前端微服务在字节跳动的打磨与应用
本文讨论了微前端在字节跳动的应用情况,内容主要分析了微前端具体落地的步骤和两年来的使用情况。其中分析的部分主要讲到一些实际问题和我们的应对,落地情况强调了实现的过程。特别讲到很多在我们观念里面务必要提供的微前端基石,这些方面作为基础设施几乎是使用微前端的必要和前提条件。
传统前端业务通常会根据业务线集成在一个站点上,随着业务复杂度上升,包体积会迅速变的过大。为了适应这个变化往往需要更多的开发者、更细粒度的团队组织。分组开发时大家的模块解耦到各自完成,上线时糅合在一起运行,产生出层出不穷的分支合并、代码回滚,都会造成合作效率的骤降。这正是头条号平台在 17 年时面临的问题。
过大的代码集合还会造成发布频繁,每个业务分支和功能点都有一定的更新频率,如果以传统的独石系统开发、验证和上线,每一个业务都会让项目所有一起升级、测试和上线,发布频率的总和会非常高、非常频繁。如果不解除原有的耦合会彻底失去响应能力。
更进一步来看以如此之高的上线频率、版本迭代速度,开发者极难追溯哪个版本对应哪个改动。
字节跳动微服务前端解决方案为应对以上挑战而生。经过几年发展已经成功支持了几十个对内和对外的系统。
问题背景
Monolithic 的问题
Monolith 独石就是一块石头的意思。正常翻译一般是“单体”:单体应用。这个在前端届概念不普及,用独石这个翻译更能体现他是什么意思。一整个建筑(或者什么其他东西)是一整块石头刻出来的。比如石狮子。这就是独石的应用。这样做事情在前端工程环境这个快速变化、快速迭代的领域有很多问题。
上线慢
单体应用的一大问题是发布非常慢。字节跳动的典型业务情况是上一次线需要至少 30 分钟,前端的上线就需要这么长的时间。当然这是我们在 17 年经历的情况,保持我们的发展态势如果不升级技术,现在可能更慢。然后 17 年底我们开始了大改版,开始拼命的拥抱微前端。
原本回滚一次也是 10 分钟的。所以当时每天上线不了几次,风险也很大。逐渐导致变更都要憋着,成了“几天上线一次、一次多个变更”。
我相信这也是绝大多数听众都会有的问题。尤其是那种传统的后台工程。没事 webpack 一下你懂的。
上下线会很多吗?很多的,业务多了,有多少更新都要一起发布。
理解困难
当然本次是工程化的议题。更需要关注的影响更大的其实是框架问题。大家都是几十个项目合作到一个工程里。工程化在搞什么呢其中非常重要一个点就是要“人可以理解”。更低的认知成本,能收获更低的犯错概率。
那这些项目非得维持完全一致的组织模型就基本上是必须的。比如 model 是充血的还是失血的?是 contorller 全都放一起、还是根据 router 与视图们放一起?这些事非常鸡毛蒜皮的例子。实际上深层次的问题与之类似的非常多。
还有其它问题比如 debug 的时候到底能不能找到。也不是单体应用不行,单纯是说解决这个问题的时候投入了多少精力、多少设计,以及维持这个设计规范问题不崩坏,需要多少精力。
这一类都是单体应用本身的代码问题。“拆了就没这些事了。”
框架无法调整
真的从架构角度来说,到底如今的前端项目需要怎么开发、一般是怎么干的呢。从上一段内容读过来,我们知道大部分出色的架构师工程师都已经解决了好多那些困难了,方式是通过杰出的架构设计。
然后都知道前端的各种框架各种实践实际上非常多。前端工程师有个别名不知道你们听过吗,叫“npm install 工程师”哈哈,还有“github search 工程师”。
到底发生了极端困难的情况是来自框架还是来自生产框架的方法呢,这个不好说。但是是个值得琢磨的问题。所以你看接手拿到项目什么的别说了你就学吧。反正现有架构肯定是挺好的。就是你得学一阵、用对了才好。
微前端在字节跳动
这里开始讲我们的细节,分别是服务发现、运行隔离、环境一致以及其他架构优势,其实这几件事都讲完就能发现在讲的主要意思是,具体是什么把一个非常特殊、对习惯改变比较大的方案变成可能的。实现这样一个与众不同的方案不是大家聊一聊觉得同意并且开心就能做成。涉及到过程、成本、风险等方方面面。
“工程师”的任务不是说证明一个结构在理论上是可以存在的就完了,要有建造这个结构的过程。比如你拿化学键可以算出来任何可能存在的分子,画个小人都可以。但是到底怎么合成,按照什么路径能让这种分子被制造,哪种路径最快最便宜,这个是过程的可能性。通常这才是工程师的任务。
服务发现
服务发现的方面我们会首先讲一下在整个微服务模式里他作用是什么、有哪些方式。然后第二部分讲到底在解决什么问题,以及多说一些他能提供的新能力。我们很重视新能力因为我们的定位不是消防队,灭了火就完成任务,还有很多新目标、很多新好处可以探索实现。
最后是讲一下在字节跳动具体是怎么实现的。
1. 原理
“服务发现”就是原来的单体服务拆分之后,本来一个项目里的方法分开部署了,谁也找不到谁。需要有个统一的注册机构,把提供服务的各个部署都查到。
“发现”就是当你想访问一个微服务,你要怎么找到他。
这样就有两种构型,一个是以 Netflix OSS 为典型的,它在客户端的机器里先拿到一个服务目录,处理逻辑在客户端的代码里。另一种是服务端的服务发现,AWS 就是如此。
传统微服务的服务发现更像是函数调用的替代,拆了之后怎么调到不同容器里部署的函数。这里微前端思路非常类似,作用略有区别。微服务的情况是会区分像什么订阅、通知、请求、发布这些,前端很可能都不用或者表现上不在前端运行时使用。还有一些例如“对单”、“对多”这些基本就是前端不太用考虑的东西。
两者一致的地方是都谁也不认识谁了,如何知道哪些服务存在、谁在提供?下面就要讲一下各种构型的服务发现和背后的服务注册分别具体是什么情况。
客户端服务发现 是说客户端——也就是服务的调用者,去请求一个注册的目录,里面包含所有服务和负载均衡的基本信息这些,然后自己决定如何处理,使用哪种具体的 load balance 策略。比如 Netflix 的 OSS,服务在 Netflix Eureka 注册一下,它心跳给各个客户端。客户端自己搞,简单直观。
服务端服务发现 是类似 AWS Elastic LoadBalancer 这种。客户端请求就完了,服务端决定怎么给你反向代理、负载均衡。
服务注册 分自注册和第三方注册。自注册不言而喻。第三方注册就是一个保活机制,定期检查服务状态,帮你去管控该上了还是下了。
我们主要用的是第一种:客户端服务发现,就是你要多请求一个模块列表。这个列表给出的资源是根据用户 session 决定的,有丰富的动态的能力。然后客户端再根据这个列表里的各种信息,去加载模块资源。
2. 给前端带来了什么?
用服务发现的方式去组织微前端,除了使复杂的上线流程变得解耦、快捷,还可以使拆散之后的工程版本方便对齐,实现更高的稳定性和可调试性。还对前端工程带来好多其他好处。下面主要讲一下各种收益中的最重要的两个。
快速上线 是什么概念呢,前面说了几十个业务和在一个项目里,一起发布,这样发布的频率能有多高?实际考察一下放开限制后的情景,就会发现有超乎意料的高。我们的一个微前端应用的业务是头条号,它在 2019 年上半年发了 2000 个版本。前面说了传统上线需要 30 分钟才能完成打包升级和容器的重启,并且 10 分钟才能完一个回滚,这就意味着 1000 小时的上下线等待时间。相比之下我们新的方式点一下 HTTP 请求发出去就生效了,是一个毫秒级的反应速度。
这个搁以前就不是慢、需要干等着的问题了,直接大家就不这样去发了。都学 Native 发版那样火车式发布。结果是响应效率降低了很多,很多需求渐渐变得不再由开发形成瓶颈,反而是总要等版本排发布。
独立切换 我们现在就分别发,可以一个单页应用分几十个模块,各自上各自的、下各自的。而且后面会说到还可以各自配置自己的 AB 测试版:有 10 个模块就可以产生 1024 个 AB 版的组合,20 个模块 100 万个。跟以前完全不敢想象——也就是说一起发版的时代根本做不了这个事。现在不敢想象的反而是,你说字节跳动某个业务里面不能做 AB 测。
我们的头条号平台就是刚才一个典型的微前端项目,包含列出的这么多模块,各模块有独立的版本,和对服务版本的 session 控制。每个模块进去都是版本列表,有一个模块所有的历史版本。通过这个平台配置小流量、AB、上线规则。
运行隔离
1. 耦合开发的严峻形势
17 年我们推进项目的时候有一个很不错的帖子很流行,红遍朋友圈那种,讲 react-loadable 的。ta 从解耦的维度介绍了这个方向。我们当时也有一个很明确的业务需求,要把公司不同部门的人组织到一个项目里。并且这个项目经过经年累月的增肥,已经非常臃肿并且积攒了很多值得推敲的、非直接技术的工程细节。这就意味着要用不同组织,不同的技术,不同的工程规范和打包工具,去合写同一个平台、同一个工程。如果当时用了 iframe 可能就是非常凑合的勉强满足业务,完全不符合我们追求极致的习惯。
然后当时我们很在意一点就是这种跨团队合作,想融合不同的技术团队,实现少费力沟通或者不重沟通,运行隔离是个非常绝对的基本前提,我们其他分享里面也用了不小的篇幅介绍,有对内的也有对外的。当时的效果是什么呢。这个是我们 18 年 4 月内部培训录制到的当时情况:

我们把线上的页面(左图)通过调试工具插入脚本,临时移除掉沙盒功能,得到的右图效果。
2. 运行隔离的目标
运行隔离是啥意思,回想一下刚才说的 AB 测的问题,20 个项目是多少个组合。如果把这个对应到 bug 的维度,大家都在一个应用里乱跑会有多恐怖。那么这样的组合对我们的程序和程序员提出了什么样的要求?
不跑挂 说是“对一切工程师最基本要求”,我觉得不算夸张。所有软件工程师的第一个能力层级都应该是不把系统拖垮。微服务之后这个问题不明显了,因为有架构层面的方式解决了绝大多数挑战。我很信服的一个理论是所有程序员都是四个阶段:写完需求,不拖垮别人,能扩容,性能好。
不干扰 也是另一个大问题,我们当时西瓜团队和头条是两个独立的 App,他们和我们的合作完全跨部门,连 polyfill 的规则都不一样。事先也是做了很多公共组件、 CSS 约定之类的。但是规范和约定远远不够。协作的境界从最差到最好应该是:
定规范:谁来了都好好学、好好听,自己对自己的行为负全责。
能 enforce 规范:不凭自觉,而是用工具和流程等手段去发现和强制,实现可靠性。
不需要规范:系统的确定性由系统解决。靠人去发现和执行规范是消耗大量认知资源的,带来的都是额外的工作量和系统的不确定性。
3. 沙盒
我们还有另外一篇文章专门介绍沙盒的设计和采坑经验。这篇就快速用几张图示意一下。
① 变量保护: 全局变量、 DOM 和 CSS 基本都是走的这条路。前后两次快照,我们来比较,之后根据需要帮你恢复现场。这块内容不细说了,看一眼图就不言而喻:一次比较对照所有 key、两次遍历、黑名单 location、白名单 readonly。估计我这样一说大家都懂。

② 沙盒时序: 稍微多说一些。右图是我们做的 ABCDE 五个模块的加载和混行的时序图。虚线左边是加载,右边是独占线程所占用的时间。也就是说有 ABCDE 五个模块五个沙盒,分别在这个模块编译(下载、创建 js 变量和函数、运行这些语句、最终生成一个 React Component)和运行时(这个模块被打开、渲染对应的所有功能)。

这里面两个基础:js 单线程、事件循环
我们用了非常单纯的单进程操作系统的思路,比喻一下就是 js 的单线程就像单核 CPU 一样。你激活一个模块,相当于激活一个线程,其他都退到背景里。
实际上单核单进程不是必然,大家都知道这个原理。在事件循环的基础上,我们可以封装所有的异步操作,把回调套在沙盒激活后面。比如 setTimeout 和 addEventListener,这样每个模块看起来就像是在并行。这块可以说的很多,但是就想一下操作系统的比喻就好了。
4. 加载方式
React 的项目用 react-loadable 本身不多说了,VUE 和 raw (也就是不包含展示层框架的原始版)的各种项目,我们都提供 masterpage 的样例,每个版本对应的都实现了一套和 react-loadable 相似的效果。
子模块(Modules) 就是一个个的 CMD 包,我用 new Function 来包起来。其他就是具体主工程(MasterPage)项目框架的约定,load 过程分为 5 个钩子:
preload是否预加载,是个promise,fullfill的时候就会触发 Ajax。各种空闲政策阻塞政策都可以由 master 制定;loadCondition编译前置条件,fullfill了才会开始运行这部分,执行结果就是得到那个 CMD 的exports;provider是一个模块的入口的函数,由模块开发者提供,返回模块的一切输出。这个函数的传入参数由 masterpage 主工程来提供。loaded完成加载,得到编译结果了。等等后面不说太细了。
环境一致
因为我们之前都是在讲微服务是什么和落地效果如何,从来没有讲过 推行一个微服务你得做什么。现在这部分内容是我们第一次公开分享的,也是一个很独立的维度。
其实就是在讲为什么对微前端来说这个环境一致工具是必须的,是绕不过的必经之路。如果不搞也很容易就栽进坑里,项目失败。然后很可能还不知道是为何失败的,把问题归结为框架不好啊、人不好啊甚至微前端就不好啊之类的问题上。

1. Serverless vs container
container 就是一个寄生环境,尽管这个环境还是挺特殊的,不像 linux 这种完整操作系统。相比之下 Serverless 就特殊多了。特殊到连谷歌云都曾经在商业上被击败。
这里举两个 Serverless 的例子,比如 lambda。它的本地工具是一个 CLI 系统:SAM,是一个非常典型的必要基础设施。如果说发展容器化 AWS 全是靠 docker,发展 lambda 就是靠的 SAM。
另一个典型的例子 firebase。想必前端的同学们都非常清楚,也都用过他们的开发套件。这些工具都非常重视一点就是本地开发,我做个项目到底能不能先测试再上。或者说先调试在上。
要做的话就是尽可能模拟真实环境了,SAM 的话就模拟了 API Gateway,memory limit 这些。有 live debugging、 local debugging。不然的话发什么疯有人敢把线上业务放到一个非常不同的环境下运行。
2. 你是不是环境有问题(在我这是好的)
标题程序员最常说的一句话对不对,另一种表达是“我这是好的”。大家都知道绝大多数情况这么说话不对,但常常会忍不住说。甚至更像是其实是对自己说。一种扪心自问,自我拷问,“我这是好的啊”。
我们用沙盒把微前端做成了像 container,像浏览器里的 docker。但是不够,我们还是把寄生在 masterpage 内这种应用框架的特征,也就是业务具体逻辑,看成是一种 Serverless。
然后我们还把隔离的思路做到极致,我们的 dev 命令是通过启动参数启动一个完全独立的 Chrome 会话,有自己的 cookie 啊缓存啊这些,效果像是装了 2 个 Chrome 乃至多个 Chrome。然后代理工具默认也配到了启动参数,是个 pac 文件。所以也可以单独用或者装 switchy 用。
代理工具 就是调试环境的整个配置,那些走测试环境、哪些走线上请求全部代理管理。生成一个动态的 pac 地址和代理服务。就是刚才说的。
关键请求,比如服务发现的请求,显然是代理掉的。走一个我们为本地环境定制的返回值。更细节的功能是我们可以协助调试主工程(MasterPage)、 组合上某个 module,你也可以用指定的 MasterPage 版本来调用你正在编写的模块。
你也可以指定是否加载完整的线上模块列表、只替换你正在调试的模块。
我们也还有完整的植入 webpack dev server 的服务供选择。前面说了支持任意打包工具,这块是解耦的,只不过你用了我们可以帮你 reload,部分刷新动态刷新。后面再细说。
发布检查 是针对服务注册这一块。这块的一部分,我们的 build 命令有一套检查,对应 git 钩子。
方便调试 我们还在一定程度上支持了 HMR。我们可以像开发一个普通前端应用一样开发主工程(MasterPage)和子模块(Module),子模块更新后改变模块管理器状态,并由内置的 eventbus 机制来重新渲染 HMR,这个机制也可以用到盛传环境。
我们的公共库可以通过在 MasterPage 项目里引入、子模块里 external 的方式实现模块间共享。也支持子模块使用特定版本的基础库。
Vue 用到了全局变量及原型链扩展,暂时还不支持 Hot Reload 的调试。
其他的框架优势
框架上看就是 serverless 的方向。不是真的 serverless 是前端 serverless,业务 module 开发者很多东西都不用再关心了。举个例子就是 console.log。现在大家都知道线上业务要干干净净体体面面,把 console 都收拾整齐。这是我们之前提到的规范的层面,我们可以做到吸收所有 console,存储错误堆栈。然后用户反馈的时候作为 trace 元数据提交到反馈后台等等。
这些都是 masterpage 层面的框架了。当然不是必然关系。但是可以说微前端给了一个非常方便像这样组织项目的渠道。
我们线上的 sourcemap 也是根据服务发现的管理后台权限控制的,只有开发者能看。
下一代前端展望
前面讲了,服务发现是一个对前端可用资源的总体管理。这个能力是不局限于运行时的微服务前端的。对一切资源都适用,下面说一下这块。
服务发现 + CDN
抽象一个完整的前端访问,首先拆成 3 步:A 页面加载,B“服务发现”,C 根据服务发现结果加载资源。那就有不同的变种。最直观的就是 AB 结合,SSR 画上去,把 html 请求下来,module list 资源列表已经全了。这个系统我们这代号 GOOFY。当然也可以 ABC 都组装进去。这个后面细说。

另外一个思路就是 BC 结合,我请求一个列表,不用说我可以把 js 内容都 combo 进去。少一些额外的请求。

总之大意就是这个 ABC。
Token 解析
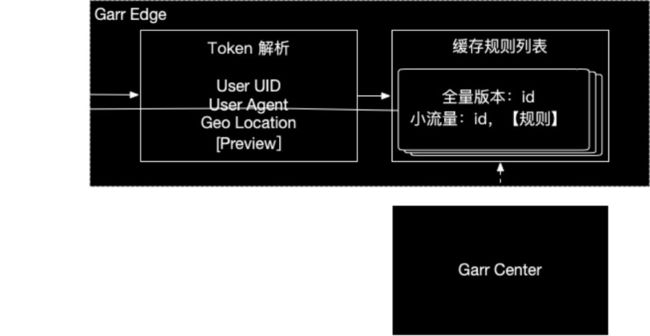
中心服务从中心机房把规则心跳给边缘节点,边缘节点接收客户请求,就近解析出基本的 token,这个过程中不依赖其他服务。
这个 token 由同样在边缘的页面服务提供。因为脱离了到中心机房验证的步骤所以 token 时效有一定依赖前端 SDK。
高可用
高可用可以说是边缘计算的一个极大的好处,额外给了我们一个收益。这套系统的容灾基本等同于智能 DNS 对应的探针保活这一套成熟技术了。
我们需要的就是把边缘节点心跳到一个监控服务上,他们会分钟级动态修改 DNS。如果没有足够的边缘节点生存,还可以 DNS 到传统的中心机房。
这样绝大多数流量都不需要进出中心机房,资源都是就近的、多播的。
结尾
以上就是本次分享的全部内容,我们从落地的细节分享了字节跳动两年来使用微前端的经验,以及面对这些挑战时的思考过程。非常幸运我们的项目有足够多给力的伙伴们支持,最终获得了比较大的成功,也非常明显地提升了重量级的产品的质量。
微前端和很多前沿和刚刚发展的概念一样,本身还在快速的演进和验证的过程中,我们的具体实践也一直在快速的变化,在不断地发现弱点和纠正它们,也在努力发展更多的可能。在这个从种种不完美到更完美的奋斗过程中,能给读者分享我们的成果是我们的一种荣幸。而且在分享后,如果能收到指教、讨论和建议我们会更加感激,并且非常欢迎。也欢迎更多的有识之士加入我们,具体可参见 job.bytedance.com (点击文末“阅读原文”,获得内推链接)。

欢迎关注「字节跳动技术团队」
 点击阅读原文,快来加入我们吧!
点击阅读原文,快来加入我们吧!