Flink SQL
Query
使用TableEnvironment的sqlQuery()方法指定SQL查询。该方法以表的形式返回SQL查询的结果。表可以用于后续的SQL和表API查询,可以转换为DataSet或DataStream,也可以写入TableSink)。可以无缝地混合SQL和Table API查询,并对其进行整体优化,并将其转换为单个程序。
为了访问SQL查询中的表,必须在TableEnvironment中注册表。可以从TableSource, Table, DataStream, 或 DataSet.注册表。另外,用户还可以在TableEnvironment中注册外部目录,以指定数据源的位置。
为了方便起见,Table.toString()在TableEnvironment中以惟一的名称自动注册表并返回该名称。因此,表对象可以直接内联到SQL查询中(通过字符串连接),如下面的示例所示。
Flink使用Apache Calcite解析SQL ,它支持标准的ANSI SQL。Flink不支持DDL语句。
操作
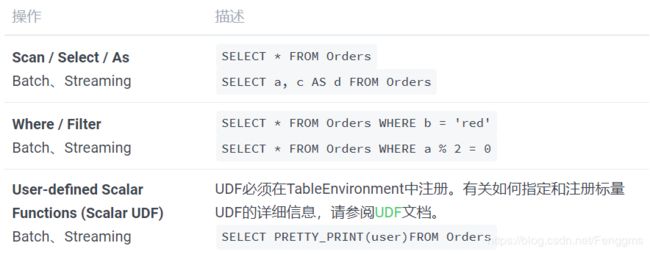
扫描,投影,过滤(Scan, Projection, and Filter)
聚合(Aggregations)
GroupBy Aggregation
SELECT a, SUM(b) as d
FROM Orders
GROUP BY a
GroupBy Window Aggregation
SELECT user, SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' DAY), user

关联(Joins)
集合操作(Set Operations)
Union
SELECT *
FROM (
(SELECT user FROM Orders WHERE a % 2 = 0)
UNION
(SELECT user FROM Orders WHERE b = 0)
)
Union All
SELECT *
FROM (
(SELECT user FROM Orders WHERE a % 2 = 0)
UNION ALL
(SELECT user FROM Orders WHERE b = 0)
)
OrderBy & Limit
流式查询的结果必须主要按升序时间属性排序。支持其他排序属性。
Order By
SELECT *
FROM Orders
ORDER BY orderTime
Limit
SELECT *
ROM Orders
LIMIT 3
插入(Insert)
INSERT INTO OutputTable
SELECT users, tag
FROM Orders
模式识别(Pattern Recognition)
DDL
Flink的DDL支持尚未完成。
以下示例显示如何指定SQL DDL。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// SQL query with a registered table
// register a table named "Orders"
tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR, amount INT) WITH (...)");
// run a SQL query on the Table and retrieve the result as a new Table
Table result = tableEnv.sqlQuery(
"SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
// SQL update with a registered table
// register a TableSink
tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT) WITH (...)");
// run a SQL update query on the Table and emit the result to the TableSink
tableEnv.sqlUpdate(
"INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
创建表
CREATE TABLE [catalog_name.][db_name.]table_name
[(col_name1 col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name1, col_name2, ...)]
WITH (key1=val1, key2=val2, ...)
删除表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name