程序员分前端与后端,那么后端程序员都做些什么?看完你就明白了!
我刚开始做Web开发的时候,根本没有前端,后端之说。
原因很简单,那个时候服务器端的代码就是一切:接受浏览器的请求,实现业务逻辑,访问数据库,用JSP生成HTML,然后发送给浏览器。
即使后来Javascript在浏览器中添加了一些AJAX的效果,那也是锦上添花,绝对不敢造次。因为页面的HTML主要还是用所谓“套模板”的方式生成:美工生成HTML模板,程序员用JSP,Veloctiy,FreeMaker等技术把动态的内容添加上去,仅此而已。
那个时候最流行的图是这个样子:
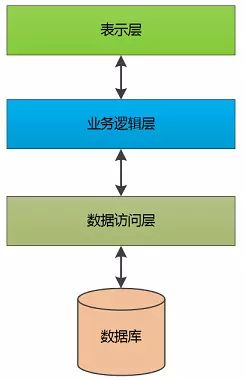
在最初的J2EE体系中,这个表示层可不仅仅是浏览器中运行的页面,还包括Java写的桌面端,只是Java在桌面端太不争气, 没有发展起来。
每个程序员都是所谓“全栈”工程师,不仅要搞定HTML, JavaScript, CSS,还要实现业务逻辑,编写访问数据库的代码。等到部署的时候,就把所有的代码打成一个WAR包,往Tomcat指定的目录一扔,测试一下没问题,收工回家!
不差钱的公司会把程序部署到Weblogic,Websphere这样的应用服务器中,还会用上高大上的EJB。
虽然看起来生活“简单”又“惬意”,但实际上也需要实现那些多变的、不讲逻辑的业务需求,苦逼的本质并没有改变。
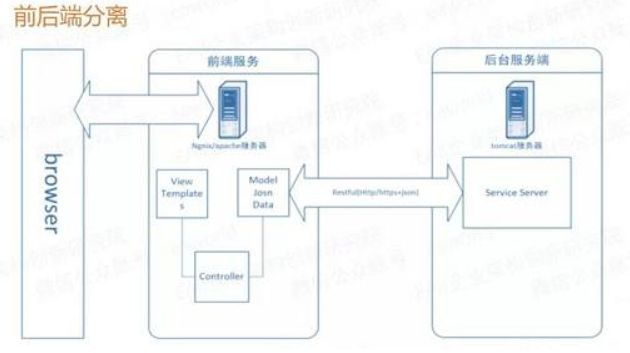
1、前后端的分离
随着大家对浏览器页面的视觉和交互要求越来越高,“套模板”的方式渐渐无法满足要求,这个所谓的表示层慢慢地迁移到浏览器当中去了,一大批像Angular, ReactJS之类的框架崛起,前后端分离了!
后端的工程师只负责提供接口和数据,专注于业务逻辑的实现,前端取到数据后在浏览器中展示,各司其职。
像Java这样的语言很适合去实现复杂的业务逻辑,尤其是一些MIS系统,行业软件如税务、电力、烟草、金融,通信等等。 所以剥离表示层,只做后端挺合适的。
但是如果仅仅是实现业务逻辑,那后端也不会需要这么多技术了,搞定SSH/SSM就行了。
2、后端技术
互联网,尤其是移动互联网开始兴起以后,海量的用户呼啸而来,一个单机部署的小小War包肯定是撑不住了,必须得做分布式。
原来的单个Tomcat得变成Tomcat的集群,前边弄个Web服务器做请求的负载均衡,不仅如此,还得考虑状态问题,session的一致性。
(注:参见文章《小白科普:分布式和集群》)
业务越来越复杂,我们不得不把某些业务放到一个机器(或集群)上,把另外一部分业务放到另外一个机器(或集群)上,虽然系统的计算能力,处理能力大大增强,但是这些系统之间的通信就变成了头疼的问题,消息队列(MQ),RPC框架(如Dubbo)应运而生,为了提高通信效率,各种序列化的工具(如Protobuf)也争先空后地问世。
单个数据库也撑不住了,那就做数据库的读写分离,如果还不行,就做分库和分表,把原有的数据库垂直地切一切,或者水平地切一切, 但不管怎么切,都会让应用程序的访问非常麻烦,因为数据要跨库做Join/排序,还需要事务,为了解决这个问题,又有各种各样“数据访问中间件”的工具和产品诞生。
为了最大程度地提高性能,缓存肯定少不了,可以在本机做缓存(如Ehcache),也可以做分布式缓存(如Redis),如何搞数据分片,数据迁移,失效转移,这又是一个超级大的主题了。
互联网用户喜欢上传图片和文件,还得搞一个分布式的文件系统(如FastDFS),要求高可用,高可靠。
数据量大了,搜索的需求就自然而然地浮出水面,你得弄一个支持全文索引的搜索引擎(如Elasticsearch ,Solr)出来。
林子大了,什么鸟都有,必须得考虑安全,数据的加密/解密,签名、证书,防止SQL注入,XSS/CSRF等各种攻击。

3、“大后端”
前面提到了这么多的系统,还都是分布式的,每次上线,运维的同学说:把这么多系统协调好,把老子都累死了。
得把持续集成做好,能自动化地部署,自动化测试(其实前端也是如此),后来出现了一个革命化的技术docker, 能够让开发、测试、生成环境保持一致,系统原来只是在环境(如Ngnix, JVM,Tomcat,MySQL等)上部署代码,现在把代码和环境一并打包, 运维的工作一下子就简化了。
公司自己购买服务器比较贵,维护也很麻烦,又难于弹性地增长,那就搞点虚拟的服务器吧,硬盘、内存都可以动态扩展(反正是虚拟的), 访问量大的时候多用点,没啥访问量了就释放一点,按需分配,很方便,这就是云计算的一个场景。
随着时间的推移,各个公司和系统收集的数据越来越多,都堆成一座大山了,难道就放在那里白白地浪费硬盘空间吗?
有人就惊奇地发现,咦,我们利用这些数据搞点事情啊, 比如把数据好好分析一下,预测一下这个用户的购买/阅读/浏览习惯,给他推荐一点东西嘛。
可是这么多数据,用传统的方式计算好几天甚至好几个月才能出个结果,到时候黄花菜都凉了,所以也得利用分布式的技术,想办法把计算分到各个计算机去,然后再把计算结果收回来, 时势造英雄,Hadoop及其生态系统就应运而生了。
之前听说过一个大前端的概念,把移动端和网页端都归结为“前端”,我这里造个词“大后端”,把那些用户直接接触不到的、发生在服务器端的都归结进来。想要在程序员生涯内有更高的成就的话,C/C++就是一个既可以强化思维能力,又可以打好编程基础的编程语言,要做软件开发,成为核心程序员的话,就来湫湫学习C/C++吧!你如果感觉自学C/C++语言有困难的话,C/C++编程学习,六零四,一六8和719。即使是零基础的学习者,都可以一起成长进步。

4、怎么学好后端?
现在无论是前端还是后端,技术领域多如牛毛,都严重地细分了,所以我认为真正的全栈工程师根本不存在,因为一个人精力有限,不可能搞定这么多技术领域,太难了。
培训机构所说的“全栈”,我认为就是前后端还在拉拉扯扯,藕断丝连,没有彻底分离的时候的“全栈”工程师。
那么问题来了, 后端这么多东西,我该怎么学?
之前写过一篇文章叫做《上天还是入地》,说了学习的广度和深度,在这里也是相通的。
往深度挖掘,可以成为某个技术领域的专家,如搜索方面的专家、安全方面的专家,分布式文件的专家等等,不管是哪个领域,重点都不是学会使用某个工具和框架, 而是保证你可以自己的知识和技术去搞定这个领域的顶尖问题。
往广度发展,各个技术领域都要了解,对于某种需求,能够选取合适的软件和技术架构来实现它,把需求转化成合适的技术组件,让这些组件以合适的方式连接、部署、运行,这也需要持续地学习和不断的经验积累。
最后,以一张漫画来结束吧!学习C/C++编程,欢迎关注微信公众号:C语言编程学习基地。
