Azure SQL DB/DW 系列(14)——使用Query Store(3)——常用场景
本文属于Azure SQL DB/DW系列
上一文:Azure SQL DB/DW 系列(13)——使用Query Store(2)——报表介绍(2)
本文继续如何使用Query Store的常用场景
前言
Query Store有很多用途,基于它的收集功能,很适合作为服务器的性能基线。性能基线是一个标准,用来后续判断服务器是否存在性能问题。所以专业的数据库及服务器运维,都应该制定合理的性能基线。
在启用了Query Store之后,可以收集一个时间区间的数据,这个区间根据INTERVAL_LENGTH_MINUTES而定。可以是1,5,10,15,60和1440分钟。
常用于做性能基线的报表是【总体资源消耗】:

通过这个报表,可以看到这个时间区间内,服务器及数据库的资源使用情况。比如上图(同样是借用网上的图),两天前活动很低,这两天是周末,所以从负载中大概可以猜出这是一个面向工作日使用的应用系统。同时观察到但凡持续时间很久的时候,逻辑读也很高,这个时候可以跳到【资源消耗量最大的几个查询】报表中查看具体的查询。
我们也可以使用下面语句查看最近10天内持续时间最长的10个查询:
SELECT TOP 10 qt.query_sql_text
,q.query_id
,so.name
,so.type
,SUM(rs.count_executions * rs.avg_duration) AS 'Total Duration'
FROM sys.query_store_query_text qt
INNER JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats rs ON p.plan_id = rs.plan_id
INNER JOIN sys.query_store_runtime_stats_interval rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
INNER JOIN sysobjects so ON so.id = q.object_id
WHERE rsi.start_time >= DATEADD(DAY, - 10, GETUTCDATE())
GROUP BY qt.query_sql_text
,q.query_id
,so.name
,so.type
ORDER BY SUM(rs.count_executions * rs.avg_duration_time) DESC
不过随着全球化的发展,很多时间已经是以UTC来存储,比如北京时间就是UTC+8。所以使用这个脚本时要注意转换。
除此之外还可以分析出现了计划回归的查询、发现资源消耗情况、修改配置后的对比,其实在我看来,Query Store可以很好地用于出大部分的报告。
使用Query Store创建性能基线
首先我们得知道Query Store收集了什么,哪些是我们需要的,哪些是要额外用其他工具收集的。
另外在收集和制定基线之前,记得先清空Query Store的数据以免数据混乱。可以通过GUI→数据库→属性→【查询存储】界面中的【清空Query Store】按钮来清空。也可以执行:
USE [<Database>]
GO
EXEC sys.sp_query_store_flush_db;
清空之后,可以开始运行负载,最好是现实环境。
在收集了一定时间之后,通常根据你的收集间隔而定,比如15分钟,那么15分钟后就可以停止或者开始新一轮的收集以便了解变化。
常见的使用是了解过去一小段时间特别是晚上发生了什么事,因为往往已经发生的事情要回查起来是更为困难的。
但是有了Query Store,回看过去某个时间段的情况就很简单了。
比如查看【资源消耗量最大的几个查询】中的配置,选择特定的时间:
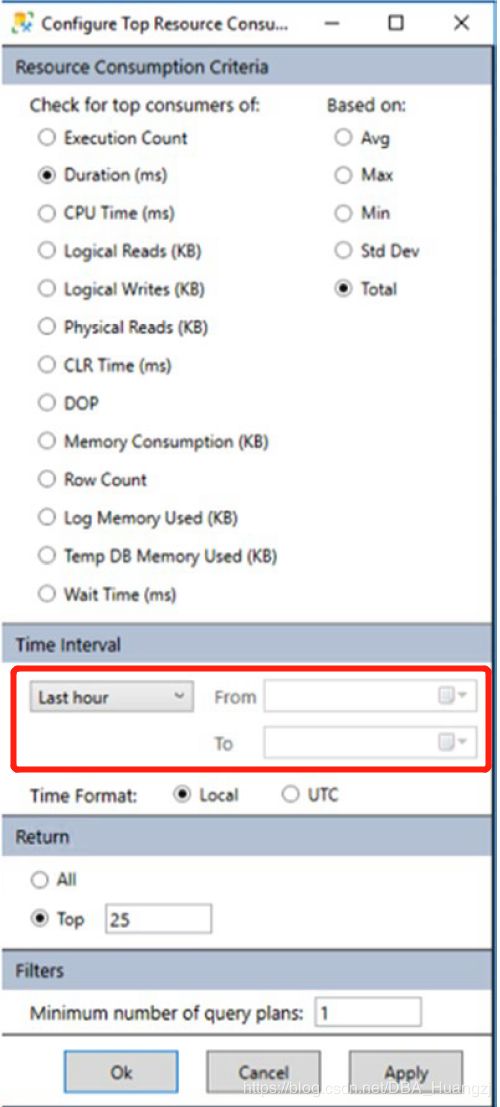
查找回归的查询
前面文章提到过,回归查询使得同样的查询性能出现不一样(通常是更差),产生回归的原因可能是统计信息的更新,数据分布的变化,索引的变化等等。由于优化器会根据实际情况选择更优的执行计划,这就往往会导致查询回归。这个时候就可以使用【回归的查询】报表。
在这个报表中,你可以在右上角的窗口中选择两个计划后,使用具有两个计划的查询,并使用右上角的比较计划按钮。那么执行计划的差异部分就会高亮:

同时属性也可以看出不一致:
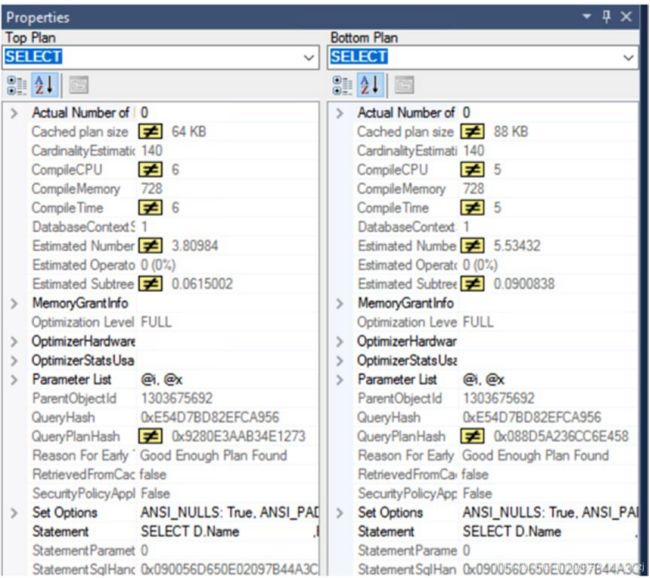
T-SQL 查询信息
Query Store本质上就是以存储为主,并显示7中预设报表,但是还有很多数据没有被利用出来,这个时候可以用一些T-SQL查询来发现它的价值,下面列出几个网上搜集的查询,供读者参考:
--查询文本的总数
SELECT COUNT(*) AS CountQueryTextRows
FROM sys.query_store_query_text;
--查询的总数
SELECT COUNT(*) AS CountQueryRows
FROM sys.query_store_query;
--唯一查询(也就是不同的查询)的数量
SELECT COUNT(DISTINCT query_hash) AS CountDifferentQueryRows
FROM sys.query_store_query;
--总执行计划数
SELECT COUNT(*) AS CountPlanRows
FROM sys.query_store_plan;
--不同执行计划的数量
SELECT COUNT(DISTINCT query_plan_hash) AS CountDifferentPlanRows
FROM sys.query_store_plan;
如果你发现CountQueryRows 和CountDifferentQueryRows 或者
CountPlanRows 和CountDifferentPlansRows之间存在差异,意味着你有一些类似的语句在运行,可能适合进行参数化。
--数据库中10个最近被执行的查询
SELECT
TOP 10 qt.query_sql_text, q.query_id, qt.query_text_id,
p.plan_id, rs.last_execution_time
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats rs ON p.plan_id = rs.plan_id
ORDER BY rs.last_execution_time DESC
--获取每个查询的执行次数
SELECT
q.query_id, qt.query_text_id,
qt.query_sql_text,
SUM(rs.count_executions) AS total_execution_count
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats rs ON p.plan_id = rs.plan_id
GROUP BY q.query_id, qt.query_text_id, qt.query_sql_text
ORDER BY total_execution_count DESC
--在最近一个小时内,平均执行时间最长的10个查询
SELECT
TOP 10 qt.query_sql_text,
q.query_id, qt.query_text_id, p.plan_id,
GETUTCDATE() AS CurrentUTCTime,
rs.last_execution_time, rs.avg_duration
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats rs ON p.plan_id = rs.plan_id
WHERE rs.last_execution_time > DATEADD(HOUR, -1, GETUTCDATE())
ORDER BY rs.avg_duration desc
--最近24小时内,10个平均物理I/O 读最高的查询
SELECT
TOP 10 qt.query_sql_text,
q.query_id, qt.query_text_id,
p.plan_id, rs.runtime_stats_id,
rsi.start_time, rsi.end_time,
rs.avg_physical_io_reads,
rs.avg_rowcount, rs.count_executions
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats rs ON p.plan_id = rs.plan_id
JOIN sys.query_store_runtime_stats_interval rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rsi.start_time >= DATEADD(HOUR, -24, GETUTCDATE())
ORDER BY rs.avg_physical_io_reads desc
--最近性能倒退(回归)的查询,条件是过去48小时内执行时间增长了一倍以上)
SELECT
qt.query_sql_text,
q.query_id,
p1.plan_id AS plan1,
rs2.avg_duration AS plan2
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p1 ON q.query_id = p1.query_id
JOIN sys.query_store_runtime_stats rs1 ON p1.plan_id = rs1.plan_id
JOIN sys.query_store_runtime_stats_interval rsi1 ON rsi1.runtime_stats_interval_id = rs1.runtime_stats_interval_id
JOIN sys.query_store_plan p2 ON q.query_id = p2.query_id
JOIN sys.query_store_runtime_stats rs2 ON p2.plan_id = rs2.plan_id
JOIN sys.query_store_runtime_stats_interval rsi2 ON rsi2.runtime_stats_interval_id = rs2.runtime_stats_interval_id
WHERE rsi1.start_time > DATEADD(HOUR, -48, GETUTCDATE()) AND
rsi2.start_time > rsi1.start_time AND
rs2.avg_duration > 2*rs1.avg_duration
--具有多个执行计划的查询
WITH QueryWithMultiplePlans
AS
(
SELECT COUNT(*) AS cnt, q.query_id
FROM sys.query_store_query_text qt
JOIN sys.query_store_query q ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan p ON p.query_id = q.query_id
GROUP BY q.query_id HAVING COUNT(DISTINCT plan_id) > 1
)
SELECT q.query_id, OBJECT_NAME(object_id) AS ContainingObject,
query_sql_text, plan_id, p.query_plan AS plan_xml, p.last_compile_start_time,
p.last_execution_time
FROM QueryWithMultiplePlans qm
JOIN sys.query_store_query q ON qm.query_id = q.query_id
JOIN sys.query_store_plan p ON q.query_id = p.query_id
JOIN sys.query_store_query_text qt ON qt.query_text_id = q.query_text_id
ORDER BY query_id, plan_id
如果后续有好的脚本也会继续补录。
总结
本文介绍了Query Store的常用场景,就我个人而言,首先它收集的数据很全面,其次预设报表已经非常完善,可以应对大部分问题。然后在深入了解之后,还可以自己定义一些查询来满足需求。本人在工作中使用到的情景并不是非常多,所以暂时不扩展开来。一旦有一定数量和质量的积累,会及时更新。