go源码阅读——malloc.go
【博文目录>>>】 【项目地址>>>】
内存分配器
golang内存分配最初是基于tcmalloc的,但是有很大的不同。tcmalloc文章:
参见:http://goog-perftools.sourceforge.net/doc/tcmalloc.html
翻译:https://blog.csdn.net/DERRANTCM/article/details/105342996
主分配器在大量页(runs of pages)中工作。将较小的分配大小(最大为32 kB,包括32 kB)舍入为大约70个大小类别之一,每个类别都有其自己的大小完全相同的空闲对象集。任何空闲的内存页都可以拆分为一个大小类别的对象集,然后使用空闲位图(free bitmap)进行管理。
分配器的数据结构为:
fixalloc:用于固定大小的堆外对象的空闲列表分配器,用于管理分配器使用的存储。
mheap:malloc堆,以页(8192字节)粒度进行管理。
mspan:由mheap管理的一系列使用中的页面。
mcentral:收集给定大小类的所有跨度。
mcache:具有可用空间的mspans的每P个缓存。
mstats:分配统计信息。
分配一个小对象沿用了高速缓存的层次结构:
- 1、将大小四舍五入为一个较小的类别,然后在此P的mcache中查看相应的mspan。扫描mspan的空闲位图以找到空闲位置(slot)。如果有空闲位置,分配它。这都可以在不获取锁的情况下完成。
- 2、如果mspan没有可用位置,则从mcentral的具有可用空间的所需size类的mspan列表中获取一个新的mspan。获得整个跨度(span)会摊销锁定mcentral的成本。
- 3、如果mcentral的mspan列表为空,从mheap获取一系列页以用于mspan。
- 4、如果mheap为空或没有足够大的页,则从操作系统中分配一组新的页(至少1MB)。分配大量页面将分摊与操作系统进行对话的成本。
清除mspan并释放对象沿用了类似的层次结构:
- 1、如果响应分配而清除了mspan,则将mspan返还到mcache以满足分配。
- 2、否则,如果mspan仍有已分配的对象,则将其放在mspan的size类别的mcentral空闲列表上。
- 3、否则,如果mspan中的所有对象都是空闲的,则mspan的页面将返回到mheap,并且mspan现在已失效。
分配和释放大对象直接使用mheap,而绕过mcache和mcentral。如果mspan.needzero为false,则mspan中的可用对象位置已被清零。否则,如果needzero为true,则在分配对象时将其清零。通过这种方式延迟归零有很多好处:
- 1、堆栈帧分配可以完全避免置零。
- 2、它具有更好的时间局部性,因为该程序可能即将写入内存。
- 3、我们不会将永远不会被重用的页面归零。
虚拟内存布局
堆由一组arena组成,这些arena在64位上为64MB,在32位(heapArenaBytes)上为4MB。每个arena的起始地址也与arena大小对齐。
每个arena都有一个关联的heapArena对象,该对象存储该arena的元数据:arena中所有字(word)的堆位图和arena中所有页的跨度(span)图。它们本身是堆外分配的。
由于arena是对齐的,因此可以将地址空间视为一系列arena帧(frame)。arena映射(mheap_.arenas)从arena帧号映射到*heapArena,对于不由Go堆支持的部分地址空间,映射为nil。arena映射的结构为两层数组,由“L1”arena映射和许多“ L2”arena映射组成;但是,由于arena很大,因此在许多体系结构上,arena映射都由一个大型L2映射组成。
arena地图覆盖了整个可用的地址空间,从而允许Go堆使用地址空间的任何部分。分配器尝试使arena保持连续,以便大跨度(以及大对象)可以跨越arena。
OS内存管理抽象层
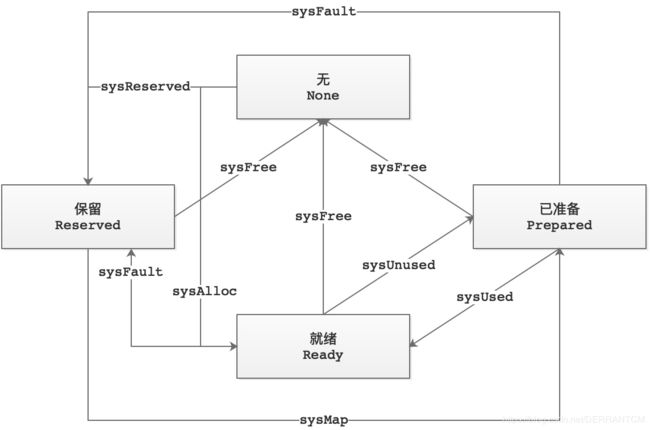
在任何给定时间,运行时管理的地址空间区域可能处于四种状态之一:
- 1)无(None)——未保留和未映射,这是任何区域的默认状态。
- 2)保留(Reserved)——运行时拥有,但是访问它会导致故障。不计入进程的内存占用。
- 3)已准备(Prepared)——保留,意在不由物理内存支持(尽管OS可能会延迟实现)。可以有效过渡到就绪。在这样的区域中访问内存是不确定的(可能会出错,可能会返回意外的零等)。
- 4)就绪(Ready)——可以安全地访问。
这组状态对于支持所有当前受支持的平台而言绝对不是必需的。只需一个“无”,“保留”和“就绪”就可以解决问题。但是,“已准备”状态为我们提供了用于性能目的的灵活性。例如,在POSIX-y操作系统上,“保留”通常是设置了PROT_NONE的私有匿名mmap’d区域,要转换到“就绪”状态,需要设置PROT_READ | PROT_WRITE。但是,Prepared的规格不足使我们仅使用MADV_FREE从Ready过渡到Prepared。因此,在“准备好”状态下,我们可以提早设置一次权限位,我们可以有效地告诉操作系统,当我们严格不需要它们时,可以自由地将页面从我们手中夺走。
对于每个操作系统,都有一组通用的帮助程序,这些帮助程序在这些状态之间转换内存区域。帮助程序如下:
sysAlloc
sysAlloc将OS选择的内存区域从“无”转换为“就绪”。更具体地说,它从操作系统中获取大量的零位内存,通常大约为一百千字节或兆字节。该内存始终可以立即使用。
sysFree
sysFree将内存区域从任何状态转换为“无(Ready)”。因此,它无条件返回内存。如果在分配过程中检测到内存不足错误,或用于划分出地址空间的对齐部分,则使用此方法。仅当sysReserve始终返回与堆分配器的对齐限制对齐的内存区域时,如果sysFree是无操作的,这是可以的。
sysReserve
sysReserve将内存区域从“无(None)”转换为“保留(Reserved)”。它以这样一种方式保留地址空间,即在访问时(通过权限或未提交内存)会导致致命错误。因此,这种保留永远不会受到物理内存的支持。如果传递给它的指针为非nil,则调用者希望在那里保留,但是sysReserve仍然可以选择另一个位置(如果该位置不可用)。
注意:sysReserve返回OS对齐的内存,但是堆分配器可能使用更大的对齐方式,因此调用者必须小心地重新对齐sysReserve获得的内存。
sysMap
sysMap将内存区域从“保留(Reserved)”状态转换为“已准备(Prepared)”状态。它确保可以将存储区域有效地转换为“就绪(Ready)”。
sysUsed
sysUsed将内存区域从“已准备(Prepared)”过渡到“就绪(Ready)”。它通知操作系统需要内存区域,并确保可以安全地访问该区域。在没有明确的提交步骤和严格的过量提交限制的系统上,这通常是不操作的,例如,在Windows上至关重要。
sysUnused
sysUnused将内存区域从“就绪(Ready)”转换为“已准备(Prepared)”。它通知操作系统,不再需要支持该内存区域的物理页,并且可以将其重新用于其他目的。 sysUnused内存区域的内容被认为是没用的,在调用sysUsed之前,不得再次访问该区域。
sysFault
sysFault将内存区域从“就绪(Ready)”或“已准备(Prepared)”转换为“保留(Reserved)”。它标记了一个区域,以便在访问时总是会发生故障。仅用于调试运行时。
状态转换图
hint的选择
64位机器
在64位计算机上,我们选择以下hit因为:
- 1、从地址空间的中间开始,可以轻松扩展到连续范围,而无需运行其他映射。
- 2、这使Go堆地址在调试时更容易识别。
- 3、gccgo中的堆栈扫描仍然很保守,因此将地址与其他数据区分开很重要。
从0x00c0开始意味着有效的内存地址将从0x00c0、0x00c1 … n 小端开始,即c0 00,c1 00,…这些都不是有效的UTF-8序列,否则它们是尽可能远离ff(可能是一个公共字节)。如果失败,我们尝试其他0xXXc0地址。较早的尝试使用0x11f8导致线程分配期间OS X上的内存不足错误。 0x00c0导致与AddressSanitizer发生冲突,后者保留了最多0x0100的所有内存。这些选择减少了保守的垃圾收集器不收集内存的可能性,因为某些非指针内存块具有与内存地址匹配的位模式。
但是,在arm64上,我们忽略了上面的所有建议,并在0x40 << 32处分配,因为当使用具有3级转换缓冲区的4k页面时,
用户地址空间在darwin/arm64上被限制为39位,地址空间更小。
在AIX上,对于64位,mmaps从0x0A00000000000000开始。
32位机器
在32位计算机上,我们更加关注保持可用堆是连续的。
因此:
- 1、我们为所有的heapArena保留空间,这样它们就不会与heap交错。 它们约为258MB,因此还算不错。(如果出现问题,我们可以在前面预留较小的空间。)
- 2、我们建议堆从二进制文件的末尾开始,因此我们有最大的机会保持其连续性。
- 3、我们尝试放出一个相当大的初始堆保留。
一些常量
- var zerobase uintptr:所有0字节分配的基地址
源码
// Memory allocator.
//
// This was originally based on tcmalloc, but has diverged quite a bit.
// http://goog-perftools.sourceforge.net/doc/tcmalloc.html
// The main allocator works in runs of pages.
// Small allocation sizes (up to and including 32 kB) are
// rounded to one of about 70 size classes, each of which
// has its own free set of objects of exactly that size.
// Any free page of memory can be split into a set of objects
// of one size class, which are then managed using a free bitmap.
//
// The allocator's data structures are:
//
// fixalloc: a free-list allocator for fixed-size off-heap objects,
// used to manage storage used by the allocator.
// mheap: the malloc heap, managed at page (8192-byte) granularity.
// mspan: a run of in-use pages managed by the mheap.
// mcentral: collects all spans of a given size class.
// mcache: a per-P cache of mspans with free space.
// mstats: allocation statistics.
//
// Allocating a small object proceeds up a hierarchy of caches:
//
// 1. Round the size up to one of the small size classes
// and look in the corresponding mspan in this P's mcache.
// Scan the mspan's free bitmap to find a free slot.
// If there is a free slot, allocate it.
// This can all be done without acquiring a lock.
//
// 2. If the mspan has no free slots, obtain a new mspan
// from the mcentral's list of mspans of the required size
// class that have free space.
// Obtaining a whole span amortizes the cost of locking
// the mcentral.
//
// 3. If the mcentral's mspan list is empty, obtain a run
// of pages from the mheap to use for the mspan.
//
// 4. If the mheap is empty or has no page runs large enough,
// allocate a new group of pages (at least 1MB) from the
// operating system. Allocating a large run of pages
// amortizes the cost of talking to the operating system.
//
// Sweeping an mspan and freeing objects on it proceeds up a similar
// hierarchy:
//
// 1. If the mspan is being swept in response to allocation, it
// is returned to the mcache to satisfy the allocation.
//
// 2. Otherwise, if the mspan still has allocated objects in it,
// it is placed on the mcentral free list for the mspan's size
// class.
//
// 3. Otherwise, if all objects in the mspan are free, the mspan's
// pages are returned to the mheap and the mspan is now dead.
//
// Allocating and freeing a large object uses the mheap
// directly, bypassing the mcache and mcentral.
//
// If mspan.needzero is false, then free object slots in the mspan are
// already zeroed. Otherwise if needzero is true, objects are zeroed as
// they are allocated. There are various benefits to delaying zeroing
// this way:
//
// 1. Stack frame allocation can avoid zeroing altogether.
//
// 2. It exhibits better temporal locality, since the program is
// probably about to write to the memory.
//
// 3. We don't zero pages that never get reused.
// Virtual memory layout
//
// The heap consists of a set of arenas, which are 64MB on 64-bit and
// 4MB on 32-bit (heapArenaBytes). Each arena's start address is also
// aligned to the arena size.
//
// Each arena has an associated heapArena object that stores the
// metadata for that arena: the heap bitmap for all words in the arena
// and the span map for all pages in the arena. heapArena objects are
// themselves allocated off-heap.
//
// Since arenas are aligned, the address space can be viewed as a
// series of arena frames. The arena map (mheap_.arenas) maps from
// arena frame number to *heapArena, or nil for parts of the address
// space not backed by the Go heap. The arena map is structured as a
// two-level array consisting of a "L1" arena map and many "L2" arena
// maps; however, since arenas are large, on many architectures, the
// arena map consists of a single, large L2 map.
//
// The arena map covers the entire possible address space, allowing
// the Go heap to use any part of the address space. The allocator
// attempts to keep arenas contiguous so that large spans (and hence
// large objects) can cross arenas.
/**
* 内存分配器
*
* 这最初是基于tcmalloc的,但是有很大的不同。
* 参见:http://goog-perftools.sourceforge.net/doc/tcmalloc.html
* 翻译:https://blog.csdn.net/DERRANTCM/article/details/105342996
*
* 主分配器在大量页(runs of pages)中工作。
* 将较小的分配大小(最大为32 kB,包括32 kB)舍入为大约70个大小类别之一,每个类别都有其自己的大小完全相同的空闲对象集。
* 任何空闲的内存页都可以拆分为一个大小类别的对象集,然后使用空闲位图(free bitmap)进行管理。
*
* 分配器的数据结构为:
*
* fixalloc:用于固定大小的堆外对象的空闲列表分配器,用于管理分配器使用的存储。
* mheap:malloc堆,以页(8192字节)粒度进行管理。
* mspan:由mheap管理的一系列使用中的页面。
* mcentral:收集给定大小类的所有跨度。
* mcache:具有可用空间的mspans的每P个缓存。
* mstats:分配统计信息。
*
* 分配一个小对象沿用了高速缓存的层次结构:
*
* 1.将大小四舍五入为一个较小的类别,然后在此P的mcache中查看相应的mspan。
* 扫描mspan的空闲位图以找到空闲位置(slot)。如果有空闲位置,分配它。这都可以在不获取锁的情况下完成。
*
* 2.如果mspan没有可用位置,则从mcentral的具有可用空间的所需size类的mspan列表中获取一个新的mspan。
* 获得整个跨度(span)会摊销锁定mcentral的成本。
*
* 3.如果mcentral的mspan列表为空,从mheap获取一系列页以用于mspan。
*
* 4.如果mheap为空或没有足够大的页,则从操作系统中分配一组新的页(至少1MB)。
* 分配大量页面将分摊与操作系统进行对话的成本。
*
* 清除mspan并释放对象沿用了类似的层次结构:
*
* 1.如果响应分配而清除了mspan,则将mspan返还到mcache以满足分配。
*
* 2.否则,如果mspan仍有已分配的对象,则将其放在mspan的size类别的mcentral空闲列表上。
*
* 3.否则,如果mspan中的所有对象都是空闲的,则mspan的页面将返回到mheap,并且mspan现在已失效。
*
* 分配和释放大对象直接使用mheap,而绕过mcache和mcentral。
*
* 如果mspan.needzero为false,则mspan中的可用对象位置已被清零。否则,如果needzero为true,
* 则在分配对象时将其清零。通过这种方式延迟归零有很多好处:
*
* 1.堆栈帧分配可以完全避免置零。
*
* 2.它具有更好的时间局部性,因为该程序可能即将写入内存。
*
* 3.我们不会将永远不会被重用的页面归零。
*
* 虚拟内存布局
*
* 堆由一组arena组成,这些arena在64位上为64MB,在32位(heapArenaBytes)上为4MB。
* 每个arena的起始地址也与arena大小对齐。
*
* 每个arena都有一个关联的heapArena对象,该对象存储该arena的元数据:arena中所有字(word)的堆位图
* 和arena中所有页的跨度(span)图。它们本身是堆外分配的。
*
* 由于arena是对齐的,因此可以将地址空间视为一系列arena帧(frame)。arena映射(mheap_.arenas)
* 从arena帧号映射到*heapArena,对于不由Go堆支持的部分地址空间,映射为nil。arena映射的结构为两层数组,
* 由“L1”arena映射和许多“ L2”arena映射组成;但是,由于arena很大,因此在许多体系结构上,
* arena映射都由一个大型L2映射组成。
*
* arena地图覆盖了整个可用的地址空间,从而允许Go堆使用地址空间的任何部分。分配器尝试使arena保持连续,
* 以便大跨度(以及大对象)可以跨越arena。
**/
package runtime
import (
"runtime/internal/atomic"
"runtime/internal/math"
"runtime/internal/sys"
"unsafe"
)
const (
debugMalloc = false
maxTinySize = _TinySize
tinySizeClass = _TinySizeClass
maxSmallSize = _MaxSmallSize
pageShift = _PageShift
pageSize = _PageSize
pageMask = _PageMask
// By construction, single page spans of the smallest object class
// have the most objects per span.
// 通过构造,对象类别最小的单个页面跨度在每个跨度中具有最多的对象。
// 每个跨度的最大多对象数
maxObjsPerSpan = pageSize / 8
concurrentSweep = _ConcurrentSweep
_PageSize = 1 << _PageShift
_PageMask = _PageSize - 1
// _64bit = 1 on 64-bit systems, 0 on 32-bit systems
// _64bit = 1在64位系统上,0在32位系统上
_64bit = 1 << (^uintptr(0) >> 63) / 2
// Tiny allocator parameters, see "Tiny allocator" comment in malloc.go.
// Tiny分配器参数,请参阅malloc.go中的“Tiny分配器”注释。在mallocgc方法中
_TinySize = 16
_TinySizeClass = int8(2)
// FixAlloc的块大小
_FixAllocChunk = 16 << 10 // Chunk size for FixAlloc
// Per-P, per order stack segment cache size.
// 每个P,每个order堆栈段的缓存大小。
_StackCacheSize = 32 * 1024
// Number of orders that get caching. Order 0 is FixedStack
// and each successive order is twice as large.
// We want to cache 2KB, 4KB, 8KB, and 16KB stacks. Larger stacks
// will be allocated directly.
// Since FixedStack is different on different systems, we
// must vary NumStackOrders to keep the same maximum cached size.
// 获得缓存的order数。Order 0是FixedStack,每个连续的order是其两倍。
// 我们要缓存2KB,4KB,8KB和16KB堆栈。较大的堆栈将直接分配。
// 由于FixedStack在不同的系统上是不同的,因此我们必须改变NumStackOrders以保持相同的最大缓存大小。
// 下面是不同的操作系统对应的FixedStack和NumStackOrders的对应表
// OS | FixedStack | NumStackOrders
// -----------------+------------+---------------
// linux/darwin/bsd | 2KB | 4
// windows/32 | 4KB | 3
// windows/64 | 8KB | 2
// plan9 | 4KB | 3
_NumStackOrders = 4 - sys.PtrSize/4*sys.GoosWindows - 1*sys.GoosPlan9
// heapAddrBits is the number of bits in a heap address. On
// amd64, addresses are sign-extended beyond heapAddrBits. On
// other arches, they are zero-extended.
//
// On most 64-bit platforms, we limit this to 48 bits based on a
// combination of hardware and OS limitations.
//
// amd64 hardware limits addresses to 48 bits, sign-extended
// to 64 bits. Addresses where the top 16 bits are not either
// all 0 or all 1 are "non-canonical" and invalid. Because of
// these "negative" addresses, we offset addresses by 1<<47
// (arenaBaseOffset) on amd64 before computing indexes into
// the heap arenas index. In 2017, amd64 hardware added
// support for 57 bit addresses; however, currently only Linux
// supports this extension and the kernel will never choose an
// address above 1<<47 unless mmap is called with a hint
// address above 1<<47 (which we never do).
//
// arm64 hardware (as of ARMv8) limits user addresses to 48
// bits, in the range [0, 1<<48).
//
// ppc64, mips64, and s390x support arbitrary 64 bit addresses
// in hardware. On Linux, Go leans on stricter OS limits. Based
// on Linux's processor.h, the user address space is limited as
// follows on 64-bit architectures:
// heapAddrBits是堆地址中的位数。在amd64上,地址被符号扩展到heapAddrBits之外。在其他架构上,它们是零扩展的。
//
// 在大多数64位平台上,基于硬件和操作系统限制的组合,我们将其限制为48位。
//
// amd64硬件将地址限制为48位,符号扩展为64位。前16位不全为0或全为1的地址是“非规范的”且无效。
// 由于存在这些“负”地址,因此在计算进入堆竞技场索引的索引之前,在amd64上将地址偏移1 << 47(arenaBaseOffset)。
// 2017年,amd64硬件增加了对57位地址的支持;但是,当前只有Linux支持此扩展,内核将永远不会选择大于1 << 47的地址,
// 除非调用mmap的提示地址大于1 << 47(我们从未这样做)。
//
// arm64硬件(自ARMv8起)将用户地址限制为48位,范围为[0,1 << 48)。
//
// ppc64,mips64和s390x在硬件中支持任意64位地址。在Linux上,Go依靠更严格的OS限制。
// 基于Linux的processor.h,在64位体系结构上,用户地址空间受到如下限制:
//
// Architecture Name Maximum Value (exclusive)
// ---------------------------------------------------------------------
// amd64 TASK_SIZE_MAX 0x007ffffffff000 (47 bit addresses)
// arm64 TASK_SIZE_64 0x01000000000000 (48 bit addresses)
// ppc64{,le} TASK_SIZE_USER64 0x00400000000000 (46 bit addresses)
// mips64{,le} TASK_SIZE64 0x00010000000000 (40 bit addresses)
// s390x TASK_SIZE 1<<64 (64 bit addresses)
//
// These limits may increase over time, but are currently at
// most 48 bits except on s390x. On all architectures, Linux
// starts placing mmap'd regions at addresses that are
// significantly below 48 bits, so even if it's possible to
// exceed Go's 48 bit limit, it's extremely unlikely in
// practice.
//
// On 32-bit platforms, we accept the full 32-bit address
// space because doing so is cheap.
// mips32 only has access to the low 2GB of virtual memory, so
// we further limit it to 31 bits.
//
// On darwin/arm64, although 64-bit pointers are presumably
// available, pointers are truncated to 33 bits. Furthermore,
// only the top 4 GiB of the address space are actually available
// to the application, but we allow the whole 33 bits anyway for
// simplicity.
// TODO(mknyszek): Consider limiting it to 32 bits and using
// arenaBaseOffset to offset into the top 4 GiB.
//
// WebAssembly currently has a limit of 4GB linear memory.
// 这些限制可能会随时间增加,但目前最多为48位,但s390x除外。在所有体系结构上,
// Linux都开始将mmap'd区域放置在明显低于48位的地址上,因此,即使有可能超过Go的48位限制,在实践中也极不可能。
//
// 在32位平台上,我们接受完整的32位地址空间,因为这样做很便宜。 mips32仅可以访问2GB的低虚拟内存,
// 因此我们进一步将其限制为31位。
//
// 在darwin / arm64上,尽管大概可以使用64位指针,但指针会被截断为33位。此外,
// 只有地址空间的前4个GiB实际上可供应用程序使用,但是为了简单起见,我们还是允许全部33位。
// TODO(mknyszek):考虑将其限制为32位,并使用arenaBaseOffset偏移到前4个GiB中。
//
// WebAssembly当前限制为4GB线性内存。
// heapAddrBits:堆空间地址位数,间接表示了他可以支持的最大的内存空间
heapAddrBits = (_64bit*(1-sys.GoarchWasm)*(1-sys.GoosDarwin*sys.GoarchArm64))*48 + (1-_64bit+sys.GoarchWasm)*(32-(sys.GoarchMips+sys.GoarchMipsle)) + 33*sys.GoosDarwin*sys.GoarchArm64
// maxAlloc is the maximum size of an allocation. On 64-bit,
// it's theoretically possible to allocate 1<
// 32-bit, however, this is one less than 1<<32 because the
// number of bytes in the address space doesn't actually fit
// in a uintptr.
// maxAlloc是分配的最大大小。在64位上,理论上可以分配1 << heapAddrBits字节。
// 但是,在32位上,这比1<<32小1,因为地址空间中的字节数实际上不适合uintptr。
maxAlloc = (1 << heapAddrBits) - (1-_64bit)*1
// The number of bits in a heap address, the size of heap
// arenas, and the L1 and L2 arena map sizes are related by
//
// (1 << addr bits) = arena size * L1 entries * L2 entries
//
// Currently, we balance these as follows:
// 堆地址中的位数,堆arena的大小以及L1和L2 arena映射的大小与
//
// 1 << addr位)=arena大小* L1条目* L2条目
//
// 目前,我们将这些平衡如下:
//
// Platform Addr bits Arena size L1 entries L2 entries
// -------------- --------- ---------- ---------- -----------
// */64-bit 48 64MB 1 4M (32MB)
// windows/64-bit 48 4MB 64 1M (8MB)
// */32-bit 32 4MB 1 1024 (4KB)
// */mips(le) 31 4MB 1 512 (2KB)
// heapArenaBytes is the size of a heap arena. The heap
// consists of mappings of size heapArenaBytes, aligned to
// heapArenaBytes. The initial heap mapping is one arena.
//
// This is currently 64MB on 64-bit non-Windows and 4MB on
// 32-bit and on Windows. We use smaller arenas on Windows
// because all committed memory is charged to the process,
// even if it's not touched. Hence, for processes with small
// heaps, the mapped arena space needs to be commensurate.
// This is particularly important with the race detector,
// since it significantly amplifies the cost of committed
// memory.
// heapArenaBytes是堆arenas的大小。堆由大小为heapArenaBytes的映射组成,
// 并与heapArenaBytes对齐。最初的堆映射是一个arenas。
//
// 当前在64位非Windows上为64MB,在32位和Windows上为4MB。我们在Windows上使用较小的arenas,
// 因为所有已提交的内存都由进程负责,即使未涉及也是如此。因此,对于具有小堆的进程,映射的arenas空间需要相对应。
// 这对于竞争检测器尤其重要,因为它会大大增加已提交内存的成本。
heapArenaBytes = 1 << logHeapArenaBytes
// logHeapArenaBytes is log_2 of heapArenaBytes. For clarity,
// prefer using heapArenaBytes where possible (we need the
// constant to compute some other constants).
// logHeapArenaBytes是heapArenaBytes的log_2。为了清楚起见,
// 最好在可能的地方使用heapArenaBytes(我们需要使用常量来计算其他常量)。
logHeapArenaBytes = (6+20)*(_64bit*(1-sys.GoosWindows)*(1-sys.GoarchWasm)) + (2+20)*(_64bit*sys.GoosWindows) + (2+20)*(1-_64bit) + (2+20)*sys.GoarchWasm
// heapArenaBitmapBytes is the size of each heap arena's bitmap.
// heapArenaBitmapBytes是每个堆arena的位图大小。
heapArenaBitmapBytes = heapArenaBytes / (sys.PtrSize * 8 / 2)
// 每个arena所的页数
pagesPerArena = heapArenaBytes / pageSize
// arenaL1Bits is the number of bits of the arena number
// covered by the first level arena map.
//
// This number should be small, since the first level arena
// map requires PtrSize*(1<
// binary's BSS. It can be zero, in which case the first level
// index is effectively unused. There is a performance benefit
// to this, since the generated code can be more efficient,
// but comes at the cost of having a large L2 mapping.
//
// We use the L1 map on 64-bit Windows because the arena size
// is small, but the address space is still 48 bits, and
// there's a high cost to having a large L2.
// arenaL1Bits是第一级arena映射覆盖的arena编号的位数。
//
// 这个数字应该很小,因为第一级arena映射在二进制文件的BSS中需要PtrSize*(1<
// 它可以为零,在这种情况下,第一级索引实际上未被使用。这会带来性能上的好处,
// 因为生成的代码可以更高效,但是以拥有较大的L2映射为代价。
//
// 我们在64位Windows上使用L1映射,因为arena大小很小,但是地址空间仍然是48位,并且拥有大型L2的成本很高。
arenaL1Bits = 6 * (_64bit * sys.GoosWindows)
// arenaL2Bits is the number of bits of the arena number
// covered by the second level arena index.
//
// The size of each arena map allocation is proportional to
// 1<
// large. 48 bits leads to 32MB arena index allocations, which
// is about the practical threshold.
// arenaL2Bits是第二级arena索引覆盖的arena编号的位数。
//
// 每个arena映射分配的大小与1<
// 48位导致32MB arena索引分配,这大约是实际的阈值。
arenaL2Bits = heapAddrBits - logHeapArenaBytes - arenaL1Bits
// arenaL1Shift is the number of bits to shift an arena frame
// number by to compute an index into the first level arena map.
// arenaL1Shift是将arena帧号移位以计算进入第一级arena映射的索引的位数。
arenaL1Shift = arenaL2Bits
// arenaBits is the total bits in a combined arena map index.
// This is split between the index into the L1 arena map and
// the L2 arena map.
// arenaBits是组合的arena映射索引中的总位。这在进入L1 arena映射和L2 arena映射的索引之间进行划分。
arenaBits = arenaL1Bits + arenaL2Bits
// arenaBaseOffset is the pointer value that corresponds to
// index 0 in the heap arena map.
//
// On amd64, the address space is 48 bits, sign extended to 64
// bits. This offset lets us handle "negative" addresses (or
// high addresses if viewed as unsigned).
//
// On aix/ppc64, this offset allows to keep the heapAddrBits to
// 48. Otherwize, it would be 60 in order to handle mmap addresses
// (in range 0x0a00000000000000 - 0x0afffffffffffff). But in this
// case, the memory reserved in (s *pageAlloc).init for chunks
// is causing important slowdowns.
//
// On other platforms, the user address space is contiguous
// and starts at 0, so no offset is necessary.
// arenaBaseOffset是与堆arena映射中的索引0对应的指针值。
//
// 在amd64上,地址空间为48位,符号扩展为64位。此偏移量使我们可以处理“负”地址(如果视为无符号,则为高地址)。
//
// 在aix/ppc64上,此偏移量允许将heapAddrBits保持为48。否则,为了处理mmap地址
//(范围为0x0a00000000000000-0x0afffffffffffffff),它将为60。但是在这种情况下,
// (s*pageAlloc).init中为块保留的内存会导致严重的速度下降。
//
// 在其他平台上,用户地址空间是连续的,并且从0开始,因此不需要偏移量。
arenaBaseOffset = sys.GoarchAmd64*(1<<47) + (^0x0a00000000000000+1)&uintptrMask*sys.GoosAix
// Max number of threads to run garbage collection.
// 2, 3, and 4 are all plausible maximums depending
// on the hardware details of the machine. The garbage
// collector scales well to 32 cpus.
// 运行垃圾回收的最大线程数。 2、3和4都是合理的最大值,具体取决于机器的硬件细节。 垃圾收集器可以很好地扩展到32 cpus。
_MaxGcproc = 32
// minLegalPointer is the smallest possible legal pointer.
// This is the smallest possible architectural page size,
// since we assume that the first page is never mapped.
//
// This should agree with minZeroPage in the compiler.
//
// minLegalPointer是最小的合法指针。 这是可能的最小体系架构页大小,因为我们假设第一页从未映射过。
//这应该与编译器中的minZeroPage一致。
minLegalPointer uintptr = 4096
)
// physPageSize is the size in bytes of the OS's physical pages.
// Mapping and unmapping operations must be done at multiples of
// physPageSize.
//
// This must be set by the OS init code (typically in osinit) before
// mallocinit.
//
// physPageSize是操作系统物理页面的大小(以字节为单位)。
// 映射和取消映射操作必须以physPageSize的倍数完成。
//
// 必须在mallocinit之前通过OS初始化代码(通常在osinit中)进行设置。
var physPageSize uintptr
// physHugePageSize is the size in bytes of the OS's default physical huge
// page size whose allocation is opaque to the application. It is assumed
// and verified to be a power of two.
//
// If set, this must be set by the OS init code (typically in osinit) before
// mallocinit. However, setting it at all is optional, and leaving the default
// value is always safe (though potentially less efficient).
//
// Since physHugePageSize is always assumed to be a power of two,
// physHugePageShift is defined as physHugePageSize == 1 << physHugePageShift.
// The purpose of physHugePageShift is to avoid doing divisions in
// performance critical functions.
//
// physHugePageSize是操作系统默认物理大页面大小的大小(以字节为单位),
// 该大小对于应用程序是不透明的。 假定并验证为2的幂。
//
// 如果已设置,则必须在mallocinit之前通过OS初始化代码(通常在osinit中)进行设置。
// 但是,完全设置它是可选的,并且保留默认值始终是安全的(尽管可能会降低效率)。
//
// 由于physHugePageSize始终假定为2的幂,因此physHugePageShift定义为physHugePageSize == 1 << physHugePageShift。
// physHugePageShift的目的是避免对性能至关重要的功能进行划分。
var (
physHugePageSize uintptr
physHugePageShift uint
)
// OS memory management abstraction layer
//
// Regions of the address space managed by the runtime may be in one of four
// states at any given time:
// 1) None - Unreserved and unmapped, the default state of any region.
// 2) Reserved - Owned by the runtime, but accessing it would cause a fault.
// Does not count against the process' memory footprint.
// 3) Prepared - Reserved, intended not to be backed by physical memory (though
// an OS may implement this lazily). Can transition efficiently to
// Ready. Accessing memory in such a region is undefined (may
// fault, may give back unexpected zeroes, etc.).
// 4) Ready - may be accessed safely.
//
// This set of states is more than is strictly necessary to support all the
// currently supported platforms. One could get by with just None, Reserved, and
// Ready. However, the Prepared state gives us flexibility for performance
// purposes. For example, on POSIX-y operating systems, Reserved is usually a
// private anonymous mmap'd region with PROT_NONE set, and to transition
// to Ready would require setting PROT_READ|PROT_WRITE. However the
// underspecification of Prepared lets us use just MADV_FREE to transition from
// Ready to Prepared. Thus with the Prepared state we can set the permission
// bits just once early on, we can efficiently tell the OS that it's free to
// take pages away from us when we don't strictly need them.
//
// For each OS there is a common set of helpers defined that transition
// memory regions between these states. The helpers are as follows:
//
// sysAlloc transitions an OS-chosen region of memory from None to Ready.
// More specifically, it obtains a large chunk of zeroed memory from the
// operating system, typically on the order of a hundred kilobytes
// or a megabyte. This memory is always immediately available for use.
//
// sysFree transitions a memory region from any state to None. Therefore, it
// returns memory unconditionally. It is used if an out-of-memory error has been
// detected midway through an allocation or to carve out an aligned section of
// the address space. It is okay if sysFree is a no-op only if sysReserve always
// returns a memory region aligned to the heap allocator's alignment
// restrictions.
//
// sysReserve transitions a memory region from None to Reserved. It reserves
// address space in such a way that it would cause a fatal fault upon access
// (either via permissions or not committing the memory). Such a reservation is
// thus never backed by physical memory.
// If the pointer passed to it is non-nil, the caller wants the
// reservation there, but sysReserve can still choose another
// location if that one is unavailable.
// NOTE: sysReserve returns OS-aligned memory, but the heap allocator
// may use larger alignment, so the caller must be careful to realign the
// memory obtained by sysReserve.
//
// sysMap transitions a memory region from Reserved to Prepared. It ensures the
// memory region can be efficiently transitioned to Ready.
//
// sysUsed transitions a memory region from Prepared to Ready. It notifies the
// operating system that the memory region is needed and ensures that the region
// may be safely accessed. This is typically a no-op on systems that don't have
// an explicit commit step and hard over-commit limits, but is critical on
// Windows, for example.
//
// sysUnused transitions a memory region from Ready to Prepared. It notifies the
// operating system that the physical pages backing this memory region are no
// longer needed and can be reused for other purposes. The contents of a
// sysUnused memory region are considered forfeit and the region must not be
// accessed again until sysUsed is called.
//
// sysFault transitions a memory region from Ready or Prepared to Reserved. It
// marks a region such that it will always fault if accessed. Used only for
// debugging the runtime.
/**
* OS内存管理抽象层
*
* 在任何给定时间,运行时管理的地址空间区域可能处于四种状态之一:
* - 1)无(None)——未保留和未映射,这是任何区域的默认状态。
* - 2)保留(Reserved)——运行时拥有,但是访问它会导致故障。不计入进程的内存占用。
* - 3)已准备(Prepared)——保留,意在不由物理内存支持(尽管OS可能会延迟实现)。
* 可以有效过渡到就绪。在这样的区域中访问内存是不确定的(可能会出错,可能会返回意外的零等)。
* - 4)就绪(Ready)——可以安全地访问。
*
* 这组状态对于支持所有当前受支持的平台而言绝对不是必需的。只需一个“无”,“保留”和“就绪”就可以解决问题。
* 但是,“已准备”状态为我们提供了用于性能目的的灵活性。例如,在POSIX-y操作系统上,“保留”通常是设置了PROT_NONE的私有匿名mmap'd区域,
* 要转换到“就绪”状态,需要设置PROT_READ | PROT_WRITE。但是,Prepared的规格不足使我们仅使用MADV_FREE从Ready过渡到Prepared。
* 因此,在“准备好”状态下,我们可以提早设置一次权限位,我们可以有效地告诉操作系统,当我们严格不需要它们时,可以自由地将页面从我们手中夺走。
*
* 对于每个操作系统,都有一组通用的帮助程序,这些帮助程序在这些状态之间转换内存区域。帮助程序如下:
*
* sysAlloc
* sysAlloc将OS选择的内存区域从“无”转换为“就绪”。更具体地说,它从操作系统中获取大量的零位内存,通常大约为一百千字节或兆字节。
* 该内存始终可以立即使用。
*
* sysFree
* sysFree将内存区域从任何状态转换为“无(Ready)”。因此,它无条件返回内存。如果在分配过程中检测到内存不足错误,
* 或用于划分出地址空间的对齐部分,则使用此方法。仅当sysReserve始终返回与堆分配器的对齐限制对齐的内存区域时,
* 如果sysFree是无操作的,这是可以的。
*
* sysReserve
* sysReserve将内存区域从“无(None)”转换为“保留(Reserved)”。它以这样一种方式保留地址空间,
* 即在访问时(通过权限或未提交内存)会导致致命错误。因此,这种保留永远不会受到物理内存的支持。如果传递给它的指针为非nil,
* 则调用者希望在那里保留,但是sysReserve仍然可以选择另一个位置(如果该位置不可用)。
*
* 注意:sysReserve返回OS对齐的内存,但是堆分配器可能使用更大的对齐方式,因此调用者必须小心地重新对齐sysReserve获得的内存。
*
* sysMap
* sysMap将内存区域从“保留(Reserved)”状态转换为“已准备(Prepared)”状态。它确保可以将存储区域有效地转换为“就绪(Ready)”。
*
* sysUsed
* sysUsed将内存区域从“已准备(Prepared)”过渡到“就绪(Ready)”。它通知操作系统需要内存区域,并确保可以安全地访问该区域。
* 在没有明确的提交步骤和严格的过量提交限制的系统上,这通常是不操作的,例如,在Windows上至关重要。
*
* sysUnused
* sysUnused将内存区域从“就绪(Ready)”转换为“已准备(Prepared)”。它通知操作系统,不再需要支持该内存区域的物理页,
* 并且可以将其重新用于其他目的。 sysUnused内存区域的内容被认为是没用的,在调用sysUsed之前,不得再次访问该区域。
*
* sysFault
* sysFault将内存区域从“就绪(Ready)”或“已准备(Prepared)”转换为“保留(Reserved)”。它标记了一个区域,
* 以便在访问时总是会发生故障。仅用于调试运行时。
**/
func mallocinit() {
// 检查_TinySizeClass与_TinySize对应关系
if class_to_size[_TinySizeClass] != _TinySize {
throw("bad TinySizeClass")
}
// 确保映射到相同defer大小类别的defer arg大小也映射到相同的malloc大小类别。
testdefersizes()
// 判断heapArenaBitmapBytes是否是2的指数次方
if heapArenaBitmapBytes&(heapArenaBitmapBytes-1) != 0 {
// heapBits expects modular arithmetic on bitmap
// addresses to work.
// heapBits希望对位图地址进行模块化算术运算。
throw("heapArenaBitmapBytes not a power of 2")
}
// Copy class sizes out for statistics table.
// 将类别大小拷贝到统计表
for i := range class_to_size {
memstats.by_size[i].size = uint32(class_to_size[i])
}
// Check physPageSize.
// 检查physPageSize。
if physPageSize == 0 {
// The OS init code failed to fetch the physical page size.
// 操作系统初始化代码无法获取物理页面大小。
throw("failed to get system page size")
}
// 物理页大小比最大物理页还大
if physPageSize > maxPhysPageSize {
print("system page size (", physPageSize, ") is larger than maximum page size (", maxPhysPageSize, ")\n")
throw("bad system page size")
}
// 物理页大小比最小物理页还小
if physPageSize < minPhysPageSize {
print("system page size (", physPageSize, ") is smaller than minimum page size (", minPhysPageSize, ")\n")
throw("bad system page size")
}
// 物理页必须是2的幂次方
if physPageSize&(physPageSize-1) != 0 {
print("system page size (", physPageSize, ") must be a power of 2\n")
throw("bad system page size")
}
// 操作系统默认页大小,物理页必须是2的幂次方
if physHugePageSize&(physHugePageSize-1) != 0 {
print("system huge page size (", physHugePageSize, ") must be a power of 2\n")
throw("bad system huge page size")
}
// 操作系统默认页大小大于操作系统最大的页大小
if physHugePageSize > maxPhysHugePageSize {
// physHugePageSize is greater than the maximum supported huge page size.
// Don't throw here, like in the other cases, since a system configured
// in this way isn't wrong, we just don't have the code to support them.
// Instead, silently set the huge page size to zero.
// physHugePageSize大于所支持的最大大页面大小。不要像其他情况那样在这里throw错误,
// 因为以这种方式配置的系统没有错,所以我们只是没有支持它们的代码。而是将巨大的页面大小静默设置为零。
physHugePageSize = 0
}
if physHugePageSize != 0 {
// Since physHugePageSize is a power of 2, it suffices to increase
// physHugePageShift until 1<
// 由于physHugePageSize为2的幂,因此足以将physHugePageShift增大到1<
for 1<<physHugePageShift != physHugePageSize {
physHugePageShift++
}
}
// Initialize the heap.
// 初始化堆
mheap_.init()
_g_ := getg()
_g_.m.mcache = allocmcache()
// Create initial arena growth hints.
// 创建初始arena增长提示。8表示字节数
if sys.PtrSize == 8 {
// On a 64-bit machine, we pick the following hints
// because:
//
// 1. Starting from the middle of the address space
// makes it easier to grow out a contiguous range
// without running in to some other mapping.
//
// 2. This makes Go heap addresses more easily
// recognizable when debugging.
//
// 3. Stack scanning in gccgo is still conservative,
// so it's important that addresses be distinguishable
// from other data.
//
// Starting at 0x00c0 means that the valid memory addresses
// will begin 0x00c0, 0x00c1, ...
// In little-endian, that's c0 00, c1 00, ... None of those are valid
// UTF-8 sequences, and they are otherwise as far away from
// ff (likely a common byte) as possible. If that fails, we try other 0xXXc0
// addresses. An earlier attempt to use 0x11f8 caused out of memory errors
// on OS X during thread allocations. 0x00c0 causes conflicts with
// AddressSanitizer which reserves all memory up to 0x0100.
// These choices reduce the odds of a conservative garbage collector
// not collecting memory because some non-pointer block of memory
// had a bit pattern that matched a memory address.
//
// However, on arm64, we ignore all this advice above and slam the
// allocation at 0x40 << 32 because when using 4k pages with 3-level
// translation buffers, the user address space is limited to 39 bits
// On darwin/arm64, the address space is even smaller.
//
// On AIX, mmaps starts at 0x0A00000000000000 for 64-bit.
// processes.
//
// 在64位计算机上,我们选择以下hit因为:
//
// 1.从地址空间的中间开始,可以轻松扩展到连续范围,而无需运行其他映射。
//
// 2.这使Go堆地址在调试时更容易识别。
//
// 3. gccgo中的堆栈扫描仍然很保守,因此将地址与其他数据区分开很重要。
//
// 从0x00c0开始意味着有效的内存地址将从0x00c0、0x00c1 ... n 小端开始,即c0 00,c1 00,...
// 这些都不是有效的UTF-8序列,否则它们是尽可能远离ff(可能是一个公共字节)。
// 如果失败,我们尝试其他0xXXc0地址。较早的尝试使用0x11f8导致线程分配期间OS X上的内存不足错误。
// 0x00c0导致与AddressSanitizer发生冲突,后者保留了最多0x0100的所有内存。
// 这些选择减少了保守的垃圾收集器不收集内存的可能性,因为某些非指针内存块具有与内存地址匹配的位模式。
//
// 但是,在arm64上,我们忽略了上面的所有建议,并在0x40 << 32处分配,因为当使用具有3级转换缓冲区的4k页面时,
// 用户地址空间在darwin/arm64上被限制为39位,地址空间更小。
//
// 在AIX上,对于64位,mmaps从0x0A00000000000000开始。
// 预先进行内存分配,最多分配64次
for i := 0x7f; i >= 0; i-- { // i=0b01111111
var p uintptr
switch {
case GOARCH == "arm64" && GOOS == "darwin":
p = uintptr(i)<<40 | uintptrMask&(0x0013<<28)
case GOARCH == "arm64":
p = uintptr(i)<<40 | uintptrMask&(0x0040<<32)
case GOOS == "aix":
if i == 0 {
// We don't use addresses directly after 0x0A00000000000000
// to avoid collisions with others mmaps done by non-go programs.
// 我们不会在0x0A00000000000000之后直接使用地址,以免与非执行程序造成的其他mmap冲突。
continue
}
p = uintptr(i)<<40 | uintptrMask&(0xa0<<52)
case raceenabled: // 此值已为false
// The TSAN runtime requires the heap
// to be in the range [0x00c000000000,
// 0x00e000000000).
p = uintptr(i)<<32 | uintptrMask&(0x00c0<<32)
if p >= uintptrMask&0x00e000000000 {
continue
}
default:
p = uintptr(i)<<40 | uintptrMask&(0x00c0<<32)
}
// p是所求的每个hint起始地址
// 采用头插法对hint块进行拉链,小端地址在前
// 最终所有的地址都分配在了mheap_.arenaHints上
hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())
hint.addr = p
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
} else {
// On a 32-bit machine, we're much more concerned
// about keeping the usable heap contiguous.
// Hence:
//
// 1. We reserve space for all heapArenas up front so
// they don't get interleaved with the heap. They're
// ~258MB, so this isn't too bad. (We could reserve a
// smaller amount of space up front if this is a
// problem.)
//
// 2. We hint the heap to start right above the end of
// the binary so we have the best chance of keeping it
// contiguous.
//
// 3. We try to stake out a reasonably large initial
// heap reservation.
//
// 在32位计算机上,我们更加关注保持可用堆是连续的。
// 因此:
//
// 1.我们为所有的heapArena保留空间,这样它们就不会与heap交错。 它们约为258MB,因此还算不错。
// (如果出现问题,我们可以在前面预留较小的空间。)
//
// 2.我们建议堆从二进制文件的末尾开始,因此我们有最大的机会保持其连续性。
//
// 3.我们尝试放出一个相当大的初始堆保留。
// 计算arena元数据大小
const arenaMetaSize = (1 << arenaBits) * unsafe.Sizeof(heapArena{})
// 保留内存
meta := uintptr(sysReserve(nil, arenaMetaSize))
if meta != 0 { // 保留成功,就进行初始化
mheap_.heapArenaAlloc.init(meta, arenaMetaSize)
}
// We want to start the arena low, but if we're linked
// against C code, it's possible global constructors
// have called malloc and adjusted the process' brk.
// Query the brk so we can avoid trying to map the
// region over it (which will cause the kernel to put
// the region somewhere else, likely at a high
// address).
// 我们想从低arena地址开始,但是如果我们与C代码链接,则可能全局构造函数调用了malloc并调整了进程的brk。
// 查询brk,以便我们避免尝试在其上映射区域(这将导致内核将区域放置在其他地方,可能位于高地址)。
// brk和sbrk相关文档
// https://blog.csdn.net/yusiguyuan/article/details/39496057
// https://blog.csdn.net/Apollon_krj/article/details/54565768
procBrk := sbrk0()
// If we ask for the end of the data segment but the
// operating system requires a little more space
// before we can start allocating, it will give out a
// slightly higher pointer. Except QEMU, which is
// buggy, as usual: it won't adjust the pointer
// upward. So adjust it upward a little bit ourselves:
// 1/4 MB to get away from the running binary image.
// 如果我们要求结束数据段,但是操作系统在开始分配之前需要更多空间,它将给出稍高的指针。
// 像往常一样,除了QEMU之外,它还有很多问题:它不会向上调整指针。 因此,我们自己向上调整一点:
// 1/4 MB以远离正在运行的二进制映像。
p := firstmoduledata.end
if p < procBrk {
p = procBrk
}
if mheap_.heapArenaAlloc.next <= p && p < mheap_.heapArenaAlloc.end {
p = mheap_.heapArenaAlloc.end
}
// alignUp(n, a) alignUp将n舍入为a的倍数。 a必须是2的幂。
p = alignUp(p+(256<<10), heapArenaBytes)
// Because we're worried about fragmentation on
// 32-bit, we try to make a large initial reservation.
// 因为我们担心32位上的碎片,所以我们尝试进行较大的初始保留。
arenaSizes := []uintptr{
512 << 20,
256 << 20,
128 << 20,
}
// 从在到小尝试分配,首次分配好就结束
for _, arenaSize := range arenaSizes {
// sysReserveAligned类似于sysReserve,但是返回的指针字节对齐的。
// 它可以保留n个或n+align个字节,因此它返回保留的大小。
a, size := sysReserveAligned(unsafe.Pointer(p), arenaSize, heapArenaBytes)
if a != nil {
mheap_.arena.init(uintptr(a), size)
p = uintptr(a) + size // For hint below
break
}
}
hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())
hint.addr = p
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
}
// sysAlloc allocates heap arena space for at least n bytes. The
// returned pointer is always heapArenaBytes-aligned and backed by
// h.arenas metadata. The returned size is always a multiple of
// heapArenaBytes. sysAlloc returns nil on failure.
// There is no corresponding free function.
//
// sysAlloc returns a memory region in the Prepared state. This region must
// be transitioned to Ready before use.
//
// h must be locked.
/**
* sysAlloc至少为n个字节分配堆arena空间。返回的指针始终是heapArenaBytes对齐的,
* 并由h.arenas元数据支持。返回的大小始终是heapArenaBytes的倍数。 sysAlloc失败时返回nil。
* 没有相应的free函数。
*
* sysAlloc返回处于Prepared状态的内存区域。使用前,该区域必须转换为“就绪”。
*
* h必须被锁定。
* @param n 待分配的字节数
* @return v 地址指针
* @return size 分配的字节数
**/
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
// 进行字节对齐
n = alignUp(n, heapArenaBytes)
// First, try the arena pre-reservation.
// 首先,尝试arena预定。
v = h.arena.alloc(n, heapArenaBytes, &memstats.heap_sys)
if v != nil {
size = n
goto mapped
}
// Try to grow the heap at a hint address.
// 尝试在hint地址处增加堆。
for h.arenaHints != nil {
hint := h.arenaHints
p := hint.addr
if hint.down {
p -= n
}
if p+n < p {
// We can't use this, so don't ask.
// 我们不能使用它,所以不回应。
v = nil
} else if arenaIndex(p+n-1) >= 1<<arenaBits {
// Outside addressable heap. Can't use.
// 外部可寻址堆。无法使用。
v = nil
} else {
v = sysReserve(unsafe.Pointer(p), n)
}
if p == uintptr(v) {
// Success. Update the hint.
// 成功。更新hint。
if !hint.down {
p += n
}
hint.addr = p
size = n
break
}
// Failed. Discard this hint and try the next.
//
// TODO: This would be cleaner if sysReserve could be
// told to only return the requested address. In
// particular, this is already how Windows behaves, so
// it would simplify things there.
// 失败了放弃此hint,然后尝试下一个。
//
// TODO:如果可以告诉sysReserve仅返回所请求的地址,则这样做会更清洁。
// 特别是,这已经是Windows的处理方式,因此它将简化那里的事情。
if v != nil {
sysFree(v, n, nil)
}
h.arenaHints = hint.next
h.arenaHintAlloc.free(unsafe.Pointer(hint))
}
if size == 0 {
if raceenabled { // 此值已为false
// The race detector assumes the heap lives in
// [0x00c000000000, 0x00e000000000), but we
// just ran out of hints in this region. Give
// a nice failure.
throw("too many address space collisions for -race mode")
}
// All of the hints failed, so we'll take any
// (sufficiently aligned) address the kernel will give
// us.
// 所有hint均失败,因此我们将采用内核将提供给我们的任何地址(已充分对齐)。
v, size = sysReserveAligned(nil, n, heapArenaBytes)
if v == nil {
return nil, 0
}
// Create new hints for extending this region.
// 创建用于扩展此区域的新hint。
hint := (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr, hint.down = uintptr(v), true
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
hint = (*arenaHint)(h.arenaHintAlloc.alloc())
hint.addr = uintptr(v) + size
hint.next, mheap_.arenaHints = mheap_.arenaHints, hint
}
// Check for bad pointers or pointers we can't use.
// 检查错误的指针或我们不能使用的指针。
{
var bad string
p := uintptr(v)
if p+size < p {
bad = "region exceeds uintptr range"
} else if arenaIndex(p) >= 1<<arenaBits {
bad = "base outside usable address space"
} else if arenaIndex(p+size-1) >= 1<<arenaBits {
bad = "end outside usable address space"
}
if bad != "" {
// This should be impossible on most architectures,
// but it would be really confusing to debug.
// 在大多数体系结构上,这应该是不可能的,但是调试起来确实很混乱。
print("runtime: memory allocated by OS [", hex(p), ", ", hex(p+size), ") not in usable address space: ", bad, "\n")
throw("memory reservation exceeds address space limit")
}
}
if uintptr(v)&(heapArenaBytes-1) != 0 {
throw("misrounded allocation in sysAlloc")
}
// Transition from Reserved to Prepared.
// 转换状态将从预留到已准备。
sysMap(v, size, &memstats.heap_sys)
mapped:
// Create arena metadata.
// 创建arena元数据。
for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {
l2 := h.arenas[ri.l1()]
if l2 == nil {
// Allocate an L2 arena map.
// 分配L2arena映射。
l2 = (*[1 << arenaL2Bits]*heapArena)(persistentalloc(unsafe.Sizeof(*l2), sys.PtrSize, nil))
if l2 == nil {
throw("out of memory allocating heap arena map")
}
atomic.StorepNoWB(unsafe.Pointer(&h.arenas[ri.l1()]), unsafe.Pointer(l2))
}
if l2[ri.l2()] != nil {
throw("arena already initialized")
}
var r *heapArena
r = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
r = (*heapArena)(persistentalloc(unsafe.Sizeof(*r), sys.PtrSize, &memstats.gc_sys))
if r == nil {
throw("out of memory allocating heap arena metadata")
}
}
// Add the arena to the arenas list.
// 将arena添加到arena列表中。
if len(h.allArenas) == cap(h.allArenas) {
size := 2 * uintptr(cap(h.allArenas)) * sys.PtrSize
if size == 0 {
size = physPageSize
}
newArray := (*notInHeap)(persistentalloc(size, sys.PtrSize, &memstats.gc_sys))
if newArray == nil {
throw("out of memory allocating allArenas")
}
oldSlice := h.allArenas
*(*notInHeapSlice)(unsafe.Pointer(&h.allArenas)) = notInHeapSlice{newArray, len(h.allArenas), int(size / sys.PtrSize)}
copy(h.allArenas, oldSlice)
// Do not free the old backing array because
// there may be concurrent readers. Since we
// double the array each time, this can lead
// to at most 2x waste.
// 不要释放旧的后备阵列,因为可能有并发读取器。
// 由于我们每次将阵列加倍,因此最多可能导致2倍的浪费。
}
h.allArenas = h.allArenas[:len(h.allArenas)+1]
h.allArenas[len(h.allArenas)-1] = ri
// Store atomically just in case an object from the
// new heap arena becomes visible before the heap lock
// is released (which shouldn't happen, but there's
// little downside to this).
// 以原子方式存储,以防新的堆空间中的对象在释放堆锁之前可见(这不应该发生,但这没有什么坏处)。
atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))
}
// Tell the race detector about the new heap memory.
// 告诉竞态检测器新的堆内存。
if raceenabled {
racemapshadow(v, size)
}
return
}
// sysReserveAligned is like sysReserve, but the returned pointer is
// aligned to align bytes. It may reserve either n or n+align bytes,
// so it returns the size that was reserved.
/**
* sysReserveAligned类似于sysReserve,但是返回的指针以字节对齐。
* 它可以保留n个或n+align个字节,因此它返回保留的大小。
* @param v 地址指针
* @param size 待分配的字节数
* @param align 对齐的字节数
* @return unsafe.Pointer 新的地址指针
* @return uintptr 分配的字节数
**/
func sysReserveAligned(v unsafe.Pointer, size, align uintptr) (unsafe.Pointer, uintptr) {
// Since the alignment is rather large in uses of this
// function, we're not likely to get it by chance, so we ask
// for a larger region and remove the parts we don't need.
// 由于在使用此功能时对齐方式相当大,因此我们不太可能偶然得到它,
// 因此我们要求更大的区域并删除不需要的部分。
retries := 0
retry:
// 先进行未对齐内存保留
p := uintptr(sysReserve(v, size+align))
switch {
case p == 0: // 未分配成功
return nil, 0
case p&(align-1) == 0:
// We got lucky and got an aligned region, so we can
// use the whole thing.
// 我们很幸运或取到一个对齐区域,所以我们可以使用整个分配的内存。
return unsafe.Pointer(p), size + align
case GOOS == "windows":
// On Windows we can't release pieces of a
// reservation, so we release the whole thing and
// re-reserve the aligned sub-region. This may race,
// so we may have to try again.
// 在Windows上,我们无法释放部分保留内存,因此我们释放整个内容并重新保留对齐的子区域。
// 这可能会生产竞争,所以我们可能必须重试。
sysFree(unsafe.Pointer(p), size+align, nil)
p = alignUp(p, align)
p2 := sysReserve(unsafe.Pointer(p), size)
if p != uintptr(p2) {
// Must have raced. Try again.
// 必定竞争了,需要重试
sysFree(p2, size, nil)
if retries++; retries == 100 {
throw("failed to allocate aligned heap memory; too many retries")
}
goto retry
}
// Success.
return p2, size
default:
// Trim off the unaligned parts.
// 修剪掉未对齐的部分。
pAligned := alignUp(p, align)
// 释放[p, pAligned-1]的内存
sysFree(unsafe.Pointer(p), pAligned-p, nil)
end := pAligned + size
endLen := (p + size + align) - end
if endLen > 0 {
// 释放[end, endLen-1]的内存
sysFree(unsafe.Pointer(end), endLen, nil)
}
// 返回分配地址和分配大小
return unsafe.Pointer(pAligned), size
}
}
// base address for all 0-byte allocations
// 所有0字节分配的基地址
var zerobase uintptr
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
/**
* 如果一个可用的对象很快可用,则nextFreeFast返回下一个可用的对象。 否则返回0。
* @param s 跨度对象
* @return gclinkptr是指向gclink的指针,但对垃圾收集器不透明。
**/
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
//
// Must run in a non-preemptible context since otherwise the owner of
// c could change.
/**
* nextFree从缓存范围中返回下一个空闲对象(如果有)。 否则,它将使用可用对象的跨度重新填充高速缓存,
* 并返回该对象以及指示这是繁重分配的标志。 如果分配很重,则调用方必须确定是否需要启动新的GC周期,
* 或者GC是否处于活动状态,因此该例行程序是否需要协助GC。
*
* 必须在不可抢占的上下文中运行,因为否则c的所有者可能会更改。
* @param spc spanClass表示跨度的大小类别和noscan-ness
* @return v gclinkptr指针
* @return s 跨度指针
* @return shouldhelpgc 是否需要gc帮助
**/
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// The span is full.
// 跨度已满
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// 重新填充跨度
c.refill(spc)
// 标记需要gc帮助
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
/**
* 分配一个大小为size字节的对象。
* 从每个P缓存的空闲列表中分配小对象。
* 从堆直接分配大对象(> 32 kB)。
* @param size 分配的内存
* @param needzero
* @return 分配的地址指针
**/
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
// _GCmarktermination: GC标记终止:分配黑色,P帮助GC,写屏障启用
throw("mallocgc called with gcphase == _GCmarktermination")
}
// 空地址
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
// TODO(austin): This should be just
// align = uintptr(typ.align)
// but that's only 4 on 32-bit platforms,
// even if there's a uint64 field in typ (see #599).
// This causes 64-bit atomic accesses to panic.
// Hence, we use stricter alignment that matches
// the normal allocator better.
// TODO(austin)):这应该只是align = uintptr(typ.align),
// 但即使在typ中有uint64字段,它在32位平台上也只有4(请参阅#599)。
// 这会导致对64位原子访问出现panic。 因此,我们使用更严格的对齐方式来更好地匹配常规分配器。
if size&7 == 0 {
align = 8
} else if size&3 == 0 {
align = 4
} else if size&1 == 0 {
align = 2
} else {
align = 1
}
}
return persistentalloc(size, align, &memstats.other_sys)
}
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
// assistantG是负责此次分配的G,如果GC当前未处于活动状态,则为nil。
var assistG *g
// 如果允许增变辅助和后台标记工作程序将对象变黑,则gcBlackenEnabled为1。
// 仅当gcphase == _GCmark时才可以设置。
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
// 获取负责此次分配的g
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
// 我们将在mallocgc末尾统计内部碎片。
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
// 这个G负债中。 协助GC进行更正,然后再分配。 这必须在禁用抢占之前发生。
gcAssistAlloc(assistG)
}
}
// Set mp.mallocing to keep from being preempted by GC.
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 { // 当前m已经在分配内容了
throw("malloc deadlock")
}
// 处理信号的g和当前的g是同一个
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1 // 设当前m正在分配内存
shouldhelpgc := false
dataSize := size
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.ptrdata == 0
if size <= maxSmallSize { // 小分配
if noscan && size < maxTinySize { // 微小分配
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
//
// 微小分配器
//
// 微小分配器 将几个微小的分配请求组合到一个内存块中。当所有子对象均不可访问时,将释放结果存储块。
// 子对象必须是noscan(没有指针),以确保限制可能浪费的内存量。
//
// 用于合并的存储块的大小(maxTinySize)是可调的。当前设置为16个字节,这涉及最坏情况下2倍的内存浪费
// (当除了一个子对象之外的所有其他对象均无法访问时)。8字节完全不会浪费,但是合并的机会更少。 3
// 2字节提供了更多的合并机会,但可能导致最坏情况下4倍浪费。无论块大小如何,最佳案例获胜都是8倍。
//
// 不能显式释放从微小分配器获得的对象。因此,当明确释放对象时,我们确保其大小>=maxTinySize。
//
// SetFinalizer对于可能来自微小分配器的对象具有特殊情况,在这种情况下,它可以为内存块的内部字节设置终结器(finalizers)。
//
// 微小分配器的主要目标是小字符串和独立的转义变量。在json基准上,分配器将分配数量减少了约12%,并将堆大小减少了约20%。
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
// 对齐微型指针以进行必需的(保守的)对齐。
if size&7 == 0 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
// 该对象适合现有的微小块。
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
// 分配一个新的maxTinySize块。
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 { // 快速分配没有成功,进行通常规分配
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
// 根据剩余的可用空间量,看看是否需要用新的小块替换现有的小块。
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else { // 小分配置
var sizeclass uint8
// 确定大小类别
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else { // 大分配
var s *mspan
shouldhelpgc = true // 需要gc帮助
// systemstack在系统堆栈上运行fn。
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
// 如果分配一个defer+arg块,现在我们已经选择了一个足够大的malloc大小来容纳所有内容,
// 请将“asked for”大小减小为defer头部,以便GC位图将arg块记录为不包含任何内容
// (好像是由于大小舍入导致的malloc块末尾的未使用空间)。
// 延迟arg区域将作为scanstack的一部分进行扫描。
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
// 记录数据类型
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
// 数组分配。 如果有任何指针,GC必须扫描到最后一个元素。
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
// 确保在调用者使x对垃圾收集器可观察之前,将上面的x初始化为类型安全的内存并设置堆存储的位信息。
// 否则,在顺序较弱的计算机上,垃圾收集器可能会跟随指向x的指针,但会看到未初始化的内存或陈旧的堆位。
publicationBarrier()
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
// 在GC期间分配黑色。 所有槽位均为nill,因此无需扫描。这可能与GC发生争用,
// 因此如果可以进行争夺来标记该位,则可以自动进行。
if gcphase != _GCoff { // go未运行
// gcmarknewobject将新分配的对象标记为黑色。obj不得包含任何非nil指针。
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0 // 标记分配已经完成
releasem(mp) // 释放m
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
// 设置内存采样
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.next_sample {
c.next_sample -= size
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
// 在assist debt中解决内部碎片化问题
assistG.gcAssistBytes -= int64(size - dataSize)
}
if shouldhelpgc {
// gcTrigger是用于启动GC循环的动作(predicate)。 具体来说,它是_GCoff阶段的退出条件。
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t)
}
}
return x
}
/**
* 大内存分配
* @param
* @return
**/
func largeAlloc(size uintptr, needzero bool, noscan bool) *mspan {
// print("largeAlloc size=", size, "\n")
// 判断是否内存溢出
if size+_PageSize < size {
throw("out of memory")
}
// 计算需要分配的页数
npages := size >> _PageShift
if size&_PageMask != 0 {
npages++
}
// Deduct credit for this span allocation and sweep if
// necessary. mHeap_Alloc will also sweep npages, so this only
// pays the debt down to npage pages.
// 扣除此跨度分配的信用,并在必要时进行扫描。 mHeap_Alloc还将清扫npages,因此这只会将债务减少到npage页。
deductSweepCredit(npages*_PageSize, npages)
// mheap_.alloc从GC的堆中分配新的npage页。
s := mheap_.alloc(npages, makeSpanClass(0, noscan), needzero)
if s == nil {
throw("out of memory")
}
s.limit = s.base() + size
// heapBitsForAddr返回地址addr的heapBits。
heapBitsForAddr(s.base()).initSpan(s)
return s
}
// implementation of new builtin
// compiler (both frontend and SSA backend) knows the signature
// of this function
/**
* 内建函数new的实现,编译器(前端和SSA后端)都知道此函数的签名
* @param 类型
* @return 对象指针
**/
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
/**
* reflect包中的unsafe_New实现
* @param
* @return
**/
//go:linkname reflect_unsafe_New reflect.unsafe_New
func reflect_unsafe_New(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
/**
* internal/reflectlite包中的unsafe_New实现
* @param
* @return
**/
//go:linkname reflectlite_unsafe_New internal/reflectlite.unsafe_New
func reflectlite_unsafe_New(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
/**
* newarray分配一个类型为typ的n个元素组成的数组。
* @param
* @return
**/
// newarray allocates an array of n elements of type typ.
func newarray(typ *_type, n int) unsafe.Pointer {
if n == 1 {
return mallocgc(typ.size, typ, true)
}
// 计算数组创建需要分配的内存
mem, overflow := math.MulUintptr(typ.size, uintptr(n))
if overflow || mem > maxAlloc || n < 0 {
panic(plainError("runtime: allocation size out of range"))
}
return mallocgc(mem, typ, true)
}
/**
* reflect包中的unsafe_NewArray实现
* @param
* @return
**/
//go:linkname reflect_unsafe_NewArray reflect.unsafe_NewArray
func reflect_unsafe_NewArray(typ *_type, n int) unsafe.Pointer {
return newarray(typ, n)
}
func profilealloc(mp *m, x unsafe.Pointer, size uintptr) {
mp.mcache.next_sample = nextSample()
mProf_Malloc(x, size)
}
// nextSample returns the next sampling point for heap profiling. The goal is
// to sample allocations on average every MemProfileRate bytes, but with a
// completely random distribution over the allocation timeline; this
// corresponds to a Poisson process with parameter MemProfileRate. In Poisson
// processes, the distance between two samples follows the exponential
// distribution (exp(MemProfileRate)), so the best return value is a random
// number taken from an exponential distribution whose mean is MemProfileRate.
/**
* nextSample返回用于堆分析的下一个采样点。 目标是在每个MemProfileRate字节抽样平均分配,
* 但在分配时间轴上具有完全随机的分配; 这对应于带有参数MemProfileRate的泊松过程。
* 在泊松过程中,两个样本之间的距离遵循指数分布(exp(MemProfileRate)),
* 因此最佳返回值是取自均值为MemProfileRate的指数分布的随机数。
* @param
* @return
**/
func nextSample() uintptr {
if GOOS == "plan9" {
// Plan 9 doesn't support floating point in note handler.
if g := getg(); g == g.m.gsignal {
return nextSampleNoFP()
}
}
return uintptr(fastexprand(MemProfileRate))
}
// fastexprand returns a random number from an exponential distribution with
// the specified mean.
/**
* fastexprand从具有指定平均值的指数分布中返回一个随机数。
* @param
* @return
**/
func fastexprand(mean int) int32 {
// Avoid overflow. Maximum possible step is
// -ln(1/(1<
// 避免溢出。 最大可能步长为-ln(1/(1<
switch {
case mean > 0x7000000:
mean = 0x7000000
case mean == 0:
return 0
}
// Take a random sample of the exponential distribution exp(-mean*x).
// The probability distribution function is mean*exp(-mean*x), so the CDF is
// p = 1 - exp(-mean*x), so
// q = 1 - p == exp(-mean*x)
// log_e(q) = -mean*x
// -log_e(q)/mean = x
// x = -log_e(q) * mean
// x = log_2(q) * (-log_e(2)) * mean ; Using log_2 for efficiency
const randomBitCount = 26
q := fastrand()%(1<<randomBitCount) + 1
qlog := fastlog2(float64(q)) - randomBitCount
if qlog > 0 {
qlog = 0
}
const minusLog2 = -0.6931471805599453 // -ln(2)
return int32(qlog*(minusLog2*float64(mean))) + 1
}
// nextSampleNoFP is similar to nextSample, but uses older,
// simpler code to avoid floating point.
/**
* nextSampleNoFP与nextSample相似,但使用更旧,更简单的代码来避免浮点数。
* @param
* @return
**/
func nextSampleNoFP() uintptr {
// Set first allocation sample size.
rate := MemProfileRate
if rate > 0x3fffffff { // make 2*rate not overflow
rate = 0x3fffffff
}
if rate != 0 {
return uintptr(fastrand() % uint32(2*rate))
}
return 0
}
/**
* 持久化分配结构
**/
type persistentAlloc struct {
base *notInHeap
off uintptr
}
/**
* 全局分配结构
**/
var globalAlloc struct {
mutex
persistentAlloc
}
// persistentChunkSize is the number of bytes we allocate when we grow
// a persistentAlloc.
// persistentChunkSize是我们增长persistentAlloc时分配的字节数。256KB
const persistentChunkSize = 256 << 10
// persistentChunks is a list of all the persistent chunks we have
// allocated. The list is maintained through the first word in the
// persistent chunk. This is updated atomically.
// psistenceChunks是我们分配的所有持久性块的列表。
// 该列表通过持久性块中的第一个字(word)进行维护。 这是原子更新的。
var persistentChunks *notInHeap
// Wrapper around sysAlloc that can allocate small chunks.
// There is no associated free operation.
// Intended for things like function/type/debug-related persistent data.
// If align is 0, uses default align (currently 8).
// The returned memory will be zeroed.
//
// Consider marking persistentalloc'd types go:notinheap.
/**
* 围绕sysAlloc的包装程序,可以分配小内存块。 没有相关的自由操作。
* 用于函数/类型/调试相关的持久数据。 如果align为0,则使用默认的align(当前为8)。
* 返回的内存将被清零。考虑标记为持久分配的类型go:notinheap。
* @param
* @return
**/
func persistentalloc(size, align uintptr, sysStat *uint64) unsafe.Pointer {
var p *notInHeap
systemstack(func() {
p = persistentalloc1(size, align, sysStat)
})
return unsafe.Pointer(p)
}
/**
* 必须在系统堆栈上运行,因为堆栈增长可以(重新)调用它。 请参阅问题9174。
* @param
* @return
**/
// Must run on system stack because stack growth can (re)invoke it.
// See issue 9174.
//go:systemstack
func persistentalloc1(size, align uintptr, sysStat *uint64) *notInHeap {
const (
// Windows上的VM预留粒度为64K
maxBlock = 64 << 10 // VM reservation granularity is 64K on windows
)
if size == 0 {
throw("persistentalloc: size == 0")
}
if align != 0 {
if align&(align-1) != 0 {
throw("persistentalloc: align is not a power of 2")
}
if align > _PageSize {
throw("persistentalloc: align is too large")
}
} else {
align = 8
}
if size >= maxBlock {
return (*notInHeap)(sysAlloc(size, sysStat))
}
mp := acquirem()
var persistent *persistentAlloc
if mp != nil && mp.p != 0 {
persistent = &mp.p.ptr().palloc
} else {
lock(&globalAlloc.mutex)
persistent = &globalAlloc.persistentAlloc
}
persistent.off = alignUp(persistent.off, align)
if persistent.off+size > persistentChunkSize || persistent.base == nil {
persistent.base = (*notInHeap)(sysAlloc(persistentChunkSize, &memstats.other_sys))
if persistent.base == nil {
if persistent == &globalAlloc.persistentAlloc {
unlock(&globalAlloc.mutex)
}
throw("runtime: cannot allocate memory")
}
// Add the new chunk to the persistentChunks list.
for {
chunks := uintptr(unsafe.Pointer(persistentChunks))
*(*uintptr)(unsafe.Pointer(persistent.base)) = chunks
if atomic.Casuintptr((*uintptr)(unsafe.Pointer(&persistentChunks)), chunks, uintptr(unsafe.Pointer(persistent.base))) {
break
}
}
persistent.off = alignUp(sys.PtrSize, align)
}
p := persistent.base.add(persistent.off)
persistent.off += size
releasem(mp)
if persistent == &globalAlloc.persistentAlloc {
unlock(&globalAlloc.mutex)
}
if sysStat != &memstats.other_sys {
mSysStatInc(sysStat, size)
mSysStatDec(&memstats.other_sys, size)
}
return p
}
/**
* inPersistentAlloc报告p是否指向由persistentalloc分配的内存。
* 由于它是由cgo检查器代码调用的,而后者由写屏障代码调用,因此必须不能拆分。
* @param
* @return
**/
// inPersistentAlloc reports whether p points to memory allocated by
// persistentalloc. This must be nosplit because it is called by the
// cgo checker code, which is called by the write barrier code.
//go:nosplit
func inPersistentAlloc(p uintptr) bool {
chunk := atomic.Loaduintptr((*uintptr)(unsafe.Pointer(&persistentChunks)))
for chunk != 0 {
if p >= chunk && p < chunk+persistentChunkSize {
return true
}
chunk = *(*uintptr)(unsafe.Pointer(chunk))
}
return false
}
// linearAlloc is a simple linear allocator that pre-reserves a region
// of memory and then maps that region into the Ready state as needed. The
// caller is responsible for locking.
/**
* linearAlloc是一个简单的线性分配器,它可以预先保留一个内存区域,
* 然后根据需要将该区域映射到“就绪”状态。 调用方负责锁定。
**/
type linearAlloc struct {
next uintptr // next free byte // next free byte
mapped uintptr // one byte past end of mapped space // 映射空间的末尾一个字节
end uintptr // end of reserved space // 保留空间的结尾
}
/**
* 初始化线性分配器
* @param
* @return
**/
func (l *linearAlloc) init(base, size uintptr) {
l.next, l.mapped = base, base
l.end = base + size
}
/**
* 分配内存
* @param
* @return
**/
func (l *linearAlloc) alloc(size, align uintptr, sysStat *uint64) unsafe.Pointer {
p := alignUp(l.next, align)
if p+size > l.end {
return nil
}
l.next = p + size
if pEnd := alignUp(l.next-1, physPageSize); pEnd > l.mapped {
// Transition from Reserved to Prepared to Ready.
sysMap(unsafe.Pointer(l.mapped), pEnd-l.mapped, sysStat)
sysUsed(unsafe.Pointer(l.mapped), pEnd-l.mapped)
l.mapped = pEnd
}
return unsafe.Pointer(p)
}
/**
* notInHeap是由sysAlloc或persistentAlloc之类的较低级分配器分配的堆外内存。
*
* 通常,最好使用标记为go:notinheap的实类型,但这在不可能的情况下(例如在分配器中)用作通用类型。
*
* TODO:使用它作为sysAlloc,persistentAlloc等的返回类型吗?
**/
// notInHeap is off-heap memory allocated by a lower-level allocator
// like sysAlloc or persistentAlloc.
//
// In general, it's better to use real types marked as go:notinheap,
// but this serves as a generic type for situations where that isn't
// possible (like in the allocators).
//
// TODO: Use this as the return type of sysAlloc, persistentAlloc, etc?
//
//go:notinheap
type notInHeap struct{}
func (p *notInHeap) add(bytes uintptr) *notInHeap {
return (*notInHeap)(unsafe.Pointer(uintptr(unsafe.Pointer(p)) + bytes))
}