Redis学习日记(三):Redis 主从复制
九、Redis复制原理和优化
1、什么是主从复制?
a、redis单机存在的问题:
redis单机部署非常不安全,具体可以表现为:
* 机器故障导致的 redis 服务停止,高可用问题,可以用 redis 的 主从复制来解决。
* redis 服务意外停止导致的服务停止和数据丢失,高可用问题,主从复制可以解决。
* redis 容量瓶颈 , redis 的qps瓶颈(每秒查询率),这些问题可以通过redis的分布式解决。(在之后的文笔中介绍)
b、 主从复制
从字面上理解就是有主redis和从redis,主从可以是1对1, 也可以是1对多,主节点只能为一个,从节点可以多个。
我们可以理解主从的关系为从节点会复制主节点的数据达到他们两者的数据一致性。
主从的数据流是单向的,只能从主(master)到从(slave)。
主从复制还能通过读写分离来实现请求的分流达到负载均衡(写数据到主节点,从从节点读数据)
2、复制的配置
a、命令方式
slaveof ip port :在连接到6379的客户端发送了如slaveof 127.0.0.1 6380 这样的命令,意思就是把当前节点6379当做从节点,6380当做主节点,在这个完成后6379就会进行对6380的同步数据操作。这个命令是异步的,在发出命令时就会返回结果,但实际执行结果可能并没这么快。
slaveof no one :解除当前客户端和绑定主节点的关系,执行后当前客户端就不再对之前主节点的复制。
命令方式不需要重启,可以直接生效,但是不便于管理。
b、配置文件方式
配置文件中的配置项:
slaveof ip port : 和命令一样,在配置的时候就绑定主节点。
slave-read-only yes :从节点只进行读数据而不进行写,这样保证了主从节点数据的一致性。
配置方式需要重启才生效,便于统一管理。
3、全量复制和部分复制
a、run_id 和 偏移量
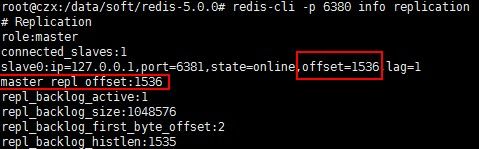
如这是主节点(6380) run_id 的信息,它唯一标识了一个redis的服务,用户区分不同的redis

关于这个 run_id ,我们可以看下之前主从复制时从节点(6381)的日志,我们可以看到从节点在复制主节点(6380)时就是用run_id来标识要复制的对象的。
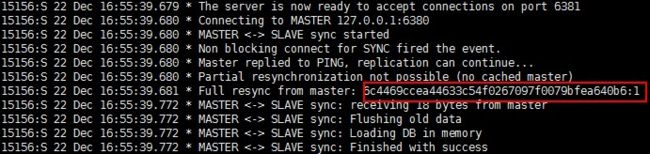
偏移量的信息可以看下图,这时主节点的偏移量信息,我们可以看到在主从同步是这个主从的偏移量是一致的,也就是说如果这个偏移量相差过大的话说明这个主从同步是存在问题的。
b、全量复制
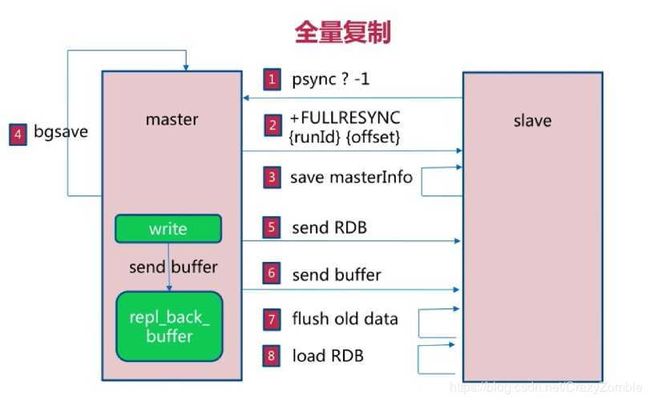
①、从节点请求全量同步,但是从节点不知道主节点的 run_id 和 offset ,所以这时携带的参数是 ? 和 -1
②、主节点统一全量复制,这时把自己的 run_id 和 offset 携带给从节点
③、从节点先存储主节点的信息
④、主节点开始bgsave , 保存RDB 文件, 准备给从节点同步
⑤、发送备份好的 RDB 文件给从节点
⑥、因为在开始 bgsave 开始到备份结束这段时间主节点主进程还在接收命令,所以这时的命令存入 缓存区,在发送完 RDB 文件后在把这 buffer 发送到从节点
⑦,⑧、从节点清旧数据,然后重新加载主节点的数据。
c、部分复制
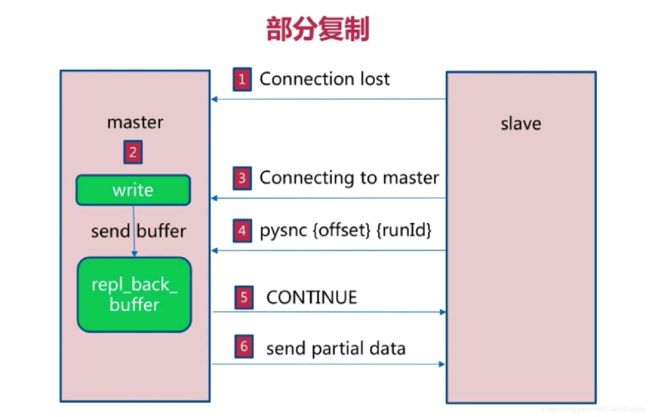
当master和slave断开连接时,master会将期间所做的操作记录到复制缓存区当中(可以看成是一个队列,其大小默认1M)。待slave重连后,slave会向master发送psync命令并传入offset和runId,这时候,如果master发现slave传输的偏移量的值,在缓存区队列范围中,就会将从offset开始到队列结束的数据传给slave,从而达到同步,降低了使用全量复制的开销。
4、开发运维常见问题
a、读写分离
读写分离 : 将数据写入主节点,从从节点读数据,mysql中也常使用。
读写分离的问题:
复制数据存在延迟(从节点阻塞的时候会变明显)。
读取到过期数据:主节点中保存的某个key过期了但是一直都没被删除,通过主从复制从节点就带着了这个key,但是主从复制的时候又不允许对从节点写,所以在读取从节点的时候就可能会读取到这个过期的key。这里得知道 删除过期数据的两个策略:①、懒惰策略:只有在使用到这个key 的时候再去查看他的ttl,如果过期了则删除并返回空;②、定时策略:定时从erpires字典中随机抽样一些key查看这个过期时间,如果这个key过期则删除。具体的策略可以参考这个简书上写的。redis的过期时间和过期删除机制
从节点故障,将连接这个从节点的客户端的迁移会比较困难。
b、主从配置不一致
1、主从节点 maxmemory 不一致 导致的数据丢失。
2、数据结构化参数 (例如hash-max-ziplist-entries)不同导致的 数据内存不一致问题。
c、规避全量复制

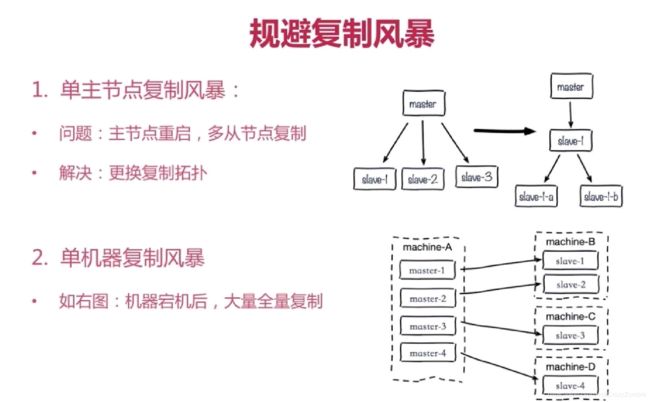
d、规避复制风暴
先了解下什么是复制风暴: 复制风暴是指例如当一个主节点因为某些原因而挂了然后重启后,从节点都从这个主节点同时同步数据导致的cpu,内存,i/o 飙升的问题。