程序员角度下使用 SIR 模型预测 nCoV

“首先我先介绍一下背景,这篇文章完全是出于个人兴趣以及知识科普而言,并不代表真实性和权威性。使用模型预测流行传染病的疫情发展趋势,是数学建模中常见的手段。
其实在过年的时候就一直在想,之前大学的时候做了那么多次的数学建模竞赛(虽然没取得过什么优异的成绩),通过经典的传染病模型,可以自己做一次数据预测。所以才决定写这么一篇 SIR 模型介绍的文章。当然由于我不是专业人士,其中数据一定会有一些纰漏,欢迎各个专业人士的斧正。
1. SIR 模型参数简介
 SIR 模型关系
SIR 模型关系
SIR (Susceptible Infected Recovered Model) 是常用的急性传染病模型,SIR 对应以下的几个单词:
易感者 (Susceptible):用符号 来表示;
感染者 (Infective):用符号 来表示;
康复者 (Recoverd):用符号 来表示;
这里的 是时间戳,也就是代表这些值都是 的一个函数。其次,在时间戳 的基础上,总人数 。如果暂时不考虑人口增加和死亡情况,那么 是一个恒定的常数。
另外还有几个参数要解释:
β 表示感染者触到易感者之后,易感者得病的概率;
γ 表示感染者康复的概率,有可能变成易感者(可再感染),也有可能变成康复者(不再感染);
知道了以下这些参数代表的含义,下面直接给出 SIR 模型的微分方程。对于如何证明,可以查看这个知乎问答的链接 关于传染病的数学模型有哪些?——张戎的回答[1]。
其初始条件:
2. 部分参数关系
根据上式中出现的几个变量,我们知道还需要求出易感者得病概率 β 以及感染者康复概率 γ 才可以绘制关系曲线。这里再给出几个估算公式:
2.1 平均恢复率估计
感染人群恢复的平均速率 γ ,取决于感染的平均持续时间 。其对应关系是:
γ
2.2 易感得病概率估计
在上述偏微分方程中有以下式子:
在初期,我们可以认为 的,因为在疫情初期,感人者相对于易感人群的比例很小。所以我们可以得到:
通过以下方式反解 :
这里的 H 是一个常数。考虑到初始状态下 ,所以求得:
3. 系数入参取值
这一章节参考了 武汉肺炎传播的多种数学模型[2] 的方法对参数值进行取值。
首先根据报道 根据目前数据,再次分析武汉新冠肺炎患者数量和死亡率[3] 可以求得感染的平均持续时间 ,所以求得:
所以得到 :
此时 怎么求呢?根据上述的那篇参考文献的分析方法,我们使用最单一高斯法来做函数拟合:
| 时间 | 时间戳(t) | 感染人数(I) |
|---|---|---|
| 2019/12/08 | 0 | 1 |
| ... | ... | ... |
| 2020/01/19 | 42 | 198 |
| 2020/01/20 | 43 | 218 |
| 2020/01/21 | 44 | 320 |
| 2020/01/22 | 45 | 478 |
| 2020/01/23 | 46 | 639 |
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
import math
def func_I(t, beta):
return math.e ** ((beta - 1 / 14) * t)
xdata = [0, 42, 43, 44, 45, 46]
ydata = [1, 198, 218, 320, 478, 639]
popt, pcov = curve_fit(func_I, xdata, ydata)
beta = popt[0]
gamma = 1 / 14
R0 = beta / gamma
print(beta) # 0.20664331675643124
print(R0) # 2.8930064345900375
通过单一高斯拟合 curve_fit 可以求得:
另外可以通过 和 来估计基础再生数(Basic Reproduction Number):
“这里要提一个 SIR 模型中的阈值定理:基础再生数 是刻画传染病爆发与否的参数, 是区分传染病是否流行的阈值。当 时,传染病不会流行,而是会逐渐衰弱直至消亡;当 时传染病就会爆发流行,然后才最终消亡。
4. SIR 模型微分方程组
我们有了以上这些基础数据之后,就可以来求解 SIR 微分方程组。具体的求解方式在 matlab 中直接使用 ode45 方法即可。ode45 方法,采用四阶-五阶 Runge-Kutta 算法,是我们大学时做数学建模解决微分方程组的最常用的方法。
“Runge-Kutta 算法是数值分析学科中的一个重要的知识。是用于非线性常微分方程的解的重要的一类隐式或显式迭代法。
当然,现在为了拥抱 Python,笔者特意去学习了如何使用 Python 来求解微分方程组。经过查阅发现大多数求解微分方程组都采用 scipy.integrate.odeint 这个方法来求解。但是对应的算法原理目前还没有检索到,如果有同学知道其原理,欢迎告知!我会在第一时间补充。
4.1 感染者与时间变化
from scipy.integrate import odeint
import numpy as np
import datetime
start_day = datetime.datetime(2019, 12, 8)
def func_SIR(w, t, beta, gamma, N):
S, I, R = w
return np.array([
-beta * I * S / N,
beta * I * S / N - gamma * I,
gamma * I,
])
N = 11000000 # 武汉人口
ts = np.arange(0, 180, 1)
w0 = (N - 1, 1, 0) # 初始值
beta, gamma = 0.2066, 1 / 14
track1 = odeint(func_SIR, w0, ts, args=(beta, gamma, N))
#print(track1)
import matplotlib.pyplot as plt
Is = [k[1] for k in track1]
plt.figure
plt.plot(ts, Is, 'r')
max_index = np.argmax(Is)
# 峰值天
top_day = start_day + datetime.timedelta(days=int(ts[max_index]))
plt.annotate(f'{int(Is[max_index])}, {"{0:%Y-%m-%d}".format(top_day)}', xy=(ts[max_index], Is[max_index]))
# 上升最快天
rec_ind, detal_c = 0, 0
for i in range(1, len(Is)):
if Is[i] - Is[i - 1] > detal_c:
detal_c = Is[i] - Is[i - 1]
rec_ind = i
speed_day = start_day + datetime.timedelta(days=int(ts[rec_ind]))
speed_last_day = start_day + datetime.timedelta(days=(int(ts[rec_ind] - 1)))
plt.annotate(f'{int(Is[rec_ind])}, {"{0:%Y-%m-%d}".format(speed_day)}',
xytext=(ts[rec_ind - 70], Is[rec_ind]),
xy=(ts[rec_ind], Is[rec_ind]))
plt.annotate(f'{int(Is[rec_ind - 1])}, {"{0:%Y-%m-%d}".format(speed_last_day)}',
xytext=(ts[rec_ind - 74], Is[rec_ind - 1]),
xy=(ts[rec_ind - 1], Is[rec_ind - 1]))
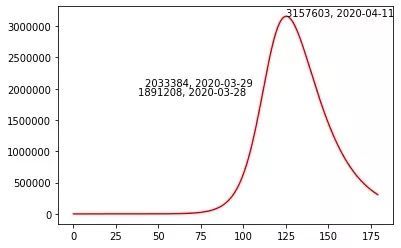
这张图代表在无政府管控以及科研加持的基础上的感染者与时间的关系曲线。模型表明,疫情后第 75 天开始爬坡式爆发,到三月底才会出现增长(斜率)的拐点,但此时感染人数已经 200 万人左右;到 4 月 11 日感染人数到达峰值 315 万人。
4.2 累计死亡与时间变化
根据 WHO的这篇报道[4],目前 nCoV 的死亡率约为4%。由于死亡滞后感染,则 时刻前累计死亡人数为:
使用这个累计死亡公示来模拟一下:
Ss = [k[0] for k in track1]
Ds = [0] * len(Ss)
for i in range(len(Ss)):
if i <= 14:
Ds[i] = 0
continue
Ds[i] = 0.04 * (N - Ss[i - 14])
plt.figure
plt.plot(ts, Ds, 'r')
print(int(max(Ds))) # 410356
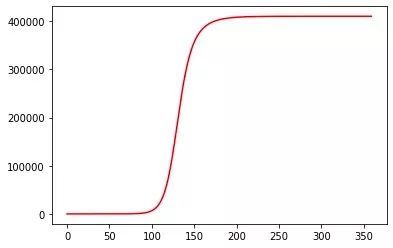
通过这种方式来模拟累计死亡数与时间的关系,在自由传播的前提下,最终累计死亡人数会高达 41 万人。这个模拟看的笔者自己是胆战心惊。但其实不用害怕,因为官方给的数据并没有按照这个死亡人数曲线的趋势在走,证明政府管控以及市民的防控对疫情已经有了作用。
5. 总述
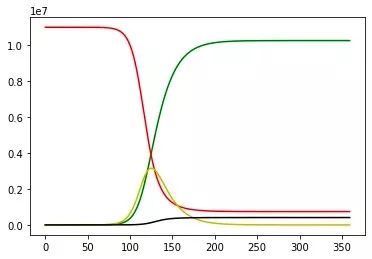
本次建模的背景是病毒自由传播状态下给予 SIR 模型来对 nCoV 病毒对于武汉市的影响。但是观察每日武汉市的数据,自 2 月份以来已经开始有了下降的苗头。如此反应了政策出台、我们个人的努力,已经开始起到了正向作用。
所以,勤洗手、戴口罩也是最近经常听到的社会呼吁。通过估算 ,我们认识到了 nCoV 的传染性是十分强的,所以避免出门是预防的最好方式。这里也呼吁大家多劝劝自己的父母长辈,一定要认真对待这个问题。
“最后插一点自己的想法:我在 2 月 2 日天津飞往上海虹桥机场的飞机上,完成了这篇公众号。今天早上出门倒垃圾的时候,看见了很多小区内长辈三五成群的买菜回家。虽然都绝大多数长辈已经带上了口罩,但是带口罩避免感染也只是概率事件。所以也希望看到这篇文章的朋友,也可以对劝戒身边的长辈,多避免外出的扎堆现象。
参考资料
[1]
关于传染病的数学模型有哪些?——张戎的回答: https://www.zhihu.com/question/367466399/answer/985150406
[2]武汉肺炎传播的多种数学模型: https://zhuanlan.zhihu.com/p/104371621
[3]根据目前数据,再次分析武汉新冠肺炎患者数量和死亡率: https://user.guancha.cn/main/content?id=232461
[4]关于新型冠状病毒(2019-nCoV)疫情的《国际卫生条例(2005)》突发事件委员会会议的声明: https://www.who.int/zh/news-room/detail/23-01-2020-statement-on-the-meeting-of-the-international-health-regulations-(2005)-emergency-committee-regarding-the-outbreak-of-novel-coronavirus-(2019-ncov)
[5]基于SIR模型的SARS传染病研究 徐宝春 山东大学 2019.5.24



最近《让技术一瓜共食》开始了新一年的算法打卡活动,并且由原来的知识星球改成了微信圈子打卡。如果想开始一个算法的训练,又没有计划无从下手,欢迎大家来参加我们的每日一题算法打卡。