献回开源社区,等贡献完之后可以出详细的 benchmark 报告,由于现在没有贡献完成,所以这里没有两套方案直接的性能对比数字,但是我们企业版对比开源的数字十分亮眼,查询稳定性提升也十分明显,TPCH 1000 下,目前的 Kylin On HBase 实现对于一些复杂的查询无法查询出结果,Kylin On Parquet 则能在一个合理的时间内查询出结果。
下面介绍去重分析,去重分析在企业日常分析中的使用频率非常高,如何在大数据场景下快速地进行去重分析一直是一大难点。Apache Kylin 使用预计算+ Bitmap 来加速这种场景,实现在超大规模数据集上精确去重的快速响应。
Kylin 中的精确去重

下面还是由一个例子来引出我们后续的讨论:
还是上面的商品访问表,这次我们希望求商品的 UV,这是去重非常典型的一个场景。我们的数据是存储在分布式平台上的,分别在数据节点 1 和 2 上。
我们从物理执行层面上想一下这句 SQL 背后会发生什么故事:首先分布式计算框架启动任务,从两个节点上去拿数据,因为 SQL group by 了 item 列,所以需要以 item 为 key 对两个表中的原始数据进行一次 shuffle。我们来看看需要 shuffle 哪些数据:因为 select/group by了 item,所以 item 需要 shuffle 。但是,user_id 我们只需要它的一个统计值,能不能不 shuffle 整个 user_id 的原始值呢?
如果只是简单的求 count 的话,每个数据节点分别求出对应 item 的 user_id 的 count,然后只要 shuffle 这个 count 就行了,因为 count 只是一个数字,所以 shuffle 的量非常小。但是由于分析的指标是 count distinct,我们不能简单相加两个节点 user_id 的 count distinct 值,我们只有得到一个 key 对应的所有 user_id 才能统计出正确的 count distinct 值,而这些值原先可能分布在不同的节点上,所以我们只能通过 shuffle 把这些值收集到同一个节点上再做去重。而当 user_id 这一列的数据量非常大的时候,需要 shuffle 的数据量也会非常大。我们其实最后只需要一个 count 值,那么有办法可以不 shuffle 整个列的原始值吗?我下面要介绍的两种算法就提供了这样的一种思路,使用更少的信息位,同样能够求出该列不重复元素的个数(基数)。
Bitmap 算法

第一种要介绍的算法是一种精确的去重算法,主要利用了 Bitmap 的原理。Bitmap 也称之为 Bitset,它本质上是定义了一个很大的 bit 数组,每个元素对应到 bit 数组的其中一位。例如有一个集合[2,3,5,8]对应的 Bitmap 数组是[001101001],集合中的 2 对应到数组 index 为 2 的位置,3 对应到 index 为 3 的位置,下同,得到的这样一个数组,我们就称之为 Bitmap。很直观的,数组中 1 的数量就是集合的基数。追本溯源,我们的目的是用更小的存储去表示更多的信息,而在计算机最小的信息单位是 bit,如果能够用一个 bit 来表示集合中的一个元素,比起原始元素,可以节省非常多的存储。
这就是最基础的 Bitmap,我们可以把 Bitmap 想象成一个容器,我们知道一个 Integer 是32位的,如果一个 Bitmap 可以存放最多 Integer.MAX_VALUE 个值,那么这个 Bitmap 最少需要 32 的长度。一个 32 位长度的 Bitmap 占用的空间是512 M (2^32/8/1024/1024),这种 Bitmap 存在着非常明显的问题:这种 Bitmap 中不论只有 1 个元素或者有 40 亿个元素,它都需要占据 512 M 的空间。回到刚才求 UV 的场景,不是每一个商品都会有那么多的访问,一些爆款可能会有上亿的访问,但是一些比较冷门的商品可能只有几个用户浏览,如果都用这种 Bitmap,它们占用的空间都是一样大的,这显然是不可接受的。
升级版 Bitmap:Roaring Bitmap

对于上节说的问题,有一种设计的非常的精巧 Bitmap,叫做 Roaring Bitmap,能够很好地解决上面说的这个问题。我们还是以存放 Integer 值的 Bitmap 来举例,RoaringBitmap 把一个 32 位的 Integer 划分为高 16 位和低 16 位,取高 16 位找到该条数据所对应的 key,每个 key 都有自己的一个 Container。我们把剩余的低 16 位放入该Container 中。依据不同的场景,有 3 种不同的 Container,分别是 Array Container、Bitmap Container 和 Run Container,下文将介绍前面两种 Container,最后一种 Container 留待读者自己去探索。
Roaring Bitmap:Array Container

ArrayContainer 是 Roaring Bitmap 初始化时默认的Container。Array Container 适合存放稀疏的数据,Array Container 内部的数据结构是一个 short array,这个 array 是有序的,方便查找。数组初始容量为 4,数组最大容量为 4096。超过最大容量 4096 时,会转换为 Bitmap Container。这边举例来说明数据放入一个 Array Container 的过程:有 0xFFFF0000 和 0xFFFF0001 两个数需要放到 Bitmap 中,它们的前 16 位都是 FFFF,所以他们是同一个 key,它们的后 16 位存放在同一个 Container 中;它们的后 16 位分别是 0 和 1,在 Array Container 的数组中分别保存 0 和 1 就可以了,相较于原始的 Bitmap 需要占用 512M 内存来存储这两个数,这种存放实际只占用了 2+4=6 个字节(key占 2 Bytes,两个 value 占 4 Bytes,不考虑数组的初始容量)。
Roaring Bitmap:Bitmap Container

第二种 Container 是 Bitmap Container,其原理就是上文说的 Bitmap。它的数据结构是一个 long 的数组,数组容量固定为 1024,和上文的 Array Container 不同,Array Container 是一个动态扩容的数组。这边推导下 1024 这个值:由于每个 Container 还需处理剩余的后 16 位数据,使用 Bitmap 来存储需要 8192 Bytes(2^16/8),而一个 long 值占 8 个 Bytes,所以一共需要 1024(8192/8)个 long 值。所以一个 Bitmapcontainer 固定占用内存 8 KB(1024 * 8 Byte)。当 Array Container 中元素到 4096 个时,也恰好占用 8 k(4096 * 2 Bytes)的空间,正好等于 Bitmap 所占用的 8 KB。而当你存放的元素个数超过 4096 的时候,Array Container 的大小占用还是会线性的增长,但是 BitmapContainer 的内存空间并不会增长,始终还是占用 8 K,所以当 ArrayContainer 超过最大容量(DEFAULT_MAX_SIZE)会转换为 Bitmap Container。
我们自己在 Kylin 中实践使用 Roaring Bitmap 时,我们发现 Array Container 随着数据量的增加会不停地 resize 自己的数组,而 Java 数组的 resize 其实非常消耗性能,因为它会不停地申请新的内存,同时老的内存在复制完成前也不会释放,导致内存占用变高,所以我们建议把 DEFAULT_MAX_SIZE 调得低一点,调成 1024 或者 2048,减少 ArrayContainer 后期 reszie 数组的次数和开销。
Roaring Bitmap:Container 总结
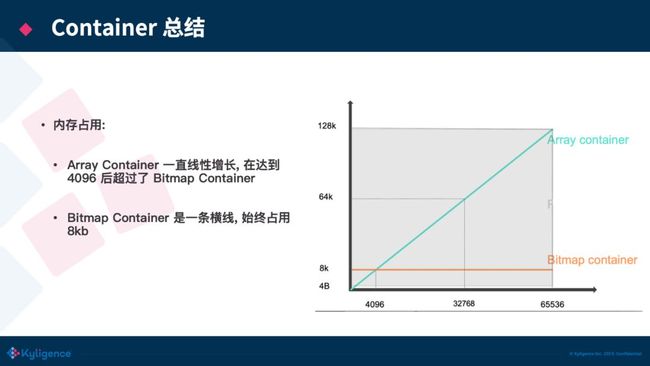
用一张图来总结3种 Container 所占的存储空间,可以看到元素个数达到 4096 之前,选用 Array Container 的收益是最好的,当元素个数超过了 4096 时,ArrayContainer 所占用的空间还是线性的增长,而 Bitmap Container 的存储占用则与数据量无关,这个时候 Bitmap Container 的收益就会更好。而 Run Container 占用的存储大小完全看数据的连续性,因此只能画出一个上下限范围 [4Bytes,128KB]。
再看去重场景

我们回到刚刚的去重场景,看看使用了 Bitmap 会给我们带来什么增益:无优化 case 下,每个 item 对应的 user_id 就可以看成存储原始值的一个集合;在使用Bitmap 优化的 case 下,每个 item 对应的 user_id 就可以看成一个 Bitmap 实例,Bitmap 实例占用的空间都会比直接存储原始值的集合要小(大部分情况下),这就达到了我们开始提的减少 shuffle 数据量的需求。
Kylin 精确去重在用户行为分析中的妙用

Bitmap 不仅支持高效的 OR 操作,还支持高效的 AND 的操作,例如上图中的例子,我们可以直接使用之前建立的 Bitmap 来分析用户行为。

为了便于在 SQL 中做“与”操作,Kylin 提供了一个自定义函数:“intersect_count”(详见Apache Kylin官方文档)。顾名思义这个函数就是求交集以后的结果数。

可以看到在其他 Query engine 中,计算用户的两天留存率,需要 join 两个子查询,并且有三个 count distinct 的Aggregate,可想而知这个性能不会太好,而 Kylin 只需要直接使用 intersect_count 函数就可以支持此类分析。

最后 Apache Kylin 有 1000+ 的全球用户,这说明有很多用户已经帮大家踩过坑了,Apache Kylin 已经是一个非常成熟的大数据 OLAP 解决方案,大家在做技术选型的时候可以放心大胆的选用 Apache Kylin。欢迎大家加我的微信,进一步沟通探讨(微信号:245915794)!
QA集锦
提问:Kylin on Parquet 怎么使用 Spark,通过 Thrift Server 吗?
回答:Kylin 在启动的时候时候会往 Yarn 上提交一个常驻的 SparkContext,Kylin 作为driver 端,后续的查询都发到这上面去进行计算。
提问:Bitmap 对于非数字的数据怎么处理?
回答:会对这些类型的数据建立全局字典,得到每个数据对应的一个 ID,用以建立 Bitmap。
提问:全局字典怎么用,查询的时候每次都要用到全局字典吗?
回答:全局字典只在构建的时候使用,用以生成 Bitmap,构建完成之后 Cube 数据上就会多一个 Bitmap 列,查询的时候就直接对 Bitmap 进行聚合就可以了。
提问:构建的 Cube 占用的空间会不会很大?
回答:这个要分情况来讨论,如果没有任何剪枝,Cube 就会有”维度的诅咒”,空间膨胀的会非常厉害,所以 Kylin 有一套剪枝机制,例如 ABC 三个维度一定会分析,那么 ABD 这样的 Cuboid 就可以剪枝掉,这个具体可以查看 Kylin 官网文档。
更多精彩分享:
上海沙龙回顾 | 字节跳动在Spark SQL上的核心优化实践
上海沙龙回顾 | 字节跳动如何优化万级节点HDFS平台
字节跳动技术沙龙
字节跳动技术沙龙是由字节跳动技术学院发起,字节跳动技术学院、掘金技术社区联合主办的技术交流活动。
字节跳动技术沙龙邀请来自字节跳动及业内互联网公司的技术专家,分享热门技术话题与一线实践经验,内容覆盖架构、大数据、前端、测试、运维、算法、系统等技术领域。
字节跳动技术沙龙旨在为技术领域人才提供一个开放、自由的交流学习平台,帮助技术人学习成长,不断进阶。

欢迎关注「字节跳动技术团队」