Kylin构建Cube过程详解
1 前言
在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根据原始表中的某一个string字段(这个字段的格式必须是日期格式,表示日期的含义)设定分区字段,这样一个cube就可以进行多次build,每一次的build会生成一个segment,每一个segment对应着一个时间区间的cube,这些segment的时间区间是连续并且不重合的,对于拥有多个segment的cube可以执行merge,相当于将一个时间区间内部的segment合并成一个。下面开始分析cube的build过程。
2 Cube示例
以手机销售为例,表SALE记录各手机品牌在各个国家,每年的销售情况。表PHONE是手机品牌,表COUNTRY是国家列表,两表通过外键与SALE表相关联。这三张表就构成星型模型,其中SALE是事实表,PHONE、COUNTRY是维度表。
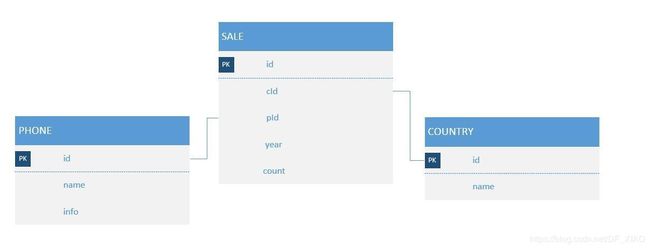
现在需要知道各品牌手机于2010-2012年,在中国的总销量,那么查询sql为:
SELECT b.`name`, c.`NAME`, SUM(a.count)
FROM SALE AS a
LEFT JOIN PHONE AS b ON a.`pId`=b.`id`
LEFT JOIN COUNTRY AS c ON a.`cId`=c.`id`
WHERE a.`time` >= 2010 AND a.`time` <= 2012 AND c.`NAME` = "中国"
GROUP BY b.`NAME`其中时间(time), 手机品牌(b.name,后文用phone代替),国家(c.name,后文用country代替)是维度,而销售数量(a.count)是度量。手机品牌的个数可用于表示手机品牌列的基度。各手机品牌在各年各个国家的销量可作为一个cuboid,所有的cuboid组成一个cube,如下图所示: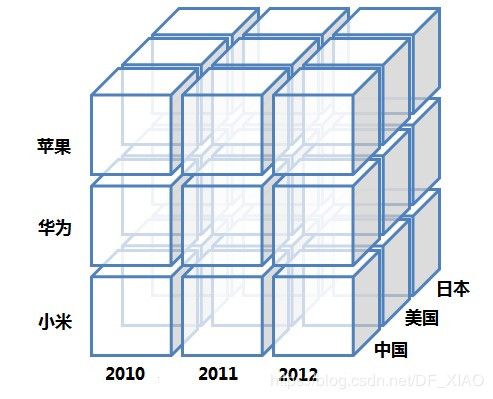
上图展示了有3个维度的cube,每个小立方体代表一个cuboid,其中存储的是度量列聚合后的结果,比如苹果在中国2010年的销量就是一个cuboid。
3 入口介绍
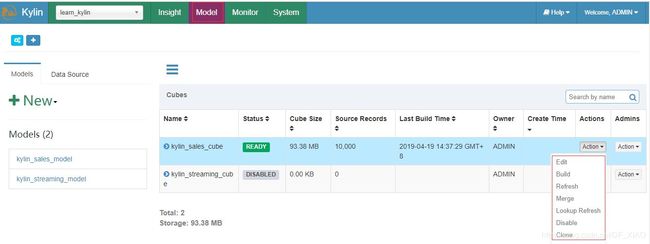
在kylin的web页面上创建完成一个cube之后可以点击action下拉框执行build或者merge操作,这两个操作都会调用cube的rebuild接口,调用的参数包括:
- cube名,用于唯一标识一个cube,在当前的kylin版本中cube名是全局唯一的,而不是每一个project下唯一的;
- 本次构建的startTime和endTime,这两个时间区间标识本次构建的segment的数据源只选择这个时间范围内的数据;对于BUILD操作而言,startTime是不需要的,因为它总是会选择最后一个segment的结束时间作为当前segment的起始时间。
- buildType标识着操作的类型,可以是”BUILD”、”MERGE”和”REFRESH”。
4 构建Cube过程
Kylin中Cube的Build过程,是将所有的维度组合事先计算,存储于HBase中,以空间换时间,HTable对应的RowKey,就是各种维度组合,指标存在Column中,这样,将不同维度组合查询SQL,转换成基于RowKey的范围扫描,然后对指标进行汇总计算,以实现快速分析查询。整个过程如下图所示: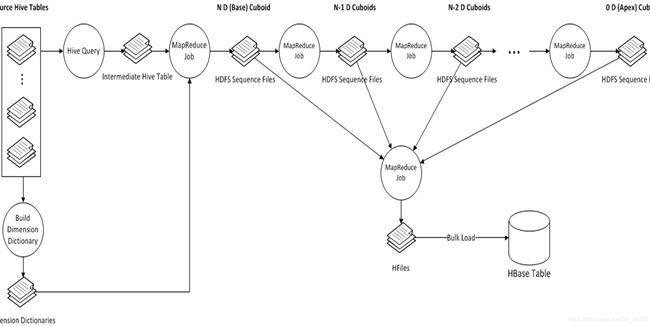
主要的步骤可以按照顺序分为几个阶段:
- 根据用户的cube信息计算出多个cuboid文件;
- 根据cuboid文件生成htable;
- 更新cube信息;
- 回收临时文件。
每一个阶段操作的输入都需要依赖于上一步的输出,所以这些操作全是顺序执行的。下面对这几个阶段的内容细分为11步具体讲解一下:
4.1 创建Hive事实表中间表(Create Intermediate Flat Hive Table)
这一步的操作会新创建一个hive外部表,然后再根据cube中定义的星状模型,查询出维度和度量的值插入到新创建的表中,这个表是一个外部表,表的数据文件(存储在HDFS)作为下一个子任务的输入。
4.2 重新分配中间表(Redistribute Flat Hive Table)
在前面步骤,hive会在HDFS文件夹中生成数据文件,一些文件非常大,一些有些小,甚至是空的。文件分布不平衡会导致随后的MR作业不平衡:一些mappers作业很快执行完毕,但其它的则非常缓慢。为了平衡作业,kylin增加这一步“重新分配”数据。首先,kylin获取到这中间表的行数,然后根据行数的数量,它会重新分配文件需要的数据量。默认情况下,kylin分配每100万行一个文件。
4.3 提取事实表不同列值 (Extract Fact Table Distinct Columns)
在这一步是根据上一步生成的hive中间表计算出每一个出现在事实表中的维度列的distinct值,并写入到文件中,它是启动一个MR任务完成的,它关联的表就是上一步创建的临时表,如果某一个维度列的distinct值比较大,那么可能导致MR任务执行过程中的OOM。
4.4 创建维度字典(Build Dimension Dictionary)
这一步是根据上一步生成的distinct column文件和维度表计算出所有维度的子典信息,并以字典树的方式压缩编码,生成维度字典,子典是为了节约存储而设计的。每一个cuboid的成员是一个key-value形式存储在hbase中,key是维度成员的组合,但是一般情况下维度是一些字符串之类的值(例如商品名),所以可以通过将每一个维度值转换成唯一整数而减少内存占用,在从hbase查找出对应的key之后再根据子典获取真正的成员值。
4.5 保存Cuboid的统计信息(Save Cuboid Statistics)
计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid。理论上来说,一个N维的Cube,便有2的N次方种维度组合,参考网上的一个例子,一个Cube包含time, item, location, supplier四个维度,那么组合(Cuboid)便有16种:

4.6 创建HTable
创建一个HTable的时候还需要考虑一下几个事情:
- 列簇的设置。
- 每一个列簇的压缩方式。
- 部署coprocessor。
- HTable中每一个region的大小。
在这一步中,列簇的设置是根据用户创建cube时候设置的,在HBase中存储的数据key是维度成员的组合,value是对应聚合函数的结果,列簇针对的是value的,一般情况下在创建cube的时候只会设置一个列簇,该列包含所有的聚合函数的结果;
在创建HTable时默认使用LZO压缩,如果不支持LZO则不进行压缩,在后面kylin的版本中支持更多的压缩方式;
kylin强依赖于HBase的coprocessor,所以需要在创建HTable为该表部署coprocessor,这个文件会首先上传到HBase所在的HDFS上,然后在表的元信息中关联,这一步很容易出现错误,例如coprocessor找不到了就会导致整个regionServer无法启动,所以需要特别小心;region的划分已经在上一步确定了,所以这里不存在动态扩展的情况,所以kylin创建HTable使用的接口如下:
public void createTable(final HTableDescriptor desc , byte [][] splitKeys)
4.7 用Spark引擎构建Cube(Build Cube with Spark)
在Kylin的Cube模型中,每一个cube是由多个cuboid组成的,理论上有N个普通维度的cube可以是由2的N次方个cuboid组成的,那么我们可以计算出最底层的cuboid,也就是包含全部维度的cuboid(相当于执行一个group by全部维度列的查询),然后在根据最底层的cuboid一层一层的向上计算,直到计算出最顶层的cuboid(相当于执行了一个不带group by的查询),其实这个阶段kylin的执行原理就是这个样子的,不过它需要将这些抽象成mapreduce模型,提交Spark作业执行。使用Spark,生成每一种维度组合(Cuboid)的数据。Build Base Cuboid Data;Build N-Dimension Cuboid Data : 7-Dimension;Build N-Dimension Cuboid Data : 6-Dimension;……Build N-Dimension Cuboid Data : 2-Dimension;Build Cube。
4.8 将Cuboid数据转换成HFile(Convert Cuboid Data to HFile)
创建完了HTable之后一般会通过插入接口将数据插入到表中,但是由于cuboid中的数据量巨大,频繁的插入会对Hbase的性能有非常大的影响,所以kylin采取了首先将cuboid文件转换成HTable格式的Hfile文件,然后在通过bulkLoad的方式将文件和HTable进行关联,这样可以大大降低Hbase的负载,这个过程通过一个MR任务完成。
4.9 导HFile入HBase表(Load HFile to HBase Table)
将HFile文件load到HTable中,这一步完全依赖于HBase的工具。这一步完成之后,数据已经存储到HBase中了,key的格式由cuboid编号 每一个成员在字典树的id组成,value可能保存在多个列组里,包含在原始数据中按照这几个成员进行GROUP BY计算出的度量的值。
4.10 更新Cube信息(Update Cube Info)
更新cube的状态,其中需要更新的包括cube是否可用、以及本次构建的数据统计,包括构建完成的时间,输入的record数目,输入数据的大小,保存到Hbase中数据的大小等,并将这些信息持久到元数据库中。
4.11 清理Hive中间表(Hive Cleanup)
这一步是否成功对正确性不会有任何影响,因为经过上一步之后这个segment就可以在这个cube中被查找到了,但是在整个执行过程中产生了很多的垃圾文件,其中包括:
- 临时的hive表;
- 因为hive表是一个外部表,存储该表的文件也需要额外删除;
- fact distinct这一步将数据写入到HDFS上为建立子典做准备,这时候也可以删除了;
- rowKey统计的时候会生成一个文件,此时可以删除;
- 生成HFile时文件存储的路径和hbase真正存储的路径不同,虽然load是一个remove操作,但是上层的目录还是存在的,也需要删除。
至此整个Build过程结束。