《推荐系统开发实战》之冷启动介绍与解决
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
推荐系统基于用户大量的历史行为做出事物呈现,因此用户的历史行为数据是构建一个优质推荐系统的先决条件,但在实际场景中并非所有的用户都拥有丰富的历史数据,如首次进入电商网站的用户。如何在没有丰富历史数据的情况下为用户推荐个性化的商品,这就是冷启动问题。
冷启动介绍
冷启动主要分为三类:用户冷启动、物品冷启动、系统冷启动。
- 用户冷启动:解决的是如何给新用户进行个性化推荐的问题。当一个新用户进入网站或APP时,由于系统之前没有任何关于该用户的历史行为数据,导致无法对用户进行兴趣建模,从而无法为该用户进行个性化推荐。
- 物品冷启动:解决的是如何将新加入系统的物品推荐给用户。由于新物品没有任何被动行为,在系统中所占的权重几乎为0,这会导致在对商品排序或进行协同过滤推荐时该物品无法出现在推荐列表中。
- 系统冷启动:解决的是在一个新系统中没有用户,也没有用户行为,只有物品信息,如何给用户进行个性化推荐的问题。
针对推荐系统的冷启动,主要有以下几种实现方法:
- 基于热门数据推荐;
- 利用用户注册信息;
- 利用用户上下文信息;
- 利用第三方数据;
- 利用用户和系统之间的交互;
- 利用物品内容属性;
- 利用专家标注数据。
下面将对如何解决推荐系统中的冷启动问题进行解答。
基于热门数据推荐实现冷启动
热门数据是指(某类)物品按照一定规则进行排序得到的排名靠前的数据。热门数据反映的是大众的偏好,但受外界影响因素较大。例如某电商网站上的一个商品推广广告,可能会导致该商品在很短的时间内热度飙升;某新闻网站中的一条娱乐新闻,热度容易受舆论和明星效应的影响。
虽然热门数据不能够准确地传达出用户偏好,但在某种程度上也是用户群体中大部分人的短期兴趣点。将热门数据作为解决用户冷启动的推荐数据,“个性化”地展示给用户,用户在这些数据中产生行为之后,再进行个性化推荐。
热门数据排行榜在实际场景中应用十分广泛。例如,当用户新到达一个地方,打开某生活服务APP的美食频道后,附近的商家就会默认以热度排序展示给用户,如图9-1所示。
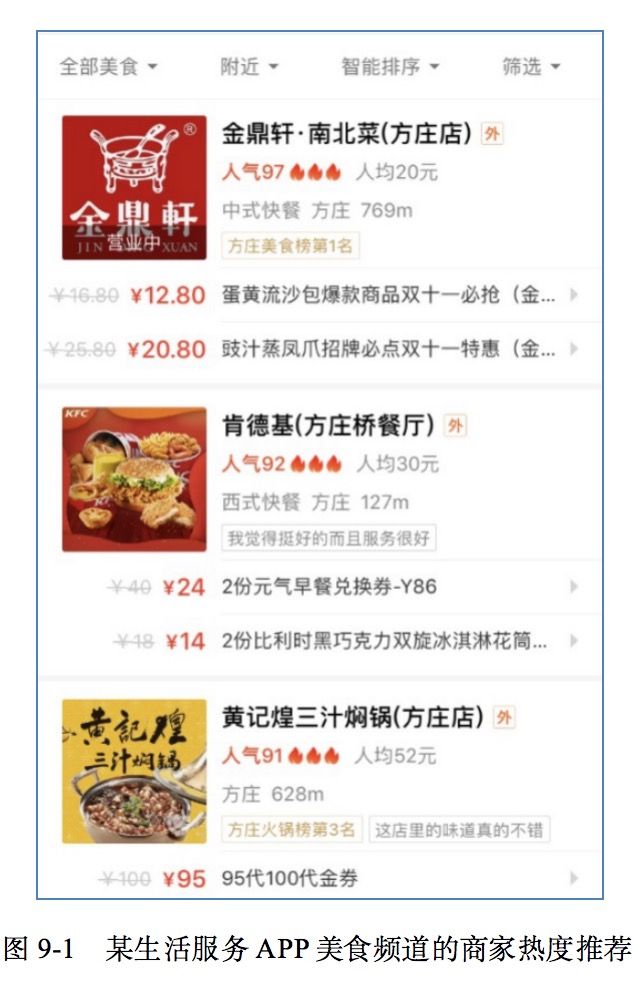
在工业界的推荐系统中,召回的类型是多种多样的,但往往也会召回性别热门、地域热门或群体热门等数据,进而扩展推荐系统的丰富性。同时,在用户行为较少或偏好较少的情况下,也能准确地为用户进行商品推荐。
利用用户注册信息实现冷启动
用户注册信息是指用户在新注册一个系统时所填写的信息。这些信息是联系新用户和系统的关键,也是系统获取的用户直接信息。
当一个新用户注册某个网站时,系统并不知道该用户喜欢什么物品,系统可以基于热门数据推荐为用户进行商品推荐。但如果系统能在用户进行注册时获取一些信息,则可以根据这些信息为用户进行商品推荐。例如,系统知道该用户来自东北,就可以给他推荐一些东北区域的热门物品;若知道该用户是来自东北的女性朋友,那么就会在地域的约束条件内,再给她推荐一些适合女性使用的物品,或者在性别的约束条件内,给她推荐一些区域内的热门商品。
用户在进行注册时,所填写的注册信息可以分为以下三类。
- 人口统计学信息:包括用户的年龄、身高、体重、居住地等。
- 用户兴趣的描述:某些网站或APP会让用户填写自己的兴趣爱好。
- 其他网站的导入数据:如用户通过微信、微博等登录第三方网站。
网站获取这些数据之后,就可以对用户进行粗粒度的个性化推荐了。其推荐的大致流程如下:
- 获取用户注册信息;
- 根据用户注册信息对用户进行分类(可以是多分类,即一个用户被分到多个类别中);
- 给用户推荐其所在分类的用户最喜欢的物品,对不同类别下的物品进行加权求和。
利用用户上下文信息实现冷启动
前边介绍了用户的时间和地域等上下文信息在推荐系统中的应用。在实际的业务场景中,用户的上下文信息所构造的特征维度更加丰富,如用户使用的设备信息、用户所处的时间地域信息、用户看到商品的展示信息。
上下文特征是代表用户当前时空状态、最近一段时间的行为抽象的特征。
设备信息特征
设备信息主要是用户进行浏览的载体(手机、平板电脑、电脑等)的信息。不同设备所携带的信息是不一样的。例如,手机或平板的操作系统分为iOS、Android、PC等;计算机的操作系统分为Windows、MacOS、UNIX等,手机和计算机品牌更是多种多样,不同设备的分辨率、屏幕尺寸、价格也是不一样的。
不同设备下用户的偏好也是不一样的。例如,iOS系统的用户可能是个“苹果粉”,那么在冷启动时就可以推荐一些苹果相关的产品,为了提升推荐系统的丰富度,也可以推荐一些手机数码类别的商品。再如,用户是用UNIX系统进行商品浏览的,那么该用户有可能是IT工作者,可以给该用户推荐一些数码、技术书籍等商品。
当然,除了在冷启动中使用这些特征,在正常训练推荐系统模型时也可以对设备的相关信息进行特征构造,进而作为特征来训练模型。
时间地域信息特征
时间和地域是推荐系统中比较重要的信息,在第7章中介绍了相关内容。那么针对冷启动,时间和地域是怎样发挥它们作用的呢?
时间可以是节假日、季节、周末等。地域可以是省市区、经纬度等,也可以是逻辑上的区域划分(如中关村软件园、商务中心区、海滨城市等)。当一个新用户来访时,通过对其建立时间和地域上的映射来为用户召回相关的商品并进行推荐。
在构建特征时,时间和地域也是非常重要的。例如,对于时间,可以构造如下特征:是否是工作日、是否是休息日、访问时间所属的时间段(早上、上午、中午、下午、晚上、凌晨)等。
实现原理
针对用户的上下文信息,可以根据用户的历史数据分析出用户在相应属性下的行为偏好,为相应的商品打上对应的时间和地域信息。在新用户来访时,系统通过获取时间和地域信息,召回对应属性下的数据,并按照一定的规则进行排序,然后返回前 K条数据给用户。
例如,服装、食物类商品有着明显的季节属性,特产、海鲜类商品有着明显的节日属性,每个商品都有产地属性和品牌属性,这样通过相应的标签就可以将用户的上下文信息和已经构建好的标签进行关联了。
同样,不仅可以将用户的上下文信息作为召回的标签数据,也可以对信息属性进行One-Hot编码,作为训练模型的特征使用。
利用第三方数据实现冷启动
目前很多APP支持第三方账户登录,通过第三方的授权登录,系统可以获取到用户在第三方平台上的相关信息(包括用户本身的属性信息和朋友关系信息),从而可以使用协同过滤算法计算出用户可能感兴趣的商品,进而解决用户的冷启动问题,为用户推荐个性化的内容。
利用用户和系统之间的交互实现冷启动
交互,即用户对系统的推荐结果做出反馈,或者系统通过一定的方式向用户进行兴趣征集。交互不仅在冷启动方面有着比较重要的作用,在推荐系统的结果反馈中也有着很重要的作用。
交互实现冷启动的原理和推荐系统中实时交互的应用有那些呢?
利用物品的内容属性实现冷启动
前边介绍的是如何解决推荐系统中的用户冷启动问题,对于物品冷启动问题该怎么解决呢?物品冷启动要解决的问题是,如何将新加入系统的物品推荐给对它感兴趣的用户。
物品的冷启动在新闻、娱乐、资讯类网站中格外重要。由于新闻的生命周期较短,如果无法在短期内将其曝光给更多的用户,那么其本身的价值将大大减小。
对于物品的冷启动,可以利用物品的内容属性将物品展示给尽可能符合其偏好的用户。
物品内容属性的分类
物品的内容属性多种多样,不同类型的物品有不同的内容属性,这里将物品的内容属性概括为三大类:
- 物品本身的属性:用来描述物品本身的属性,具有宏观上的唯一性,如物品编码、标题名字、产出时间等。
- 物品的归纳属性:用来形容物品的类别信息属性,具有宏观概括性,如类别、品牌、标签、风格等。
- 物品的被动属性:用户表示物品的被动行为属性,具有客观概括性,如物品的浏览量、点击率、评论等。
物品内容属性分析? 物品内容属性应用?
利用专家标注数据实现冷启动
很多推荐系统在刚开始建立时,既没有用户行为数据,也没有能用来准确计算物品相似度的物品信息。那么为了在刚开始就让用户获得良好的体验,很多系统都会采用专家标数据。这方面的代表是Pandora音乐电台。
Pandora是一个给用户播放音乐的个性化网络电台。计算音乐、视频之间的相似度是非常难的,音乐属于流媒体,如果从音频分析入手计算音乐的相似度,技术门槛很高,而且结果也难以令人满意。另外,仅仅利用音乐的专辑、歌手等信息也难以得到令人满意的结果。
为了解决这个问题,Pandora启动了一项称为“音乐基因组”的项目。这个名为“音乐基因组”的项目开始于1999年,该项目雇用一批懂计算机的音乐人,听了几万名歌手的歌,并对这些歌从各个维度进行标注,最终他们提供了450多维的特征来区分不同的音乐,这些标签可以细化到一首歌是否有吉他的和弦、是否有架子鼓、主唱的年龄等。在得到这些维度的特征之后就可以利用基于内容的推荐算法进行相似度计算了。这里的内容指的是音乐本身所表现出来的内容。
注:《推荐系统开发实战》是小编近期要上的一本图书,预计本月(7月末)可在京东,当当上线,感兴趣的朋友可以进行关注!

