Tensorflow2.0 自定义图像数据集 读取加速 tf.data.Dataset.cache (二)
接上一篇Tensorflow2.0 tf.data.Dataset.from_tensor_slices 自定义图像数据集 (一)。这里对比pipeline、cache(缓存)和.cache(filename=’./cache.tf-data’)方法建立缓存文件
这里写目录标题
- Tensorflow
- pipeline性能
- cache(缓存) 性能
- 缓存文件性能
- 前两个epoch读取速度对比
- 参考
Tensorflow
pipeline性能
在建立tf.data.Dataset.from_tensor_slicestf.data.Dataset.from_tensor_slices对象后,建立一个时间函数来记录数据读取的时间
steps_per_epoch=100
import time
default_timeit_steps = 2*steps_per_epoch+1
def timeit(ds, steps=default_timeit_steps):
overall_start = time.time()
# 在开始计时之前
# 取得单个 batch 来填充 pipeline(管道)(填充随机缓冲区)
it = iter(ds.take(steps+1))
next(it)
start = time.time()
for i,(images,labels) in enumerate(it):
if i%10 == 0:
print('.',end='')
print()
end = time.time()
duration = end-start
print("{} batches: {} s".format(steps, duration))
print("{:0.5f} Images/s".format(BATCH_SIZE*steps/duration))
print("Total time: {}s".format(end-overall_start))
pipeline(管道)读取数据
ds = image_label_ds.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))
ds = ds.batch(BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)
timeit(ds)
…
201 batches: 56.24465847015381 s
114.35753 Images/s
Total time: 87.22198867797852s
cache(缓存) 性能
使用.cache()方法:当计算缓存空间足够时,将preprocess的数据存储在缓存空间中将大幅提高计算速度。
ds = image_label_ds.cache()
ds = ds.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))
ds = ds.batch(BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)
timeit(ds)
…
201 batches: 6.359469652175903 s
1011.40509 Images/s
Total time: 36.266807556152344s
从结果可以看出在多组epoch操作中,数据读取速度有数量级的提升。同时你可以观察你的GPU内存在结算结束后仍未释放。
缓存文件性能
当你的数据集合过大,计算内存无法满足需求时建立一个缓存文件同样能提高数据加载速度。
ds = image_label_ds.cache(filename='./cache.tf-data')
ds = ds.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))
ds = ds.batch(BATCH_SIZE).prefetch(1)
timeit(ds)
201 batches: 21.75392198562622 s
295.67082 Images/s
Total time: 61.888566970825195s
虽然相比缓存速度还是相差较大,但是比pipeline方式有提升不失为一个好方法。毕竟还是可以减少preprocess的计算过程。
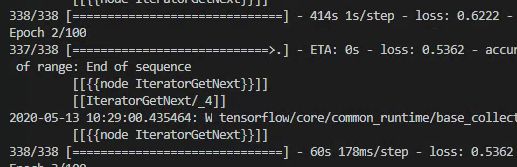
前两个epoch读取速度对比
可以看到第一组epoch的step的读取速度是1s/step, 第二组epoch的速度魏178ms/step,且以后的epoch将维持此速度。