Java HashMap和HashSet总结
本文是作者在项目过程中做的总结,内容既有借鉴其他大神的地方,也有自己结合当前项目的思考。若有错误的地方,欢迎指正!最后感谢以下作者的分享!!
参考来源1:http://www.importnew.com/7099.html
参考来源2:https://blog.csdn.net/chenssy/article/details/18323767
参考来源3:https://blog.csdn.net/chenssy/article/details/21988605
1.HashMap
它是基于哈希表的Map接口的实现,是一种支持快速存取的数据结构,以键值对的形式存储数据。在HashMap中,key-value会被当做一个整体来处理,系统会根据hash算法来计算key-value的位置,实现通过key快速存、取value。
1.1定义
public class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable
HashMap继承AbstractMap类(AbstractMap实现了Map接口),在这里又再次实现了Map接口(当初写这段代码的 Josh Bloch说这就是一个写法错误。详情见https://stackoverflow.com/questions/2165204/why-does-linkedhashsete-extend-hashsete-and-implement-sete)。
Map接口定义了键映射到值的规则,而AbstractMap类提供Map接口的骨干实现,以最大限度的减少实现此接口所需的工作。
1.2影响HashMap性能的重要参数
1.2.1初始容量
容量表示哈希表中桶的数量,初始容量是创建哈希表时的容量。若未指定容量,则默认初始容量为16。
1.2.2加载因子
加载因子是哈希表在容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表空间的使用程度。加载因子越大表示散列表的装填程度越高,反之愈小。对于链表散列来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。系统默认负载因子为0.75,一般情况下我们是无需修改的。
1.3数据结构
每次新建一个HashMap,都会初始化一个table数组。table数组的元素为Entry节点。其中Entry为HashMap的内部类,它包含了键key,值value,下一个节点next以及hash值。正是由于Entry才构成了table数组的项为链表。
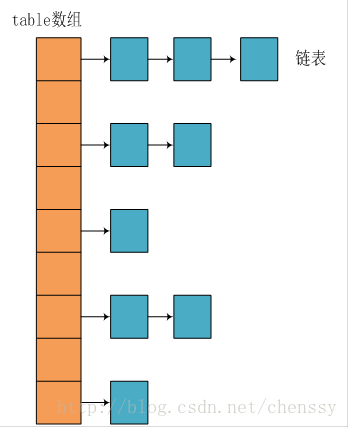
1.4存储实现:put(key,value)
当我们向一个HashMap添加一对key-value时,首先根据key计算hash值,然后根据hash值确定在table数组中的位置,即bucket的位置。若该位置没有元素,则直接插入,否则迭代此处的entry节点构成的链表。若两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的entry的value覆盖原来节点的value。如果两个hash值相等但key值不等,则将该节点插入链表的链头。
1.5读取实现:get(key)
读取的前提是:hashcode相同,bucket位置相同。hashcode相同,key不一定相同;key相同,hashcode一定相同。
通过key的hash值找到table数组中的索引处的链表,遍历链表,找到hash和key值相等的Entry节点。
1.6相关面试题
1.6.1你知道HashMap的工作原理吗?
HashMap是基于hashing的原理,我们使用put(key,value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put方法传递键值时,我们先对键调用hashcode()方法,返回的hash值用于找到bucket位置来存储Entry对象。
1.6.2当两个对象的hashcode相同会发生什么?
因为hashcode相同,bucket位置相同,‘碰撞’会发生。遍历bucket位置的链表,由Entry节点构成的链表,若hash值和key值相等,则用新的Entry节点的value替换原来节点的value,否则将新的Entry节点插入链表的表头。
1.6.3如果两个键的hashcode相同,你如何获取值对象?
通过hashcode找到bucke位置,遍历链表,判断key值是否相等,直到找到值对象。
1.6.4如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
1.7Java8新特性:Map computeIfAbsent方法说明
参考来源:https://blog.csdn.net/weixin_38229356/article/details/81129320
1.8什么时候用HashMap?
1.当一个函数需要return多个参数时,可以通过Map返回。
2.当函数形参较多或者不确定个数时,可以通过Map传参。
3.对大量数据进行分组整理,例如:本项目中的供应商信息根据能提供的原料id进行分组。
4.实现下拉列表key-value可以通过List
5.字典值 通过value找name :Map
例如:订单类型(order_type):日(day)周(week)月(month) firstMap.put("order_type",secondMap)
secondMap.put("day","日"),secondMap.put("week","周"),secondMap.put("month","月")
6.将List/array转为Map,将判断依据放到key,要获取的信息放到value,利用Map快速存取的特性实现快速判断集合中是否包含某个元素,从而提高程序的执行效率。
7.JSONArray->JSONObject->JSONString的转换:将JSONArray放到map中,由于JSONObject本身就是一个map,再通过JSON.toJSONString()方法将JSON对象转化为JSON字符串。
2.HashSet
HashSet是基于HashMap来实现的,底层采用HashMap来保存元素。
2.1定义
public class HashSet
extends AbstractSet
implements Set, Cloneable, java.io.Serializable
Set接口是一种不包含重复元素的collection,它维持它自己的内部排序,所以随机访问没有意义。简而言之,HashSet是无序、不重复的集合。(HashMap是按照HashCode大小进行排序)
2.2基本属性
//基于HashMap实现,底层使用HashMap保存所有元素
private transient HashMap map;
//定义一个Object对象作为HashMap的value
private static final Object PRESENT = new Object();
HashSet中的所有元素都是保存在HashMap的key中,value则是使用的PRESENT对象。由于HashMap中key不会重复,因此满足 了HashSet中元素不会重复的特性。
2.3什么时候用HashSet?
当集合元素需要去重且对元素的顺序没有要求时使用!例如:本项目中的获取所有原料单位、商品单位、菜单id。