pandas技能总结
pandas是数据分析的必备工具,操作非常方便,效率也非常高。在机器学习的特征工程阶段十分常用,起到事半功倍的效果。
1 pandas常用数据读取
pandas可以读取各种格式的数据文件,比如常见的csv,excel和数据库等数据文件,还能读取粘贴板里的数据。
- 读取csv文件
import pandas as pd df = pd.read_csv('filename') - 读取excel文件
df = pd.read_excel('filename') - 读取数据库文件
con = pymysql.connect(host="***", user="***", password="***", db="***") df = pd.read_sql("sql语句", con) - 读取粘贴板里的数据
df = pd.read_clipboard()
读取的数据将以
DataFrame格式返回,进行后续操作。
2 查看数据信息
df.info(): 返回每列数据的缺失值情况以及类型。df.index:返回DataFrame索引值。df.columns:返回DataFrame列名。df.dtypes:查看每列数据类型。df.values:查看数据值(以array形式返回)
3 创建Series
Series本质就像一个dict一样,可通过key取数据。
s = pd.Series([7, 'Beijing', 3.14, -123, 'Happy'])
pandas会默认从0到n来作为series的index(如上面的例子),但是我们也可以自己去指定index。index我们可以把它理解成dict当中的key。
s = pd.Series([7, 'Beijing', 3.14, -123, 'Happy'], index=['A','B','C','D','E'])
也可以用一个dict初始化一个Series
cities = {'Beijing':55000, 'Shanghai':60000, 'Shenzhen':50000, 'Hangzhou':30000, 'Guangzhou':45000, 'Suzhou':None}
my_series = pd.Series(cities, name='salary')
4 创建DataFrame
一个DataFrame就像是一个Excel当中的表格一样,Series就是一个一维数组,DataFrame是一个2维数组,你可以把DataFrame看做一组Series的组合。DataFrame的一列为一个Series。
- 传入字典创建
data = {'country':['aaa','bbb','ccc'], 'population':[10,12,14]} df = pd.DataFrame(data) - 指定索引和列名
df = pd.DataFrame([[1,2,3],[4,5,6]], index=['a','b'], columns['A','B','C'])
- 用几个Series创建
cities = {'Beijing':55000, 'Shanghai':60000, 'Shenzhen':50000, 'Hangzhou':30000, 'Guangzhou':45000, 'Suzhou':None} my_series = pd.Series(cities, name='salary') cars = pd.Series([300000,250000,200000,350000,250000,200000], index=['Beijing', 'Guangzhou', 'Hangzhou', 'Shanghai', 'Shenzhen', 'Tianjin']) df = pd.DataFrame({'salary':my_series, 'cars':cars})
5 常用数据分析操作
df.set_index()设置索引,可传入某一列名,将返回以该列名为索引的df。# 以Name列作为索引值 df = df.set_index('Name')df.describe()返回最大值、最小值、均值等统计值。
5.1 pandas数据索引
- 索引某几列数据的某几行
# 索引age和fare两个字段的前5条数据 df[['age', 'fare']][:5] df.iloc:通过num值来索引# 索引前5条数据的第2列和第3列数据 df.iloc[0:5, 1:3]df.loc通过label索引,一般为字符串(索引,列名)# 获取Mike的身高 df.loc['Mike', 'height'] # 也能切片处理 df.loc['Mike':, 'height':] # 也可以传入list drop_list = [695,2703,251,340] # list为不同的index disease_score.loc[drop_list] # 返回这4个索引对应4条数据的DataFrame
5.2 groupby操作
groupby能够对数据按照列进行分组,能够依照一列进行分组,也能够依照多列进行分组。
- 第一种写法,用内置的sum(),mean(),median(),size()
df.groupby('key').sum() # 对key字段分组求和 df.groupby('sex')['age'].mean() # 统计男女的年龄均值 ... - 第二种,借助agg
结果如下:import pandas as pd salaries = pd.DataFrame({'name':['BOSS','David','David','Han','BOSS','BOSS','Han','BOSS'], 'Year':[2016,2016,2016,2016,2017,2017,2017,2017], 'Salary':[9999999,20000,25000,3000,9999999,9999999,3500,9999999], 'Bonus':[1000000,200000,250000,5000,2000000,2500000,3000,40000000]}) group_by_name = salaries.groupby('name') group_by_name[['Bonus','Salary']].agg(['sum','mean','median','size']) # 同时执行这几个统计操作,size为统计每个分组的记录 # 也可以使用numpy的操作这样写 group_by_name.agg([np.sum, np.mean, np.std])

对每一列可以采用不同的aggregate操作# 以字典形式指定每列执行的操作 group_by_name.agg({"Bonus": np.sum, "Salary": np.sum, "Year": (lambda x: list(x)[0])})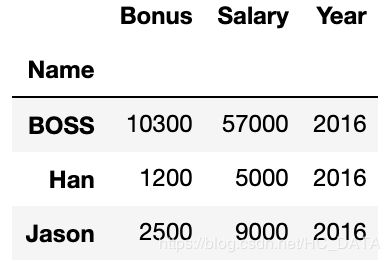
- 依照多列进行分组
group_by_name_year = salaries.groupby(['name','Year']) group_by_name_year.sum()
分组之后可以接agg,也可以接describe去看每个组的统计分布 - 查看分组详情
# 遍历查看所有组 for name,group in group_by_name: print(name) print(group) # 选择一个组 group_by_name.get_group('David') - 数据处理transform
下图为一份英伟达数据:
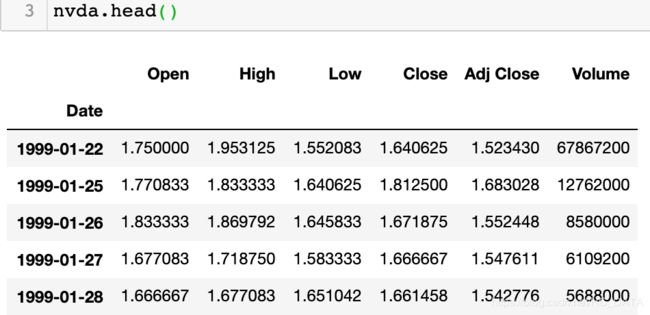
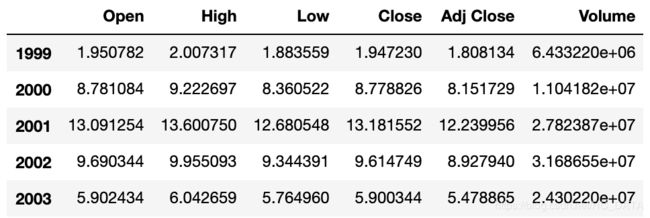
运行结果如下:# groupby可以接收函数返回值 nvda.groupby(lambda x:x.year).mean() # 上面也可写成 nvda.groupby(nvda.index.year).mean()
transform操作my_transform = lambda x:(x-x.mean())/x.std() # 按照年份分组后,对每列进行transform操作 transform = nvda.groupby(nvda.index.year).transform(my_transform) transform.head()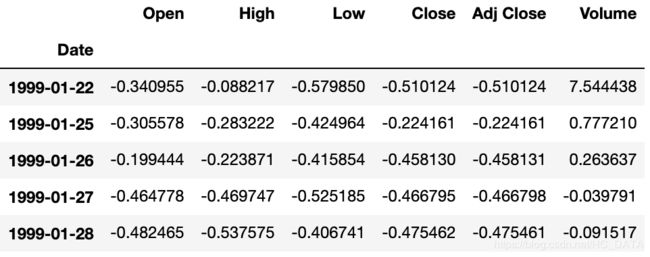
5.3 数值运算
df.sum(axis=1) # 按行求和,默认axis=0,按列求和
df.mean()
df.max()
df.min()
df.median()
df.cov() # 返回特征之间的协方差
df.corr() # 返回特征之间的相关系数
df['age'].value_counts() # 统计不同年龄值的人数
df['age'].value_counts(ascending=True) # 指定升序排列
df['age'].value_counts(ascending=True, bins=5) # 将年龄平均划分为5组统计
df['age'].count() # 统计age列有多少非空值
5.4 对象操作
- Series结构的增删改查
data = [10,11,12] index = ['a','b','c'] s = pd.Series(data=data, index=index) # 创建就series # 索引方式和dataframe类似 s[0:2] # 返回a,b两条数据 mask = [True,False,True] s[mask] # 返回a,c两条数据 s.loc['b'] # 索引b的值 s.iloc[1] # 返回11 s1 = s.copy() # 拷贝一份 s1['a'] = 100 # 将a的值改为100 s1.replace(to_replace=100, value=101, inplace=True) # 将100替换为101 s1.index = ['a','b','d'] # 修改索引 s1.rename(index=['a':'A'], inplace=True) # 将索引a改为A s2 = pd.Series([100,500], index=['g','h']) s1.append(s2) # s2添加到s1中 s1.append(s2, ignore_index=False) # 等于False保留原来的索引,True生成新的索引方式 del s1['A'] # 删除s1中的A记录 s1.drop(['b','d'],inplace=True) # 删除多条记录采用drop - DataFrame结构的增删改查
data = [[1,2,3],[4,5,6]] index = ['a','b'] columns = ['A','B','C'] df = pd.DataFrame(data=data, index=index, columns=columns) # 查操作是类似的 df['A'] # 查看A列 df.loc['a'] # 查看a条记录 # 改操作 df.loc['a']['A'] = 150 # 改某个值 df.index = ['f','g'] # 改索引 # 增操作 df.loc['c'] = [1,2,3] # 增加索引为c的记录 df2 = pd.DataFrame(data=[[1,2,3],[4,5,6]], index=['j','k'], columns=['A','B','C']) df3 = pd.concat([df,df2]) # 按照样本进行纵向,指定axis=1进行横向拼接 df['D'] = [10,11] # 增加D列 df4 = pd.DataFrame([[10,11],[12,13]], index=['j','k'], columns=['D','E']) df5 = pd.concat([df2,df4], axis=1) # 此时增加了D和E两列数据 # 删操作 df5.drop(['j'], axis=0, inplace=True) # 删除第j行样本 del df5['D'] # 删除D列 df5.drop(['A','B','C'], axis=1, inplace=True) # s删除ABC三列
5.5 多表合并与拼接
-
concat
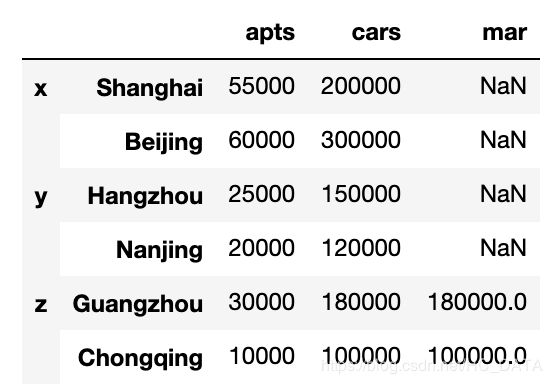
df1 = pd.DataFrame({'apts': [55000, 60000], 'cars': [200000, 300000],}, index = ['Shanghai', 'Beijing'] ) df2 = pd.DataFrame({'cars': [150000, 120000], 'apts': [25000, 20000], }, index = ['Hangzhou', 'Nanjing']) df3 = pd.DataFrame({'apts': [30000, 10000], 'cars': [180000, 100000],'mar': [180000, 100000]}, index = ['Guangzhou', 'Chongqing']) result = pd.concat([df1,df2,df3]) result
在concat的时候可以指定keys,这样可以给每一个部分加上一个Key。
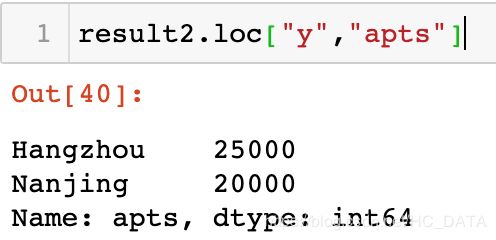
以下的例子就构造了一个hierarchical index。result2 = pd.concat([df1,df2,df3], keys=['x', 'y', 'z'], sort=False) result2
随后我们可以根据key获取对应数据:
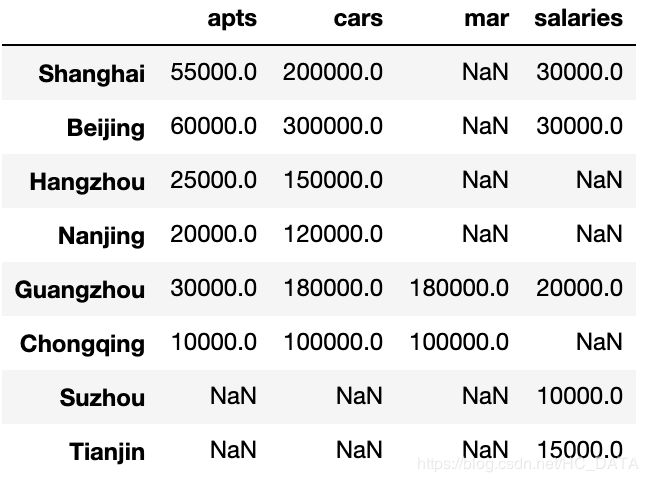
指定axis=1可以做横向拼接
df4 = pd.DataFrame({'salaries': [10000, 30000, 30000, 20000, 15000]},
index = ['Suzhou', 'Beijing', 'Shanghai', 'Guangzhou', 'Tianjin'])
result3 = pd.concat([result, df4], axis=1, sort=False)
result3
用inner可以去掉NaN,也就是说如果出现了不匹配的行就会被忽略
result3 = pd.concat([result, df4], axis=1, join='inner')
result3

Series和DataFrame还可以被一起concatenate,这时候Series会先被转成DataFrame然后做Join,因为Series本来就是一个只有一维的DataFrame。
- append
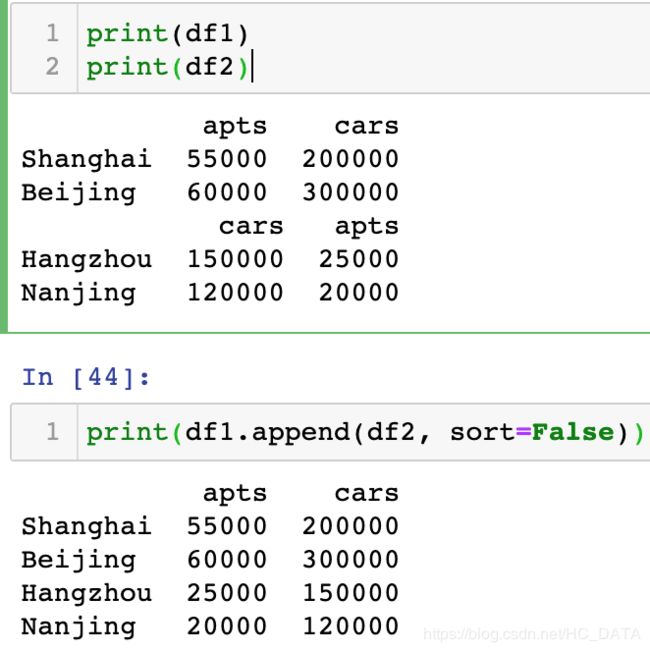
- merge
df1 = pd.DataFrame({'apts': [55000, 60000, 58000], 'cars': [200000, 300000,250000], 'city': ['Shanghai', 'Beijing','Shenzhen']}) df4 = pd.DataFrame({'salaries': [10000, 30000, 30000, 20000, 15000], 'city': ['Suzhou', 'Beijing', 'Shanghai', 'Guangzhou', 'Tianjin']}) result = pd.merge(df1, df4, on='city') result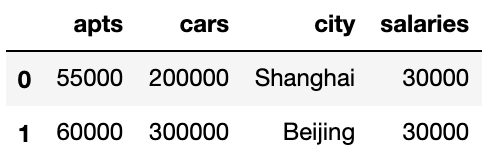
如果不指定on的对象,pandas也会寻找两个表相同列名去merge
how可以指定不同方式print(pd.merge(df1, df4, on='city', how='outer')) print(pd.merge(df1, df4, on='city', how='right')) print(pd.merge(df1, df4, on='city', how='left'))
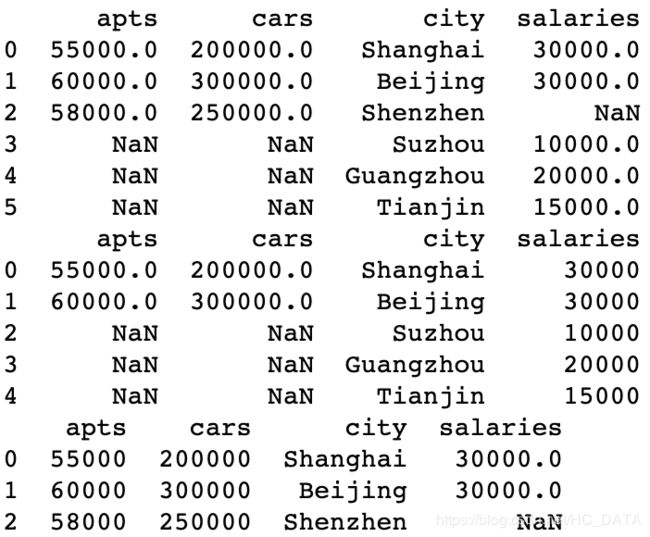
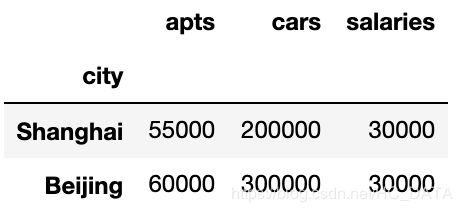
如果要用concat做同样的事情
pd.concat([df1.set_index("city"), df4.set_index('city')], sort=False, axis=1, join="inner")
5.6 缺失值处理
dropna默认是删掉行,如果想删掉一列,就要声明一下axis参数
# how='all'表示删除全部是缺失值的行或列,默认是行,指定axis=1,会删除全是缺失值的列
bikes.dropna(how="all", axis=1).head()